Spring源码系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】spring源码整体概述 | https://blog.csdn.net/zhenghuishengq/article/details/130940885 |
| 【二】通过refresh方法剖析IOC的整体流程 | https://blog.csdn.net/zhenghuishengq/article/details/131003428 |
| 【三】xml配置文件启动spring时refresh的前置工作 | https://blog.csdn.net/zhenghuishengq/article/details/131066637 |
| 【四】注解方式启动spring时refresh的前置工作 | https://blog.csdn.net/zhenghuishengq/article/details/131113249 |
注解方式启动spring时refresh的前置工作
- 一,注解的方式启动spring时refresh的前置工作
- 1,this()
- 2,register(annotatedClasses)
- 3,总结
一,注解的方式启动spring时refresh的前置工作
上一篇中提到了xml的方式启动spring,接下来通过注解方式来剖析spring内部的启动流程。
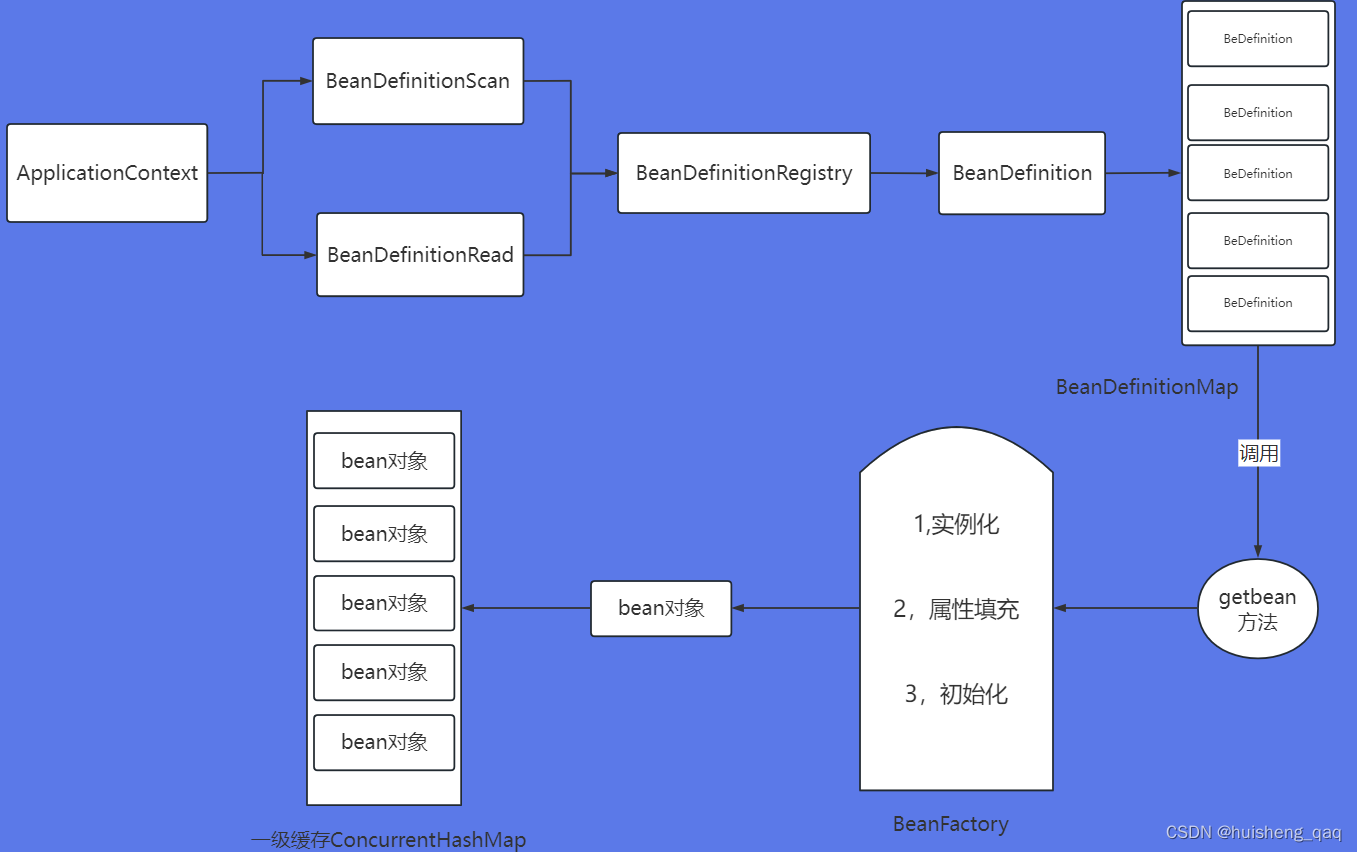
通过注解获取上下文的方式如下,随后定义一个AnnotationConfig的配置类,通过@Bean的方式构建实例。这里依旧推荐使用debug的方式,从上往下看。
ApplicationContext ac = new AnnotationConfigApplicationContext(AnnotationConfig.class);
随后会进入AnnotationConfigApplicationContext 的构造方法,并且可以发现支持传多个参数。由于这里也是剖析refresh的前置工作,因此这里重点主要是查看this() 和 register 这两个方法。
public AnnotationConfigApplicationContext(Class<?>... annotatedClasses) {
this(); //调用构造函数
register(annotatedClasses); //注册我们的配置类
refresh(); //IOC容器刷新接口
}
1,this()
首先会调用 AnnotationConfigApplicationContext 自身的构造方法,也可以通过上图的执行流程进行对照。
public AnnotationConfigApplicationContext() {
//创建一个读取注解的Bean定义读取器
this.reader = new AnnotatedBeanDefinitionReader(this);
//创建类路径下的BeanDefinition扫描器
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
在分析这个AnnotationConfigApplicationContext类之前,先来看一下这个类的类图,发现也是众多接口的具体的子类,同时也说明该类的功能非常的齐全和强大
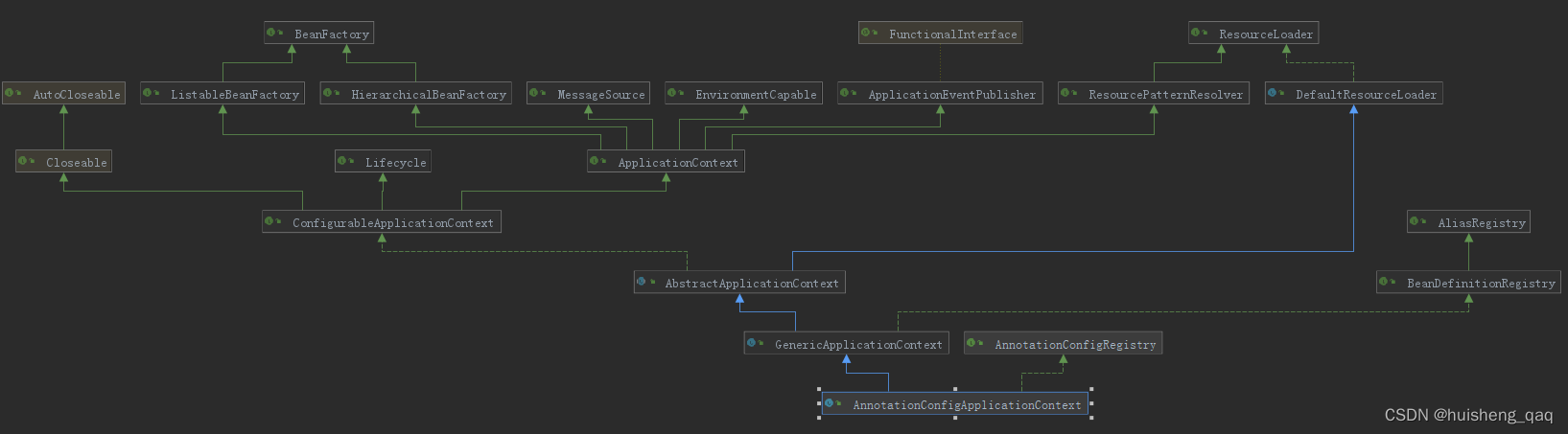
1,在实例化AnnotationConfigApplicationContext类之前,需要先实例化其父类。由于这个ResourceLoader 是一个接口,没有对应的构造方法,根据断点也能发现,会要优先加载DefaultResourceLoader的构造器。在这个构造方法中,可以发现里面会调用一个getDefaultClassLoader方法
public class DefaultResourceLoader implements ResourceLoader {
...
public DefaultResourceLoader() {
this.classLoader = ClassUtils.getDefaultClassLoader();
}
}
getDefaultClassLoader 顾名思义,就是获取默认的类加载器。在jvm中,类加载器主要有引导类加载器、扩展类加载起、系统类加载器和自定义类加载器。获取已有的类加载器,如果获取的类加载器为空,则设置默认的类加载器为系统类加载器
public static ClassLoader getDefaultClassLoader() {
ClassLoader cl = null;
//获取当前线程的类加载器
cl = Thread.currentThread().getContextClassLoader();
if (cl == null) {
//如果获取到的值为空,则将类加载器设置为系统类加载器
cl = ClassLoader.getSystemClassLoader();
}
}
2,获取到类加载器之后,根据debug的断点继续往下走,可以发现下一步是去获取一个 LogFactory ,
public static Log getLog(Class<?> clazz) {
return getLog(clazz.getName());
}
随后进入具体获取日志的方法,创建具体的日志,其内部流程也非常复杂
public static Log getLog(String name) {
switch (logApi) {
case LOG4J:
return Log4jDelegate.createLog(name);
case SLF4J_LAL:
return Slf4jDelegate.createLocationAwareLog(name);
case SLF4J:
return Slf4jDelegate.createLog(name);
default:
return JavaUtilDelegate.createLog(name);
}
}
系统默认使用的是 LOG4J ,接下来进入这个 Log4jDelegate.createLog 这个方法,里面会创建并返回一个Log4jLog 对象
return new Log4jLog(name);
而在这个Log4jLog 类中,其构造方法如下,即会调用这个 getLogger 方法
//获取日志上下文
public Log4jLog(String name) {
this.logger = loggerContext.getLogger(name);
}
随后进入真正的获取日志的方法
public ExtendedLogger getLogger(final String name, final MessageFactory messageFactory) {
//获取日志工厂,无则创建,有则获取
final ExtendedLogger extendedLogger = loggerRegistry.getLogger(name, messageFactory);
if (extendedLogger != null) {
//检查创建的日志工厂个给定的消息工厂是否一致
AbstractLogger.checkMessageFactory(extendedLogger, messageFactory);
return extendedLogger;
}
//如果获取的工厂为空,
final SimpleLogger simpleLogger = new SimpleLogger(name, defaultLevel, showLogName, showShortName, showDateTime,
showContextMap, dateTimeFormat, messageFactory, props, stream);
loggerRegistry.putIfAbsent(name, messageFactory, simpleLogger);
return loggerRegistry.getLogger(name, messageFactory);
}
如果获取到的日志工厂为空,则会调用这这个 SimpleLogger 方法
随后调用这个super父类方法,会判断当前的消息工厂是否为空,为空则创建一个默认的消息工厂
//初始化父类
public AbstractLogger(final String name, final MessageFactory messageFactory) {
this.name = name;
//不为空则获取,为空则创建一个默认的
this.messageFactory = messageFactory == null ? createDefaultMessageFactory() : narrow(messageFactory);
this.flowMessageFactory = createDefaultFlowMessageFactory();
}
其创建方式如下,通过构造器的反射的方式创建一个消息的日志
private static MessageFactory2 createDefaultMessageFactory() {
try {
final MessageFactory result = DEFAULT_MESSAGE_FACTORY_CLASS.newInstance();
return narrow(result);
} catch (final InstantiationException | IllegalAccessException e) {
throw new IllegalStateException(e);
}
}
3,在调完super之后,随后就是一个获取系统属性的一个方法
final String lvl = props.getStringProperty(SimpleLoggerContext.SYSTEM_PREFIX + name + ".level");
接下来继续往下走,可以发现是一个PropertiesUtil工具类里面的这个getStringProperty方法,而里面的重点就是这个environment 对象的由来
public String getStringProperty(final String name) {
return environment.get(name);
}
可以发现这个event环境对象,是通过这个实例化Environment对象而来
public PropertiesUtil(final Properties props) {
this.environment = new Environment(new PropertiesPropertySource(props));
}
public PropertiesUtil(final String name) {
this.environment = new Environment(new PropertyFilePropertySource(name));
}
再进入到这个Environment 的构造方法中,可以发现在这一步,就开始获取系统的变量和实现
private Environment(final PropertySource propertySource) {
sources.add(propertySource);
for (final ClassLoader classLoader: LoaderUtil.getClassLoaders()) {
try {
for (final PropertySource source: ServiceLoader.load(PropertySource.class, classLoader)) {
sources.add(source);
}
} catch (final Throwable ex) {
}
}
reload();
}
并且在这个类中,有着四个属性,literal存储集合存储系统的属性,tokenized存储系统的环境变量,normalized存储日志相关的参数。继续往下走可以看到这些参数对应的值
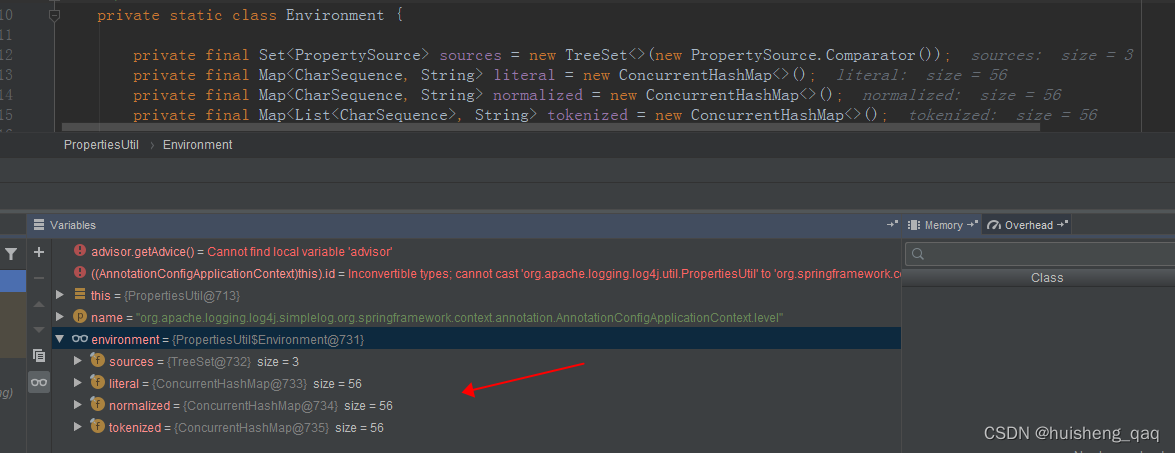
Set<PropertySource> sources = new TreeSet<>(new PropertySource.Comparator());
Map<CharSequence, String> literal = new ConcurrentHashMap<>();
Map<CharSequence, String> normalized = new ConcurrentHashMap<>();
Map<List<CharSequence>, String> tokenized = new ConcurrentHashMap<>();
环境变量
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wMjEF0JT-1686218443841)(img/1686195259391.png)]](https://img-blog.csdnimg.cn/1881b727781e48148441296aac11f47b.png)
系统属性
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zyNLSiZa-1686218443842)(img/1686195284361.png)]](https://img-blog.csdnimg.cn/715a15649a534bd2b2a3fb1ee90c8e03.png)
日志属性
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X27OwWkx-1686218443842)(img/1686195303051.png)]](https://img-blog.csdnimg.cn/984f73dfce49459382b4e34bf207a1c9.png)
在获取到这些属性之后,会对刚刚设置的值进行判断,看设置的值是包含在系统参数中,如果包含,就将这些参数加入到缓存中。
public static List < CharSequence > tokenize(final CharSequence value) {
if (CACHE.containsKey(value)) {
return CACHE.get(value);
}
final List < CharSequence > tokens = new ArrayList < > ();
final Matcher matcher = PROPERTY_TOKENIZER.matcher(value);
while (matcher.find()) {
tokens.add(matcher.group(1).toLowerCase());
}
//存入缓存
CACHE.put(value, tokens);
return tokens;
}
4,在获取完系统环境和属性之后,通过打断点继续走,再次回到了这个AbstractApplicationContext 类中,获取当前对象的hashcode对应的value
private String id = ObjectUtils.identityToString(this);
identityToString方法中可以发现,就是一字符串的形式返回对象的标识,就是通过对象的全路径名称的类名加上一个@一个该类对应的hashcode
public static String identityToString(@Nullable Object obj) {
if (obj == null) {
return EMPTY_STRING;
}
//对象名称 + @ + 获取到的hashcode对应的十六进制的值
return obj.getClass().getName() + "@" + getIdentityHexString(obj);
}
将对象的hashcode的值先进行一个十六进制的转换,后面将值给返回
//将对象的hashcode转换成十六进制,并将值返回
public static String getIdentityHexString(Object obj) {
return Integer.toHexString(System.identityHashCode(obj));
}
如下图,这个id的值就是当前对象的唯一标识,就是当前对象对应的唯一值hashcode哈希码,这样对象的哈希code对应的哈希value的值就有了,即这一步的主要作用是给当前对象的hashcode生成一个hash值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tlaH3V2m-1686218443843)(img/1686190434912.png)]](https://img-blog.csdnimg.cn/c99dabf979d94668b00abc780b62e7ea.png)
获取完这个唯一标识哈希值后,会接着获取一个名称,该名称和上面的id值一模一样
private String displayName = ObjectUtils.identityToString(this);
5,跟着断点继续往下走,接下来就是实例化这个构造方法,到了这一步和解析xml启动流程的一样,也是有一个默认的AntPathMatcher进行路径匹配
protected ResourcePatternResolver getResourcePatternResolver() {
return new PathMatchingResourcePatternResolver(this);
}
这里主要是为了获取资源处理器和加载器,用于加载一些资源和加载一些类加载器等
private PathMatcher pathMatcher = new AntPathMatcher();
//获取资源加载器
public PathMatchingResourcePatternResolver(ResourceLoader resourceLoader) {
Assert.notNull(resourceLoader, "ResourceLoader must not be null");
this.resourceLoader = resourceLoader;
}
6,接下来继续往下debug,可以发现会进入 GenericApplicationContext 这个构造方法,从这里开始,就构建了这默认的bean工厂DefaultListableBeanFactory
public GenericApplicationContext() {
//构建默认的Bean工程
this.beanFactory = new DefaultListableBeanFactory();
}
其类图如下,可以发现其功能是有多么的强大
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8U5ureQx-1686218443844)(img/1685349283411.png)]](https://img-blog.csdnimg.cn/e2f0a1db3f0f4b1a8708f677949a2577.png)
这个默认的BeanFactory的构造方法如下,只是初始化了父类的构造方法
public DefaultListableBeanFactory() {
super();
}
接下来查看其父类的构造方法,除了忽略一些依赖接口之外,也是只初始化了父类
public AbstractAutowireCapableBeanFactory() {
super();
//忽略的依赖接口
ignoreDependencyInterface(BeanNameAware.class);
ignoreDependencyInterface(BeanFactoryAware.class);
ignoreDependencyInterface(BeanClassLoaderAware.class);
}
随后调用的父类的构造方法如下,该类是一个抽象类
public AbstractBeanFactory() {
}
随后再次根据断点进入 DefaultSingletonBeanRegistry 这个类里面,里面包含存储对象缓存池
//一级缓存 这个就是我们大名鼎鼎的单例缓存池 用于保存我们所有的单实例bean
private final Map < String, Object > singletonObjects = new ConcurrentHashMap < > (256);
//三级缓存 该map用户缓存 key为 beanName value 为ObjectFactory(包装为早期对象)
private final Map < String, ObjectFactory << ? >> singletonFactories = new HashMap < > (16);
//二级缓存 ,用户缓存我们的key为beanName value是我们的早期对象(对象属性还没有来得及进行赋值)
private final Map < String, Object > earlySingletonObjects = new HashMap < > (16);
//已注册的单例名称set
private final Set < String > registeredSingletons = new LinkedHashSet < > (256);
//该集合用户缓存当前正在创建bean的名称
private final Set<String> singletonsCurrentlyInCreation = Collections.newSetFromMap(new ConcurrentHashMap<>(16));
//排除当前创建检查的
private final Set<String> inCreationCheckExclusions = Collections.newSetFromMap(new ConcurrentHashMap<>(16));
...
至此,bean工厂就初始化完成
7,AnnotationConfigApplicationContext 的父类构造器全部执行完成之后,就会再次回到当前类的构造器
public AnnotationConfigApplicationContext() {
//创建一个读取注解的Bean定义读取器
//完成了spring内部BeanDefinition的注册(主要是后置处理器)
this.reader = new AnnotatedBeanDefinitionReader(this);
//创建BeanDefinition扫描器
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
8,先看这个AnnotatedBeanDefinitionReader ,见名知意就知道这是创建一个bean定义的读取器
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry) {
this(registry, getOrCreateEnvironment(registry));
}
接下来进入这个this方法,熟悉获取环境环节又出现了,在上面就已经获取到了系统的全部环境个属性,所以这里获取返回即可。
private static Environment getOrCreateEnvironment(BeanDefinitionRegistry registry) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
//如果Environment存在,则获取直接返回
if (registry instanceof EnvironmentCapable) {
return ((EnvironmentCapable) registry).getEnvironment();
}
//不存在则创建一个标准的环境
return new StandardEnvironment();
}
如何创建一个标准环境,获取全部的系统环境和系统属性,在xml分析流程的时候详细的讲过。获取完标准环境之后,会将这个获取到的上下文的对象,赋值给read读取器,并处理一些条件注解,以及一些后置处理器等
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry, Environment environment) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
Assert.notNull(environment, "Environment must not be null");
//把ApplicationContext对象赋值给AnnotatedBeanDefinitionReader
this.registry = registry;
//用户处理条件注解 @Conditional os.name
this.conditionEvaluator = new ConditionEvaluator(registry, environment, null);
//注册一些内置的后置处理器
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
条件处理,如一些条件判断等,判断一些环境设置,资源加载对象,类加载器对象等
public ConditionContextImpl(@Nullable BeanDefinitionRegistry registry,
@Nullable Environment environment, @Nullable ResourceLoader resourceLoader) {
//ioc 容器applicationContext对象
this.registry = registry;
//bean工厂对象
this.beanFactory = deduceBeanFactory(registry);
//设置环境对象
this.environment = (environment != null ? environment : deduceEnvironment(registry));
//资源加载对象
this.resourceLoader = (resourceLoader != null ? resourceLoader : deduceResourceLoader(registry));
//类加载器对象
this.classLoader = deduceClassLoader(resourceLoader, this.beanFactory);
}
这里就是去注册一些后置处理器
public static void registerAnnotationConfigProcessors(BeanDefinitionRegistry registry) {
registerAnnotationConfigProcessors(registry, null);
}
如注册实现Order接口,加了@Lazy的注解,加了@Autowired注解,@Required属性,JSR规范的注解等等。会将实现了这些注解的接口,或者有这些属性的参数等,会注册成一个 BeanDefinition 先存在Set集合中

10,再看这个 ClassPathBeanDefinitionScanner 对象,首先会调用他的构造方法实例化对象
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry) {
this(registry, true);
}
一直到调用四个参数的构造方法
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, @Nullable ResourceLoader resourceLoader) {
this.registry = registry;
if (useDefaultFilters) {
registerDefaultFilters();
}
//设置环境对象
setEnvironment(environment);
//设置资源加载器
setResourceLoader(resourceLoader);
}
首先会注册一个默认的过滤器registerDefaultFilters 如下
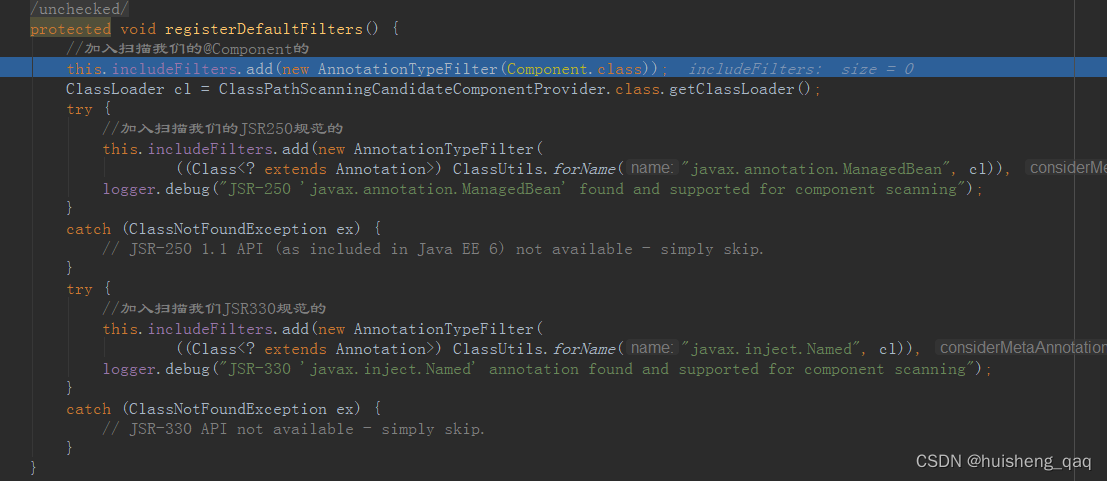
在这个类中,会定义两个集合,这个就和springboot的主启动器那里的一样,可以排除哪些类不被扫描
//包含的集合
private final List<TypeFilter> includeFilters = new LinkedList<>();
//排除的集合
private final List<TypeFilter> excludeFilters = new LinkedList<>();
在这个 registerDefaultFilters 方法中,第一句就是将有Component注解的类加进来,所以在这一步全部加了这个注解的都会被扫描,并生成bean定义,其他的就是一些JSR规范等
//加入扫描我们的@Component的
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
注册完默认的过滤器之后,接下来就是设置环境对象,设置加载资源等,这些前面都已经拿到。至此整个扫描阶段完成。除了这个@Component这个注解会被扫描,@Service @Respository @Controller等这些注解在这个类下面都会被扫描
至此,第一阶段super阶段结束,这个阶段主要做的事情总结如下:获取整个系统的类加载器,注册factoryLog日志工厂,获取整个系统的环境和属性,创建对象的哈希码,构建默认的bean工厂,将一些条件注解、后置处理器等读取成beanDefinition,将一些常用的注解扫描成bean定义
2,register(annotatedClasses)
上面通过这个reader读取器和scan扫描器将一些注解都转换成了beanDefinition,接下来要做的事情就是将这些bean定义注册。
//定义读取器
private final AnnotatedBeanDefinitionReader reader;
public void register(Class<?>... annotatedClasses) {
Assert.notEmpty(annotatedClasses, "At least one annotated class must be specified");
this.reader.register(annotatedClasses);
}
其注册方式如下,会遍历所有的这个注解类
public void register(Class<?>... annotatedClasses) {
for (Class<?> annotatedClass : annotatedClasses) {
registerBean(annotatedClass);
}
}
public void registerBean(Class<?> annotatedClass) {
doRegisterBean(annotatedClass, null, null, null);
}
接下来进入真正的注册方法 doRegisterBean
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B6CixSkX-1686218443845)(img/1686216325343.png)]](https://img-blog.csdnimg.cn/19e46c4cd0c247ce845f5fac1da610f2.png)
首先第一步会创建一个 AnnotatedGenericBeanDefinition 的类,用于存储@Configuration注解的类
public AnnotatedGenericBeanDefinition(Class<?> beanClass) {
setBeanClass(beanClass);
this.metadata = new StandardAnnotationMetadata(beanClass, true);
}
随后会判断是否要跳过注解,如一些不满足条件的,@Condition注解
//判断是否需要跳过注解,spring中有一个@Condition注解,当不满足条件,这个bean就不会被解析
if (this.conditionEvaluator.shouldSkip(abd.getMetadata())) {
return;
}
随后设置Bean的作用域,默认为单例
//解析bean的作用域,如果没有设置的话,默认为单例
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(abd);
abd.setScope(scopeMetadata.getScopeName());
随后解析一些通用注解,将这些注解填充到原先生成的bean定义当中
//解析通用注解,填充到AnnotatedGenericBeanDefinition,
//解析的注解为Lazy,Primary,DependsOn,Role,Description
AnnotationConfigUtils.processCommonDefinitionAnnotations(abd);
最后一步进行注册操作,
BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, this.registry);
其注册成bean定义的方式如下,
//将bean定义注册到bean工厂中
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// 在主名称中注册bean定义
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// 通过别名注册成bean定义
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias: aliases) {
registry.registerAlias(beanName, alias);
}
}
}
注册bean定义的registerBeanDefinition方法如下
@Override
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
...
}
如果这个bean定义已经存在,其内部又大量的条件判断,如bean定义的名称不能相同,权限大的优先存在不能被覆盖等等
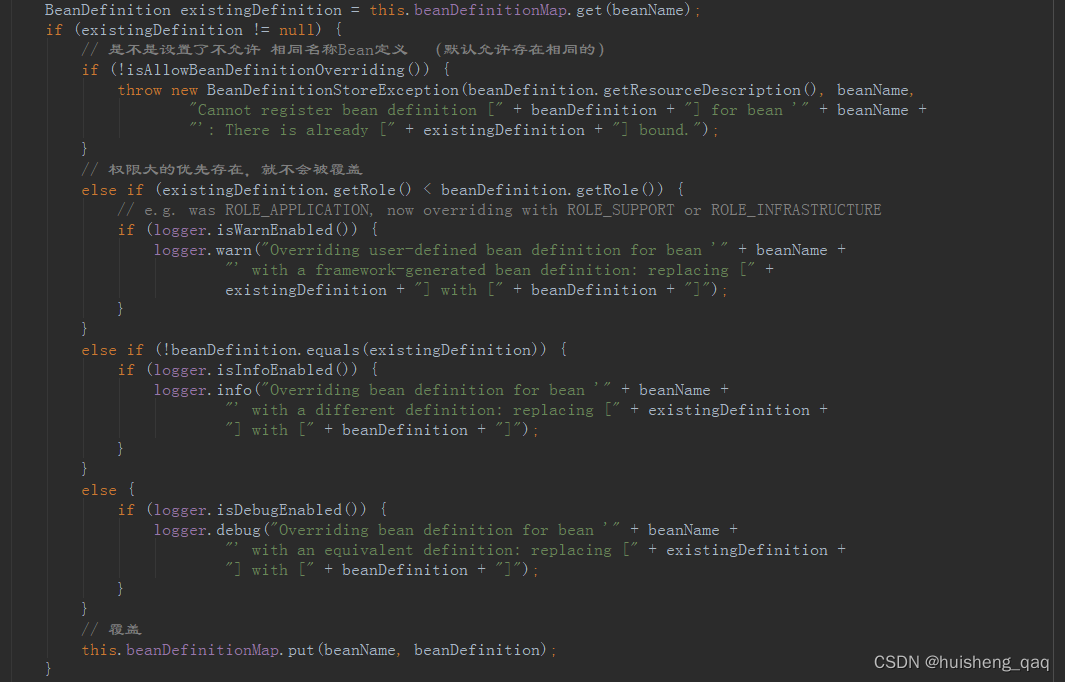
如果bean定义不存在,会将这个beanDefinition加入到 beanDefinitionMap 集合中
this.beanDefinitionMap.put(beanName, beanDefinition);
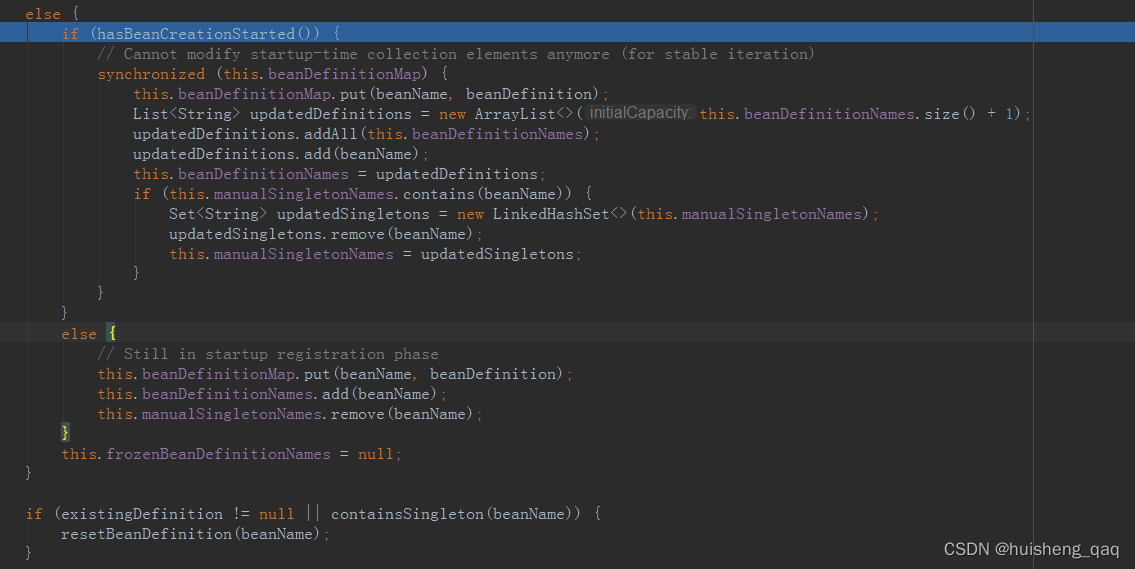
如果当前map集合中没有这个bean定义,且这个bean定义是单例的,则会将之前的reset,就是将之前的bean定义给删除,如下,会现将以前的单例bean定义删除,随后再将这个最新的单例bean定义加入到map集合中
protected void resetBeanDefinition(String beanName) {
clearMergedBeanDefinition(beanName);
destroySingleton(beanName);
// Reset all bean definitions that have the given bean as parent (recursively).
for (String bdName : this.beanDefinitionNames) {
if (!beanName.equals(bdName)) {
BeanDefinition bd = this.beanDefinitionMap.get(bdName);
if (beanName.equals(bd.getParentName())) {
resetBeanDefinition(bdName);
}
}
}
}
至此,beanDefinition的注册阶段完成。注册阶段的总结如下:就是将一些beanDefinition进行一些解析,设置一些属性和作用域,对一些bean定义进行验证是否需要注册,注册时需要验证会不会覆盖问题,注册后将beanDefinition存储到beanDefinitionMap中
3,总结
通过上面两步可以发现,用注解的方式来作为获取上下文并且启动spring,其复杂度远远超过使用xml的方式,并且xml方式里面有的步骤这里面全有。
这两部总结到一起如下:获取整个系统的类加载器,注册factoryLog日志工厂,获取整个系统的环境和属性,构建默认的bean工厂,将一些条件注解、后置处理器等读取成beanDefinition,将一些常用的注解扫描成beanDefinition,随后将这些beanDefinition进行解析,设置属性和作用域,验证是否需要注册,注册时需要验证会不会覆盖问题等操作,注册后将beanDefinition存储到beanDefinitionMap中