seqkit拆分fastq,fasta等文件有两种方式:split和split2, 二者的逻辑并不一样。
split 是将原文件拆分,写满第一个文件,再写第二个文件
split2是将原文件的内容,挨个写到各个拆分文件里面去?
比如原文件有10条记录,拆成五份:
按split拆,第一个文件就是(1,2),第二个文件就是(3,4)。。。
按split2拆,第一个文件就是(1,5),第二个文件就是(2,6)。。。
原作者沈伟描述:split2里,类似玩扑克牌的时候,挨个给玩家发牌的顺序。
split2Cmd.Flags().IntP("by-part", "p", 0, "split sequences into N parts with the round robin distribution")
斗地主的情况下,
如果按split方式发牌,就是给第一个人发17张,然后再给第二个人发17张,第三个人是最后17张。这样会很多炸弹。
如果按split2方式发牌,就是每人每次发一张牌,不断重复这个过程,就是所谓的round robin distribution。
如果像让拆分的子文件保留原文件的顺序,则用split更合适。
如果不在乎顺序,更注重拆分速度,则用split2更合适。
因为split2的速度是split的5倍
可以随便拿一个fasta文件测试一下两种拆分方式的速度和拆分后的文件内容顺序
#split
#!/bin/sh
#$ -S /bin/sh
echo -n "split mask.fa: "; date +%Y-%m-%d%t%H:%M:%S
seqkit split --force --by-part 20 --threads 6 ./mask.fa --out-file mask.fa --out-dir mask_split
echo -n "End: "; date +%Y-%m-%d%t%H:%M:%S
#split2
#!/bin/sh
#$ -S /bin/sh
echo -n "split2 mask.fa: "; date +%Y-%m-%d%t%H:%M:%S
seqkit split2 --force --by-part 20 --threads 6 ./mask.fa --out-file mask.fa --out-dir mask_split2
echo -n "End: "; date +%Y-%m-%d%t%H:%M:%S
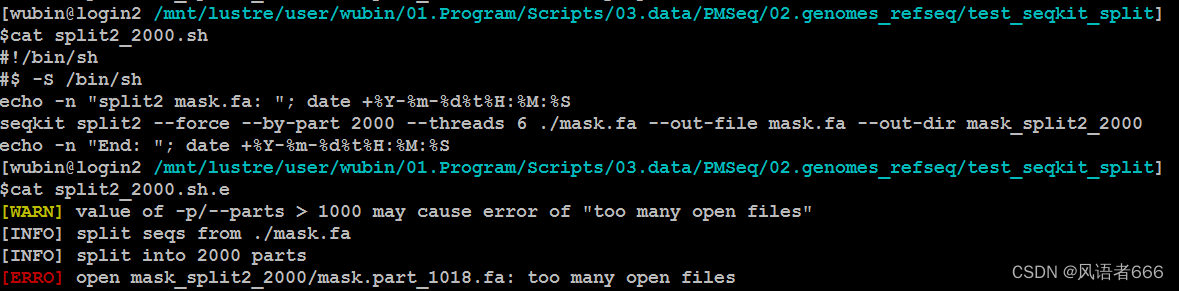
拆分的分数不能超过1000



![[游戏开发]Unity中随机位置_在圆/椭圆/三角形/多边形/内随机一个点](https://img-blog.csdnimg.cn/4668207fb7d34b05a7ebf6cfe8504c45.png)