本文从
xml开始讲解,注解后面给出
文章目录
- 1. 一个最基本的 IOC 依赖查找实例
- 2. IOC 的两种实现方式
- 2.1 依赖查找(Dependency Lookup)
- 2.2 依赖注入(Dependency Injection)
- 3. 在三层架构中的 service 层与 dao 层体会依赖查找与依赖注入的使用
- 4. 使用注解时,依赖查找在哪里查找?依赖注入在哪里注入?
- 5. @Autowired 进行自动注入时,如果存在多个同类型的 bean该如何解决?
- 6. 【面试题】依赖查找与依赖注入的对比
1. 一个最基本的 IOC 依赖查找实例
首先,我们需要明白什么是IOC(控制反转)和依赖查找。在Spring Framework中,控制反转是一种设计模式,可以帮助我们解耦模块间的关系,这样我们就可以把注意力更多地集中在核心的业务逻辑上,而不是在对象的创建和管理上。
依赖查找(Dependency Lookup)是一种技术手段,使得我们的对象可以从一个管理它们的容器(例如Spring的ApplicationContext)中获得它所需要的资源或者依赖。这种查找过程通常是通过类型、名称或者其他的标识进行的。
我们来看一个简单的例子,通过这个例子,你可以理解在Spring中如何实现IOC依赖查找。这个例子的目标是创建一个简单的"Hello World"应用,通过依赖查找,我们将从Spring的容器中获取一个打印"Hello, World!"的Bean。
第一步,我们需要创建一个简单的Java类,我们将其命名为"HelloWorld":
public class HelloWorld {
public void sayHello() {
System.out.println("Hello, World!");
}
}
接下来,我们需要在Spring的配置文件中定义这个Bean。这个配置文件通常命名为applicationContext.xml,并放在项目的src/main/resources目录下:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- 定义一个名为helloWorld的Bean -->
<bean id="helloWorld" class="com.example.demo.HelloWorld" />
</beans>
然后,我们就可以在我们的主程序中通过Spring的ApplicationContext来获取并使用这个Bean:
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class MainApp {
public static void main(String[] args) {
// 创建一个ApplicationContext,加载spring配置文件
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
// 通过id从ApplicationContext中获取Bean
HelloWorld obj = (HelloWorld) context.getBean("helloWorld");
// 调用方法
obj.sayHello();
}
}
可以在控制台上看到"Hello, World!"的输出。
2. IOC 的两种实现方式
首先,让我们开始了解什么是控制反转(IoC)。在传统的程序设计中,我们常常会在需要的地方创建对象,然后使用这些对象来完成一些工作。这种方式存在一个问题,那就是对象之间的耦合度太高。如果我们要改变对象的创建方式或者使用不同的对象来完成同样的工作,我们可能需要修改大量的代码。
为了解决这个问题,IoC的概念被引入。在IoC的设计模式中,对象的创建和维护不再由使用它们的代码来控制,而是由一个容器来控制。这个容器会负责对象的创建、配置和生命周期管理,使得我们的代码可以专注于核心的业务逻辑,而不需要关心对象是如何创建和管理的。这样,当我们需要改变对象的创建方式或者替换对象时,我们只需要修改容器的配置,而不需要修改使用对象的代码。
接下来,让我们来看看IoC的两种实现方式:依赖查找和依赖注入。
2.1 依赖查找(Dependency Lookup)
在这种方式中,当一个对象需要一个依赖(比如另一个对象)时,它会主动从容器中查找这个依赖。通常,这个查找的过程是通过类型、名称或者其他的标识来进行的。
- 根据名称查找
在这种方式中,你需要知道你要查找的bean的ID,然后使用ApplicationContext.getBean(String name)方法查找bean。
例如,假设我们有一个Printer类,它需要一个Ink对象来打印信息。在没有使用Spring框架的情况下,Printer可能会直接创建一个Ink对象:
public class Printer {
private Ink ink = new Ink();
//...
}
但是在Spring框架中,我们可以将Ink对象的创建交给Spring的容器,然后在Printer需要Ink对象时,从容器中查找获取:
public class Ink {
private String color;
public void useInk() {
System.out.println("Using ink...");
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
}
public class Printer {
private Ink ink;
public void setInk(Ink ink) {
this.ink = ink;
}
public void print() {
ink.useInk();
System.out.println("Printing...");
}
}
<bean id="inkId" class="com.example.demo.Ink" />
<bean id="printer" class="com.example.demo.Printer">
<property name="ink" ref="inkId" />
</bean>
在这个配置中,<bean> 元素定义了一个bean,id属性给这个bean定义了一个唯一的名字,class属性则指定了这个bean的完全限定类名。这里“printer”这个bean依赖于"ink" bean。当Spring容器初始化“printer”这个bean的时候,它需要查找到正确名称的"ink" bean,并将它们注入到“printer” bean中。
这里ref按照名称inkId注入bean,当调用(Printer) context.getBean("printer")时,属于按名称依赖查找,Spring检查xml配置根据名称"printer"和"inkId"注入对象,关于注入,我们后面再说。
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Printer printer = (Printer) context.getBean("printer");
}
依赖查找过程是隐含在Spring框架的工作机制中的,开发者在编写XML配置的时候,并不需要显式进行查找操作。
- 根据类型查找
在这种方式中,你不需要知道bean的ID,只需要知道它的类型。然后,你可以使用ApplicationContext.getBean(Class<T> requiredType)方法查找bean。
还是刚刚的Printer类和Ink类,还需要在XML配置文件中定义你的bean。以下面的方式定义Ink和Printer类:
这里有多个相同类型的bean,如果按照类型注入,则编译器会报错,如下:
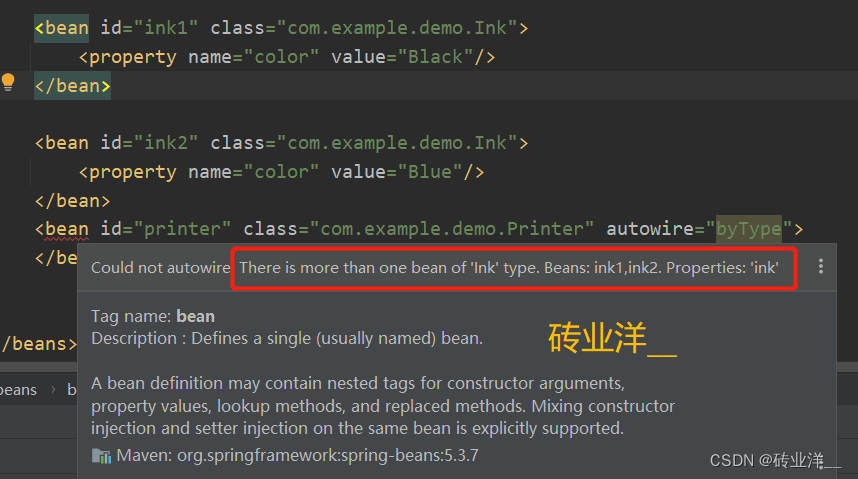
我们得按照名称注入,autowire="byType"会直接编译报错,就像有多个一样类型的bean,使用@Autowired注解就会报错。所以这里在printer bean里面指明ink bean
<bean id="ink1" class="com.example.demo.Ink">
<property name="color" value="Black"/>
</bean>
<bean id="ink2" class="com.example.demo.Ink">
<property name="color" value="Blue"/>
</bean>
<bean id="printer" class="com.example.demo.Printer">
<property name="ink" ref="ink1"/>
</bean>
这里,我们定义了两个类型为Ink的bean,ink1和ink2,他们的颜色属性分别为“Black”和“Blue”。另外,我们还定义了一个类型为Printer的bean,注入ink1依赖。
然后在Java代码中,可以按照类型获取Ink类型的bean:
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
// 按类型获取bean
// 注意,这里存在多个Ink类型的bean,这行代码会抛出异常
// Ink ink = context.getBean(Ink.class);
// 如果存在多个Ink类型的bean,你可以这样获取所有的Ink bean
Map<String, Ink> beans = context.getBeansOfType(Ink.class);
for (String id : beans.keySet()) {
System.out.println("Found ink with id: " + id);
Ink inkBean = beans.get(id);
// do something with inkBean...
}
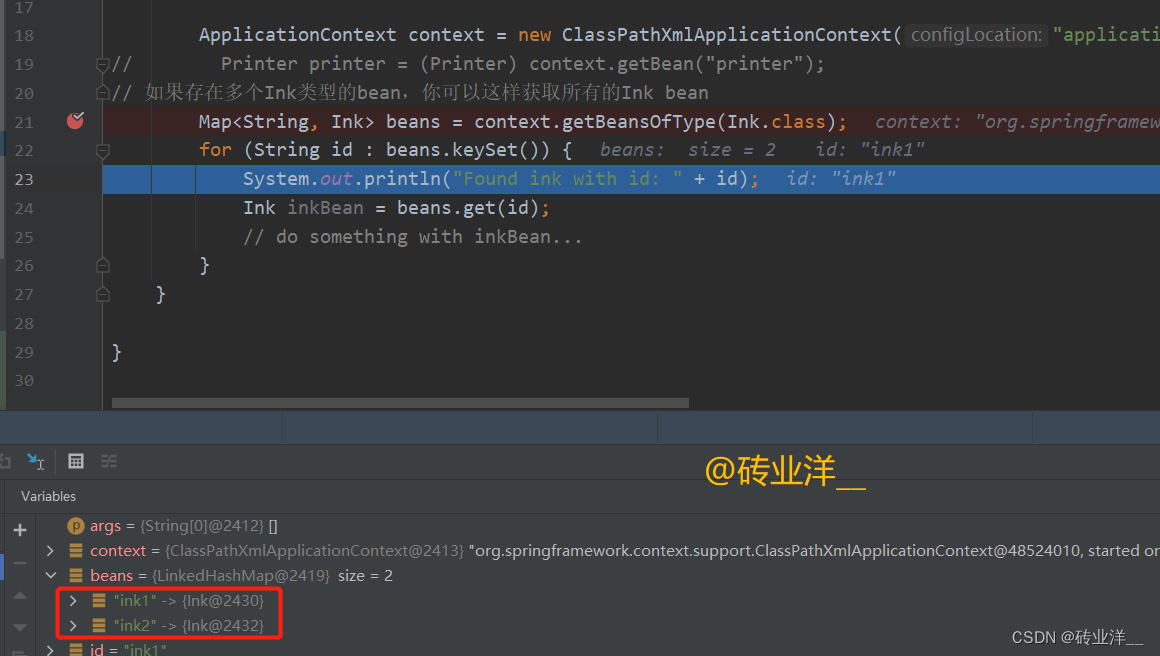
在这个例子中,context.getBean(Ink.class)会按照类型查找Ink的bean。但是这里有多个Ink类型的bean(如本例所示),这种方式会抛出异常。对于这种情况,你可以使用context.getBeansOfType(Ink.class)方法获取所有类型为Ink的bean,然后自行决定如何使用这些bean。
2.2 依赖注入(Dependency Injection)
- 通过类型进行依赖注入
还是和之前一样的Printer和Ink类:
public class Ink {
private String color;
public void useInk() {
System.out.println("Using ink...");
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
}
public class Printer {
private Ink ink;
public void setInk(Ink ink) {
this.ink = ink;
}
public void print() {
ink.useInk();
System.out.println("Printing...");
}
}
在这个例子中,Printer类有一个Ink类型的属性ink,并且有一个setter方法setInk用于设置这个属性的值。这就是我们通常说的依赖注入的setter方法。
这里我们没有使用 Spring 的 @Autowired 注解,而是使用了 Java 的 setter 方法。你可以通过在 Spring 配置文件中使用 <bean> 和 <property> 标签来配置这种依赖关系
在Spring的XML配置文件中,我们可以如下配置:
<bean id="ink" class="com.example.demo.Ink">
<property name="color" value="Blue"/>
</bean>
<bean id="printer" class="com.example.demo.Printer" autowire="byType">
</bean>
注意,我们这里加上属性autowire="byType",这样Spring就会自动根据类型来进行依赖注入。虽然autowire="byType"会启用按类型的自动注入,但如果显式配置了ink属性的值,Spring会使用你的配置,而不是按类型自动注入。
当我们需要使用Printer对象时,我们可以从Spring容器中获取:
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Printer printer = (Printer) context.getBean("printer");
printer.print();
当我们调用context.getBean("printer")时,会查找id为printer的bean对象,Printer对象会使用被Spring容器注入的Ink对象来打印信息。
Using ink...
Printing...
在这个例子中,依赖查找实际上应用于两个地方:
-
当使用
context.getBean("printer")时,实际上正在查找名为"printer"的Bean对象,即Printer对象,这是一个明显的依赖查找的例子。 -
当
Spring框架将Ink对象注入Printer对象时,Printer对象在内部是通过依赖查找方式来找到Ink对象的。在这种情况下,Spring框架控制了这个查找过程,开发者并没有直接进行依赖查找。在这个过程中,Spring框架根据配置文件中定义的依赖关系(这里是类型依赖),自动找到Ink对象,并将它注入到Printer对象中。这个查找过程是隐式的,对开发者是透明的。
所以总的来说,依赖查找可以发生在我们手动从容器中获取Bean的时候,也可以发生在Spring自动注入依赖的过程中。
通过这种方式,我们不再需要在Printer类中直接创建Ink对象,而是让Spring容器来管理Ink对象的创建和注入,从而实现了Printer和Ink之间的解耦。
- 通过名称进行依赖注入
首先,我们修改Ink类,添加构造方法,使其可以有多种颜色:
public class Ink {
private String color;
public Ink(String color) {
this.color = color;
}
public void useInk() {
System.out.println("Using " + color + " ink...");
}
}
然后,在Spring的XML配置文件中,我们定义两种颜色的墨水,以及一个打印机:
<bean id="blackInk" class="com.example.demo.Ink">
<constructor-arg value="black" />
</bean>
<bean id="blueInk" class="com.example.demo.Ink">
<constructor-arg value="blue" />
</bean>
<bean id="printer" class="com.example.demo.Printer">
<property name="ink" ref="blackInk" />
</bean>
在这个配置中,我们有两种颜色的墨水:黑色和蓝色。在printer bean的定义中,我们通过ref属性指定我们想要注入的墨水的id为"blackInk"。
在 <property> 元素中,name 和 ref 属性有不同的作用:
name 属性指的是要注入的目标 bean(这里是 “printer”)的属性名。这个属性名应该在目标 bean 的类(在这个例子中是 com.example.demo.Printer 类)中存在,且应该有相应的 setter 方法。比如,如果 name="ink",那么 com.example.demo.Printer 类中需要有一个名为 ink 的属性,且有一个名为 setInk(...) 的方法。
ref 属性指的是要注入的源 bean 的 ID。这个 ID 应该在同一份 Spring 配置文件中定义过。比如,如果 ref="blackInk",那么应该在配置文件中有一个 <bean id="blackInk" ... /> 的定义。
因此,当你看到 <property name="ink" ref="blackInk" /> 这样的配置时,你可以理解为:Spring 容器会找到 ID 为 “blackInk” 的 bean(在这个例子中是 com.example.demo.Ink 类的一个实例),然后调用 com.example.demo.Printer 类的 setInk(...) 方法,将这个 Ink 实例注入到 Printer 实例的 ink 属性中。
最后,我们可以在一个Java类中获取printer bean并调用其print方法:
ApplicationContext context = new ClassPathXmlApplicationContext("beans.xml");
Printer printer = context.getBean("printer", Printer.class);
printer.print();
这将输出以下结果:
Using black ink...
Printing...
这里体现的通过名称进行依赖注入的含义是:我们通过指定bean的id(在这里是"blackInk"),来明确地告诉Spring我们想要注入哪一个bean。这是与通过类型进行依赖注入的一个主要区别:通过类型进行依赖注入时,Spring会自动选择一个与目标属性类型匹配的bean进行注入,而不需要我们明确指定bean的id。
3. 在三层架构中的 service 层与 dao 层体会依赖查找与依赖注入的使用
在三层架构中,我们通常会有以下三层:
- 表示层(
Presentation Layer):与用户进行交互的层次,如前端页面、命令行等,比如Controller类里的逻辑。 - 业务逻辑层(
Business Logic Layer),也叫作Service层:实现业务逻辑的地方。 - 数据访问层(
Data Access Layer),也叫作DAO层:直接操作数据库或者调用API来获取数据。
在本例中,我们将只关注 Service 层与 DAO 层,并且会使用到 Spring 框架。
首先,让我们定义一个业务对象,比如一个用户(User):
public class User {
private String id;
private String name;
private String email;
// getters and setters omitted for brevity
}
接着,我们定义 DAO 层。在 DAO 层中,我们通常会有一些方法来操作数据库,如创建用户,获取用户,更新用户等。在本例中,我们简化为一个接口:
public interface UserDao {
User getUser(String id);
}
在实际项目中,我们可能有多种 UserDao 的实现,比如 MySQLUserDao、MongoDBUserDao 等。在这里,我们简化为一个模拟实现:
public class UserDaoImpl implements UserDao {
public User getUser(String id) {
// 为了简化,我们在这里直接返回一个静态的 User 对象
User user = new User();
user.setId(id);
user.setName("Test User");
user.setEmail("test@example.com");
return user;
}
}
然后,我们定义 Service 层。在 Service 层中,我们会调用 DAO 层的方法来完成业务逻辑:
public class UserService {
private UserDao userDao;
public User getUser(String id) {
return userDao.getUser(id);
}
}
这里的问题是,UserService 需要一个 UserDao 的实例,但是 UserService 并不知道如何获取 UserDao 的实例。这就是我们要解决的问题,我们可以使用依赖查找或者依赖注入来解决。
1.依赖查找:
我们可以修改 UserService 类,让它从 Spring 容器中获取 UserDao 的实例:
public class UserService {
private UserDao userDao;
public UserService() {
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
this.userDao = (UserDao) context.getBean("userDao");
}
public User getUser(String id) {
return userDao.getUser(id);
}
}
这样,当我们创建 UserService 的实例时,它会自动从 Spring 容器中获取 UserDao 的实例。
2.依赖注入:
我们可以利用 Spring 框架的依赖注入特性,让 Spring 容器自动将 UserDao 的实例注入到 UserService 中。为此,我们需要在 UserService 中添加一个 setter 方法,并在 Spring 的配置文件中配置这个依赖关系:
UserService 类:
public class UserService {
private UserDao userDao;
public void setUserDao(UserDao userDao) {
this.userDao = userDao;
}
public User getUser(String id) {
return userDao.getUser(id);
}
}
Spring 配置文件(applicationContext.xml):
<bean id="userDao" class="com.example.UserDaoImpl" />
<bean id="userService" class="com.example.UserService">
<property name="userDao" ref="userDao" />
</bean>
这样,当我们从 Spring 容器中获取 UserService 的实例时,Spring 容器会自动将 UserDao 的实例注入到 UserService 中:
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
UserService userService = (UserService) context.getBean("userService");
User user = userService.getUser("1");
如果你想在代码中获取这个bean实例,你需要做两件事情:
-
创建一个
Spring应用上下文(ApplicationContext)对象。这个对象会读取你的Spring配置文件,然后根据配置文件的内容创建和管理bean实例。在你的代码中,new ClassPathXmlApplicationContext("applicationContext.xml")就是在创建一个Spring应用上下文对象。“applicationContext.xml” 是你的Spring配置文件的路径。 -
调用
context.getBean("userDao")来获取 “userDao” 这个bean的实例。Spring会根据你的配置创建一个UserDaoImpl类的实例,并返回给你。
4. 使用注解时,依赖查找在哪里查找?依赖注入在哪里注入?
当我们全部用注解,不用xml来实现的时候,会写成如下形式:
Ink.java
@Component
public class Ink {
public void useInk() {
System.out.println("Using ink...");
}
}
Printer.java
@Component
public class Printer {
@Resource
private Ink ink;
public void print() {
ink.useInk();
System.out.println("Printing...");
}
}
@Resource注解告诉Spring,请查找一个名为"ink"的Bean并注入到这个字段中。注意,@Resource的名称是大小写敏感的,因此"ink"和"Ink"是两个不同的名字。
@Resource 注解的 name 属性应与 @Component 注解中指定的名称相匹配,如果@Component 没有指定name属性,那么bean的名称默认是类名的小写形式。
如果省略了@Resource注解的name属性,则默认的注入规则是根据字段的名称进行推断,并尝试注入同名的资源,如果Ink类上注解为@Component("inkComponent"),那这个bean的名称就是inkComponent,只能写成如下形式
@Resource(name = "inkComponent")
private Ink ink;
或者
@Resource
private Ink inkComponent;
为了使这些注解起作用,我们需要开启注解扫描@ComponentScan("com.example"):
@Configuration
@ComponentScan("com.example")
public class AppConfig {
// 可以在这里定义其他的配置或进行其他的注解配置
}
然后,你可以在你的Java代码中通过AnnotationConfigApplicationContext类获取Printer的Bean并调用它的print方法:
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
Printer printer = context.getBean(Printer.class);
printer.print();
输出以下结果:
Using ink...
Printing...
这个例子中,我们使用了完全基于Java的配置,没有使用任何XML。通过@Configuration和@ComponentScan注解,我们告诉了Spring在哪里找到我们的Bean。
这个例子中
context.getBean(Printer.class);按照类型进行了依赖查找@Resource按照名称进行了依赖注入@Resource在按名称依赖注入的时候会隐式按名称依赖查找
有没有人发现这次Printer不用强制转换了?之前还是(Printer) context.getBean("printer");呢。这里把类型都传进去了,ApplicationContext 查找的时候当然按照这个类型查找啊
依赖注入中的按名称和按类型两种方式,主要体现在注入时如何选择合适的bean进行注入。
-
按名称进行依赖注入: 是指在进行依赖注入时,根据名称来查找合适的
bean。比如在Java代码中使用@Resource(name = "beanName")。这种方式的优点是明确指定了注入的bean。 -
按类型进行依赖注入: 是指在进行依赖注入时,根据类型来查找合适的
bean。比如在Java代码中使用@Autowired。缺点是当有多个相同类型的bean存在时,可能会导致选择错误的bean。
至于context.getBean()方法,这是依赖查找的方式,而不是依赖注入。它也分为按名称和按类型两种方式,与依赖注入的按名称和按类型是类似的。
-
使用
context.getBean("beanName"),是按名称进行依赖查找。 -
使用
context.getBean(ClassType)或者context.getBean("beanName", ClassType),是按类型进行依赖查找。如果有多个同类型的bean,则会抛出异常。
对于依赖查找,除了可以使用
context.getBean进行显示的查找外,Spring容器在实例化Bean的过程中也会进行隐式的依赖查找。此外,Spring还支持使用@Autowired、@Resource、@Inject等注解在依赖注入之前隐式依赖查找。
对于依赖注入,通过XML配置文件中的<property>和<constructor-arg>进行属性和构造器注入,以及通过@Autowired和@Resource注解进行注入。但还要注意,Spring还支持通过@Value注解对简单类型的值进行注入,以及通过@Qualifier注解对同一类型的不同实例进行精确选择。
5. @Autowired 进行自动注入时,如果存在多个同类型的 bean该如何解决?
在使用 @Autowired 进行自动装配时,如果存在多个同类型的 bean,Spring 会抛出一个 NoUniqueBeanDefinitionException 异常,表示无法确定要注入哪个 bean。为了避免这种错误,可以使用以下方法之一:
- 使用 @Qualifier 注解:
@Qualifier 注解可以与 @Autowired 一起使用,通过指定 bean 的名称来解决歧义。
下面的例子中创建了两个Ink Bean,分别是blueInk和redInk。然后在Printer类中,我们通过@Qualifier注解指定需要注入的Bean的名称。
@Component
public class BlueInk implements Ink {
//...
}
@Component
public class RedInk implements Ink {
//...
}
@Component
public class Printer {
@Autowired
@Qualifier("blueInk")
private Ink ink;
public void setInk(Ink ink) {
this.ink = ink;
}
public void print() {
ink.useInk();
System.out.println("Printing...");
}
}
注意:@Autowired和@Qualifier("blueInk")写在setInk方法上和写在ink字段定义上是一样的。
- 使用 @Primary 注解:
可以使用@Primary注解来标识优先注入的Bean。如果在容器中存在多个同类型的Bean,Spring会优先注入被@Primary注解标记的Bean。
@Component
@Primary
public class BlueInk implements Ink {
//...
}
@Component
public class RedInk implements Ink {
//...
}
@Component
public class Printer {
private Ink ink;
@Autowired
public void setInk(Ink ink) {
this.ink = ink;
}
public void print() {
ink.useInk();
System.out.println("Printing...");
}
}
在上面的例子中,我们使用@Primary注解标记了BlueInk,所以在注入Ink类型的Bean时,Spring会优先选择BlueInk。
需要注意的是,@Qualifier注解的优先级高于@Primary注解,也就是说如果同时使用了@Qualifier和@Primary注解,Spring会优先考虑@Qualifier注解。
6. 【面试题】依赖查找与依赖注入的对比
依赖查找(Dependency Lookup)和依赖注入(Dependency Injection)都是在控制反转(Inversion of Control,IoC)的背景下,解决对象间依赖关系的方式,但它们在实现方式上有所不同。
- 依赖查找(
Dependency Lookup)
依赖查找是一种主动的依赖解决方式。在实际的编程中,我们需要显式地调用API(如ApplicationContext.getBean())来获取所需要的依赖。如果查找的对象里面还有其他对象,则会进行隐式依赖查找,也就是说,查找的对象里面的依赖也会被Spring自动注入。
依赖查找的一个缺点是它会使代码和Spring框架紧密耦合。这意味着如果我们想要改变依赖解决方式或者更换其他的IoC容器,我们可能需要改动大量的代码,比如改变要查找的bean名称。
- 依赖注入(
Dependency Injection)
依赖注入是一种被动的依赖解决方式。与依赖查找相比,依赖注入不需要我们显式地调用API,而是由Spring容器负责将依赖注入到需要它的Bean中。
依赖注入的主要优点是它能够减少代码和Spring框架的耦合度,使我们的代码更加易于测试和维护。同时,它也支持更加复杂的依赖关系,包括循环依赖和自动装配等。
依赖注入通常分为基于构造器的依赖注入和基于setter的依赖注入,也可以通过使用注解(如@Autowired, @Resource等)来实现。
总结来说,依赖查找和依赖注入各有优缺点。选择使用哪种方式,主要取决于实际的需求和场景。在实际的开发中,我们通常会更倾向于使用依赖注入,因为它能够提供更高的灵活性和可维护性。比如使用对象时全都是加上@Autowired或@Resource注解后直接使用,调用被注入对象的方法,不会再去用API查找对象。
如果看完本篇还有疑问,下篇:Spring高手之路——深入理解注解驱动配置与XML配置的融合与区别
欢迎一键三连~
有问题请留言,大家一起探讨学习
----------------------Talk is cheap, show me the code-----------------------