🤵♂️ 个人主页:@Lingxw_w的个人主页
✍🏻作者简介:计算机科学与技术研究生在读
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
一、背景介绍
二、比赛任务
三、评审规则
1. 数据说明
2. 评估指标
3. 评测及排行
四、作品提交要求
五、解题思路
1、读取数据和预处理
2、TFIDF和逻辑回归
3、transformers bert模型
一、背景介绍
疫情发生对人们生活生产的方方面面产生了重要影响,并引发了国内舆论的广泛关注,众多网民也参与到了疫情相关话题的讨论中。大众日常的情绪波动在疫情期间会放大,并寻求在自媒体和社交媒体上发布和评论。
比赛地址:http://challenge.xfyun.cn/topic/info?type=epidemic-weibo&option=ssgy&ch=ds22-dw-zmt05
为了掌握真实社会舆论情况,科学高效地做好防控宣传和舆情引导工作,针对疫情相关话题开展网民情绪识别是重要任务。本次我们重点关注微博平台上的用户情绪,希望各位选手能搭建自然语言处理模型,对疫情下微博文本的情绪进行识别。

二、比赛任务
本次赛题需要选手对微博文本进行情绪分类,分为正向情绪和负面情绪。数据样例如下:

赛题数据由训练集和测试集组成,本次竞赛的评价标准采用准确率指标,最高分为1。
三、评审规则
1. 数据说明
赛题数据由训练集和测试集组成,训练集数据集读取代码:
import pandas as pd
pd.read_csv('train.csv',sep='\t')2. 评估指标
本次竞赛的评价标准采用准确率指标,最高分为1。
计算方法参考地址:
sklearn.metrics.accuracy_score — scikit-learn 1.2.2 documentation ,
评估代码参考:
from sklearn.metrics import accuracy_score
y_pred = [0,2,1,3]
y_true = [0,1,2,3]
accuracy _score(y _true, y_pred)
3. 评测及排行
1、赛事提供下载数据,选手在本地进行算法调试,在比赛页面提交结果。
2、每支团队每天最多提交3次。
3、排行按照得分从高到低排序,排行榜将选择团队的历史最优成绩进行排名。
四、作品提交要求
文件格式:预测结果文件按照csv格式提交
文件大小:无要求
提交次数限制:每支队伍每天最多3次
预测结果文件详细说明:
1) 以csv格式提交,编码为UTF-8,第一行为表头;
2) 标签顺序需要与测试集文本保持一致;
3) 提交前请确保预测结果的格式与sample_submit.csv中的格式一致。
具体格式如下:
label
1
1
1
1
五、解题思路
赛题是一个非常典型的文本分类赛题,接下来我们将使用TFIDF和BERT模型两者思路来完成建模。
导入需要的一些库;
import pandas as pd
import jieba
import matplotlib.pyplot as plt
import seaborn as sns1、读取数据和预处理
读取数据
train_df = pd.read_csv("train.csv",sep='\t')
test_df = pd.read_csv("test.csv",sep='\t')
print("train size: {} \ntest size {}".format(len(train_df),len(test_df)))
# 测试 emojiswitch 效果
import emojiswitch
emojiswitch.demojize('心中千万只🐑🐑🐑呼啸而过',delimiters=("",""), lang="zh")'心中千万只母羊母羊母羊呼啸而过'
import re
def clean_str(text):
text = emojiswitch.demojize(text,delimiters=("",""), lang="zh") # Emoji转文字
return text.strip()
train_df['text'] = train_df['text'].apply(lambda x: clean_str(x))
test_df['text'] = test_df['text'].apply(lambda x: clean_str(x))# 处理后的数据一览
train_df.head(6)
# 绘制讯飞数据集的文本长度分
train_df['len'] = [len(i) for i in train_df["text"]]
test_df['len'] = [len(i) for i in test_df["text"]]
print(train_df['len'].quantile(0.995))
plt.title("text length")
sns.distplot(train_df['len'],bins=10,color='r')
sns.distplot(test_df['len'],bins=10,color='g')
plt.show() 
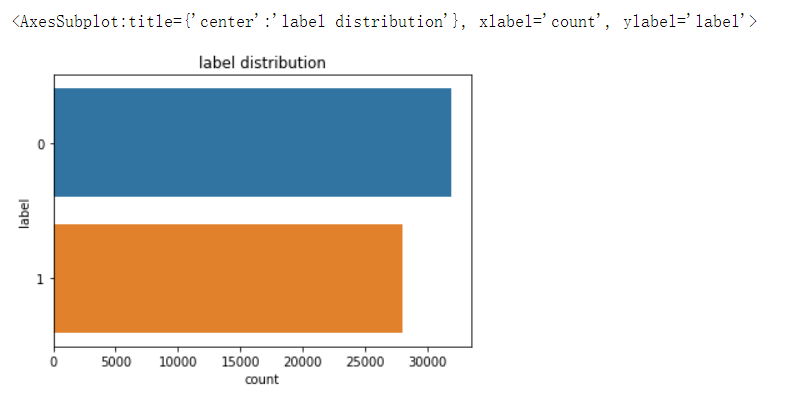
# 查看标签label分布
print(train_df['label'].value_counts())
plt.title("label distribution")
sns.countplot(y='label',data=train_df)0 31962 1 28038 Name: label, dtype: int64
1.jieba是python中的中文分词第三方库,可以将中文的文本通过分词获得单个词语,返回类型为列表类型。
2.jieba分词共有三种模式:精确模式、全模式、搜索引擎模式。
(1)精确模式语法:jieba.lcut(字符串,cut_all=False),默认时为cut_all=False,表示为精确模型。精确模式是把文章词语精确的分开,并且不存在冗余词语,切分后词语总词数与文章总词数相同。
(2)全模式语法:ieba.lcut(字符串,cut_all=True),其中cut_all=True表示采用全模型进行分词。全模式会把文章中有可能的词语都扫描出来,有冗余,即在文本中从不同的角度分词,变成不同的词语。
(3)搜索引擎模式:在精确模式的基础上,对长词语再次切分。
train_df['words'] = train_df['text'].apply(lambda x:' '.join(jieba.lcut(x)))
test_df['words'] = test_df['text'].apply(lambda x: ' '.join(jieba.lcut(x)))2、TFIDF和逻辑回归
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline # 组合流水线# 训练TFIDF和逻辑回归
pipline = make_pipeline(
TfidfVectorizer(),
LogisticRegression()
)
pipline.fit(
train_df['words'].tolist(),
train_df['label'].tolist()
)
pd.DataFrame(
{
'label': pipline.predict(test_df['words'])
}
).to_csv('lr_submit.csv', index=None) # 86左右准确率指标大概0.86左右。
3、transformers bert模型
# pip install transformers
# transformers bert相关的模型使用和加载
from transformers import BertTokenizer
# 分词器,词典
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
train_encoding = tokenizer(train_df['text'].tolist(), truncation=True, padding=True, max_length=128)
test_encoding = tokenizer(test_df['text'].tolist(), truncation=True, padding=True, max_length=128)from torch.utils.data import Dataset, DataLoader, TensorDataset
import torch
# 数据集读取
class NewsDataset(Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
# 读取单个样本
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(int(self.labels[idx]))
return item
def __len__(self):
return len(self.labels)
train_dataset = NewsDataset(train_encoding, train_df['label'])
test_dataset = NewsDataset(test_encoding, [0] * len(test_df))from torch.utils.data import Dataset, DataLoader, TensorDataset
import torch
# 数据集读取
class NewsDataset(Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
# 读取单个样本
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(int(self.labels[idx]))
return item
def __len__(self):
return len(self.labels)
train_dataset = NewsDataset(train_encoding, train_df['label'])
test_dataset = NewsDataset(test_encoding, [0] * len(test_df))精度计算
# 精度计算
def flat_accuracy(preds, labels):
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)from transformers import BertForSequenceClassification, AdamW, get_linear_schedule_with_warmup
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=2)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 单个读取到批量读取
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=16, shuffle=False)
# 优化方法
optim = AdamW(model.parameters(), lr=2e-5)
total_steps = len(train_loader) * 1训练函数
# 训练函数
def train():
model.train()
total_train_loss = 0
iter_num = 0
total_iter = len(train_loader)
for batch in train_loader:
# 正向传播
optim.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs[0]
total_train_loss += loss.item()
# 反向梯度信息
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# 参数更新
optim.step()
iter_num += 1
if(iter_num % 100==0):
print("epoth: %d, iter_num: %d, loss: %.4f, %.2f%%" % (epoch, iter_num, loss.item(), iter_num/total_iter*100))
print("Epoch: %d, Average training loss: %.4f"%(epoch, total_train_loss/len(train_loader)))
for epoch in range(1):
print("------------Epoch: %d ----------------" % epoch)
train()------------Epoch: 0 ---------------- epoth: 0, iter_num: 100, loss: 0.0293, 2.67% epoth: 0, iter_num: 200, loss: 0.0087, 5.33% epoth: 0, iter_num: 300, loss: 0.1835, 8.00% epoth: 0, iter_num: 400, loss: 0.0722, 10.67% epoth: 0, iter_num: 500, loss: 0.0275, 13.33% epoth: 0, iter_num: 600, loss: 0.0207, 16.00% epoth: 0, iter_num: 700, loss: 0.0315, 18.67% epoth: 0, iter_num: 800, loss: 0.0209, 21.33% epoth: 0, iter_num: 900, loss: 0.4200, 24.00% epoth: 0, iter_num: 1000, loss: 0.1209, 26.67% epoth: 0, iter_num: 1100, loss: 0.0093, 29.33% epoth: 0, iter_num: 1200, loss: 0.0229, 32.00% epoth: 0, iter_num: 1300, loss: 0.0164, 34.67% epoth: 0, iter_num: 1400, loss: 0.1712, 37.33% epoth: 0, iter_num: 1500, loss: 0.0070, 40.00% epoth: 0, iter_num: 1600, loss: 0.3227, 42.67% epoth: 0, iter_num: 1700, loss: 0.2320, 45.33% epoth: 0, iter_num: 1800, loss: 0.0102, 48.00% epoth: 0, iter_num: 1900, loss: 0.0195, 50.67% epoth: 0, iter_num: 2000, loss: 0.4099, 53.33% epoth: 0, iter_num: 2100, loss: 0.0076, 56.00% epoth: 0, iter_num: 2200, loss: 0.0008, 58.67% epoth: 0, iter_num: 2300, loss: 0.0496, 61.33% epoth: 0, iter_num: 2400, loss: 0.2253, 64.00% epoth: 0, iter_num: 2500, loss: 0.0046, 66.67% epoth: 0, iter_num: 2600, loss: 0.0968, 69.33% epoth: 0, iter_num: 2700, loss: 0.0118, 72.00% epoth: 0, iter_num: 2800, loss: 0.0165, 74.67% epoth: 0, iter_num: 2900, loss: 0.3721, 77.33% epoth: 0, iter_num: 3000, loss: 0.2609, 80.00% epoth: 0, iter_num: 3100, loss: 0.2001, 82.67% epoth: 0, iter_num: 3200, loss: 0.3607, 85.33% epoth: 0, iter_num: 3300, loss: 0.1450, 88.00% epoth: 0, iter_num: 3400, loss: 0.0155, 90.67% epoth: 0, iter_num: 3500, loss: 0.0164, 93.33% epoth: 0, iter_num: 3600, loss: 0.3011, 96.00% epoth: 0, iter_num: 3700, loss: 0.0728, 98.67% Epoch: 0, Average training loss: 0.1361
with torch.no_grad():
pred_label = []
for batch in test_dataloader:
# 正向传播
optim.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
outputs = model(input_ids, attention_mask=attention_mask)
pred_label += list(outputs.logits.argmax(1).cpu().data.numpy())pd.DataFrame(
{
'label': pred_label
}
).to_csv('bert_submit.csv', index=None) # 96左右准确率指标大概0.96左右。
参考:
竞赛日历 - Coggle数据科学
疫情微博情绪识别挑战赛Baseline(PaddlePaddle)-0.9735 - 飞桨AI Studio
其他数据挖掘实战案例: [订阅链接]
【数据挖掘实战】——航空公司客户价值分析(K-Means聚类案例)
【数据挖掘实战】——中医证型的关联规则挖掘(Apriori算法)
【数据挖掘实战】——家用电器用户行为分析及事件识别(BP神经网络)
【数据挖掘实战】——应用系统负载分析与容量预测(ARIMA模型)
【数据挖掘实战】——电力窃漏电用户自动识别(LM神经网络和决策树)
【数据挖掘实战】——基于水色图像的水质评价(LM神经网络和决策树)