由于现在Web已经部署到Linux上了,以前在Windows上导出dbf通过oledb执行sql生成dbf的路径已经不可用了,加上需要安装dataaccess驱动也麻烦,为此换了fastdbf生成dbf文件。
首先还算顺利,开始就碰到中文乱码问题,下载源码看代码解决了。最近碰到一个医院导出的dbf在Whonet软件死活就是报不是有效的dbf文件。我自己又用dbfview打开看了也没问题,用wps打开也没问题。当时把问题归结为是他的Whonet软件太老了,可能不支持新点的dbf文件,就没管这个事了。
昨天又有一个医院也是一样的报下图错误:
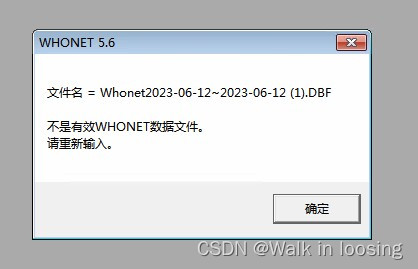
我就是意识到这应该不是用户环境问题,可能还是新导出方式导出的文件有点差异。但是Whonet的代码对我又是个黑盒,也不可能有开发配合我排查这问题,怎么办呢?
为此进行下面测试缩小范围:
1.在vs运行的Windows网站导出dbf测试,排查是否是Linux环境下的问。
2.测试Windows导出两条没问题,多了有问题后。用wps修改保存后测试是否有问题。
3.wps修改保存后没问题和wps修改后的文件比对,借助notepad++的插件HexEditer比对二进制差异,如下图:
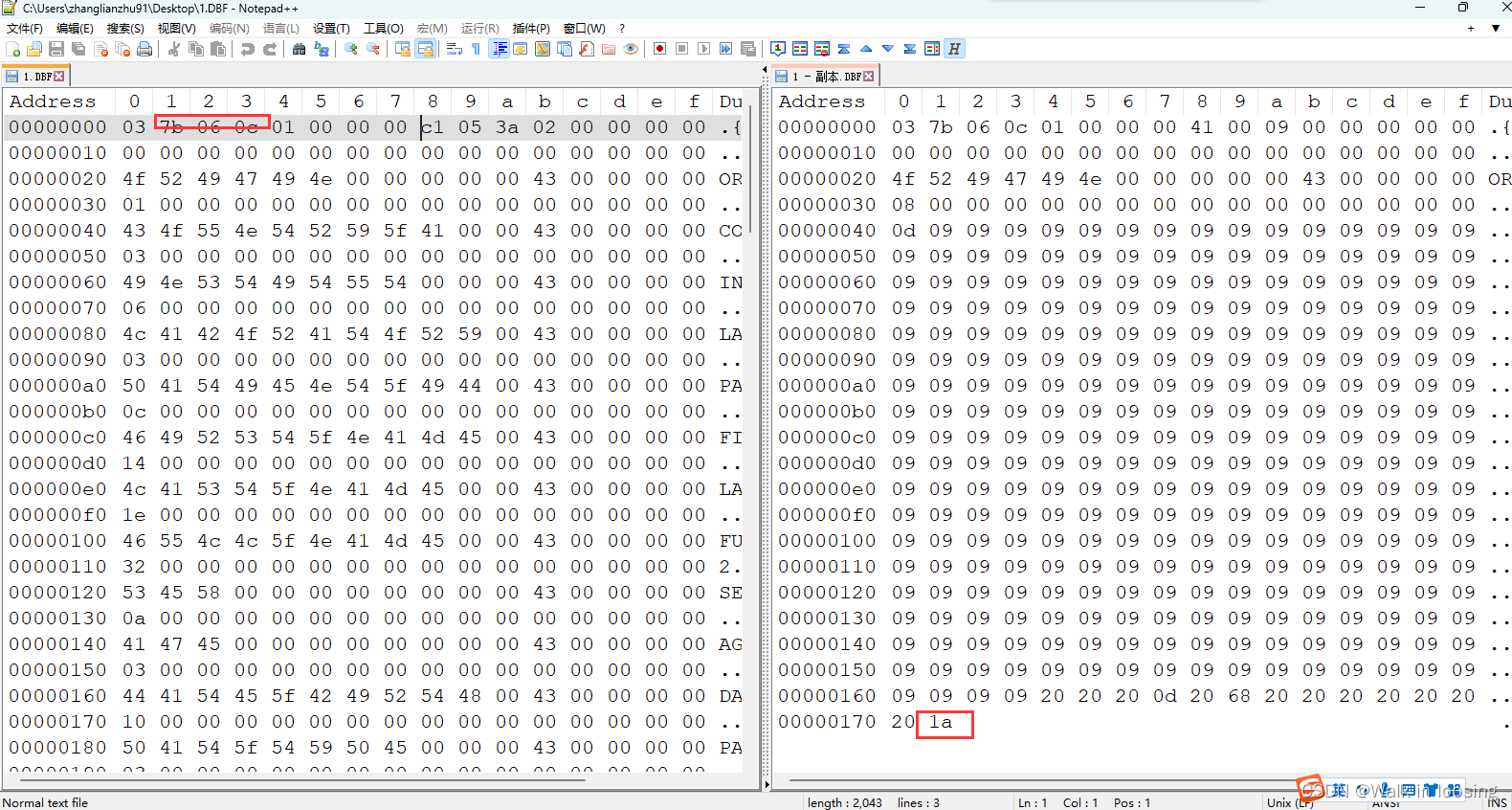
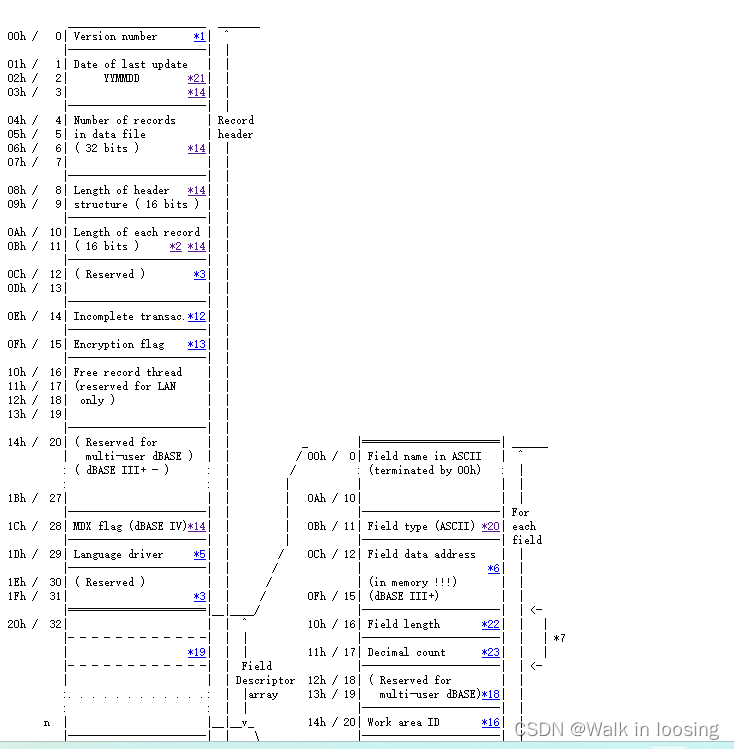
发现少了一个1a结尾字节,还有第二个自己存的年不对。然后从下面sbase官网看dbf文件格式文档:
dbf格式文档
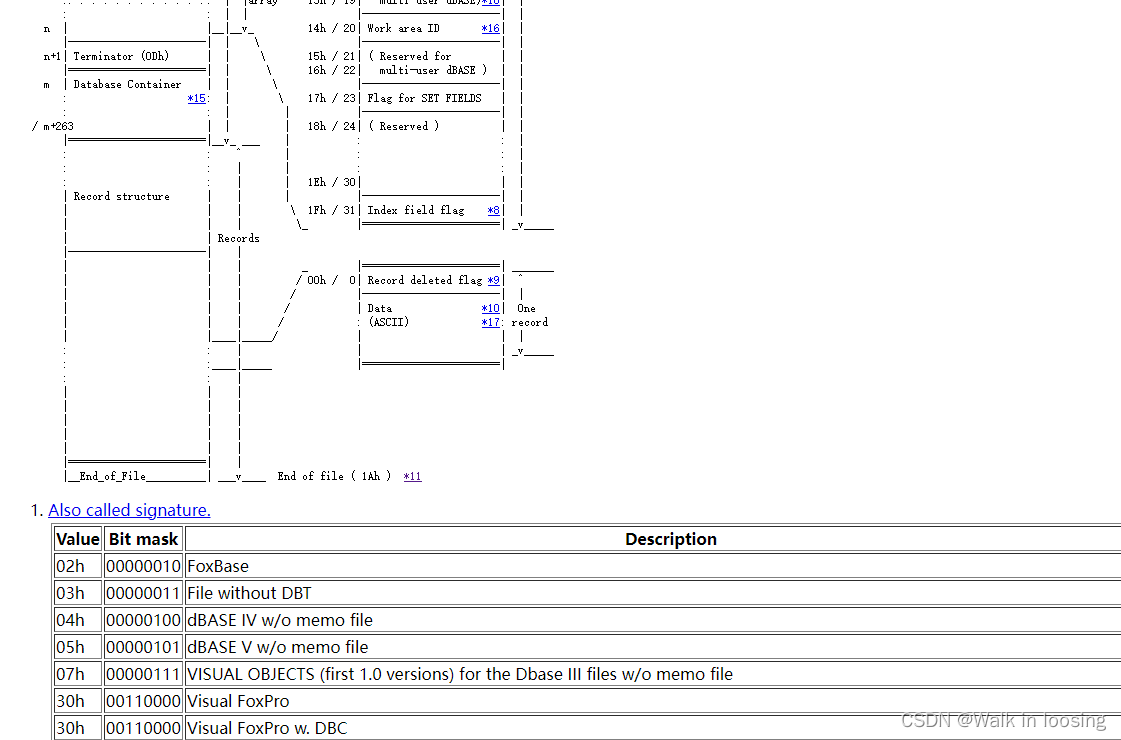
折腾一个下午比较懵,晚上回家又从9点梳理到11点总算理清了:
第0个字节表示当前的DBF版本信息(固定就行)
该文件的值是十六进制’03’,表示是FoxBASE+/Dbase III plus, no memo
1~3字节,表示最新的更新日期,按照YYMMDD格式**(FastDBF存的年默认是错误的,算成负数了)**
第一个字节的值 = 保存时的年 - 1900
第二个字节的值 = 保存时的月
第三个字节的值 = 保存时的日
该文件的第一个字节是十六进制74,对应十进制116,116+1900正好等于当前的年2016
第二个字节是十六进制07,对应十进制07,第三个字节是03,正好今天是7月3日
4~7字节,Int32类型,表示DBF文件中有多少条记录
可以看到值是02,正好当前文件确实只有两条记录
8~9,Int16类型,表示当前DBF的文件头占用的字节长度
该文件对应的值是十六进制的A1,对应十进制161
10~11,Int16类型,表示一条记录中的字节长度,即每行数据所占的长度
该文件的值是十六进制数3A,对应十进制的58
创建该文件时,一共4个字段,分别长度是20、8、8、21
计算4个列的长度和是57,比58少1
多出来的一个字节是每条记录最开始的特殊标志字节
12~13,2个字节,保留字节,用于以后添加新的说明性信息时使用,这里用0来填写
14,1个字节,表示未完成的操作
15,1个字节,dBASE IV编密码标记
16~27,12个字节,保留字节用于多用户处理时使用
28,1个字节,DBF文件的MDX标识
创建一个DBF表时,若使用MDX格式的索引文件,则DBF表头中该字节就自动被设置一个标志
当你下次试图重新打开这个DBF表的时候,数据引擎会自动识别这个标识
如果此标示为真,则数据引擎将试图打开相应MDX文件
29,1个字节,页码标记
30~31,2个字节,保留字节,用于以后添加新的说明性信息时使用,这里用0来填写。
32~N(x * 32),这段长度由表格中的列数(即字段数)决定
每个字段的长度为32,如果有x列,则占用的长度为x * 32
这每32个字节里面又按其规则填写每个字段的名称、类型等信息
N+1,1个字节,作为字段定义的终止标志,值为0x0D
然后每个字段的定义是32个字节,0-10存名称,不足的后面设置0.所以DBF列名最长11个字母。11位置存字段的数据类型,C字符、N数字、D日期、B二进制、等。12-15保留字节,用于以后添加新的说明性信息时使用,默认为0。16字段的长度,表示该字段对应的值在后面的记录中所占的长度。17字段的精度。18-19保留字节,用于以后添加新的说明性信息时使用,默认为0。20工作区ID。21-31保留字节,用于以后添加新的说明性信息时使用,默认为0。
所以整体的就是:
03 年 月 日 行 行 行 头 头 总 总 空 空 空 空 空 空 空 空 空 空 空 空 空 空 空 空 空 空 空
1列名称撑到11位 类 空 空 空 空 长 精 空 空 空 空 空 空 空 空 空 空 空 空 空 空
2列名称撑到11位 类 空 空 空 空 长 精 空 空 空 空 空 空 空 空 空 空 空 空 空 空
3列名称撑到11位 类 空 空 空 空 长 精 空 空 空 空 空 空 空 空 空 空 空 空 空 空
4列名称撑到11位 类 空 空 空 空 长 精 空 空 空 空 空 空 空 空 空 空 空 空 空 空
0D标识头结尾
1按列长度组装的数据,如1234列分别为1,8,10,50那么每行数据占69字节,每列字符位数不够后面存0
2按列长度组装的数据,如1234列分别为1,8,10,50那么每行数据占69字节,每列字符位数不够后面存0
3按列长度组装的数据,如1234列分别为1,8,10,50那么每行数据占69字节,每列字符位数不够后面存0
4按列长度组装的数据,如1234列分别为1,8,10,50那么每行数据占69字节,每列字符位数不够后面存0
5按列长度组装的数据,如1234列分别为1,8,10,50那么每行数据占69字节,每列字符位数不够后面存0
6按列长度组装的数据,如1234列分别为1,8,10,50那么每行数据占69字节,每列字符位数不够后面存0
1A结尾符
行的3个字节是int32记录的有多少行数据。
头的两个字节是int16记录的头的长度,从开始到0D的字节数。需要根据有多少列而定,每列定义占32个。长度等于固定长度+列数x32
总的两个自己是int16记录的总的字节长度,从开始到结束。长度等于头长度+行数x所有列长度和
按要求把fastdbf输出不对的部分修复后测试感觉应该好了。然而还是报格式不对,这里就想到把DBF当数据库用列名需要符合表列名要求。既:以字母开头,只能带数字和下划线,长度不能大于11.就把fastdbf的添加列方法按要求卡了一下,再导出测试成功。
修改的类:
DbfFile
///
/// Author: Ahmed Lacevic
/// Date: 12/1/2007
/// Desc: This class represents a DBF file. You can create, open, update and save DBF files using this class and supporting classes.
/// Also, this class supports reading/writing from/to an internet forward only type of stream!
///
/// Revision History:
/// -----------------------------------
/// Author:
/// Date:
/// Desc:
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
namespace SocialExplorer.IO.FastDBF
{
/// <summary>
/// This class represents a DBF file. You can create new, open, update and save DBF files using this class and supporting classes.
/// Also, this class supports reading/writing from/to an internet forward only type of stream!
/// </summary>
/// <remarks>
/// TODO: add end of file byte '0x1A' !!!
/// We don't relly on that byte at all, and everything works with or without that byte, but it should be there by spec.
/// </remarks>
public class DbfFile
{
/// <summary>
/// Helps read/write dbf file header information.
/// </summary>
protected DbfHeader _header;
/// <summary>
/// flag that indicates whether the header was written or not...
/// </summary>
protected bool _headerWritten = false;
/// <summary>
/// Streams to read and write to the DBF file.
/// </summary>
protected Stream _dbfFile = null;
protected BinaryReader _dbfFileReader = null;
protected BinaryWriter _dbfFileWriter = null;
/// <summary>
/// By default use windows 1252 code page encoding.
/// </summary>
private Encoding encoding = Encoding.Default;
/// <summary>
/// File that was opened, if one was opened at all.
/// </summary>
protected string _fileName = "";
/// <summary>
/// Number of records read using ReadNext() methods only. This applies only when we are using a forward-only stream.
/// mRecordsReadCount is used to keep track of record index. With a seek enabled stream,
/// we can always calculate index using stream position.
/// </summary>
protected long _recordsReadCount = 0;
/// <summary>
/// keep these values handy so we don't call functions on every read.
/// </summary>
protected bool _isForwardOnly = false;
protected bool _isReadOnly = false;
[Obsolete]
public DbfFile()
: this(Encoding.Default)
{
}
public DbfFile(Encoding encoding)
{
this.encoding = encoding;
_header = new DbfHeader(encoding);
}
/// <summary>
/// Open a DBF from a FileStream. This can be a file or an internet connection stream. Make sure that it is positioned at start of DBF file.
/// Reading a DBF over the internet we can not determine size of the file, so we support HasMore(), ReadNext() interface.
/// RecordCount information in header can not be trusted always, since some packages store 0 there.
/// </summary>
/// <param name="ofs"></param>
public void Open(Stream ofs)
{
if (_dbfFile != null)
Close();
_dbfFile = ofs;
_dbfFileReader = null;
_dbfFileWriter = null;
if (_dbfFile.CanRead)
_dbfFileReader = new BinaryReader(_dbfFile, encoding);
if (_dbfFile.CanWrite)
_dbfFileWriter = new BinaryWriter(_dbfFile, encoding);
//reset position
_recordsReadCount = 0;
//assume header is not written
_headerWritten = false;
//read the header
if (ofs.CanRead)
{
//try to read the header...
try
{
_header.Read(_dbfFileReader);
_headerWritten = true;
}
catch (EndOfStreamException)
{
//could not read header, file is empty
_header = new DbfHeader(encoding);
_headerWritten = false;
}
}
if (_dbfFile != null)
{
_isReadOnly = !_dbfFile.CanWrite;
_isForwardOnly = !_dbfFile.CanSeek;
}
}
/// <summary>
/// Open a DBF file or create a new one.
/// </summary>
/// <param name="sPath">Full path to the file.</param>
/// <param name="mode"></param>
public void Open(string sPath, FileMode mode, FileAccess access, FileShare share)
{
_fileName = sPath;
Open(File.Open(sPath, mode, access, share));
}
/// <summary>
/// Open a DBF file or create a new one.
/// </summary>
/// <param name="sPath">Full path to the file.</param>
/// <param name="mode"></param>
public void Open(string sPath, FileMode mode, FileAccess access)
{
_fileName = sPath;
Open(File.Open(sPath, mode, access));
}
/// <summary>
/// Open a DBF file or create a new one.
/// </summary>
/// <param name="sPath">Full path to the file.</param>
/// <param name="mode"></param>
public void Open(string sPath, FileMode mode)
{
_fileName = sPath;
Open(File.Open(sPath, mode));
}
/// <summary>
/// Creates a new DBF 4 file. Overwrites if file exists! Use Open() function for more options.
/// </summary>
/// <param name="sPath"></param>
public void Create(string sPath)
{
Open(sPath, FileMode.Create, FileAccess.ReadWrite);
_headerWritten = false;
}
/// <summary>
/// 16进制字符串转byte数组
/// </summary>
/// <param name="hexString">16进制字符</param>
/// <returns></returns>
public static byte[] ByteArrayToHexString(string hexString)
{
//将16进制秘钥转成字节数组
var byteArray = new byte[hexString.Length / 2];
for (var x = 0; x < byteArray.Length; x++)
{
var i = Convert.ToInt32(hexString.Substring(x * 2, 2), 16);
byteArray[x] = (byte)i;
}
return byteArray;
}
/// <summary>
/// Update header info, flush buffers and close streams. You should always call this method when you are done with a DBF file.
/// </summary>
public void Close()
{
//try to update the header if it has changed
//------------------------------------------
if (_header.IsDirty)
WriteHeader();
//Empty header...
//--------------------------------
_header = new DbfHeader(encoding);
_headerWritten = false;
//reset current record index
//--------------------------------
_recordsReadCount = 0;
if (_dbfFile != null)
{
_dbfFile.Seek(_dbfFile.Length, SeekOrigin.Begin);
//1a结尾
_dbfFile.Write(ByteArrayToHexString("1A"));
}
//Close streams...
//--------------------------------
if (_dbfFileWriter != null)
{
_dbfFileWriter.Flush();
_dbfFileWriter.Close();
}
if (_dbfFileReader != null)
_dbfFileReader.Close();
if (_dbfFile != null)
{
_dbfFile.Close();
_dbfFile.Dispose();
}
//set streams to null
//--------------------------------
_dbfFileReader = null;
_dbfFileWriter = null;
_dbfFile = null;
_fileName = "";
}
/// <summary>
/// Returns true if we can not write to the DBF file stream.
/// </summary>
public bool IsReadOnly
{
get
{
return _isReadOnly;
/*
if (mDbfFile != null)
return !mDbfFile.CanWrite;
return true;
*/
}
}
/// <summary>
/// Returns true if we can not seek to different locations within the file, such as internet connections.
/// </summary>
public bool IsForwardOnly
{
get
{
return _isForwardOnly;
/*
if(mDbfFile!=null)
return !mDbfFile.CanSeek;
return false;
*/
}
}
/// <summary>
/// Returns the name of the filestream.
/// </summary>
public string FileName
{
get
{
return _fileName;
}
}
/// <summary>
/// Read next record and fill data into parameter oFillRecord. Returns true if a record was read, otherwise false.
/// </summary>
/// <param name="oFillRecord"></param>
/// <returns></returns>
public bool ReadNext(DbfRecord oFillRecord)
{
//check if we can fill this record with data. it must match record size specified by header and number of columns.
//we are not checking whether it comes from another DBF file or not, we just need the same structure. Allow flexibility but be safe.
if (oFillRecord.Header != _header && (oFillRecord.Header.ColumnCount != _header.ColumnCount || oFillRecord.Header.RecordLength != _header.RecordLength))
throw new Exception("Record parameter does not have the same size and number of columns as the " +
"header specifies, so we are unable to read a record into oFillRecord. " +
"This is a programming error, have you mixed up DBF file objects?");
//DBF file reader can be null if stream is not readable...
if (_dbfFileReader == null)
throw new Exception("Read stream is null, either you have opened a stream that can not be " +
"read from (a write-only stream) or you have not opened a stream at all.");
//read next record...
bool bRead = oFillRecord.Read(_dbfFile);
if (bRead)
{
if (_isForwardOnly)
{
//zero based index! set before incrementing count.
oFillRecord.RecordIndex = _recordsReadCount;
_recordsReadCount++;
}
else
oFillRecord.RecordIndex = ((int)((_dbfFile.Position - _header.HeaderLength) / _header.RecordLength)) - 1;
}
return bRead;
}
/// <summary>
/// Tries to read a record and returns a new record object or null if nothing was read.
/// </summary>
/// <returns></returns>
public DbfRecord ReadNext()
{
//create a new record and fill it.
DbfRecord orec = new DbfRecord(_header);
return ReadNext(orec) ? orec : null;
}
/// <summary>
/// Reads a record specified by index into oFillRecord object. You can use this method
/// to read in and process records without creating and discarding record objects.
/// Note that you should check that your stream is not forward-only! If you have a forward only stream, use ReadNext() functions.
/// </summary>
/// <param name="index">Zero based record index.</param>
/// <param name="oFillRecord">Record object to fill, must have same size and number of fields as thid DBF file header!</param>
/// <remarks>
/// <returns>True if read a record was read, otherwise false. If you read end of file false will be returned and oFillRecord will NOT be modified!</returns>
/// The parameter record (oFillRecord) must match record size specified by the header and number of columns as well.
/// It does not have to come from the same header, but it must match the structure. We are not going as far as to check size of each field.
/// The idea is to be flexible but safe. It's a fine balance, these two are almost always at odds.
/// </remarks>
public bool Read(long index, DbfRecord oFillRecord)
{
//check if we can fill this record with data. it must match record size specified by header and number of columns.
//we are not checking whether it comes from another DBF file or not, we just need the same structure. Allow flexibility but be safe.
if (oFillRecord.Header != _header && (oFillRecord.Header.ColumnCount != _header.ColumnCount || oFillRecord.Header.RecordLength != _header.RecordLength))
throw new Exception("Record parameter does not have the same size and number of columns as the " +
"header specifies, so we are unable to read a record into oFillRecord. " +
"This is a programming error, have you mixed up DBF file objects?");
//DBF file reader can be null if stream is not readable...
if (_dbfFileReader == null)
throw new Exception("ReadStream is null, either you have opened a stream that can not be " +
"read from (a write-only stream) or you have not opened a stream at all.");
//move to the specified record, note that an exception will be thrown is stream is not seekable!
//This is ok, since we provide a function to check whether the stream is seekable.
long nSeekToPosition = _header.HeaderLength + (index * _header.RecordLength);
//check whether requested record exists. Subtract 1 from file length (there is a terminating character 1A at the end of the file)
//so if we hit end of file, there are no more records, so return false;
if (index < 0 || _dbfFile.Length - 1 <= nSeekToPosition)
return false;
//move to record and read
_dbfFile.Seek(nSeekToPosition, SeekOrigin.Begin);
//read the record
bool bRead = oFillRecord.Read(_dbfFile);
if (bRead)
oFillRecord.RecordIndex = index;
return bRead;
}
public bool ReadValue(int rowIndex, int columnIndex, out string result)
{
result = String.Empty;
DbfColumn ocol = _header[columnIndex];
//move to the specified record, note that an exception will be thrown is stream is not seekable!
//This is ok, since we provide a function to check whether the stream is seekable.
long nSeekToPosition = _header.HeaderLength + (rowIndex * _header.RecordLength) + ocol.DataAddress;
//check whether requested record exists. Subtract 1 from file length (there is a terminating character 1A at the end of the file)
//so if we hit end of file, there are no more records, so return false;
if (rowIndex < 0 || _dbfFile.Length - 1 <= nSeekToPosition)
return false;
//move to position and read
_dbfFile.Seek(nSeekToPosition, SeekOrigin.Begin);
//read the value
byte[] data = new byte[ocol.Length];
_dbfFile.Read(data, 0, ocol.Length);
result = new string(encoding.GetChars(data, 0, ocol.Length));
return true;
}
/// <summary>
/// Reads a record specified by index. This method requires the stream to be able to seek to position.
/// If you are using a http stream, or a stream that can not stream, use ReadNext() methods to read in all records.
/// </summary>
/// <param name="index">Zero based index.</param>
/// <returns>Null if record can not be read, otherwise returns a new record.</returns>
public DbfRecord Read(long index)
{
//create a new record and fill it.
DbfRecord orec = new DbfRecord(_header);
return Read(index, orec) ? orec : null;
}
/// <summary>
/// Write a record to file. If RecordIndex is present, record will be updated, otherwise a new record will be written.
/// Header will be output first if this is the first record being writen to file.
/// This method does not require stream seek capability to add a new record.
/// </summary>
/// <param name="orec"></param>
public void Write(DbfRecord orec)
{
//if header was never written, write it first, then output the record
if (!_headerWritten)
WriteHeader();
//if this is a new record (RecordIndex should be -1 in that case)
if (orec.RecordIndex < 0)
{
if (_dbfFileWriter.BaseStream.CanSeek)
{
//calculate number of records in file. do not rely on header's RecordCount property since client can change that value.
//also note that some DBF files do not have ending 0x1A byte, so we subtract 1 and round off
//instead of just cast since cast would just drop decimals.
int nNumRecords = (int)Math.Round(((double)(_dbfFile.Length - _header.HeaderLength - 1) / _header.RecordLength));
if (nNumRecords < 0)
nNumRecords = 0;
orec.RecordIndex = nNumRecords;
Update(orec);
_header.RecordCount++;
}
else
{
//we can not position this stream, just write out the new record.
orec.Write(_dbfFile);
_header.RecordCount++;
}
}
else
Update(orec);
}
public void Write(DbfRecord orec, bool bClearRecordAfterWrite)
{
Write(orec);
if (bClearRecordAfterWrite)
orec.Clear();
}
/// <summary>
/// Update a record. RecordIndex (zero based index) must be more than -1, otherwise an exception is thrown.
/// You can also use Write method which updates a record if it has RecordIndex or adds a new one if RecordIndex == -1.
/// RecordIndex is set automatically when you call any Read() methods on this class.
/// </summary>
/// <param name="orec"></param>
public void Update(DbfRecord orec)
{
//if header was never written, write it first, then output the record
if (!_headerWritten)
WriteHeader();
//Check if record has an index
if (orec.RecordIndex < 0)
throw new Exception("RecordIndex is not set, unable to update record. Set RecordIndex or call Write() method to add a new record to file.");
//Check if this record matches record size specified by header and number of columns.
//Client can pass a record from another DBF that is incompatible with this one and that would corrupt the file.
if (orec.Header != _header && (orec.Header.ColumnCount != _header.ColumnCount || orec.Header.RecordLength != _header.RecordLength))
throw new Exception("Record parameter does not have the same size and number of columns as the " +
"header specifies. Writing this record would corrupt the DBF file. " +
"This is a programming error, have you mixed up DBF file objects?");
//DBF file writer can be null if stream is not writable to...
if (_dbfFileWriter == null)
throw new Exception("Write stream is null. Either you have opened a stream that can not be " +
"writen to (a read-only stream) or you have not opened a stream at all.");
//move to the specified record, note that an exception will be thrown if stream is not seekable!
//This is ok, since we provide a function to check whether the stream is seekable.
long nSeekToPosition = (long)_header.HeaderLength + (long)((long)orec.RecordIndex * (long)_header.RecordLength);
//check whether we can seek to this position. Subtract 1 from file length (there is a terminating character 1A at the end of the file)
//so if we hit end of file, there are no more records, so return false;
if (_dbfFile.Length < nSeekToPosition)
throw new Exception("Invalid record position. Unable to save record.");
//move to record start
_dbfFile.Seek(nSeekToPosition, SeekOrigin.Begin);
//write
orec.Write(_dbfFile);
}
/// <summary>
/// Save header to file. Normally, you do not have to call this method, header is saved
/// automatically and updated when you close the file (if it changed).
/// </summary>
public bool WriteHeader()
{
//update header if possible
//--------------------------------
if (_dbfFileWriter != null)
{
if (_dbfFileWriter.BaseStream.CanSeek)
{
_dbfFileWriter.Seek(0, SeekOrigin.Begin);
_header.Write(_dbfFileWriter);
_headerWritten = true;
return true;
}
else
{
//if stream can not seek, then just write it out and that's it.
if (!_headerWritten)
_header.Write(_dbfFileWriter);
_headerWritten = true;
}
}
return false;
}
/// <summary>
/// Access DBF header with information on columns. Use this object for faster access to header.
/// Remove one layer of function calls by saving header reference and using it directly to access columns.
/// </summary>
public DbfHeader Header
{
get
{
return _header;
}
}
}
}
DbfHeader
///
/// Author: Ahmed Lacevic
/// Date: 12/1/2007
/// Desc:
///
/// Revision History:
/// -----------------------------------
/// Author:
/// Date:
/// Desc:
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
namespace SocialExplorer.IO.FastDBF
{
/// <summary>
/// This class represents a DBF IV file header.
/// </summary>
///
/// <remarks>
/// DBF files are really wasteful on space but this legacy format lives on because it's really really simple.
/// It lacks much in features though.
///
///
/// Thanks to Erik Bachmann for providing the DBF file structure information!!
/// http://www.clicketyclick.dk/databases/xbase/format/dbf.html
///
/// _______________________ _______
/// 00h / 0| Version number *1| ^
/// |-----------------------| |
/// 01h / 1| Date of last update | |
/// 02h / 2| YYMMDD *21| |
/// 03h / 3| *14| |
/// |-----------------------| |
/// 04h / 4| Number of records | Record
/// 05h / 5| in data file | header
/// 06h / 6| ( 32 bits ) *14| |
/// 07h / 7| | |
/// |-----------------------| |
/// 08h / 8| Length of header *14| |
/// 09h / 9| structure ( 16 bits ) | |
/// |-----------------------| |
/// 0Ah / 10| Length of each record | |
/// 0Bh / 11| ( 16 bits ) *2 *14| |
/// |-----------------------| |
/// 0Ch / 12| ( Reserved ) *3| |
/// 0Dh / 13| | |
/// |-----------------------| |
/// 0Eh / 14| Incomplete transac.*12| |
/// |-----------------------| |
/// 0Fh / 15| Encryption flag *13| |
/// |-----------------------| |
/// 10h / 16| Free record thread | |
/// 11h / 17| (reserved for LAN | |
/// 12h / 18| only ) | |
/// 13h / 19| | |
/// |-----------------------| |
/// 14h / 20| ( Reserved for | | _ |=======================| ______
/// | multi-user dBASE ) | | / 00h / 0| Field name in ASCII | ^
/// : ( dBASE III+ - ) : | / : (terminated by 00h) : |
/// : : | | | | |
/// 1Bh / 27| | | | 0Ah / 10| | |
/// |-----------------------| | | |-----------------------| For
/// 1Ch / 28| MDX flag (dBASE IV)*14| | | 0Bh / 11| Field type (ASCII) *20| each
/// |-----------------------| | | |-----------------------| field
/// 1Dh / 29| Language driver *5| | / 0Ch / 12| Field data address | |
/// |-----------------------| | / | *6| |
/// 1Eh / 30| ( Reserved ) | | / | (in memory !!!) | |
/// 1Fh / 31| *3| | / 0Fh / 15| (dBASE III+) | |
/// |=======================|__|____/ |-----------------------| | -
/// 20h / 32| | | ^ 10h / 16| Field length *22| | |
/// |- - - - - - - - - - - -| | | |-----------------------| | | *7
/// | *19| | | 11h / 17| Decimal count *23| | |
/// |- - - - - - - - - - - -| | Field |-----------------------| | -
/// | | | Descriptor 12h / 18| ( Reserved for | |
/// :. . . . . . . . . . . .: | |array 13h / 19| multi-user dBASE)*18| |
/// : : | | |-----------------------| |
/// n | |__|__v_ 14h / 20| Work area ID *16| |
/// |-----------------------| | \ |-----------------------| |
/// n+1| Terminator (0Dh) | | \ 15h / 21| ( Reserved for | |
/// |=======================| | \ 16h / 22| multi-user dBASE ) | |
/// m | Database Container | | \ |-----------------------| |
/// : *15: | \ 17h / 23| Flag for SET FIELDS | |
/// : : | | |-----------------------| |
/// / m+263 | | | 18h / 24| ( Reserved ) | |
/// |=======================|__v_ ___ | : : |
/// : : ^ | : : |
/// : : | | : : |
/// : : | | 1Eh / 30| | |
/// | Record structure | | | |-----------------------| |
/// | | | \ 1Fh / 31| Index field flag *8| |
/// | | | \_ |=======================| _v_____
/// | | Records
/// |-----------------------| |
/// | | | _ |=======================| _______
/// | | | / 00h / 0| Record deleted flag *9| ^
/// | | | / |-----------------------| |
/// | | | / | Data *10| One
/// | | | / : (ASCII) *17: record
/// | |____|_____/ | | |
/// : : | | | _v_____
/// : :____|_____ |=======================|
/// : : |
/// | | |
/// | | |
/// | | |
/// | | |
/// | | |
/// |=======================| |
/// |__End_of_File__________| ___v____ End of file ( 1Ah ) *11
///
/// </remarks>
public class DbfHeader : ICloneable
{
/// <summary>
/// Header file descriptor size is 33 bytes (32 bytes + 1 terminator byte), followed by column metadata which is 32 bytes each.
/// </summary>
public const int FileDescriptorSize = 33;
/// <summary>
/// Field or DBF Column descriptor is 32 bytes long.
/// </summary>
public const int ColumnDescriptorSize = 32;
//type of the file, must be 03h
private const int _fileType = 0x03;
//Date the file was last updated.
private DateTime _updateDate=DateTime.Now;
//Number of records in the datafile, 32bit little-endian, unsigned
private uint _numRecords = 0;
//Length of the header structure
private ushort _headerLength = FileDescriptorSize; //empty header is 33 bytes long. Each column adds 32 bytes.
//Length of the records, ushort - unsigned 16 bit integer
private int _recordLength = 1; //start with 1 because the first byte is a delete flag
//DBF fields/columns
internal List<DbfColumn> _fields = new List<DbfColumn>();
//indicates whether header columns can be modified!
bool _locked = false;
//keeps column name index for the header, must clear when header columns change.
private Dictionary<string, int> _columnNameIndex = null;
/// <summary>
/// When object is modified dirty flag is set.
/// </summary>
bool _isDirty = false;
/// <summary>
/// mEmptyRecord is an array used to clear record data in CDbf4Record.
/// This is shared by all record objects, used to speed up clearing fields or entire record.
/// <seealso cref="EmptyDataRecord"/>
/// </summary>
private byte[] _emptyRecord = null;
public readonly Encoding encoding = Encoding.ASCII;
[Obsolete]
public DbfHeader()
{
}
public DbfHeader(Encoding encoding)
{
this.encoding = encoding;
}
/// <summary>
/// Specify initial column capacity.
/// </summary>
/// <param name="nInitialFields"></param>
public DbfHeader(int nFieldCapacity)
{
_fields = new List<DbfColumn>(nFieldCapacity);
}
/// <summary>
/// Gets header length.
/// </summary>
public ushort HeaderLength
{
get
{
return _headerLength;
}
}
/// <summary>
/// Add a new column to the DBF header.
/// </summary>
/// <param name="oNewCol"></param>
public void AddColumn(DbfColumn oNewCol)
{
//以空格和_开头的忽略
if(oNewCol.Name.StartsWith("_")|| oNewCol.Name.StartsWith(" "))
{
return;
}
//包含中分隔符忽略
if (oNewCol.Name.Contains("-"))
{
return;
}
//包含中分隔符忽略
if (oNewCol.Name.Contains("/")|| oNewCol.Name.Contains("\\") || oNewCol.Name.Contains("@") || oNewCol.Name.Contains("*") || oNewCol.Name.Contains("%") || oNewCol.Name.Contains("^") || oNewCol.Name.Contains("&"))
{
return;
}
if (oNewCol.Name.Length>0)
{
//以数字开头的忽略
if(char.IsDigit(oNewCol.Name[0]))
{
return;
}
//不以字母开头的忽略
if(!((oNewCol.Name[0]>'a'&& oNewCol.Name[0]<'z')|| (oNewCol.Name[0] > 'A' && oNewCol.Name[0] < 'Z')))
{
return;
}
}
//throw exception if the header is locked
if (_locked)
throw new InvalidOperationException("This header is locked and can not be modified. Modifying the header would result in a corrupt DBF file. You can unlock the header by calling UnLock() method.");
//since we are breaking the spec rules about max number of fields, we should at least
//check that the record length stays within a number that can be recorded in the header!
//we have 2 unsigned bytes for record length for a maximum of 65535.
if (_recordLength + oNewCol.Length > 65535)
throw new ArgumentOutOfRangeException("oNewCol", "Unable to add new column. Adding this column puts the record length over the maximum (which is 65535 bytes).");
//add the column
_fields.Add(oNewCol);
//update offset bits, record and header lengths
oNewCol._dataAddress = _recordLength;
_recordLength += oNewCol.Length;
_headerLength += ColumnDescriptorSize;
//clear empty record
_emptyRecord = null;
//set dirty bit
_isDirty = true;
_columnNameIndex = null;
}
/// <summary>
/// Create and add a new column with specified name and type.
/// </summary>
/// <param name="sName"></param>
/// <param name="type"></param>
public void AddColumn(string sName, DbfColumn.DbfColumnType type)
{
AddColumn(new DbfColumn(sName, type));
}
/// <summary>
/// Create and add a new column with specified name, type, length, and decimal precision.
/// </summary>
/// <param name="sName">Field name. Uniqueness is not enforced.</param>
/// <param name="type"></param>
/// <param name="nLength">Length of the field including decimal point and decimal numbers</param>
/// <param name="nDecimals">Number of decimal places to keep.</param>
public void AddColumn(string sName, DbfColumn.DbfColumnType type, int nLength, int nDecimals)
{
AddColumn(new DbfColumn(sName, type, nLength, nDecimals));
}
/// <summary>
/// Remove column from header definition.
/// </summary>
/// <param name="nIndex"></param>
public void RemoveColumn(int nIndex)
{
//throw exception if the header is locked
if (_locked)
throw new InvalidOperationException("This header is locked and can not be modified. Modifying the header would result in a corrupt DBF file. You can unlock the header by calling UnLock() method.");
DbfColumn oColRemove = _fields[nIndex];
_fields.RemoveAt(nIndex);
oColRemove._dataAddress = 0;
_recordLength -= oColRemove.Length;
_headerLength -= ColumnDescriptorSize;
//if you remove a column offset shift for each of the columns
//following the one removed, we need to update those offsets.
int nRemovedColLen = oColRemove.Length;
for (int i = nIndex; i < _fields.Count; i++)
_fields[i]._dataAddress -= nRemovedColLen;
//clear the empty record
_emptyRecord = null;
//set dirty bit
_isDirty = true;
_columnNameIndex = null;
}
/// <summary>
/// Look up a column index by name. NOT Case Sensitive. This is a change from previous behaviour!
/// </summary>
/// <param name="sName"></param>
public DbfColumn this[string sName]
{
get
{
int colIndex = FindColumn(sName);
if (colIndex > -1)
return _fields[colIndex];
return null;
}
}
/// <summary>
/// Returns column at specified index. Index is 0 based.
/// </summary>
/// <param name="nIndex">Zero based index.</param>
/// <returns></returns>
public DbfColumn this[int nIndex]
{
get
{
return _fields[nIndex];
}
}
/// <summary>
/// Finds a column index by using a fast dictionary lookup-- creates column dictionary on first use. Returns -1 if not found. CHANGE: not case sensitive any longer!
/// </summary>
/// <param name="sName">Column name (case insensitive comparison)</param>
/// <returns>column index (0 based) or -1 if not found.</returns>
public int FindColumn(string sName)
{
if (_columnNameIndex == null)
{
_columnNameIndex = new Dictionary<string, int>(_fields.Count);
//create a new index
for (int i = 0; i < _fields.Count; i++)
{
_columnNameIndex.Add(_fields[i].Name.ToUpper(), i);
}
}
int columnIndex;
if (_columnNameIndex.TryGetValue(sName.ToUpper(), out columnIndex))
return columnIndex;
return -1;
}
/// <summary>
/// Returns an empty data record. This is used to clear columns
/// </summary>
/// <remarks>
/// The reason we put this in the header class is because it allows us to use the CDbf4Record class in two ways.
/// 1. we can create one instance of the record and reuse it to write many records quickly clearing the data array by bitblting to it.
/// 2. we can create many instances of the record (a collection of records) and have only one copy of this empty dataset for all of them.
/// If we had put it in the Record class then we would be taking up twice as much space unnecessarily. The empty record also fits the model
/// and everything is neatly encapsulated and safe.
///
/// </remarks>
protected internal byte[] EmptyDataRecord
{
get { return _emptyRecord ?? (_emptyRecord = encoding.GetBytes("".PadLeft(_recordLength, ' ').ToCharArray())); }
}
/// <summary>
/// Returns Number of columns in this dbf header.
/// </summary>
public int ColumnCount
{
get { return _fields.Count; }
}
/// <summary>
/// Size of one record in bytes. All fields + 1 byte delete flag.
/// </summary>
public int RecordLength
{
get
{
return _recordLength;
}
}
/// <summary>
/// Get/Set number of records in the DBF.
/// </summary>
/// <remarks>
/// The reason we allow client to set RecordCount is beause in certain streams
/// like internet streams we can not update record count as we write out records, we have to set it in advance,
/// so client has to be able to modify this property.
/// </remarks>
public uint RecordCount
{
get
{
return _numRecords;
}
set
{
_numRecords = value;
//set the dirty bit
_isDirty = true;
}
}
/// <summary>
/// Get/set whether this header is read only or can be modified. When you create a CDbfRecord
/// object and pass a header to it, CDbfRecord locks the header so that it can not be modified any longer.
/// in order to preserve DBF integrity.
/// </summary>
internal bool Locked
{
get
{
return _locked;
}
set
{
_locked = value;
}
}
/// <summary>
/// Use this method with caution. Headers are locked for a reason, to prevent DBF from becoming corrupt.
/// </summary>
public void Unlock()
{
_locked = false;
}
/// <summary>
/// Returns true when this object is modified after read or write.
/// </summary>
public bool IsDirty
{
get
{
return _isDirty;
}
set
{
_isDirty = value;
}
}
/// <summary>
/// Encoding must be ASCII for this binary writer.
/// </summary>
/// <param name="writer"></param>
/// <remarks>
/// See class remarks for DBF file structure.
/// </remarks>
public void Write(BinaryWriter writer)
{
//write the header
// write the output file type.
writer.Write((byte)_fileType);
//Update date format is YYMMDD, which is different from the column Date type (YYYYDDMM)
writer.Write((byte)(_updateDate.Year - 1900));
writer.Write((byte)_updateDate.Month);
writer.Write((byte)_updateDate.Day);
// write the number of records in the datafile. (32 bit number, little-endian unsigned)
writer.Write(_numRecords);
// write the length of the header structure.
writer.Write(_headerLength);
// write the length of a record
writer.Write((ushort)_recordLength);
// write the reserved bytes in the header
for (int i = 0; i < 20; i++)
writer.Write((byte)0);
// write all of the header records
byte[] byteReserved = new byte[14]; //these are initialized to 0 by default.
foreach (DbfColumn field in _fields)
{
char[] cname = field.Name.PadRight(11, (char)0).ToCharArray();
writer.Write(cname);
// write the field type
writer.Write((char)field.ColumnTypeChar);
// write the field data address, offset from the start of the record.
//dBASE III+才支持
//writer.Write(field.DataAddress);
writer.Write(0);
// write the length of the field.
// if char field is longer than 255 bytes, then we use the decimal field as part of the field length.
if (field.ColumnType == DbfColumn.DbfColumnType.Character && field.Length > 255)
{
//treat decimal count as high byte of field length, this extends char field max to 65535
writer.Write((ushort)field.Length);
}
else
{
// write the length of the field.
writer.Write((byte)field.Length);
// write the decimal count.
writer.Write((byte)field.DecimalCount);
}
// write the reserved bytes.
writer.Write(byteReserved);
}
// write the end of the field definitions marker
writer.Write((byte)0x0D);
writer.Flush();
//clear dirty bit
_isDirty = false;
//lock the header so it can not be modified any longer,
//we could actually postpond this until first record is written!
_locked = true;
}
/// <summary>
/// Read header data, make sure the stream is positioned at the start of the file to read the header otherwise you will get an exception.
/// When this function is done the position will be the first record.
/// </summary>
/// <param name="reader"></param>
public void Read(BinaryReader reader)
{
// type of reader.
int nFileType = reader.ReadByte();
if (nFileType != 0x03)
throw new NotSupportedException("Unsupported DBF reader Type " + nFileType);
// parse the update date information.
int year = (int)reader.ReadByte();
int month = (int)reader.ReadByte();
int day = (int)reader.ReadByte();
_updateDate = new DateTime(year + 1900, month, day);
// read the number of records.
_numRecords = reader.ReadUInt32();
// read the length of the header structure.
_headerLength = reader.ReadUInt16();
// read the length of a record
_recordLength = reader.ReadInt16();
// skip the reserved bytes in the header.
reader.ReadBytes(20);
// calculate the number of Fields in the header
int nNumFields = (_headerLength - FileDescriptorSize) / ColumnDescriptorSize;
//offset from start of record, start at 1 because that's the delete flag.
int nDataOffset = 1;
// read all of the header records
_fields = new List<DbfColumn>(nNumFields);
for (int i = 0; i < nNumFields; i++)
{
// read the field name
char[] buffer = new char[11];
buffer = reader.ReadChars(11);
string sFieldName = new string(buffer);
int nullPoint = sFieldName.IndexOf((char)0);
if (nullPoint != -1)
sFieldName = sFieldName.Substring(0, nullPoint);
//read the field type
char cDbaseType = (char)reader.ReadByte();
// read the field data address, offset from the start of the record.
int nFieldDataAddress = reader.ReadInt32();
//read the field length in bytes
//if field type is char, then read FieldLength and Decimal count as one number to allow char fields to be
//longer than 256 bytes (ASCII char). This is the way Clipper and FoxPro do it, and there is really no downside
//since for char fields decimal count should be zero for other versions that do not support this extended functionality.
//-----------------------------------------------------------------------------------------------------------------------
int nFieldLength = 0;
int nDecimals = 0;
if (cDbaseType == 'C' || cDbaseType == 'c')
{
//treat decimal count as high byte
nFieldLength = (int)reader.ReadUInt16();
}
else
{
//read field length as an unsigned byte.
nFieldLength = (int)reader.ReadByte();
//read decimal count as one byte
nDecimals = (int)reader.ReadByte();
}
//read the reserved bytes.
reader.ReadBytes(14);
//Create and add field to collection
_fields.Add(new DbfColumn(sFieldName, DbfColumn.GetDbaseType(cDbaseType), nFieldLength, nDecimals, nDataOffset));
// add up address information, you can not trust the address recorded in the DBF file...
nDataOffset += nFieldLength;
}
// Last byte is a marker for the end of the field definitions.
reader.ReadBytes(1);
//read any extra header bytes...move to first record
//equivalent to reader.BaseStream.Seek(mHeaderLength, SeekOrigin.Begin) except that we are not using the seek function since
//we need to support streams that can not seek like web connections.
int nExtraReadBytes = _headerLength - (FileDescriptorSize + (ColumnDescriptorSize * _fields.Count));
if (nExtraReadBytes > 0)
reader.ReadBytes(nExtraReadBytes);
//if the stream is not forward-only, calculate number of records using file size,
//sometimes the header does not contain the correct record count
//if we are reading the file from the web, we have to use ReadNext() functions anyway so
//Number of records is not so important and we can trust the DBF to have it stored correctly.
if (reader.BaseStream.CanSeek && _numRecords == 0)
{
//notice here that we subtract file end byte which is supposed to be 0x1A,
//but some DBF files are incorrectly written without this byte, so we round off to nearest integer.
//that gives a correct result with or without ending byte.
if (_recordLength > 0)
_numRecords = (uint)Math.Round(((double)(reader.BaseStream.Length - _headerLength - 1) / _recordLength));
}
//lock header since it was read from a file. we don't want it modified because that would corrupt the file.
//user can override this lock if really necessary by calling UnLock() method.
_locked = true;
//clear dirty bit
_isDirty = false;
}
public object Clone()
{
return this.MemberwiseClone();
}
}
}
耗时快一天,开心的解决Whonet导出失败的难题,对DBF的文件格式算是熟了 20230613 zlz