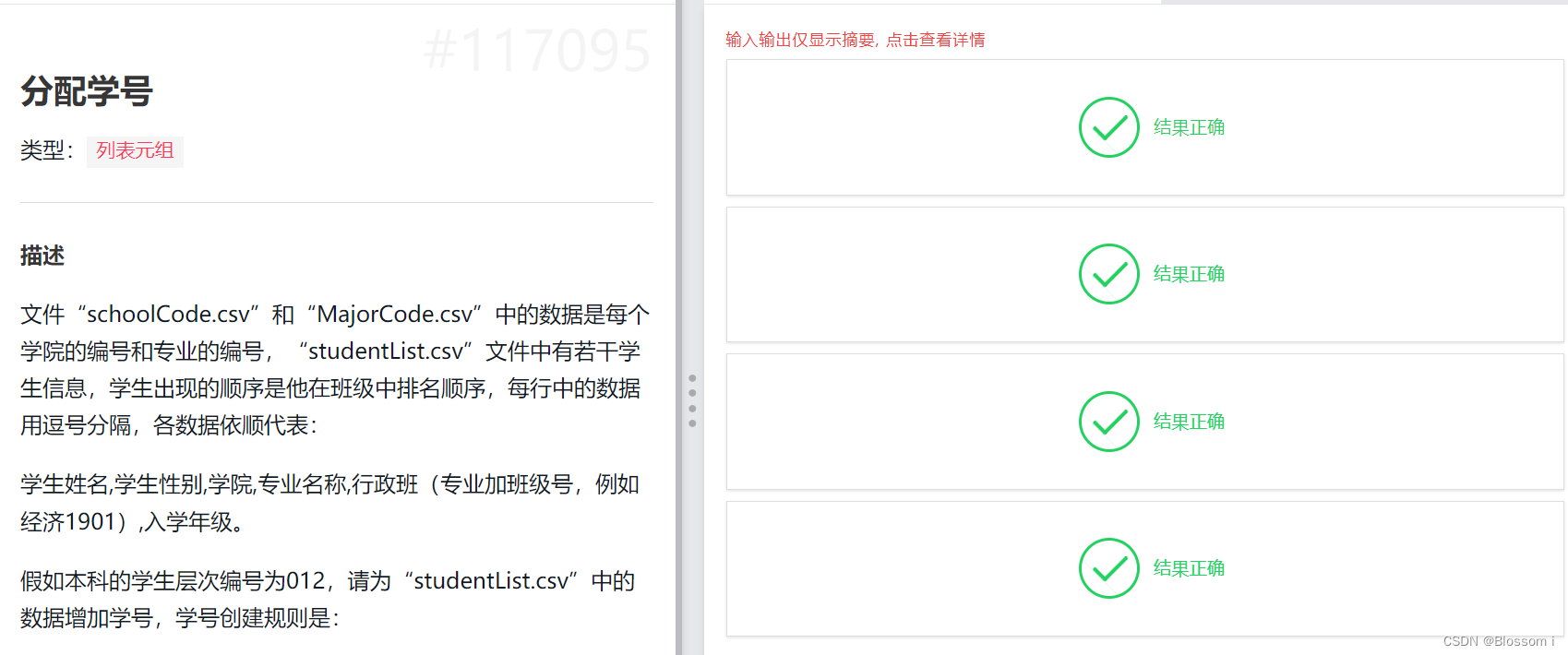
PyTorch的Autograd特征可以让PyTorch灵活快速的构建机器学习项目。autograd可以实现快速和容易的多重偏微分(梯度)计算。偏微分计算时反向传播神经网络学习的核心。
autograd的可以在运行时动态追踪计算,这意味着如果模型有决策分支、或者有在运行时之前长度未知的循环,仍然可以正确的追踪计算,得到正确的梯度进而驱动学习。并且,当模型是通过python构建的,在计算梯度时,PyTorch的autograd比那些依赖于对更加严格结构的模型进行静态分析的框架提供了更多的灵活性。
目录
Autograd可以做什么
一个简单例子
训练中的autograd
autograd的开启和关闭
autograd和in-place操作
Autograd可以做什么
PyTorch机器学习模型是一个有输入和输出的函数,将输入看作i维的特征向量,元素是
,我们可以将模型M表达为关于输入的向量值的函数
。将M的输出视作向量是因为一般而言,模型有多个输出。
讨论autograd大部分情况下是在训练的时候,这时输出是模型的loss。损失函数是模型输出的一个单值标量函数。这个函数表示模型的预测值和真值距离有多远。Note:从现在开始,当上下文比较清晰时我们省略向量符号,例如使用
代替
。
在训练模型时,想要最小化损失。在理想的情形下,这意味着调整其学习权重(learning weights)--也就是调整函数的参数,使得损失函数对于所有的输入都是0。在真实的世界,这就是一个迭代过程,不断调整学习权重,直到我们对各种各样的输入都有一个可容忍的损失。
我们如何决定从那个方向以及多远调整权重呢?想最小化损失,这意味着使得损失函数对输入的一阶导数为0:
损失L不是直接从输入导出的,而是模型输出的函数,而模型输出是关于输入的直接函数,通过链式微分法则:
使得事情变得复杂。模型输出关于输出的偏微分,如果使用链式法则再次展开表达式,我们将得到许多局部偏微分(模型中的每一个相乘学习权重,每一个激活函数,以及每一个其他的数学变换)。每个这样的偏微分的完整表达式是通过计算图的每个可能路径的局部梯度的乘积之和,该计算图的叶节点就是可测量梯度的变量。
特别的,关于学习权重的梯度是我们关心的,他告诉我们为了使得损失函数为0,对应改我们要改变权重的方向。
局部偏导数的数量和计算的复杂度会随着神经网络的加深成指数级的增长。这就是autograd出现的地方:它追踪每一个历史计算。Pytorch模型中的每一个计算的tensor携带了其输入tensor和创建它所使用的数学函数的历史信息。PyTorch每个数学函数都有一个计算自己导数的内置的实现,这大大加快了学习所需的局部导数的计算。
一个简单例子
import torch
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import math
a = torch.linspace(0., 2. * math.pi, steps=25, requires_grad=True)
print(a)输出:
tensor([0.0000, 0.2618, 0.5236, 0.7854, 1.0472, 1.3090, 1.5708, 1.8326, 2.0944,
2.3562, 2.6180, 2.8798, 3.1416, 3.4034, 3.6652, 3.9270, 4.1888, 4.4506,
4.7124, 4.9742, 5.2360, 5.4978, 5.7596, 6.0214, 6.2832],
requires_grad=True)
我们创建了一个输入的tensor,包含[0, 2pi]区间等间距值,并设置requires_grad=True。设置这个标志意味着接下来的每一个计算,autograd都将在该计算的输出tensor中累积计算的历史。
b = torch.sin(a)
#plt.plot(a.detach(), b.detach())
print(a.detach())
print(b.detach())
print(b)tensor([0.0000, 0.2618, 0.5236, 0.7854, 1.0472, 1.3090, 1.5708, 1.8326, 2.0944,
2.3562, 2.6180, 2.8798, 3.1416, 3.4034, 3.6652, 3.9270, 4.1888, 4.4506,
4.7124, 4.9742, 5.2360, 5.4978, 5.7596, 6.0214, 6.2832])
tensor([ 0.0000e+00, 2.5882e-01, 5.0000e-01, 7.0711e-01, 8.6603e-01,
9.6593e-01, 1.0000e+00, 9.6593e-01, 8.6603e-01, 7.0711e-01,
5.0000e-01, 2.5882e-01, -8.7423e-08, -2.5882e-01, -5.0000e-01,
-7.0711e-01, -8.6603e-01, -9.6593e-01, -1.0000e+00, -9.6593e-01,
-8.6603e-01, -7.0711e-01, -5.0000e-01, -2.5882e-01, 1.7485e-07])
tensor([ 0.0000e+00, 2.5882e-01, 5.0000e-01, 7.0711e-01, 8.6603e-01,
9.6593e-01, 1.0000e+00, 9.6593e-01, 8.6603e-01, 7.0711e-01,
5.0000e-01, 2.5882e-01, -8.7423e-08, -2.5882e-01, -5.0000e-01,
-7.0711e-01, -8.6603e-01, -9.6593e-01, -1.0000e+00, -9.6593e-01,
-8.6603e-01, -7.0711e-01, -5.0000e-01, -2.5882e-01, 1.7485e-07],
grad_fn=<SinBackward0>)
grad_fn提示我们当执行反向传播步骤并计算梯度时,需要对tensor的输入,计算sin(x)的导数。让我们再执行更多的计算:
c = 2 * b
print(c)
d = c + 1
print(d)输出:
tensor([ 0.0000e+00, 5.1764e-01, 1.0000e+00, 1.4142e+00, 1.7321e+00,
1.9319e+00, 2.0000e+00, 1.9319e+00, 1.7321e+00, 1.4142e+00,
1.0000e+00, 5.1764e-01, -1.7485e-07, -5.1764e-01, -1.0000e+00,
-1.4142e+00, -1.7321e+00, -1.9319e+00, -2.0000e+00, -1.9319e+00,
-1.7321e+00, -1.4142e+00, -1.0000e+00, -5.1764e-01, 3.4969e-07],
grad_fn=<MulBackward0>)
tensor([ 1.0000e+00, 1.5176e+00, 2.0000e+00, 2.4142e+00, 2.7321e+00,
2.9319e+00, 3.0000e+00, 2.9319e+00, 2.7321e+00, 2.4142e+00,
2.0000e+00, 1.5176e+00, 1.0000e+00, 4.8236e-01, -3.5763e-07,
-4.1421e-01, -7.3205e-01, -9.3185e-01, -1.0000e+00, -9.3185e-01,
-7.3205e-01, -4.1421e-01, 4.7684e-07, 4.8236e-01, 1.0000e+00],
grad_fn=<AddBackward0>)
最后让我们计算一个单元素输出。当在tensor上不使用任何参数调用.backward()时,它期望被调用的tensor只包含单个元素,这正是计算loss函数的情形。
out = d.sum()
print(out)输出:
tensor(25., grad_fn=<SumBackward0>)
可以通过使用tensor存储的grad_fn的next_functions属性,沿着计算的所有路径回溯到tensor的输入。下面的代码可以看到在tensor d上不断获取这个属性,将会展示所有前一级的tensor的梯度函数。调用a.grad_fn将会输出None,这说明a没有任何历史信息,是输入。
print('d:')
print(d.grad_fn)
print(d.grad_fn.next_functions)
print(d.grad_fn.next_functions[0][0].next_functions)
print(d.grad_fn.next_functions[0][0].next_functions[0][0].next_functions)
print(d.grad_fn.next_functions[0][0].next_functions[0][0].next_functions[0][0].next_functions)
print('\nc:')
print(c.grad_fn)
print('\nb:')
print(b.grad_fn)
print('\na:')输出:
d: <AddBackward0 object at 0x0000024725AF23A0> ((<MulBackward0 object at 0x0000024725AF2610>, 0), (None, 0)) ((<SinBackward0 object at 0x0000024725AF23A0>, 0), (None, 0)) ((<AccumulateGrad object at 0x0000024725A2CA30>, 0),) () c: <MulBackward0 object at 0x000002471D90F580> b: <SinBackward0 object at 0x000002471D90F580> a: None
需要注意的是,只有计算图的叶子节点才计算了他们的梯度。如果你尝试打印print(c.grad),你将得到None。只有输入时叶子节点,所以只有输入才有梯度。
训练中的autograd
到目前为止我们知道autograd如何工作的,我们还没有在实际模型中使用autograd。先定义一个小模型,然后检查一下在一个training batch后,梯度和学习权重是如何改变的。首先定义一些常量,模型以及输入输出。
BATCH_SIZE = 16
DIM_IN = 1000
HIDDEN_SIZE = 100
DIM_OUT = 10
class TinyModel(torch.nn.Module):
def __init__(self):
super(TinyModel, self).__init__()
self.layer1 = torch.nn.Linear(1000, 100)
self.relu = torch.nn.ReLU()
self.layer2 = torch.nn.Linear(100, 10)
def forward(self, x):
x = self.layer1(x)
x = self.relu(x)
x = self.layer2(x)
return x
some_input = torch.randn(BATCH_SIZE, DIM_IN, requires_grad=False)
ideal_output = torch.randn(BATCH_SIZE, DIM_OUT, requires_grad=False)
model = TinyModel()上面的代码并没有为模型的层指定requires_grad=True,我们定义的TinyModel类是torch.nn.Module的子类,它已经为我们设定了要跟踪层权重上的梯度以进行学习。
如果我们查看模型的层,我们可以检查权重的值,但是它没有计算出梯度。
print(model.layer2.weight[0][0:10]) # just a small slice
print(model.layer2.weight.grad)让我们看一下当运行一个training batch后,权重和梯度是如何改变的。loss函数使用的是预测和真实输出的欧式距离的平方,优化器是基本的随机梯度下降优化器。
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
prediction = model(some_input)
loss = (ideal_output - prediction).pow(2).sum()
print(loss)输出:
tensor(176.4542, grad_fn=<SumBackward0>)
loss.backward()
print(model.layer2.weight[0][0:10])
print(model.layer2.weight.grad[0][0:10])输出:
tensor([-0.0017, -0.0628, -0.0098, -0.0960, -0.0369, -0.0101, -0.0257, -0.0494,
0.0435, 0.0878], grad_fn=<SliceBackward0>)
tensor([ 2.8742, -6.6696, -2.7497, -0.2776, 1.1777, 0.4863, -1.2661, -3.1284,
-5.0247, 2.4285])
执行loss.backward()后,我们可以看到已经计算出了每一个学习权重的梯度,但是权重值未改变,这是因为我们没有执行optimizer。optimizer负责基于计算得到的梯度更新模型的参数。
optimizer.step()
print(model.layer2.weight[0][0:10])
print(model.layer2.weight.grad[0][0:10])输出:
tensor([-0.0046, -0.0561, -0.0070, -0.0957, -0.0381, -0.0106, -0.0244, -0.0463,
0.0486, 0.0854], grad_fn=<SliceBackward0>)
tensor([ 2.8742, -6.6696, -2.7497, -0.2776, 1.1777, 0.4863, -1.2661, -3.1284,
-5.0247, 2.4285])
执行optimizer.step()后,layer2的权重改变了。在调用optimizer.step()后,需要调用optimizer.zero_grad(),否则每次调用loss.backward()后学习权重上的梯度将会累积。
print(model.layer2.weight.grad[0][0:10])
for i in range(0, 5):
prediction = model(some_input)
loss = (ideal_output - prediction).pow(2).sum()
loss.backward()
print(model.layer2.weight.grad[0][0:10])
optimizer.zero_grad(set_to_none=False)
print(model.layer2.weight.grad[0][0:10])输出:
tensor([ 2.8742, -6.6696, -2.7497, -0.2776, 1.1777, 0.4863, -1.2661, -3.1284,
-5.0247, 2.4285])
tensor([ 23.3073, -15.0802, 2.5358, -0.3116, 6.0961, 5.9180, -3.2840,
-11.6558, -27.8526, 1.1333])
tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
在运行上面的代码后,你会发现多次运行loss.backward(),梯度的值将会变得非常大。在运行下一个training batch之前,未能将梯度归零将导致梯度以这种方式膨胀,从而导致不正确和不可预测的学习结果
autograd的开启和关闭
有时候希望细粒度控制autogard是否开启,有多种方式去做这件事。 最简单的方式是直接改变tensor的requires_grad标志。
a = torch.ones(2, 3, requires_grad=True)
print(a)
b1 = 2 * a
print(b1)
a.requires_grad = False
b2 = 2 * a
print(b2)输出:
tensor([[1., 1., 1.],
[1., 1., 1.]], requires_grad=True)
tensor([[2., 2., 2.],
[2., 2., 2.]], grad_fn=<MulBackward0>)
tensor([[2., 2., 2.],
[2., 2., 2.]])
如果只希望autograd临时关闭,更好的方式时使用torch.no_grad();
a = torch.ones(2, 3, requires_grad=True) * 2
b = torch.ones(2, 3, requires_grad=True) * 3
c1 = a + b
print(c1)
with torch.no_grad():
c2 = a + b
print(c2)
c3 = a * b
print(c3)输出:
tensor([[5., 5., 5.],
[5., 5., 5.]], grad_fn=<AddBackward0>)
tensor([[5., 5., 5.],
[5., 5., 5.]])
tensor([[6., 6., 6.],
[6., 6., 6.]], grad_fn=<MulBackward0>)
可能有时候我们有一个需要梯度跟踪开启的tensor,但是希望拷贝它的值,但不希望拷贝的tensor开启梯度跟踪,可以在Tensor对象上使用detach()方法。它创建从计算历史中脱离的tensor的拷贝。
x = torch.rand(5, requires_grad=True)
y = x.detach()
print(x)
print(y)输出:
tensor([0.5531, 0.4273, 0.6955, 0.4804, 0.0501], requires_grad=True) tensor([0.5531, 0.4273, 0.6955, 0.4804, 0.0501])
autograd和in-place操作
上面的每一个例子都是使用变量来获取计算的中间值。autograd需要这些中间值执行梯度计算,正是由于这个原因,我们在使用autograd时必须小心使用in-place操作。使用in-place操作会破坏在调用backward()计算导数所需的信息。PyTorch甚至可能阻止你在需要进行autograd的叶子变量上使用in-place操作。