面向企业开发者的PaaS方案
一周前,阿里云OpenSearch发布的LLM智能问答版,面向行业搜索场景,提供企业专属问答搜索服务。作为一站式免运维的SaaS服务,智能问答版基于内置的LLM大模型提供问答能力,为企业快速搭建问答搜索系统,详见链接:https://developer.aliyun.com/article/1239380
除了SaaS的解决方案外,如今阿里云OpenSearch再推面向企业开发者的PaaS方案:基于OpenSearch向量检索版,为企业开发者提供性能表现优秀、性价比优异的向量检索服务,并提供与大模型结合脚本工具,用户可在使用能力可靠的向量检索服务的同时,自由选择文档切片方案、向量化模型、大语言模型。
大语言模型时代,对话式搜索开启新纪元
随着2022年末发布大语言模型应用,短短两个月时间月活过亿,惊人的增长速度刷新了AI应用的记录,也把整个世界带到了大模型时代。
新的技术浪潮带来业务场景的革新,Google、Bing等大企业的跟进,使得对话式搜索成为企业争相探索的新领域,如何将大语言模型强大的逻辑推理、对话能力,与业务自身垂直领域数据相结合,打造出专属企业的对话式搜索服务,成为待解决的首要问题。
为什么不能直接使用大语言模型?
大语言模型表现出的“什么都懂,什么都能聊”,主要依赖于底座大语言模型(LLM)中压缩的世界知识,它能够回答比较普世的问题,但如果直接使用大语言模型咨询垂直专业领域问题,因为世界知识中并不包含企业专属的数据,得到的结果经常是完全错误的、不相关的。
下图示例中,提到的havenask是阿里巴巴自研的开源大规模搜索引擎(https://github.com/alibaba/havenask),作为OpenSearch的底层引擎于2022年11月对外开源,但大语言模型并未获知此信息,返回结果不理想。
开源信息尚且如此,可见企业想基于自身数据构建对话式搜索,是无法直接使用大语言模型的,需寻求结合方案。

为什么用向量检索+大语言模型搭建对话式搜索?
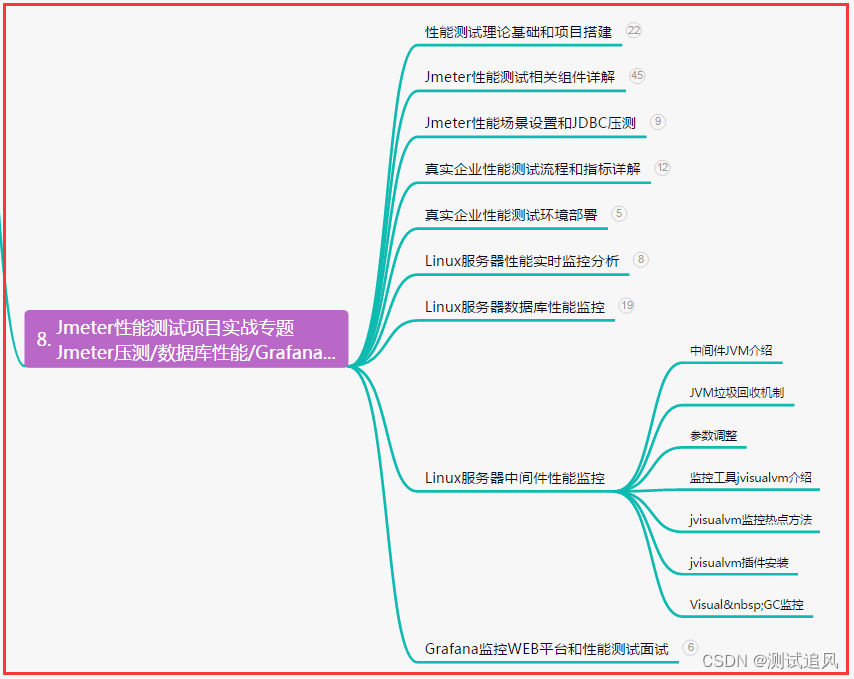
对话式搜索的应用场景
对话式搜索可被应用于电商、内容、教育、企业内部等多行业领域,根据客户特征与问题需求,精准获得问答结果,高效获取信息。
那么企业该如何基于自身数据,构建垂直领域对话式搜索服务呢?
当前大多数企业均采用“文档切片+向量检索+大模型生成答案”的方式,构建垂直领域对话式搜索。
将企业数据和对话交互信息,先进行向量特征提取,然后存入向量检索引擎构建索引并进行相似度召回,将召回TOP结果传入LLM大语言模型,对信息进行对话式结果整合,最终返回给客户。这种方案在成本、效果、业务使用灵活度等方便均具备优势,成为企业的优选方案。
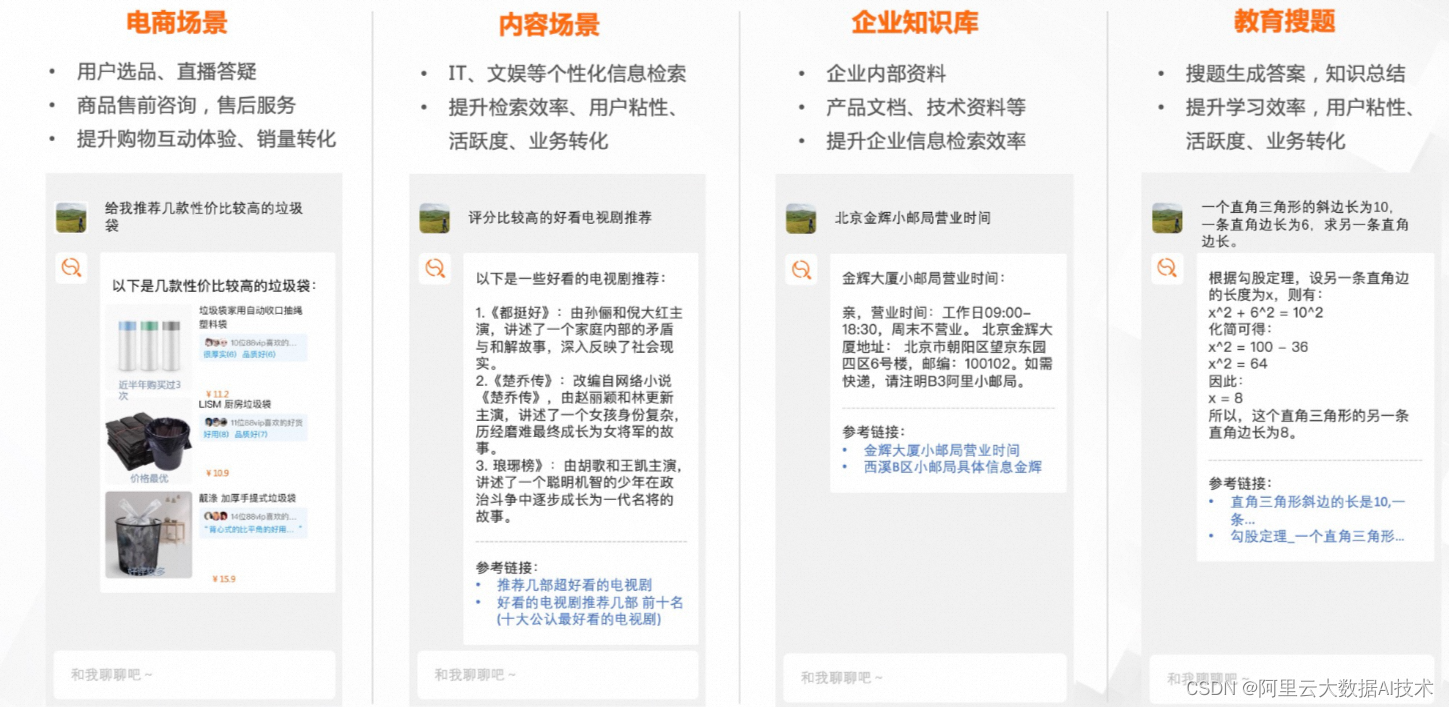
什么是向量?
将物理世界产生的非结构化数据(如图片、音视频、对话信息),转化为结构化的多维向量,用这些向量标识实体和实体间的关系。再计算向量之间距离,通常情况下,距离越近、相似度越高,召回相似度最高的TOP结果,完成检索。向量检索其实离我们很近:以图搜图、同款比价、个性化搜索、语义理解……
为什么向量能用于对话式搜索?
向量检索的其中一个典型应用场景就是「自然语义理解、语义理解」,而对话式搜索的核心,也在于对问题和答案的语义理解。
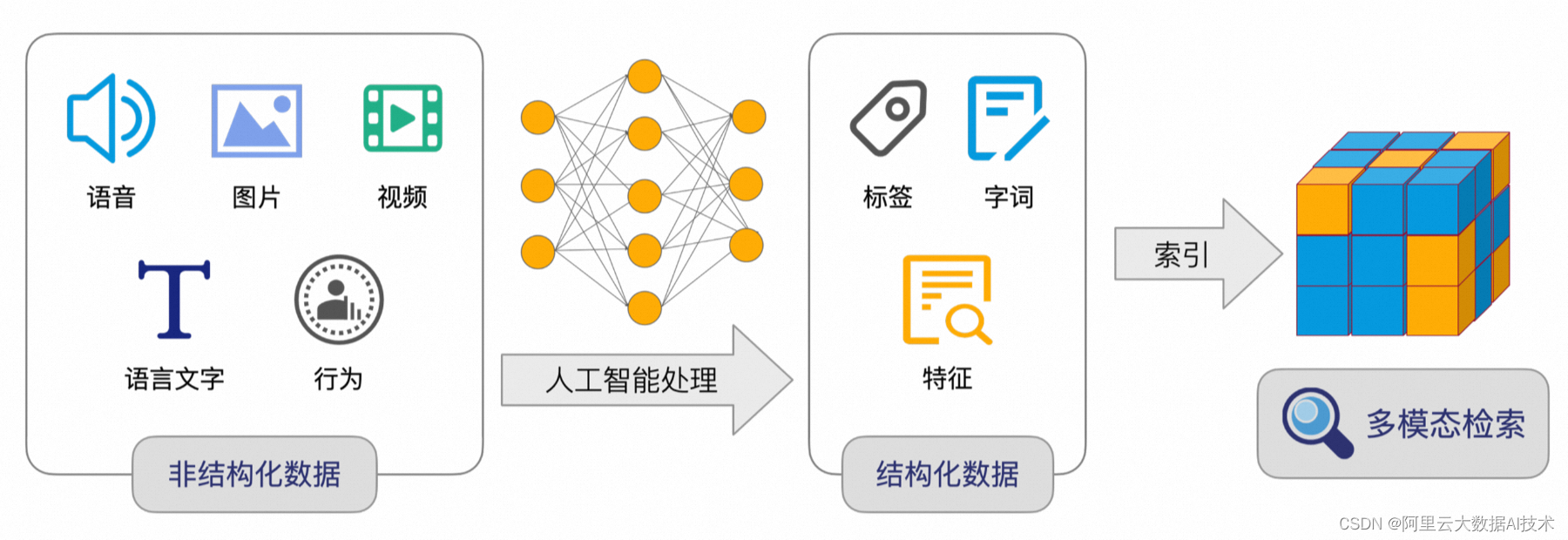
下图举例,当用户咨询“浙一医院”的相关问题时,由于数据库中不具备“浙一”关键词,所以传统分词搜索无法召回。此时引入向量分析,对人们历史语言与点击关联进行分析,建立语义相关性模型,将数据特征用高维向量表达,通过比对向量距离,发现“浙一医院”和“浙江大学医学院附属第一医院”相关性很高,可以被检索出来。
由此可见,向量可以在对话式搜索方案中,承担语义分析、返回相关数据结果的重要作用。
OpenSearch向量检索版+大模型方案简介
OpenSearch向量检索版是阿里巴巴自主研发的大规模分布式搜索引擎,其核心能力广泛应用于阿里巴巴和蚂蚁集团内众多业务。OpenSearch向量检索版专注向量检索场景,数据毫秒级查询,数据秒级更新、实时写入,支持标签+向量混合检索等能力,满足同平台下不同企业、同企业内不同业务的问答场景向量结果返回。
OpenSearch向量检索版+大模型方案整体分为2个部分,首先将业务数据进行向量化预处理,其次在线搜索服务进行检索及内容生成。
(1)业务数据预处理
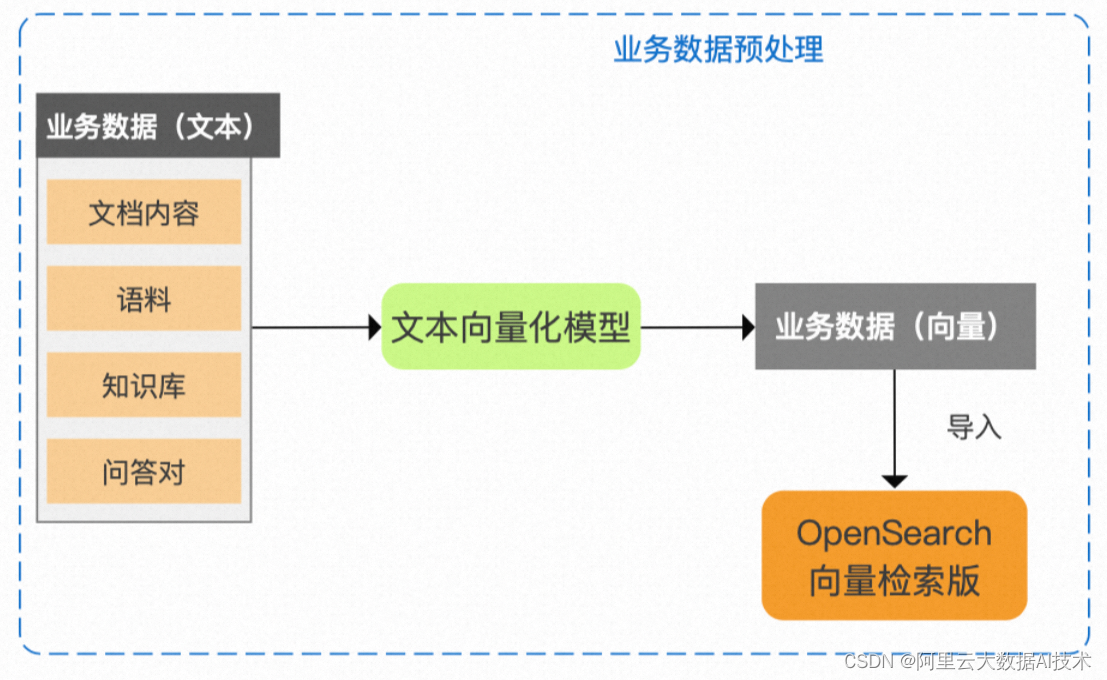
为了能够按照用户需求搜索到目标商品,需要对业务数据进行预处理,构建向量索引实现搜索功能
步骤1:将文本形式的业务数据导入文本向量化模型中,得到向量形式的业务数据
步骤2:将向量形式的业务数据导入到OpenSearch向量检索版中,构建向量索引
(2)搜索问答在线服务
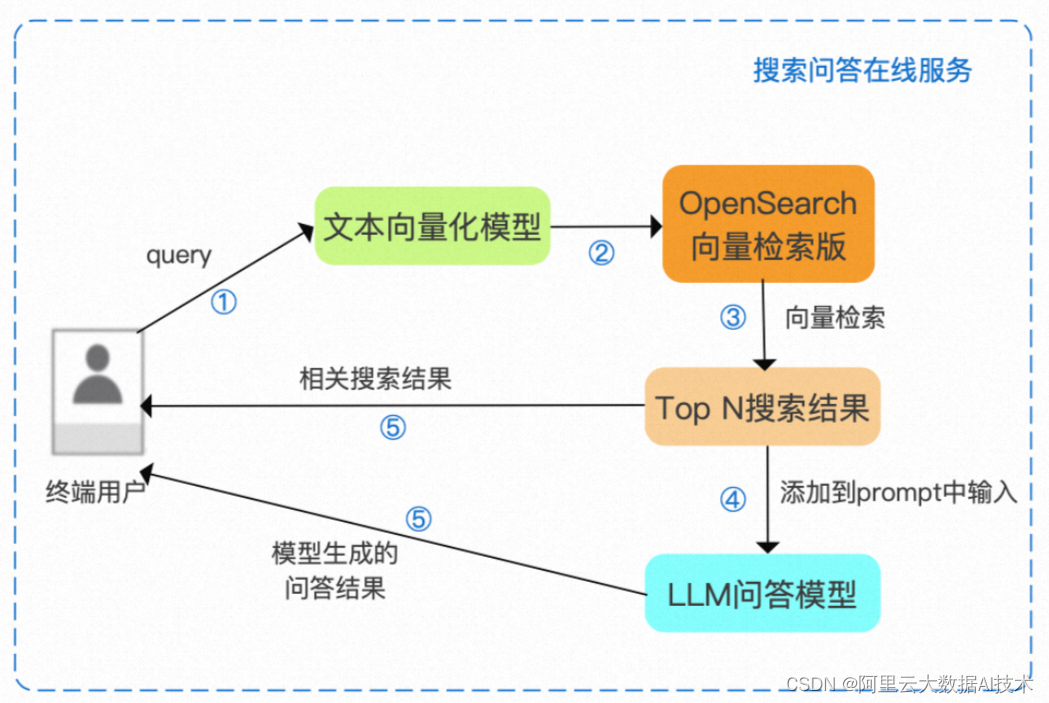
实现搜索功能后,结合Top N搜索结果,基于LLM问答模型返回搜索问答结果
步骤1:将终端用户输入的query输入文本向量化模型,得到向量形式的用户query
步骤2:将向量形式的用户query输入OpenSearch向量检索版
步骤3:使用OpenSearch向量检索版内置的向量检索引擎得到业务数据中的Top N搜索结果
步骤4:将Top N搜索结果整合作为prompt,输入LLM问答模型
步骤5:将问答模型生成的问答结果和向量检索得到的搜索结果返回给终端用户
(3)效果展示
下图为将OpenSearch产品文档作为业务数据,使用本方案构建的对话式搜索效果展示。

OpenSearch向量检索版+大模型方案,有哪些优势?
(1)高性能:自研的高性能向量检索引擎
- 大模型场景下,向量维度普遍较高,对性能成本要求更高
- OpenSearch向量检索版支持千亿数据毫秒级响应,实时数据更新秒级可见
- OpenSearch向量检索版的检索性能优于开源向量搜索引擎数倍,在高QPS场景下召回率明显优于开源向量搜索引擎
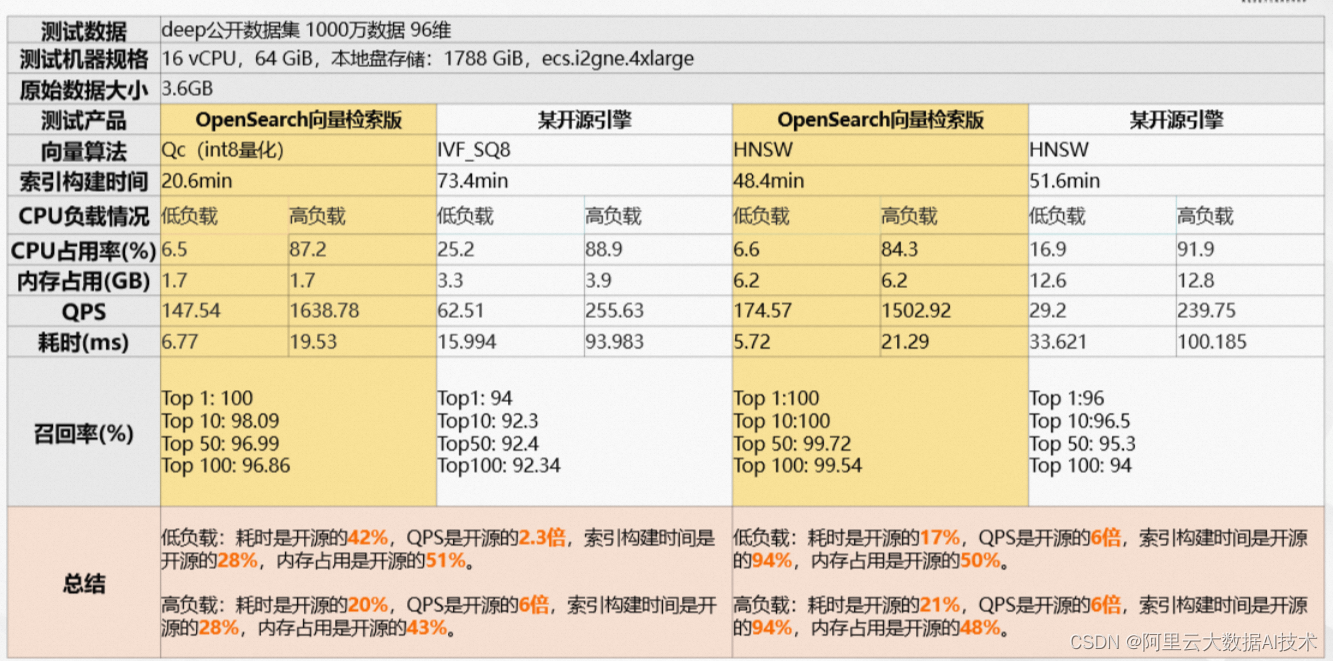
OpenSearch向量检索版VS开源引擎性能:中数据场景
OpenSearch向量检索版VS开源引擎性能:大数据场景
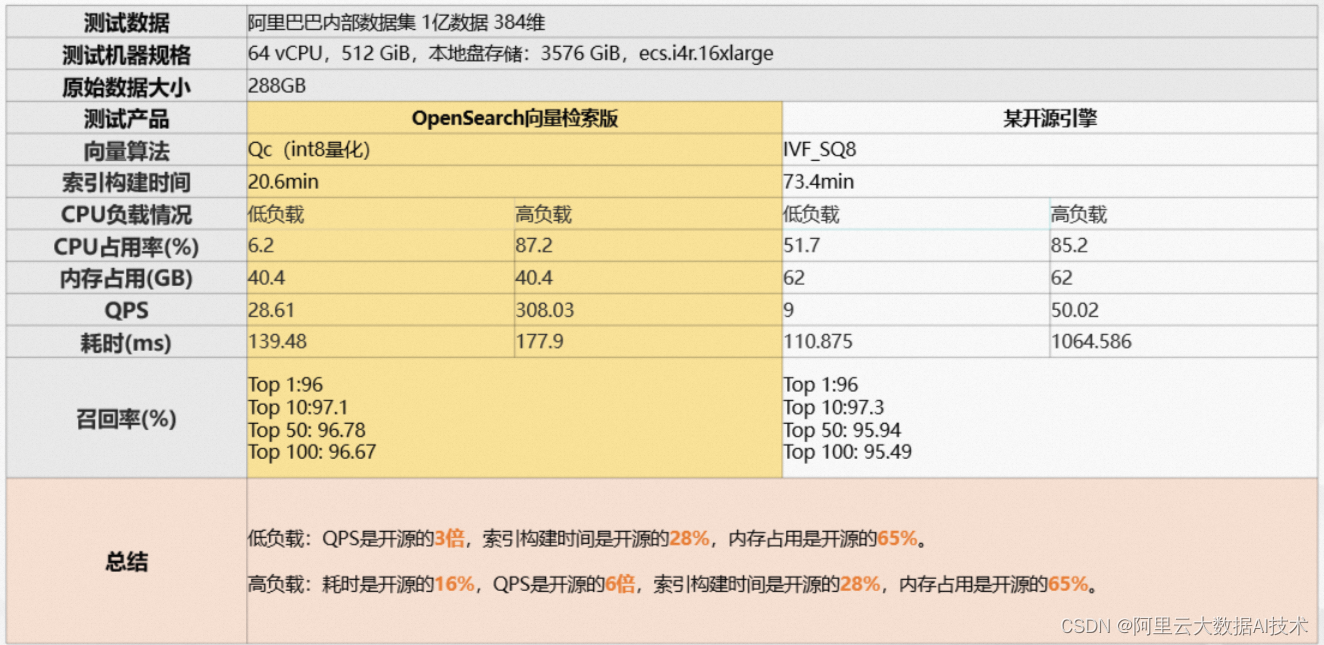
上述数据来源阿里巴巴智能引擎事业部团队,2022年11月
(2)低成本:采用多种方式优化存储成本,减少资源消耗
- 数据压缩:可将原始数据转化为float形式存储,并再采用zstd等高效算法进行数据压缩,实现存储成本优化
- 精细索引结构设计:针对不容类型索引,可采用不同优化策略,降低索引大小
- 非全内存加载:可以使用mmap非lock的形式加载索引,有效降低内存开销
- 引擎优势:OpenSearch向量检索版引擎本身具备构建索引大小、GPU资源耗用的优势,同等数据条件下,OpenSearch向量检索版内存占用仅为开源向量检索引擎的50% 左右
(3)具备丰富的向量检索能力
- 支持HNSW、QC、Linear等多种向量检索算法
- 支持标签、文本倒排索引、向量索引的混合检索

- 支持按表达式过滤,边过滤边检索

- Query中支持设置,相似度阈值、扫描返回的节点数等参数,配置灵活
(4)海量数据支持,应对业务扩张
- 支持大规模向量快速导入与索引构建,单节点 348维 1亿向量,通过配置优化,可在3.5小时内完成全量构建
- 支持数据动态更新、即增即查、自动索引重建
- 支持数据水平扩展
(5)可灵活、快速搭建企业专属对话式搜索
- 稳定可靠:使用客户业务数据而非公开数据进行内容生成,输出结果更加稳定、可靠
- 交互升级:既能为客户返回对话式检索结果,也可以作为传统检索,返回TOP结果,更灵活应对各种业务场景
- 流式输出:向量检索之后的LLM交互通常耗时较长,OpenSearch支持流式输出,缓解等待时间过长的体验问题
产品配置流程
- 第一次开通阿里云账号并登录控制台,您需先创建AK和SK
- 产品支持MaxCompute数据源、API数据源,您需提前准备向量数据(后续产品将集成文本embedding服务,可关注产品更新公告)
- 购买OpenSearch向量检索版实例,系统自动部署与购买规格一致的空集群,您需为该集群「配置数据源、配置索引结构、索引重建」,完成向量数据导入与索引构建之后,才可正常搜索
- 在控制台查询测试页面或通过API/SDK,进行向量搜索效果测试
- 下载OpenSearch大模型结合工具,并配置大模型相关信息(用户可通过简单调整结合工具代码,自行选择第三方大模型结合使用)
- 启动对话式搜索服务
更多使用说明参考: https://help.aliyun.com/document_detail/2341640.html
特别提醒:本解决方案中的“开源向量模型”、“大模型”等来自第三方(合称“第三方模型”)。阿里云无法保证第三方模型合规、准确,也不对第三方模型本身、及您使用第三方模型的行为和结果等承担任何责任。请您在访问和使用前慎重考虑。此外我们也提醒您,第三方模型附有“开源许可证”、“License”等协议,您应当仔细阅读并严格遵守这些协议的约定。
欢迎有高质量搜索效果需求的技术同学测试体验~
专家咨询问卷:https://page.aliyun.com/form/act1204394004/index.htm