NLP 学习笔记十-simple RNN+attention(注意力机制)
感兴趣的伙伴,看这个笔记,最好从头开始看哈,而且我的笔记,其实不面向零基础,最好有过一些实践经历的来看最好。
紧接上一回,我们谈到seq2seq模型解决用于机器翻译的问题。其中seq其实是采用lstm作为自己的基础记忆网络实现的,当然也可以用RNN实现实现seq2seq模型。
如下图,下图是使用simple RNN实现seq2seq模型的一个例子。和之前lstm是一个原理,比如我们要实现英文到德语的翻译,那么可以先将英语文本的字符进行onehot编码,编码成一个个的向量,然后先经过一个simple RNN模型的信息提取,也就是下图的Encoder RNN模型,之后将最终提取的信息结合要翻译的德语文本,输入下一个simple RNN模型,这个simple RNN模型也就是Decoder RNN模型。
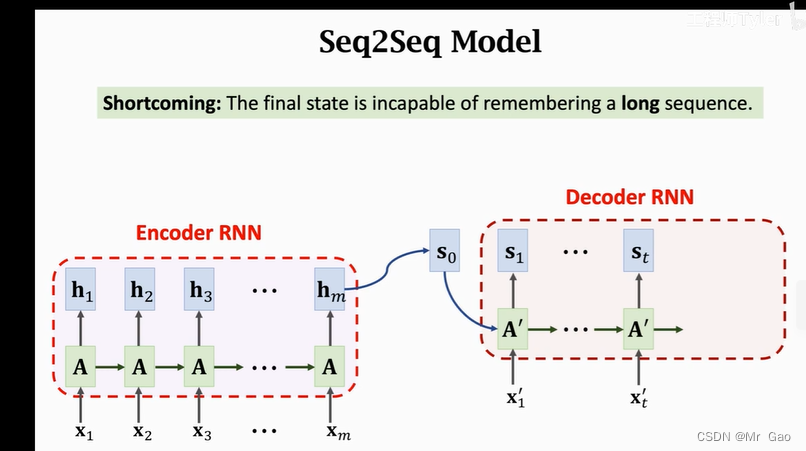
后来人们发现,无论是使用lstm模型还是simple RNN模型实现的seq2seq模型在输入文本变长之后,慢慢的翻译性能反而会下降:
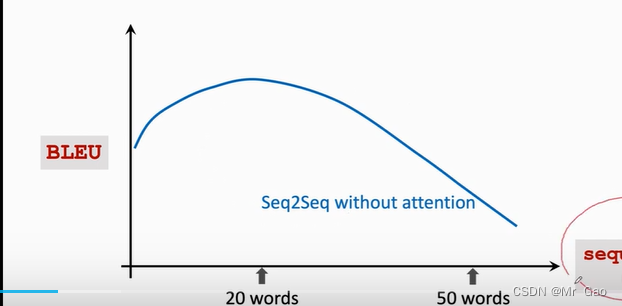
lstm模型要好一点,这是因为,随着文本输入的变成,seq2seq模型都开始遗忘开始输入的信息。所以人们考虑了使用注意力机制。
注意力机制的原理就是原本我们是不是将
s
0
s_0
s0作为decoder模型的输入吗,现在我们取
s
=
w
1
∗
h
1
+
w
2
∗
h
2
+
w
3
∗
h
3
+
w
4
∗
h
4
+
.
.
.
.
.
+
w
n
∗
h
n
s=w_1*h_1+w_2*h_2+w_3*h_3+w_4*h_4+.....+w_n*h_n
s=w1∗h1+w2∗h2+w3∗h3+w4∗h4+.....+wn∗hn作为decoder模型的输入,也就是去每次simple RNN模型的单元输出加权结构作为
s
0
s_0
s0。
现在问题就在于w_1怎么求解了:

上图的
α
\alpha
α也就是我们之前说的
w
w
w,即权重值,其实原理就是对各个
h
i
h_i
hi进行一个权重处理,权重大的会更重要,权重小重要性会低一点,这个方法,其实应该在各个领域中都用到,因为我认为加上科学的注意力机制可能不能使实验结果变好,但是最起码应该不会变坏。