1.什么是目标检测?

目标检测 vs 图像分类

目标检测的应用
(1)人脸识别
(2)智慧城市
(3)自动驾驶
(4)下游视觉任务:场景文字识别、人体姿态估计
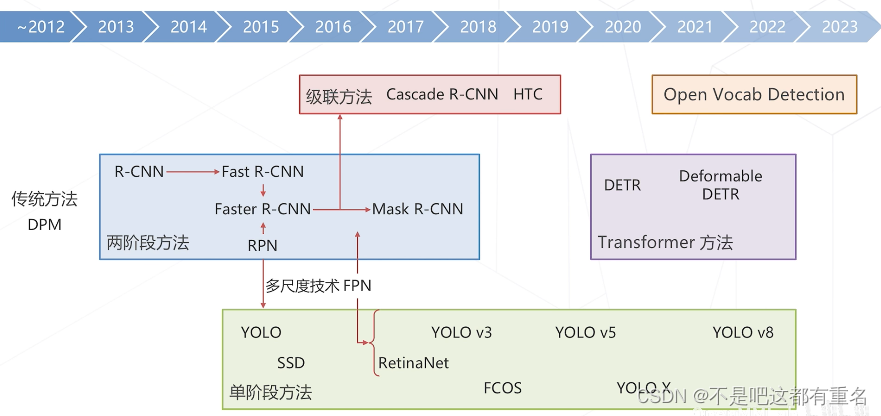
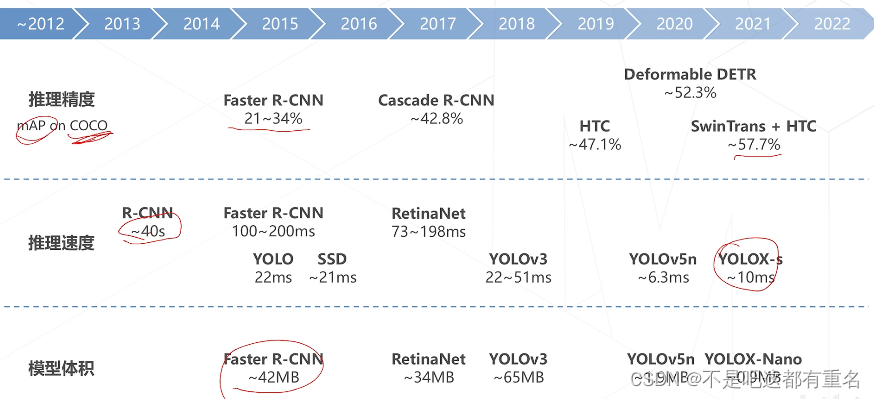
目标检测技术的演进
2.基础知识
框,边界框(Bounding Box)
框泛指图像上的矩形框,边界横平竖直。
边界框通常指紧密包围感兴趣物体的框,检测任务要求为图中出现的每个物体预测一个边界框
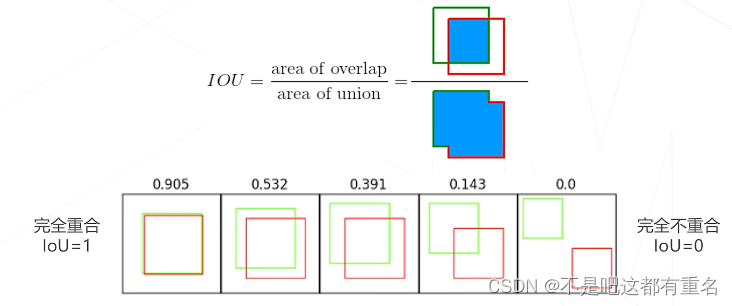
交并比(Intersection Over Union)
定义:两矩形框交集面积与并集面积之比,是矩形框重合程度的衡量指标。
感受野
定义:神经网络中,一个神经元能看到的原图的区域
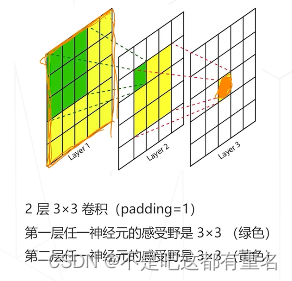
感受野的中心和步长
感受野的中心:
- 一般结论比较复杂;
- 对于尺寸3x3,pad=1的卷积(或池化)堆叠起来的模型,感受野中心=神经元在特征图上的坐标x感受野步长
感受野的步长(=降采样率=特征图尺寸的缩减倍数):
- 神经网络某一层上,相邻两个神经元的感受野的距离
- 步长=这一层之前所有stride的乘积
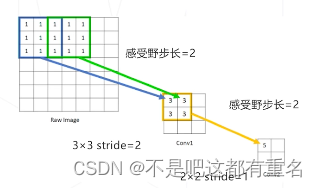
有效感受野(Effective RF)
感受野一般很大,但不同像素对激活值的贡献是不同的,也就是说激活值对感受野内的像素求导数,大小不同。影响比较大的像素通常聚集在中间区域,可以认为对应神经元提取了有效感受野范围内的特征。也就是说,感受野边缘的贡献不大,而中心比较重要。
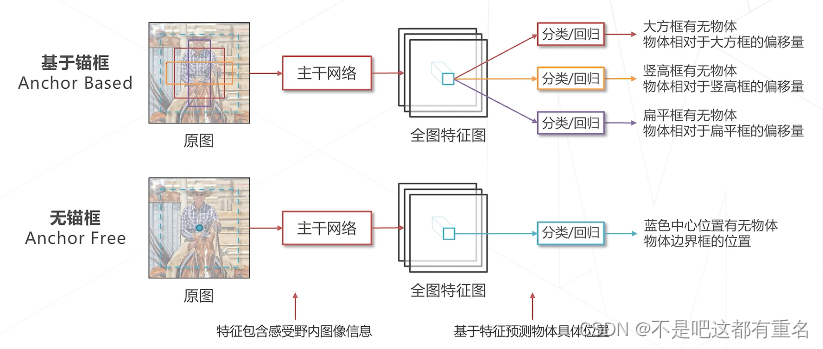
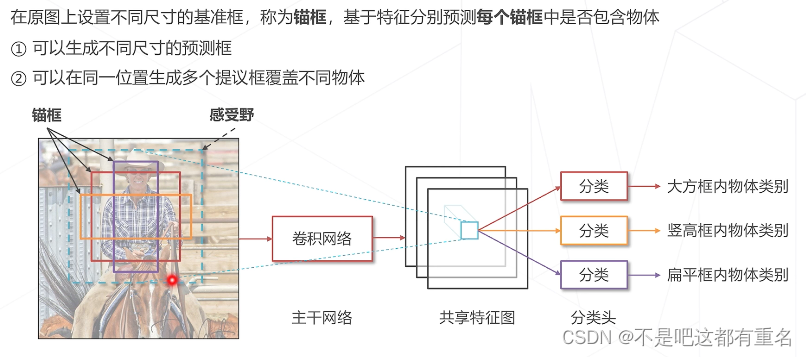
基于锚框 vs 无锚框
非极大抑制 Non-Maximum Suppression
滑窗类算法通常会在物体周围给出多个相近的检测框,这些框实际指向同一物体,只需保留其中置信度最高的
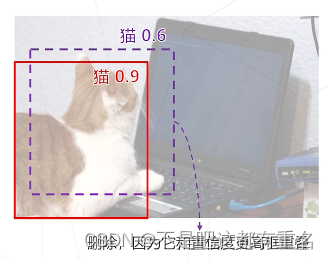
非极大抑制的算法实现:

置信度 Confidence Score
置信度:模型认可自身预测结果的程度,通常需要为每个框预测一个置信度,我们倾向认可置信度高的预测结果,例如有两个重复的预测结果了,丢弃置信度低的。
- 部分算法直接取模型预测物体属于特定类别的概率;
- 部分算法让模型单独预测一个置信度(训练时有GT,可以得相关信息作为监督);

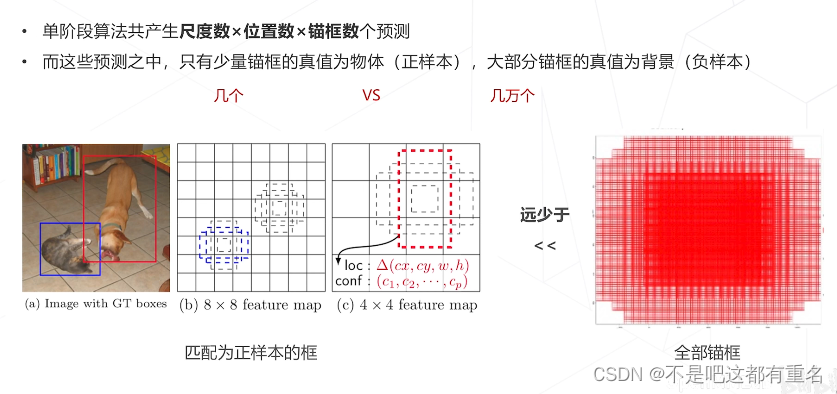
正负样本不均衡问题
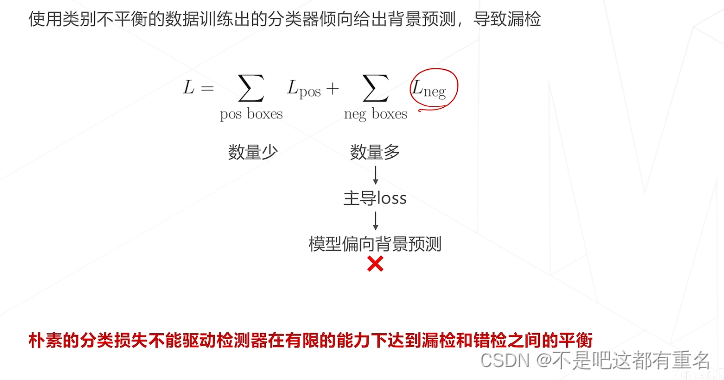
3.目标检测的基本思路
检测问题的难点
(1)需要同时解决是什么和在哪里
(2)图中物体位置、数量、尺度变化多样
滑窗 (Sliding Window)
(1)设定一个固定大小的窗口
(2)遍历图像的所有位置,所到之处用分类模型(假设已经训练好)识别窗口中的内容
(3)为了检测不同大小、不同形状的物体,可以使用不同大小、长宽比的窗口扫描图片
缺点:效率问题,计算成本很高。
改进思路1:用启发式算法替换暴力遍历,用相对低计算量的方式粗筛出可能包含物体的位置,再使用卷积网络预测。早期二阶段方法使用,依赖外部算法,系统实现复杂。
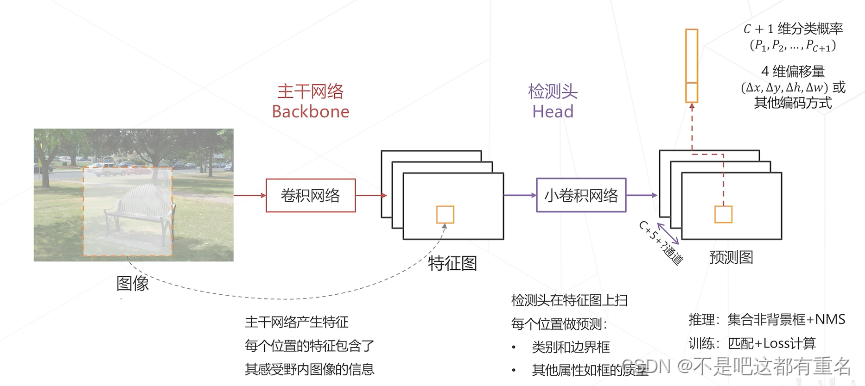
改进思路2:减少冗余计算,使用卷积网络实现密集预测,这是目前普遍采用的方式。
分析滑窗中的重复计算
下图中的重叠部分被相同的卷积核卷积,计算冗余了。
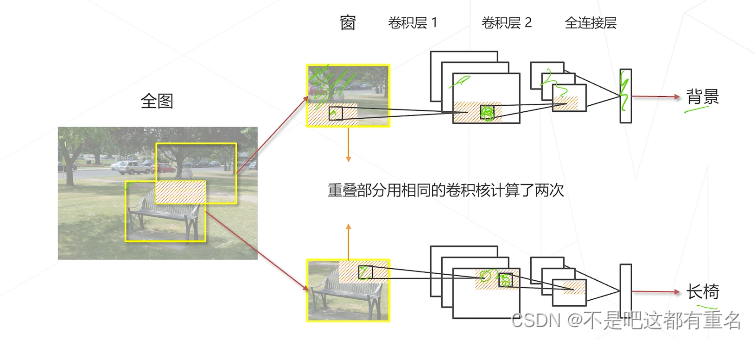
改进思路
用卷积一次性计算全图所有特征,再取出对应位置的特征完成分类
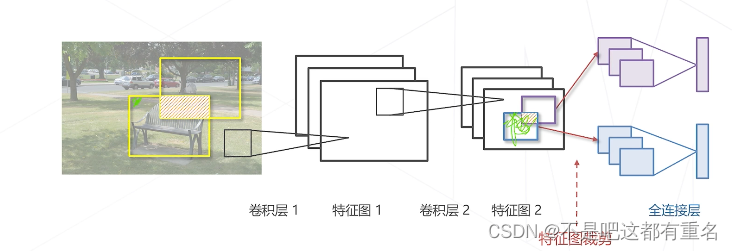
这样的特征图滑窗相比原图滑窗来说,重叠区域只计算一次卷积特征,与窗的个数无关
在特征图上进行密集预测

边界框回归 Bounding Box Regression
问题:滑窗与物体精确边界通常有偏差
处理方法:让模型在预测物体类别的同时预测边界框相对于滑窗的偏移量,这种基于同一特征做两个预测的也叫做多任务学习。
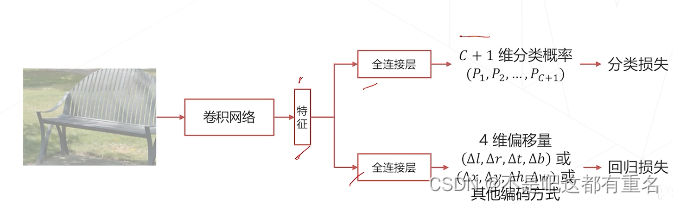
使用密集预测模型进行推理
基本流程:
- 用模型做密集预测,得到预测图,每个位置包含类别概率、边界框回归的预测结果
- 保留预测类别不是背景的框
- 基于框中心,和边界框回归结果,进行边界框解码
- 后处理:非极大值抑制
如何训练
训练神经网络的一般套路:
- 模型基于当前参数给出预测
- 计算loss:衡量预测的好坏
- 反传loss、更新参数
密集预测的训练过程: - 检测头在每一个位置产生一个预测(有无物体、类别、位置偏移量)
- 该预测值应与某个真值比较产生损失,进而才可以训练检测器
- 但这个真值在数据标注中并不存在,标注只标出了有物体的地方
- 我们需要基于稀疏的标注框为密集预测的结果产生真值,这个过程称为匹配(Assignment)
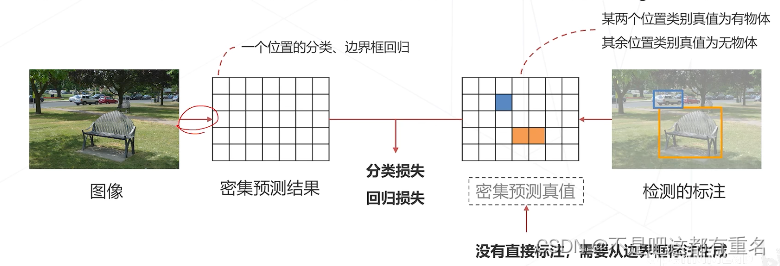
匹配的基本思路:

密集预测的基本范式
4.密集预测范式的改进:多尺度预测
尺度问题
图像中的物体大小可能有很大的差异。
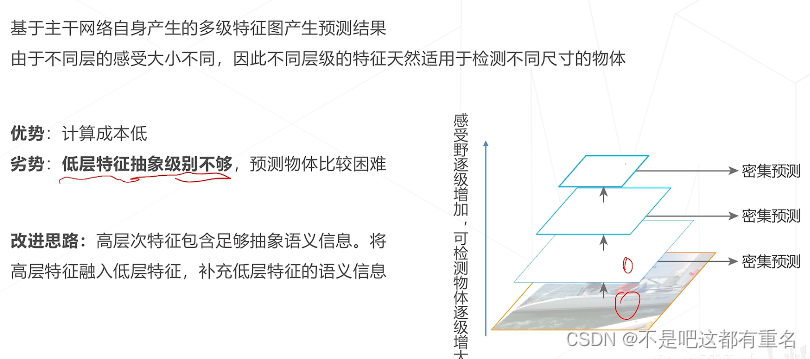
朴素的密集范式中,如果让模型基于主干网络最后一层或者倒数第二层特征图进行预测:
- 受限于结构(感受野),只擅长中等大小的物体
- 高层特征图经过多次采样,位置信息逐层丢失,小物体检测能力较弱,定位精度较低
解决方式
方法一:基于锚框
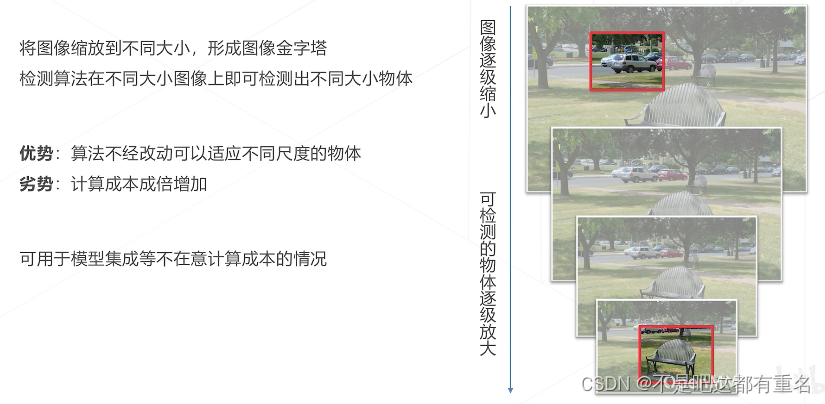
方法二:图像金字塔 Image Pyramid
方法三:基于层次化特征
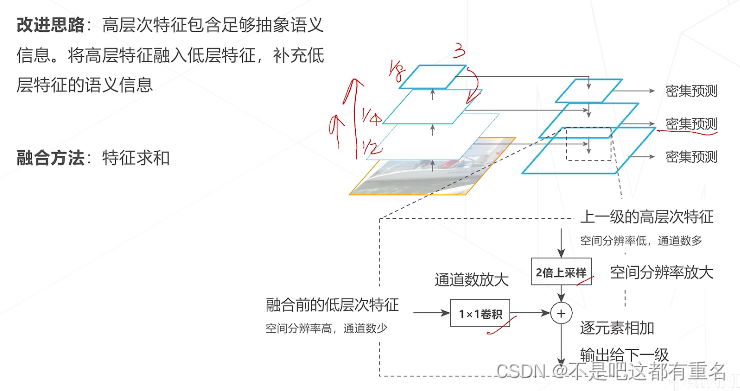
方法四:特征金字塔网络 Feature Pyramid Network
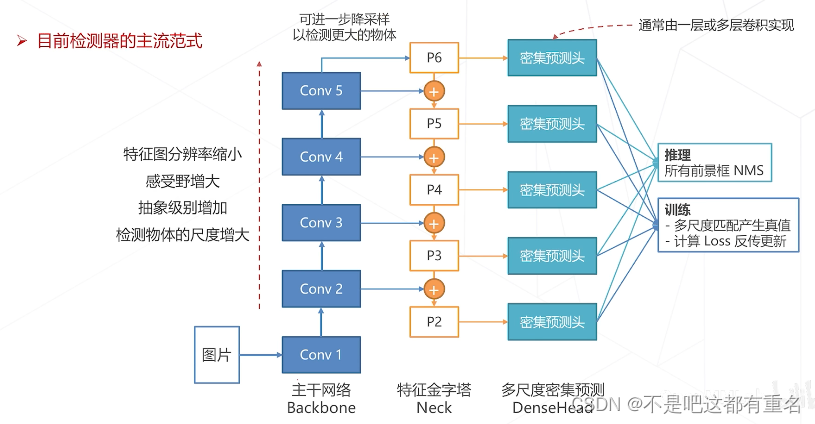
多尺度密集预测范式
5. 单阶段目标检测算法选讲
Region Proposal Network(2015)
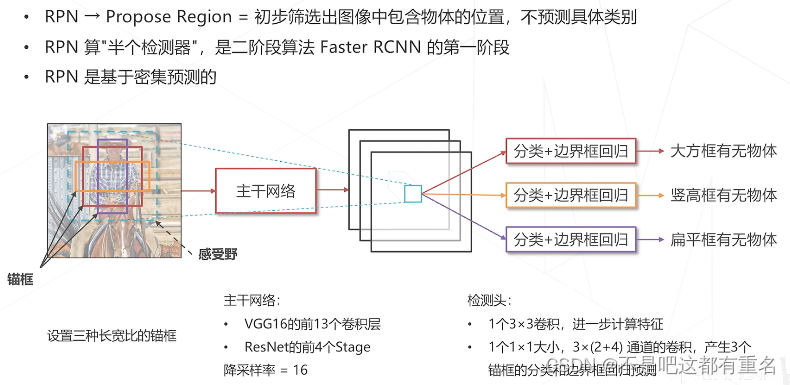
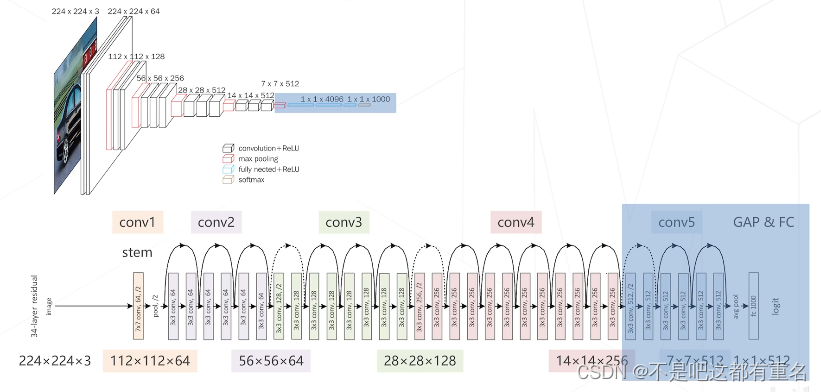
RPN的主干网络图(VGG上,resnet下)
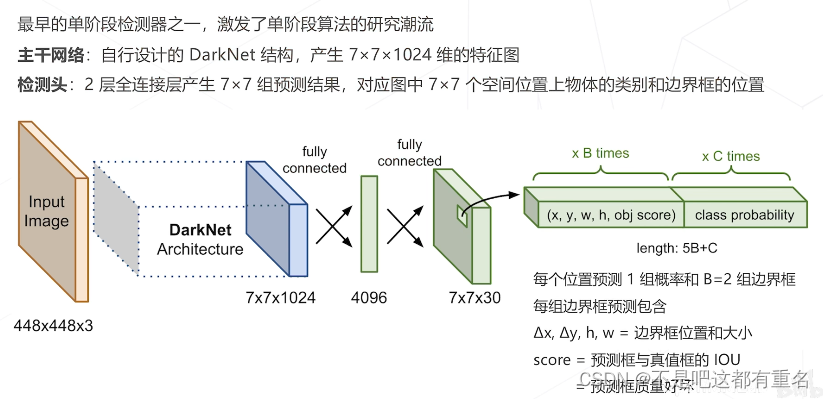
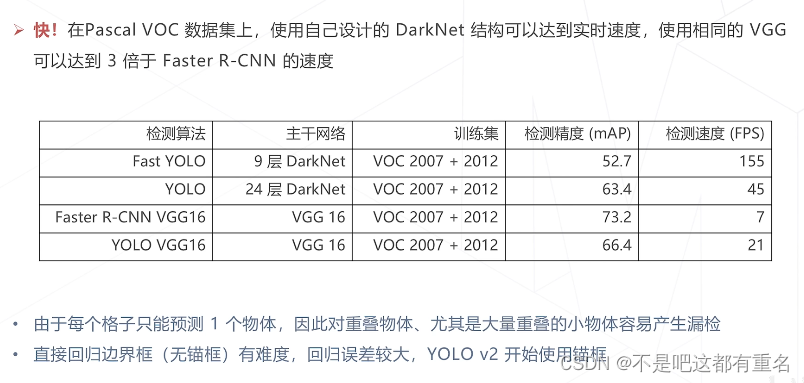
YOLO:You Only Look Once(2015)
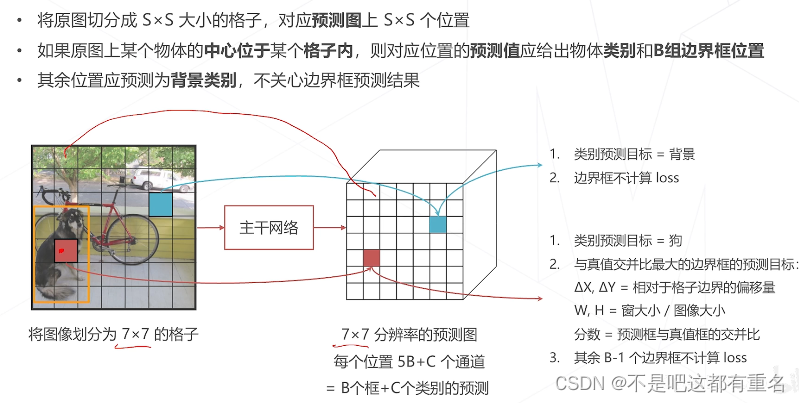
YOLO的匹配与框编码
YOLO的损失函数(现在也不是很常见)

YOLO的优缺点
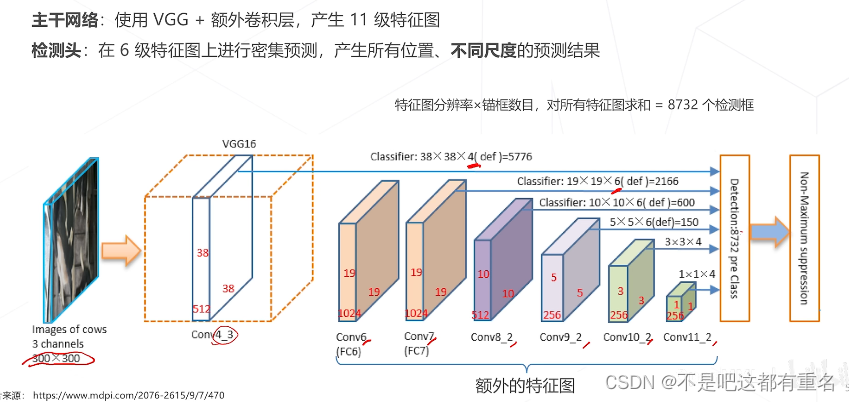
SSD:Single Shot MultiBox Detector (2016)
第一个使用多级特征图
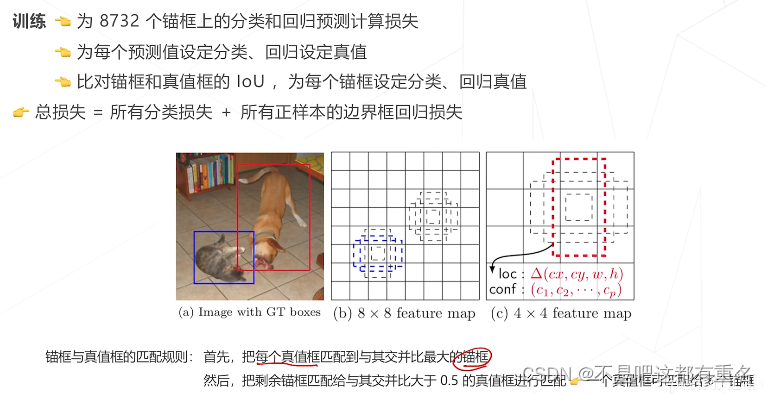
SSD 的匹配规则
RetinaNet(2017)
FPN成为主要结构
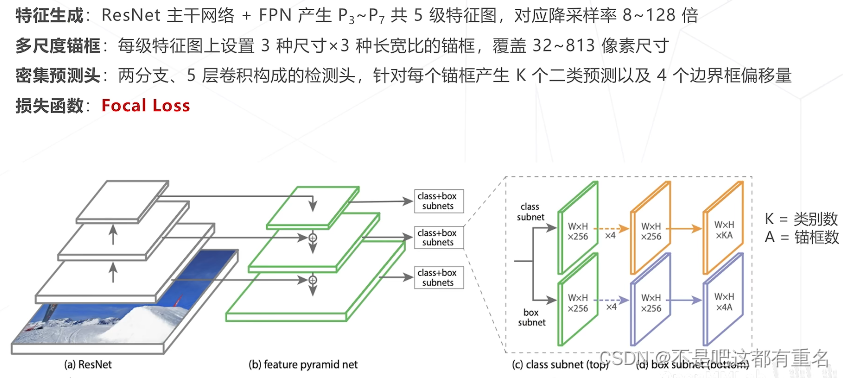
提出Focal loss主要为了解决单阶段算法面临的正负样本不均衡问题
不同负样本对损失函数的贡献
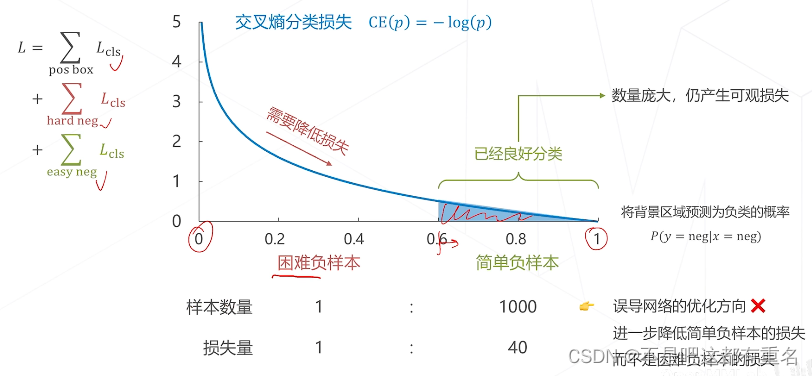
改进:降低简单负样本的损失
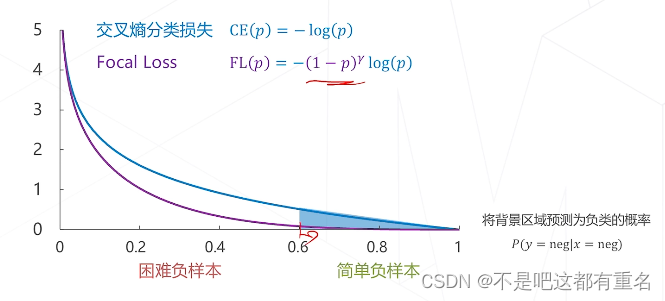
Focal Loss

YOLO v3(2018)
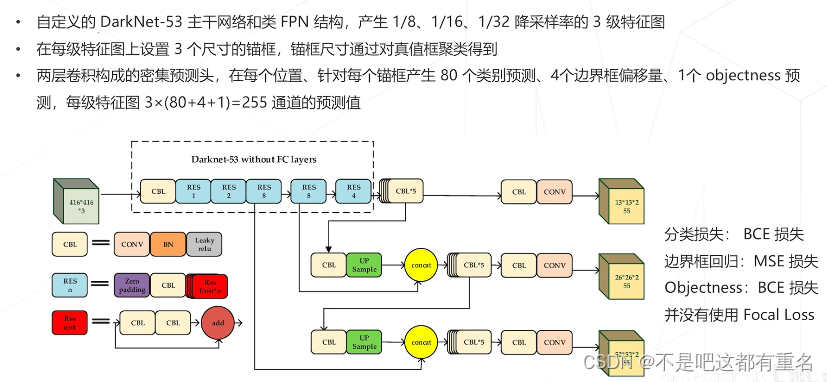
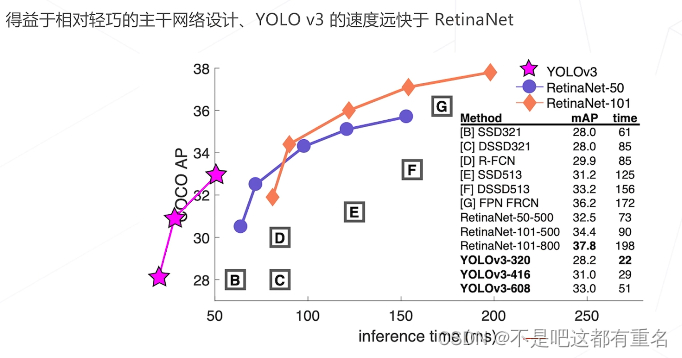
YOLO v5(2020)

6. 无锚框目标检测算法
不用锚框会导致对于重叠物体的检测效果特别差,但是借助FPN可以利用不同层次的特征预测。
FCOS,Fully Convolutional One-stage(2019)
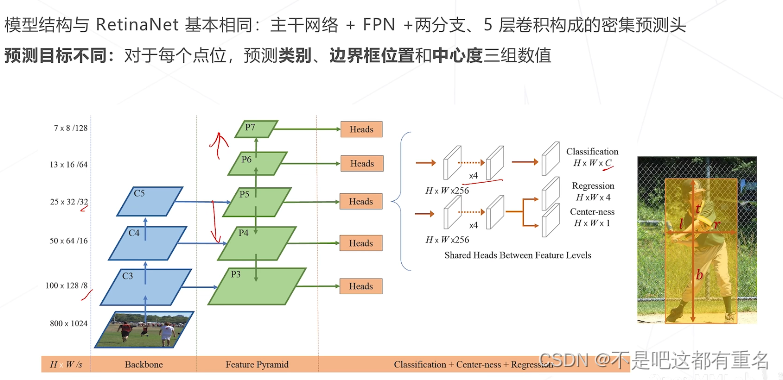
FCOS的预测目标 and 匹配规则
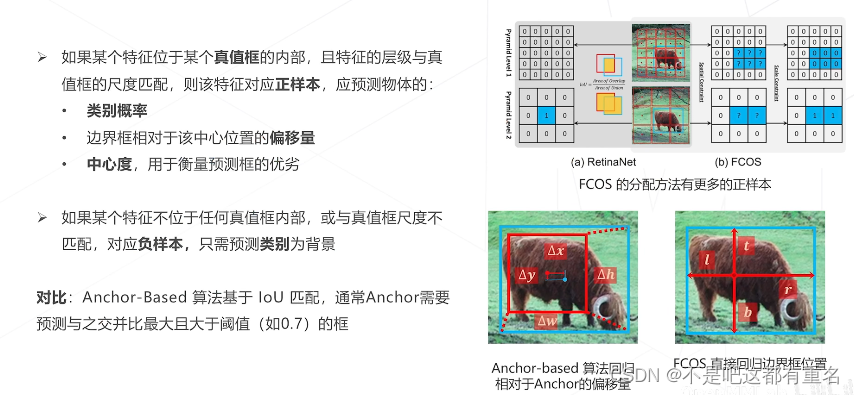
FCOS的多尺度匹配

中心度 Center-ness
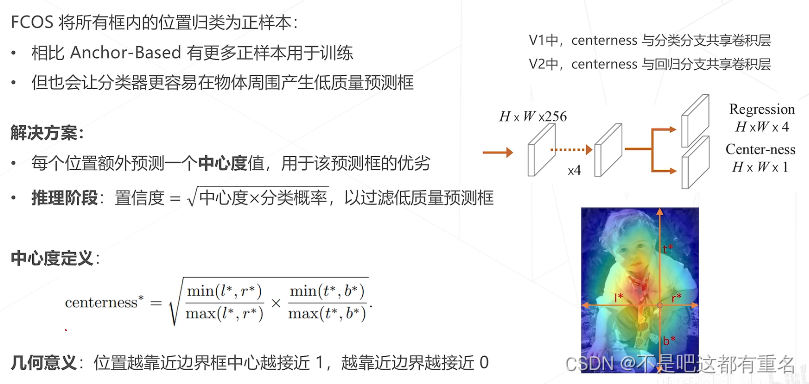
FCOS的损失函数

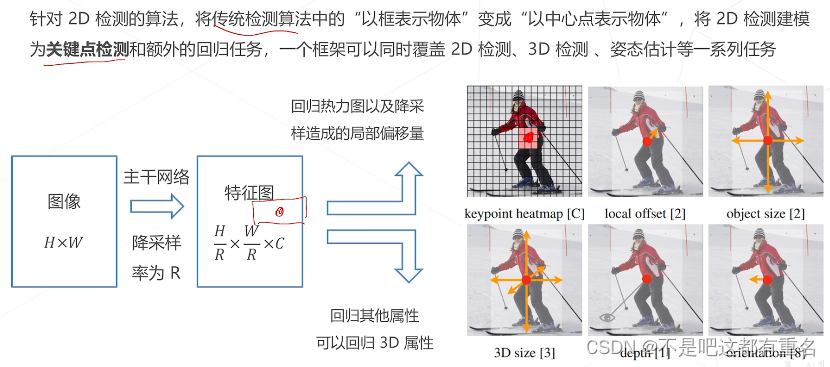
CenterNet(2019)
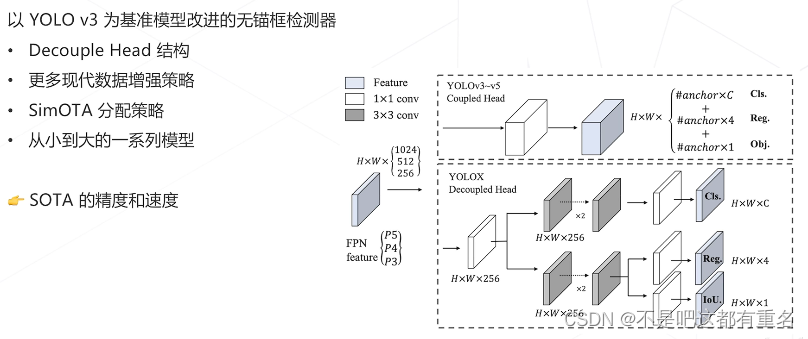
YOLO X(2021)
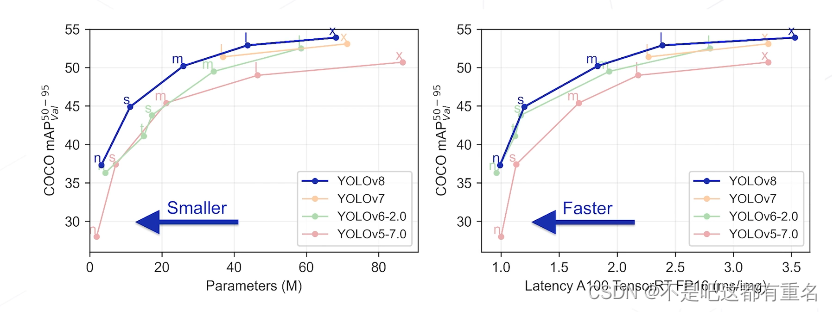
YOLO V8(2022)
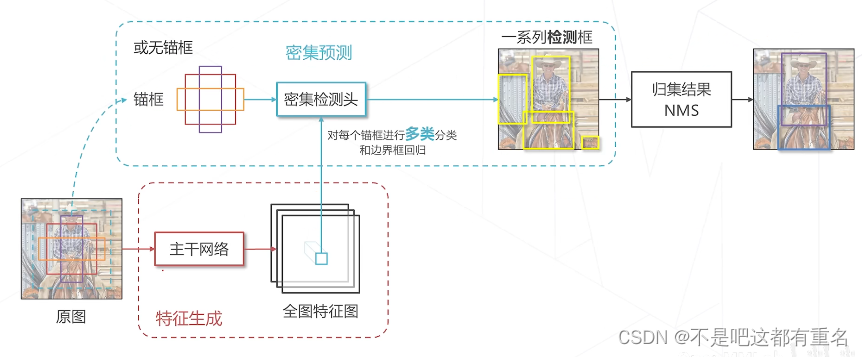
7. 单阶段算法和无锚框算法的总结










![[游戏开发]Unity中随机位置_在圆/椭圆/三角形/多边形/内随机一个点](https://img-blog.csdnimg.cn/4668207fb7d34b05a7ebf6cfe8504c45.png)