数据仓库分析工具Hive
- 概述
- Hive简介
- Hive与Hadoop生态系统中其他组件的关系
- Hive与传统数据库的对比
- Hive系统架构
- 概述
- Hive组成模块
- Hive工作原理
- SQL语句转换成MapReduce的基本原理
- Hive中SQL查询转换成MapReduce作业的过程
- 从外部访问Hive的典型方式
- Hive的应用
- Hive在报表中心的应用流程
- Hive HA原理
- Impala
- Impala简介
- Impala系统架构
- Impala和Hive的对比
- Hive编程实践
- Hive的安装与配置
- Hive的数据类型
- Hive基本操作
- Hive应用
概述
Hive简介
- Hive是一个构建于Hadoop顶层的数据仓库工具
- 某种程度上可以看作是用户编程接口,本身不存储和处理数据
- 依赖分布式文件系统HDFS存储数据
- 依赖分布式并行计算模型MapReduce处理数据
- 定义了简单的类SQL 查询语言——HiveQL
- 用户可以通过编写的HiveQL语句运行MapReduce任务
- 是一个可以提供有效、合理、直观组织和使用数据的模型
Hive的特点:
采用批处理方式处理海量数据
Hive需要把HiveQL语句转换成MapReduce任务进行运行;
数据仓库存储的是静态数据,对静态数据的分析适合采用批处理方式,不需要快速响应给出结果,而且数据本身也不会频繁变化。提供适合数据仓库操作的工具
Hive本身提供了一系列对数据进行提取转化加载的工具,可以存储、查询和分析存储在Hadoop中的大规模数据;
非常适合数据仓库应用程序维护海量数据、对数据进行挖掘、形成意见和报告等。
Hive与Hadoop生态系统中其他组件的关系

- Hive依赖于HDFS 存储数据
HDFS作为高可靠性的底层存储,用来存储海量数据 - Hive依赖于MapReduce 处理数据
MapReduce对这些海量数据进行处理,实现高性能计算,用HiveQL语句编写的处理逻辑最终均要转化为MapReduce任务来运行 - Pig可以作为Hive的替代工具
Pig是一种数据流语言和运行环境,适合用于Hadoop和MapReduce平台上查询半结构化数据集。常用于ETL过程的一部分,即将外部数据装载到Hadoop集群中,然后转换为用户期待的数据格式 - HBase 提供数据的实时访问
HBase一个面向列的、分布式的、可伸缩的数据库,它可以提供数据的实时访问功能,而Hive只能处理静态数据,主要是BI报表数据,所以HBase与Hive的功能是互补的,它实现了Hive不能提供功能。
Hive与传统数据库的对比
Hive在很多方面和传统的关系数据库类似,但是它的底层依赖的是HDFS和MapReduce,所以在很多方面又有别于传统数据库。
Hive与传统数据库的区别主要体现在以下几个方面:
1)数据插入:在传统数据库中同时支持导入单条数据和批量数据,而Hive中仅支持批量导入数据,因为Hive主要用来支持大规模数据集上的数据仓库应用程序的运行,常见操作是全表扫描,所以单条插入功能对Hive并不实用
2)数据更新:更新是传统数据库中很重要的特性,Hive不支持数据更新。Hive是一个数据仓库工具,而数据仓库中存放的是静态数据,所以Hive不支持对数据进行更新。
3)索引:索引也是传统数据库中很重要的特性,Hive在hive 0.7版本后已经可以支持索引了。但Hive不像传统的关系型数据库那样有键的概念,它只提供有限的索引功能,使用户可以在某些列上创建索引来加速一些查询操作,Hive中给一个表创建的索引数据被保存在另外的表中。
4)分区:传统的数据库提供分区功能来改善大型表以及具有各种访问模式的表的可伸缩性,可管理性和提高数据库效率。Hive也支持分区功能,Hive表组织成分区的形式,根据分区列的值对表进行粗略的划分,使用分区可以加快数据的查询速度。
5)执行延迟:因为Hive构建于HDFS与MapReduce上,所以对比传统数据库来说Hive的延迟比较高,传统的SQL语句的延迟少于一秒,而HiveQL语句的延迟会达到分钟级。
6)扩展性:传统关系数据库很难横向扩展,纵向扩展的空间也很有限。相反Hive的开发环境是基于集群的,所以具有较好的可扩展性。
Hive系统架构
概述
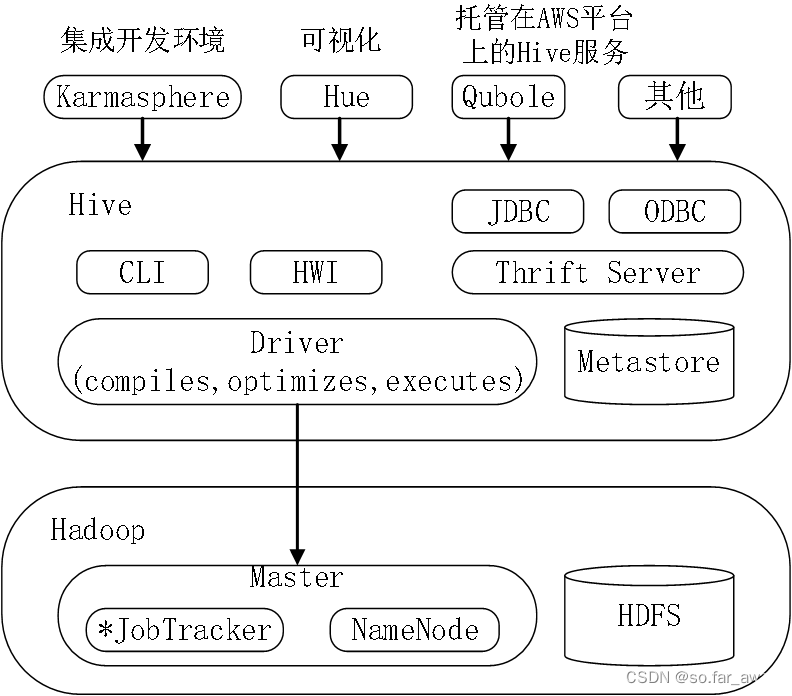
Hive组成模块
- 用户接口模块:包括CLI、HWI、JDBC、ODBC、Thrift Server等
CLI是Hive自带的一个命令行界面;
HWI是Hive的一个简单网页界面;
JDBC、ODBC以及Thrift Server可以向用户提供进行编程访问的接口。 - 驱动模块:包括编译器、优化器、执行器等
所有命令和查询都会进入到驱动模块,通过该模块对输入进行解析编译,对需求的计算进行优化,然后按照指定的步骤进行执行。 - 元数据存储模块(Metastore):是一个独立的关系型数据库
通常是与MySQL数据库连接后创建的一个MySQL实例,也可以是Hive自带的derby数据库实例。
元数据存储模块中主要保存表模式和其他系统元数据,如表的名称、表的列及其属性、表的分区及其属性、表的属性、表中数据所在位置信息等。
Hive工作原理
SQL语句转换成MapReduce的基本原理
join转化为MapReduce任务的具体过程:
- 在Map阶段,表user中记录(uid,name)映射为键值对(uid,<1,name>),表order中记录(uid, orderid)映射为键值对(uid,<2, orderid >)
1,2是表user和order的标记位
(1,Lily) ->(1,<1,Lily>), (1,101) ->(1,<2,101>) - 在Shuffle、Sort阶段, (uid,<1,name>)和(uid,<2, orderid >)按键uid的值进行哈希,然后传送给对应的Reduce机器执行,并在该机器上按表的标记位对这些键值对进行排序
(1,<1,Lily>)、(1,<2,101>)和 (1,<2,102>)传送到同一台Reduce机器上,并按该顺序排序
(2,<1,Tom>)和(2,<2,103>)传送到同一台Reduce机器上,并按该顺序排序 - 在Reduce阶段,对同一台Reduce机器上的键值对,根据表标记位对来自不同表的数据进行笛卡尔积连接操作,以生成最终的连接结果。
(1,<1,Lily>)∞(1,<2,101>) ->(Lily, 101)
(1,<1,Lily>)∞ (1,<2,102>) ->(Lily, 102)
(2,<1,Tom>) ∞(2,<2,103>) ->(Tom, 103)

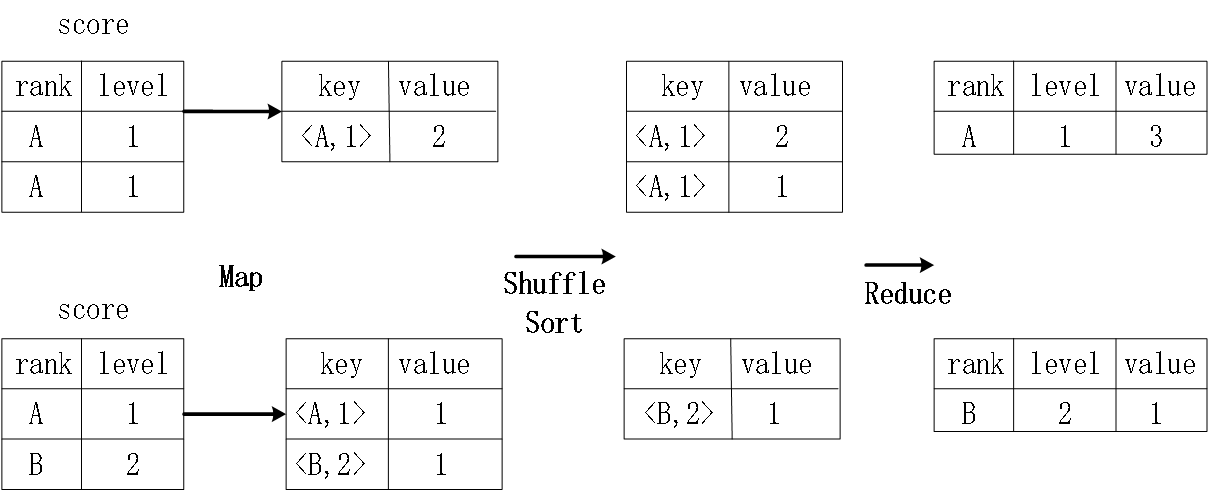
group by转化为MapReduce任务的具体过程:
- 在Map阶段,表score中记录(rank,level)映射为键值对(<rank,level> , count(rank,level))
score表的第一片段中有两条记录(A,1),(A,1) ->(<A,1> ,2)
score表的第二片段中有一条记录(A,1),(A,1) ->(<A,1> ,1) - 在Shuffle、Sort阶段, (<rank,level> ,count(rank,level))按键<rank,level>的值进行哈希,然后传送给对应的Reduce机器执行,并在该机器上按<rank,level>的值对这些键值对进行排序
(<A,1>,2)和 (<A,1>,1)传送到同一台Reduce机器上,按到达顺序排序
(<B,2>,1>)传送到另一台Reduce机器上 - 在Reduce阶段,对Reduce机器上的这些键值对,把具有相同<rank,level>键的所有count(rank,level)值进行累加,生成最终结果。
(<A,1>,2>)+ (<A,1>,1>) ->(A,1,3)
(<B,2>,1) ->(B,2,1)
Hive中SQL查询转换成MapReduce作业的过程
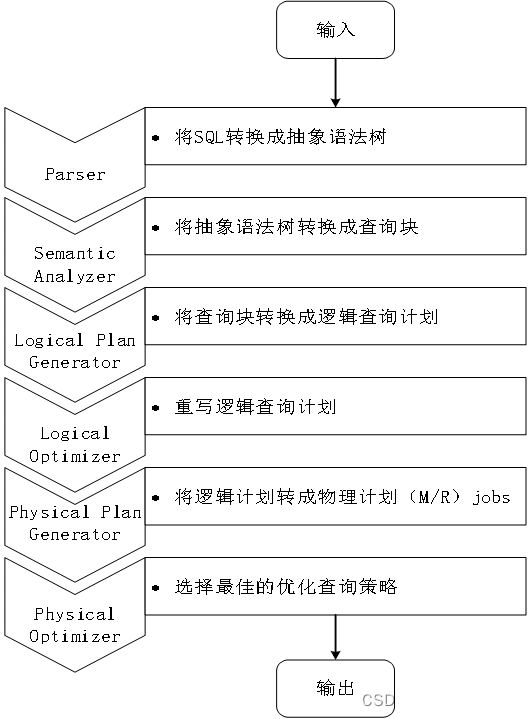
第1步:用户通过命令行CLI或其他Hive访问工具,向Hive输入一段命令或查询。
第2步:由Hive驱动模块中的编译器——Antlr语言识别工具,对用户输入的SQL语言进行词法和语法解析,将SQL语句转化为抽象语法树(AST Tree)的形式。
第3步:对该抽象语法树进行遍历,进一步转化成QueryBlock查询单元。QueryBlock是一条最基本的SQL语法组成单元,包括输入源、计算过程和输出三部分。
第4步:再对QueryBlock进行遍历,生成执行操作树(OperatorTree)。
第5步:通过Hive驱动模块中的逻辑优化器对OperatorTree进行优化。
第6步:对优化后的OperatorTree进行遍历,根据OperatorTree中的逻辑操作符生成需要执行的MapReduce任务。
第7步:启动Hive驱动模块中的物理优化器,对生成MapReduce任务进行优化,生成最终的MapReduce任务执行计划。
第8步:最后,由Hive驱动模块中的执行器,对最终的MapReduce任务进行执行。
注:
- 当启动MapReduce程序时,Hive本身是不会生成MapReduce算法程序的。
- Hive通过和JobTracker通信来初始化MapReduce任务,不必直接部署在JobTracker所在的管理节点上执行。
从外部访问Hive的典型方式
除了用CLI和HWI工具来访问Hive外,还可以采用以下几种典型外部访问工具:
1.Karmasphere是由Karmasphere公司发布的一个商业产品。
可以直接访问Hadoop里面结构化和非结构化的数据,可以运用SQL及其他语言,可以用于Ad Hoc查询和进一步的分析;
还为开发人员提供了一种图形化环境,可以在里面开发自定义算法,为应用程序和可重复的生产流程创建实用的数据集。
2.Hue是由Cloudera公司提供的一个开源项目
是运营和开发Hadoop应用的图形化用户界面;
Hue程序被整合到一个类似桌面的环境,以web程序的形式发布,对于单独的用户来说不需要额外的安装。
3.Qubole公司提供了**“Hive即服务”**的方式
托管在AWS平台,这样用户在分析存储在亚马逊S3云中的数据集时,就无需了解Hadoop系统管理;
提供的Hadoop服务能够根据用户的工作负载动态调整服务器资源配置,实现随需计算。
Hive的应用
构建于Hadoop上的数据仓库,除了依赖于Hadoop的基本组件HDFS和MapReduce外,还结合使用了Hive、Pig、HBase与Mahout。
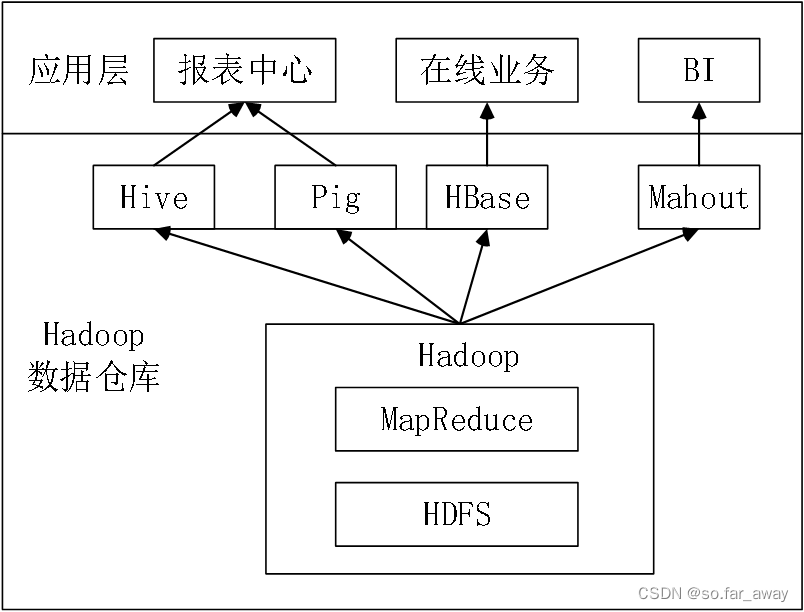
- Hive和Pig主要应用在报表中心上,Hive主要用于报表分析,Pig主要用于报表中数据的转换工作
- HBase主要用于在线业务,因为HDFS缺乏随机读写操作,而HBase正是为此开发的,支持实时访问数据
- Mahout常用于BI(商务智能) ,Mahout提供一些可扩展的机器学习领域的经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序
Hive在报表中心的应用流程
- 在Hadoop集群上构建的数据仓库由多个Hive进行管理
- 由HAProxy提供一个接口,对Hive实例进行访问
- 由Hive处理后得到的各种数据信息,或存放在MySQL数据库中,或直接以报表的形式展现
- 不同人员会根据所需数据进行相应工作
其中,HAProxy是Hive HA原理的具体实现。
Hive HA原理
- 将若干个hive 实例纳入一个资源池,然后对外提供一个唯一的接口,进行proxy relay
- 对于程序开发人员,就把它认为是一台超强“hive"。每次它接收到一个HIVE查询连接后,都会轮询资源池里可用的hive 资源
Impala
Impala简介
Impala是由Cloudera公司开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase上的PB级大数据。
Impala最开始是参照 Dremel系统进行设计的,Impala的目的不在于替换现有的MapReduce工具,而是提供一个统一的平台用于实时查询。
与Hive类似,Impala也可以直接与HDFS和HBase进行交互。
Hive底层执行使用的是MapReduce,所以主要用于处理长时间运行的批处理任务,例如批量提取、转化、加载类型的任务。
Impala通过与商用并行关系数据库中类似的分布式查询引擎,可以直接从HDFS或者HBase中用SQL语句查询数据,从而大大降低了延迟,主要用于实时查询。
Impala和Hive采用相同的SQL语法、ODBC 驱动程序和用户接口。
Impala系统架构
Impala主要由Impalad,State Store和CLI三部分组成。
1)Impalad是Impala的一个进程
负责协调客户端提交的查询的执行,给其他impalad分配任务以及收集其他impalad的执行结果进行汇总
执行其他impalad给其分配的任务,主要就是对本地HDFS和HBase里的部分数据进行操作
2)State Store会创建一个statestored进程
跟踪集群中的Impalad的健康状态及位置信息,用于查询的调度
创建多个线程来处理Impalad的注册订阅和与各类Impalad保持心跳连接
注:当State Store离线后,Impalad一旦发现State Store处于离线时,就会进入recovery模式,并进行反复注册;当State Store重新加入集群后,自动恢复正常,更新缓存数据。
3)CLI给用户提供查询使用的命令行工具
提供了Hue、JDBC及ODBC的使用接口
Impala采用与Hive相同的元数据、SQL语法、ODBC驱动程序和用户接口,这样做的主要原因是在使用同一公司Hadoop产品时,批处理和实时查询的平台是统一的
Impala和Hive的对比
Hive和Impala的不同点总结如下:
- Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询。(适用场景)
- Hive依赖于MapReduce计算框架,执行计划组合成管道型的MapReduce任务模式进行执行,Impala把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询。(原理)
- Hive在执行过程中,如果内存放不下所有数据,则会使用外存,以保证查询能顺序执行完成,而Impala在遇到内存放不下数据时,不会利用外存,所以Impala目前处理查询时会受到一定的限制。(内存)
Hive与Impala的相同点总结如下:
- Hive与Impala使用相同的存储数据池都支持把数据存储于HDFS和HBase中,其中HDFS支持存储TEXT、RCFILE、PARQUET、AVRO、ETC格式数据,HBase存储表中记录。
- Hive与Impala使用相同的元数据。
- Hive与Impala中对SQL的解释处理比较相似,都是通过词法分析生成执行计划。
Hive编程实践
Hive的安装与配置
1.Hive安装
安装Hive之前需要安装jdk1.6以上版本以及启动Hadoop。
2.Hive配置
Hive有三种运行模式,单机模式、伪分布式模式、分布式模式。
Hive的数据类型
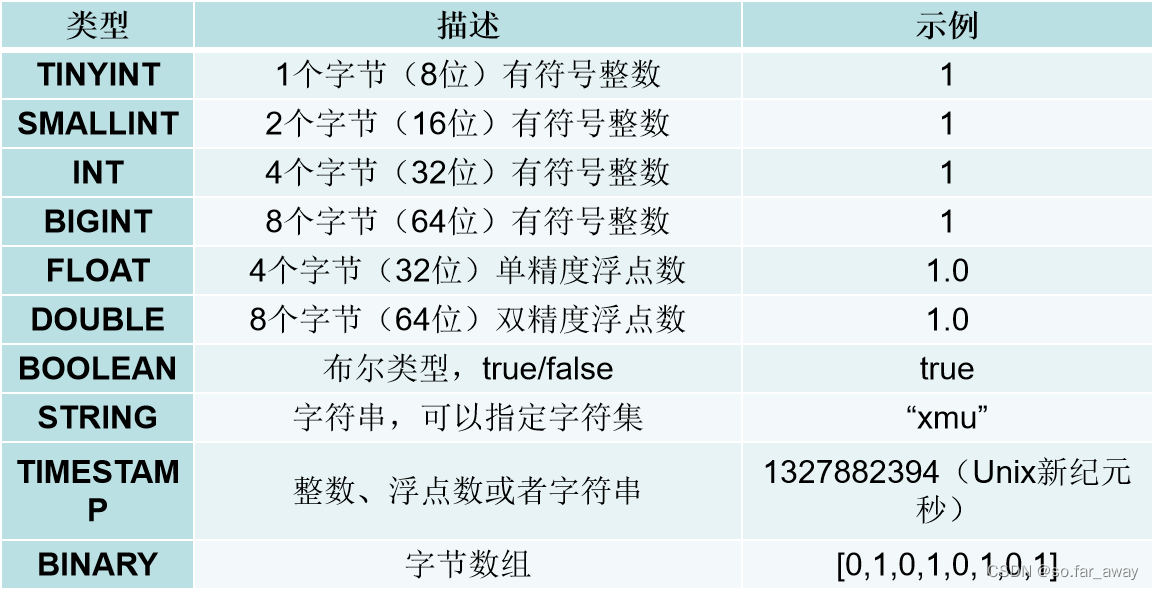
1.Hive的基本数据类型
2.Hive的集合数据类型

Hive基本操作
1.create:创建数据库、表、视图
2.drop:删除数据库、表、视图
3.alter:修改数据库、表、视图
4. show:查看数据库、表、视图
5. describe:描述数据库、表、视图
6. load:向表中装载数据
7. insert:向表中插入数据或从表中导出数据
Hive应用
在MapReduce的实现中,需要进行编译生成jar文件来执行算法,而在Hive中不需要。
HiveSQL语句的最终实现需要转化成MapReduce任务来执行,这都是由Hive框架自动完成的,用户不需要了解具体实现细节。