开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共830人左右 1 + 2 + 3)新人会进入3群。
在使用POSTGRESQL数据库的时候,我们经常发现一些常见的问题
1 PG的磁盘消耗,相对于其他的数据库可能会稍快,尤其是进行DML操作中UPDATE 操作居多的情况下。
2 PG 的索引越多,相对于进行VACUUM ,AUTOVACUUM的时间就越长。
3 时间索引使用BTREE 占用的空间较大。导致表体积臃肿,数据处理的效率变慢。
基于提高PG使用的效率,降本增效的理念,针对一些时间字段是否有必要使用BTREE 索引,我们需要来一场比较和争论。在争论的开始,我们需要来进行一个数据的支持,也就是 talk is cheap , show me the code.
方案中的明星,BRIN 索引,BRIN 索引本身是针对并不是对于数据的物理的存储位置有一个明确的定位,BRIN 索引相当于一个汇总,根据存储值的范围来将这些数据相邻的 BLOCK 分成一组,计算取值范围,通过便利组来获取数据具体在哪个范围的BLOCK组中,基于这样的原理,BRIN索引适合顺序型,日期型,的数据查找,而非常不适合随机数据和采用率大的数值的索引替代的方案。
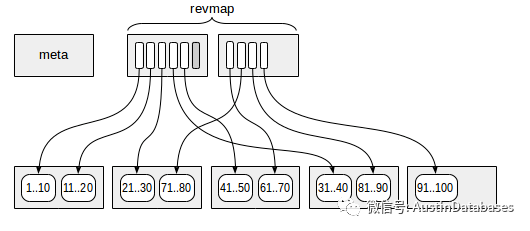
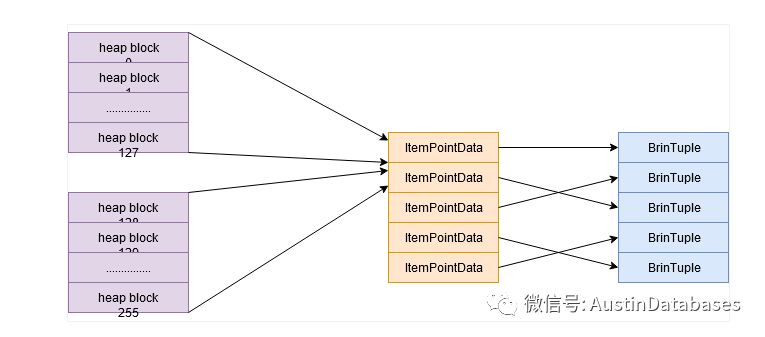
其中我们最大利用它的优势就是BRIN索引的空间占用会极小,多个相邻的BRIN 索引才会产生一条索引记录,同时BRIN 索引也不适合数据被经常删除的业务环境,所以使用BRIN 索引的前提总结
1 必须是有序的数据类型
2 数据行不会被经常频繁的删除
3 索引在实际业务体系中,并不承担核心的索引的功能
经过总结,BRIN 在我们日常的数据库系统中,特别适合时间类型的数据索引的形成,同时针对日志类型的表,中的数据字段,是非常适合进行BRIN索引的使用。
那么我们废话少说,我们针对一些索引来做一些测试。
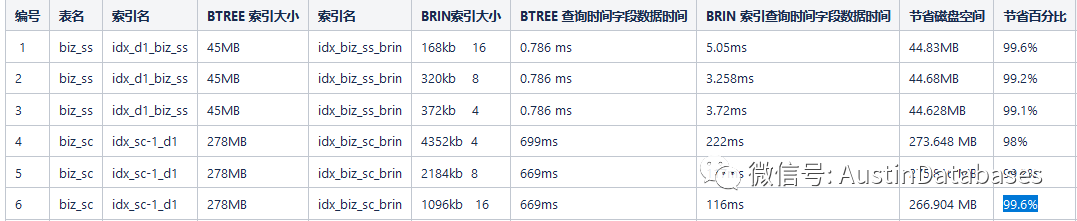
| 编号 | 表名 | 索引名 | BTREE 索引大小 | 索引名 | BRIN索引大小 | BTREE 查询时间字段数据时间 | BRIN 索引查询时间字段数据时间 | 节省磁盘空间 | 节省百分比 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | biz_ss | idx_d1_biz_ss | 45MB | idx_biz_ss_brin | 168kb 16 | 0.786 ms | 5.05ms | 44.83MB | 99.6% |
| 2 | biz_ss | idx_d1_biz_ss | 45MB | idx_biz_ss_brin | 320kb 8 | 0.786 ms | 3.258ms | 44.68MB | 99.2% |
| 3 | biz_ss | idx_d1_biz_ss | 45MB | idx_biz_ss_brin | 372kb 4 | 0.786 ms | 3.72ms | 44.628MB | 99.1% |
| 4 | biz_sc | idx_sc-1_d1 | 278MB | idx_biz_sc_brin | 4352kb 4 | 699ms | 222ms | 273.648 MB | 98% |
| 5 | biz_sc | idx_sc-1_d1 | 278MB | idx_biz_sc_brin | 2184kb 8 | 669ms | 117ms | 275.816 MB | 99.2% |
| 6 | biz_sc | idx_sc-1_d1 | 278MB | idx_biz_sc_brin | 1096kb 16 | 669ms | 116ms | 266.904 MB | 99.6% |
在测试中我们针对这个两个表中的日期类型的数据,的两种索引进行了的比对,BTREE 和 BRIN 索引,二者在查询的时间上的区别会随着你的数据的随机性而产生变化,如果是纯顺序型的数据,则BRIN 索引不光小,同时查询的时间并未比BTREE 要满,甚至还会快于BTREE 索引,但从体积上来说,性价比极高。
同时需要注意的
1 数据的插入与索引的更新,这数据在插入到数据库表中,并不是马上会触发索引的更新,而是要看情况。
1.1 索引使用的range map page 被写满了,那么将触发更新索引的工作
1.2 autovacuum 工作中,会触发BRIN索引的更新
1.3 vacuum 工作时会触发BRIN 索引的更新
而再次重申 BRIN索引在PG数据库中,是最不喜欢,DELETE和 UPDATE操作,因为这样的操作会导致,BRIN索引中的最大和最小值的范围的计算重新开始,将会导致需要扫描整个的 REANGE BLOCK,在计算出新的BRIN索引的每个BLOCK中的范围。
基于这个问题,这就导出另一个问题,我们的BRIN 索引的 桶 姑且称为桶中存放的数据,是多还是少的问题。举例 我们建立一个BRIN 索引。
CREATE INDEX index_name ON tablename USING BRIN (create_time) WITH (pages_per_range = 16,autosummarize = on);
这里着重说一下,两个建立索引的参数
pages_per_range ,这里如果你不写这个参数则默认值为 128, 随着数值的减小,你的桶总存放的数据量就变小,相关的整体的索引就会变大,在我们简单的测试中,我们针对几个值进行了测试 16 8 4 ,上面两个表中,分表都针对这三个值进行了POC ,则最终我们发现 8 这个数值在数据查询效率和索引的大小上,都是一个比较良好的选择。
当然由于基本的数据采样少,也就导致这个结果并不具有一定的普及型,所以具体这个值应该是什么,还是要进行自己实体系统的测试,找到适合的值。另外 autosummarize 默认是关闭,如果是开启的状态,则当检测到下一个页面有数据插入,则对上一个页面的范围进行重新的计算。
最终我们使用了这个方案,其中需要界定的
1 索引本身不是业务类的索引
2 索引本身使用的频率不高
3 纯时间类的索引,顺序性,并且表中的数据不是经常更新的类型
实际在更大容量的表与索引的测试中,如较大的时间类型的索引 22G --23G 可以在使用BRIN 索引后,减小到 47MB --235MB ,具体可以收缩后的大小与你选择的 pages_per_range 的数字大小有关,数字越小则产生的BRIN 索引越大,但是这里不是说我的数字越小我的索引的能力越强,在测试中,我们发现 22G 的索引大小在使用 page_per_range的情况下数字在 32 -64 的性能是较好的,而当数字下降到 8 后性能开始降低,同时也发现在使用BRIN 索引中,如果你的数据查询的位置在靠近整体数据集合的尾部,则查询的速度要快于顺序条件在前部的部分,当然由于测试的用例不多,这里仅仅是反映一个情况。
最终我们的一个索引由22G 变为 47MB ,节省了大量的磁盘空间。
小结:写到最后,POSTGRESQL 中的索引在所有目前的传统数据库中,提供了丰富的选择,对于不同的PG提供类型的索引的定位和切实的使用是一个我们应该进行的工作。