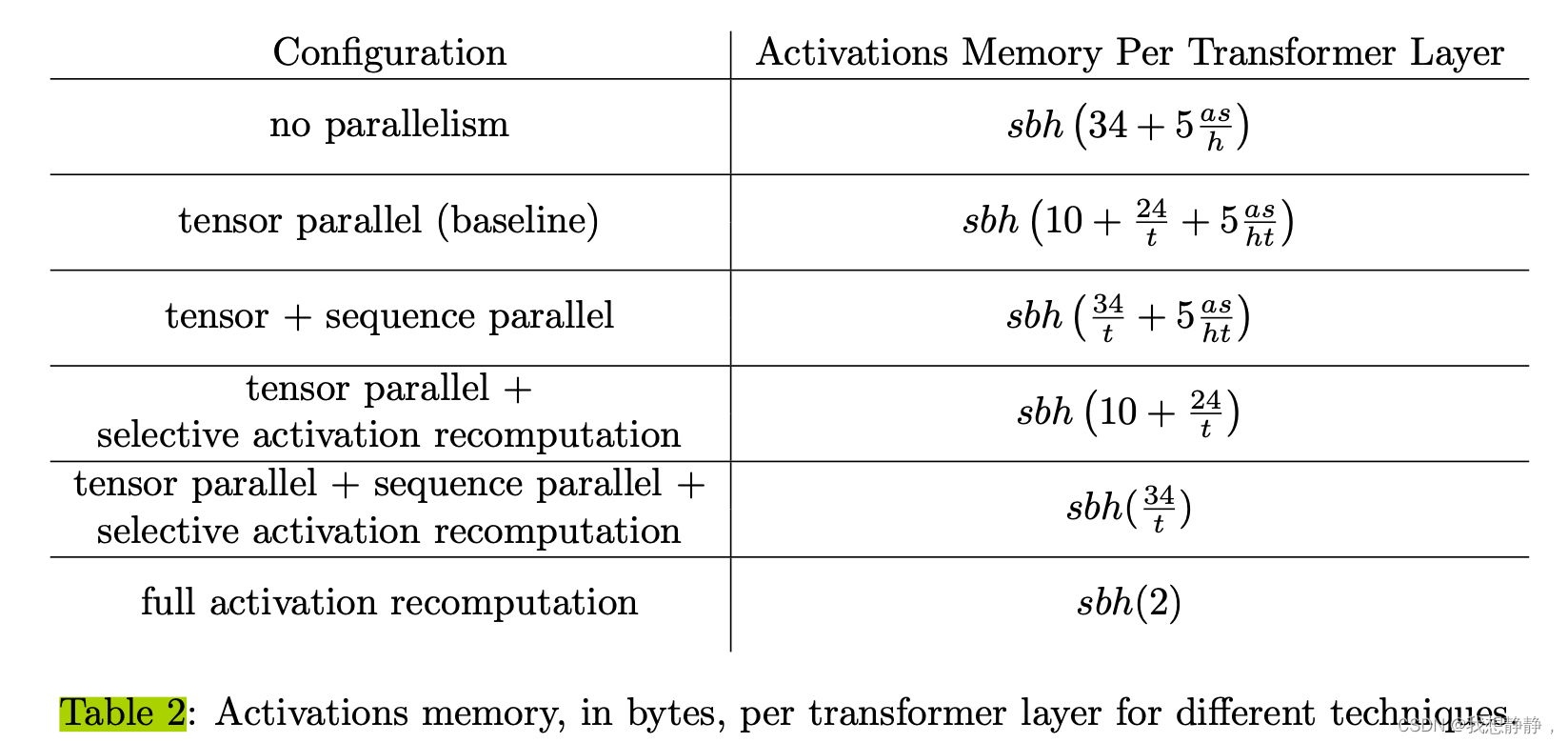
Mask RCNN---two stage
mask rcnn是一个分割算法(实例分割),可用于:
-
目标检测
-
实例分割
-
关键点检测

本质上,mask R-CNN是在faster rcnn的基础上,加入了FCN模块,得到最终的分割结果。
先检测,再分割。不是对整张feature map进行fcn,而是通过faster rcnn得到不同的region proposal,通过roi pooling将小特征图变为相同大小,对其进行fcn。
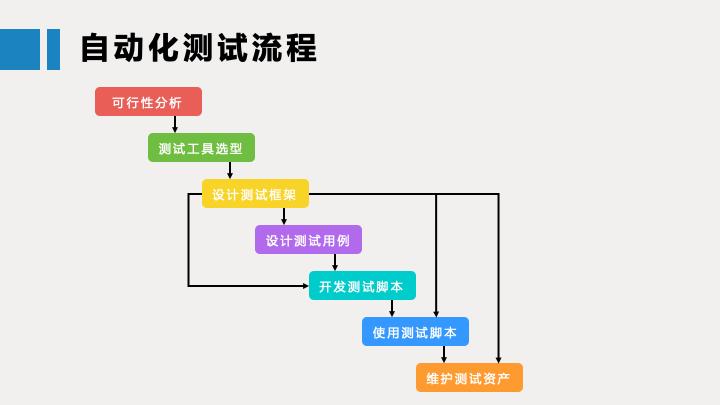
模型框架
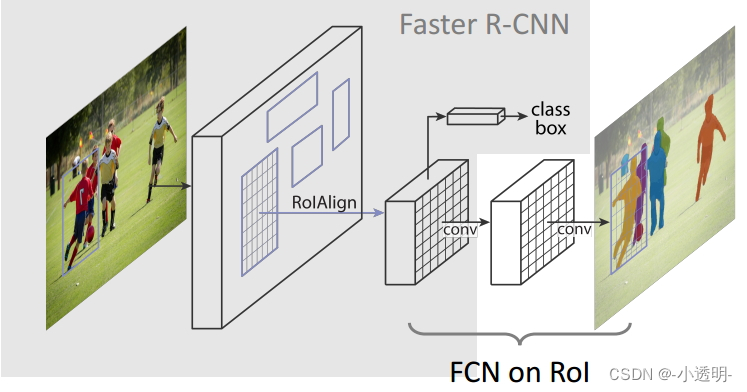
改进1: ROI Pooling → ROI Align
ROI Pooling的过程较为粗糙,存在两次量化过程,导致最终的定位精度不够精确。
给定一个feature map,得到了若干个Region Proposal
经过筛选后,这些proposal需要映射到feature map上,统一池化成7×7的尺寸
然而,该过程会发生两次量化误差。
第一次: 原图映射到feature map上产生误差。

假设一个region尺寸为665,映射到feature map上的时候缩小了32倍<2^5>(5次卷积)。
那么roi pooling选择的就是20×20的区域。
实际上,理论的尺寸为665/32=20.78, roi pooling将其约等于20,造成了0.78的误差。
0.78×32=24.96,因此造成的bbox的误差约为25个像素。
这对于小目标的尺寸会造成较大误差。
第二次 第二次误差来自于池化过程。
roi pooling在池化过程中,将feature按整数切割成若干个同等大小的块,然后分别取max。
也就是说按照整数坐标对图像进行池化。显然,这存在问题。
例如,20×20的feature进行池化,得到7×7,每个格子的坐标为2.86×2.86
这里取整数显然存在问题。
ROI Align
roi align则采用了浮点坐标的方式,来尽量减小量化误差。
其核心思想为:通过浮点数坐标的方式进行计算。虽然在浮点数上没有数值,也可以通过(双)线性插值的方式来得到像素值。
从大图中,找到region的四个角坐标(浮点数)
然后,在此区域将region划分成相等大小的7×7块
在这些块内,每个块产生4个坐标点,通过线性插值的方式来得到像素值。
然后对这些像素值进行池化处理。
改进2: FPN
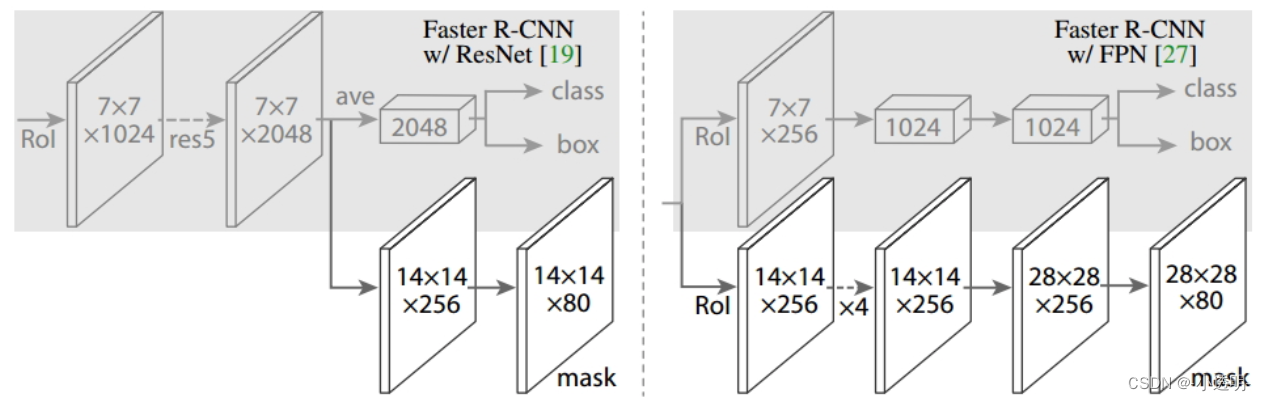
加入了FPN分支
右侧模型输出了更大的尺寸,从而能够获得更加精细的结果。
损失函数

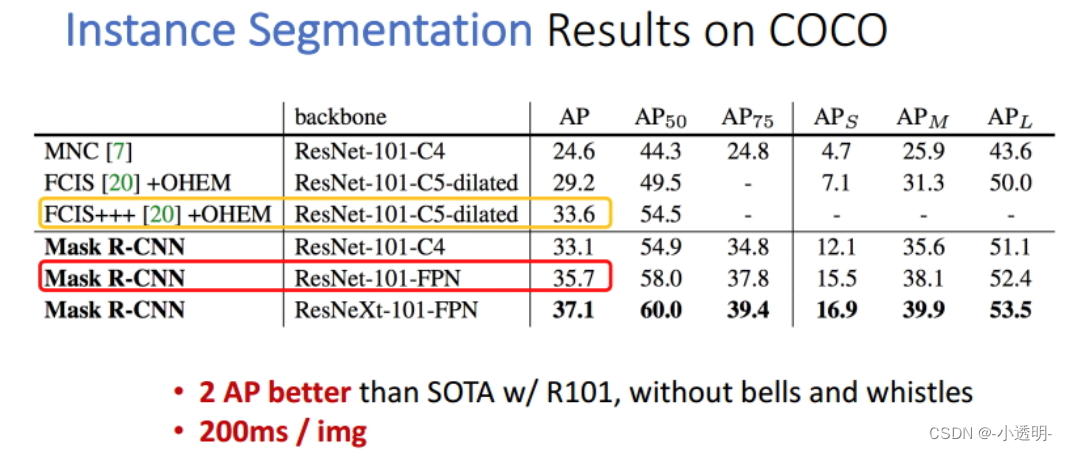
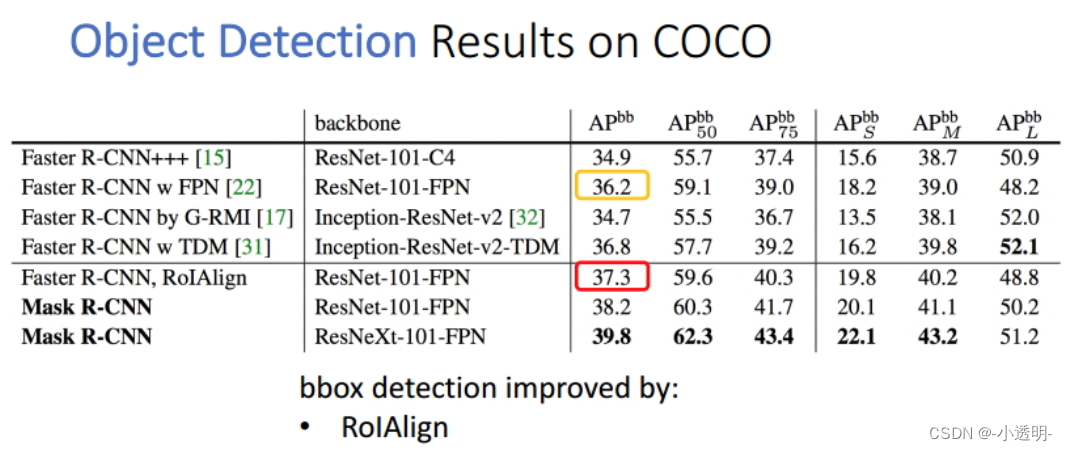
效果展示


注意力机制的语义分割
什么是注意力机制?
早期人们对注意力的认知,主要是上下文的关联,或者说是全局性的关联。
往往,一张图像中像素的语义,不仅仅和周围像素相关,也可能和较远的像素相关。
然而,受限于卷积的特性,无法从全局层面去观察图像,从而使得像素之间的上下文关联较为薄弱。
从另一个角度讲,注意力机制的存在一个重要作用,是为了更好的扩大感受野。
因此,空洞卷积(位置固定),从某种程度上来说,可以认为是注意力机制的萌芽。
同时需要注意的是,注意力机制不仅仅是扩大感受野。同时,包括:
扩大感受野:为了考虑到相隔较远的像素的关系
-
过滤不相干信息
-
建模长距离依赖性
基于注意力机制的模型--PSANet
psanet是较早使用注意力机制的模型。
在该模型之前,语义分割所面临的主要痛点在于:
-
感受野问题。堆叠卷积效果一般,空洞卷积位置固定,难以灵活建模和过滤信息
-
上下文信息难以结合。相距较远的像素区域存在强关联,但无法有效的关联起来
而PSANet针对上述问题的解决方案是:
利用自注意力机制,学习一个注意力掩膜mask,从而在特征层面关联建模,来解决局部特征的约束。
网络结构

input为特征,通过卷积得到两两之间注意力值<变长>(2h*2w),每一长条即:当前点与其他点的相关性;
其中,粉红色的块即得到的注意力特征;X为backbone的输出,经过上路(collect)和下路(distribute)两个分支融合后,得到最终输出。
以上内容即为注意力模块。
总体结构

代码
注意力模型2--DANet
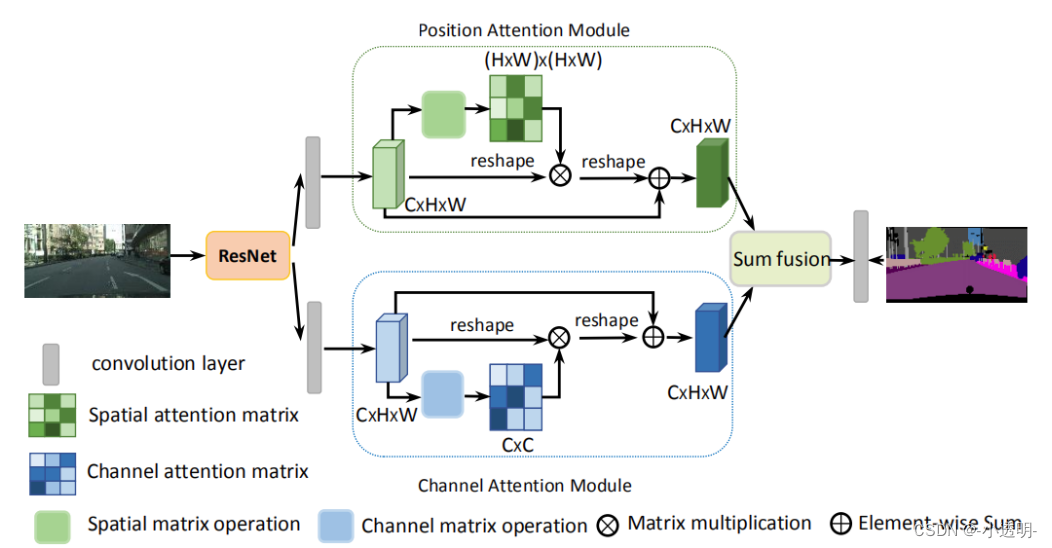
DANet创新性地将注意力划分成两种类型:
1. 通道间的注意力(蓝色的块)
2. 通道内的注意力(绿色的块)
以通道内注意力为例,其基本计算过程如下图所示
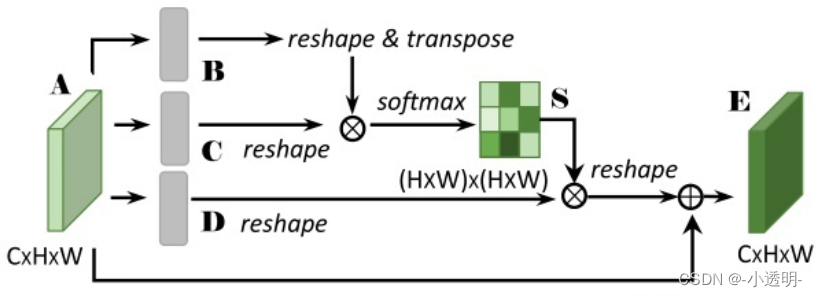
首先,给定A如下
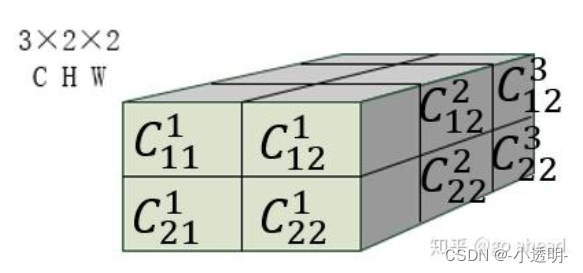
B经过reshape之后,得到
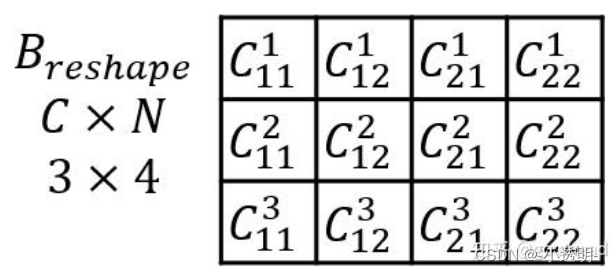
再转置,得到

那么B C矩阵相乘的结果为

最后,再乘以D,得到

这样,可以看出将同一个通道内的不同位置的信息,融合到了一起。
而通道间的注意力map经过类似的处理,得到了下图的结果

显然,他可以融合不同通道间的内容。
代码
CCNET:一种十字形的attention模块
non-block:非局部(即全局)
attention与原始特征相乘:即加权
(a)太慢了
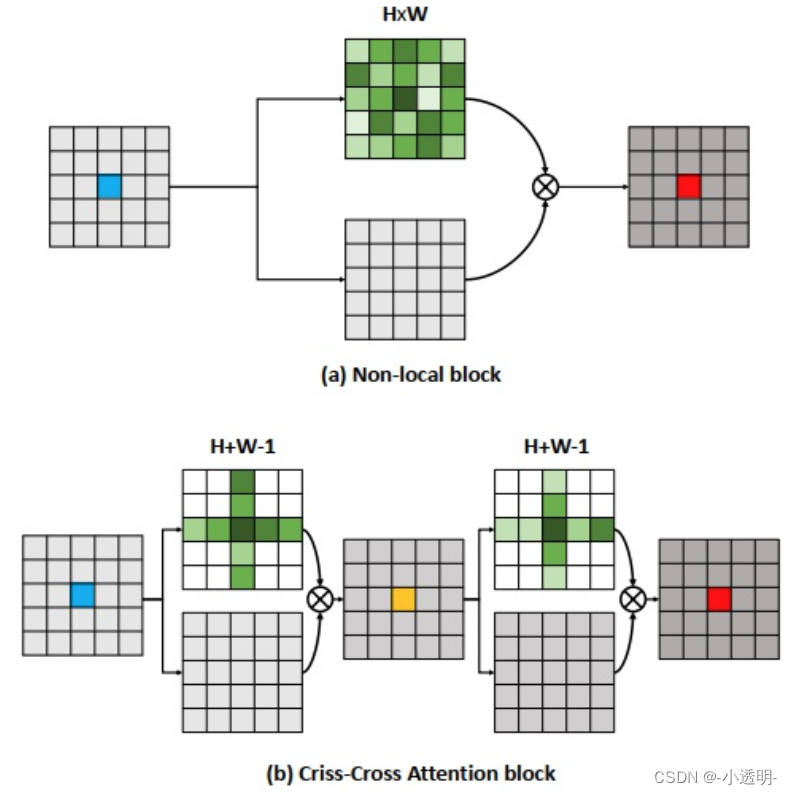
一种简化计算的注意力机制。
与级联操作 ( 3*3先经过1*3,在经过3*1:可以加速 ) 类似
经过两次十字attention,即可求解全局下的注意力。
网络结构
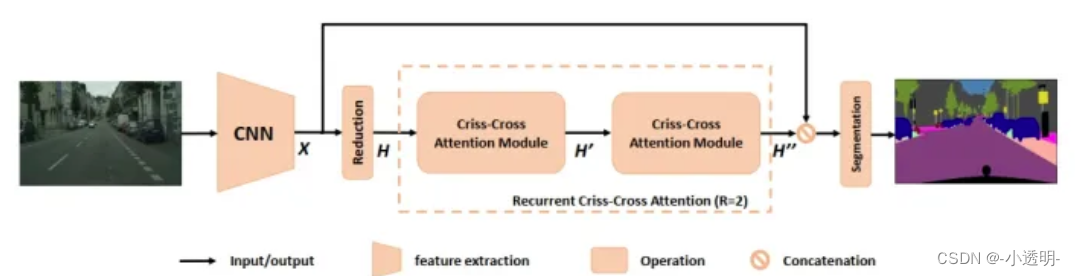
reducation:减小channels(为了减小计算量)
加入attention后,就不用加CRF就可以比较好的分割出边缘细节