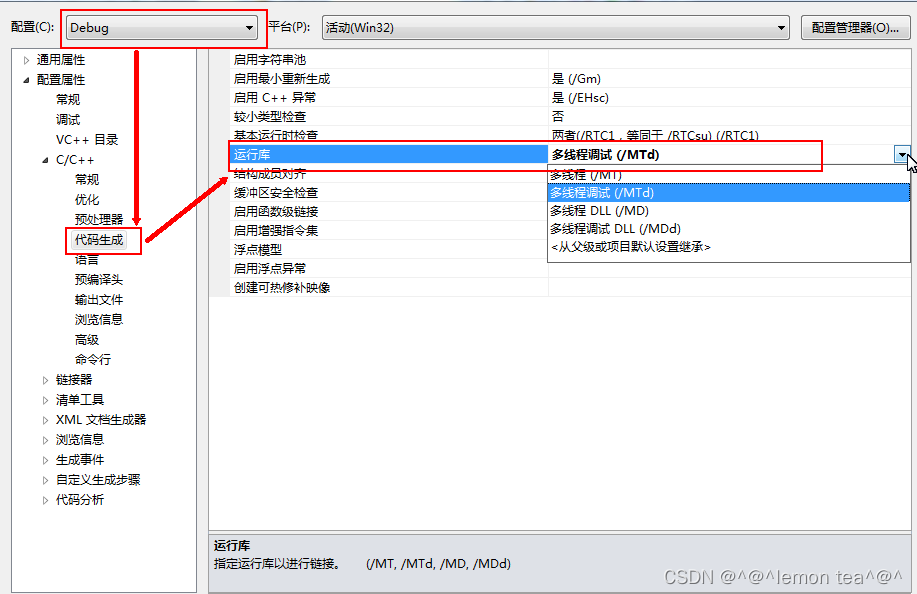
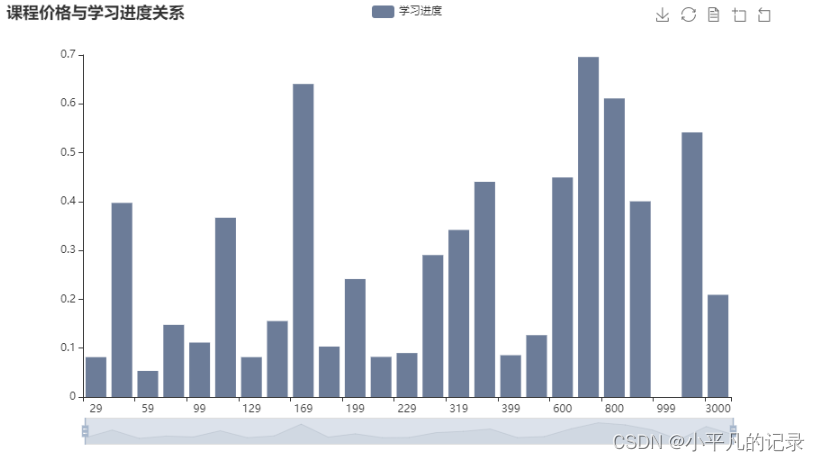
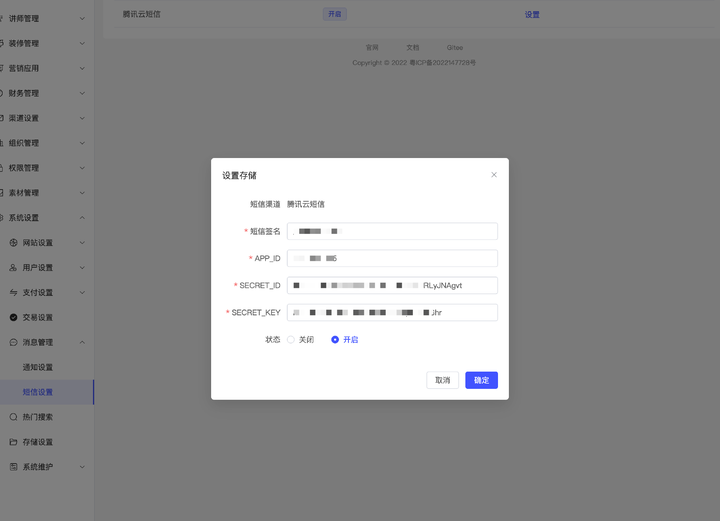
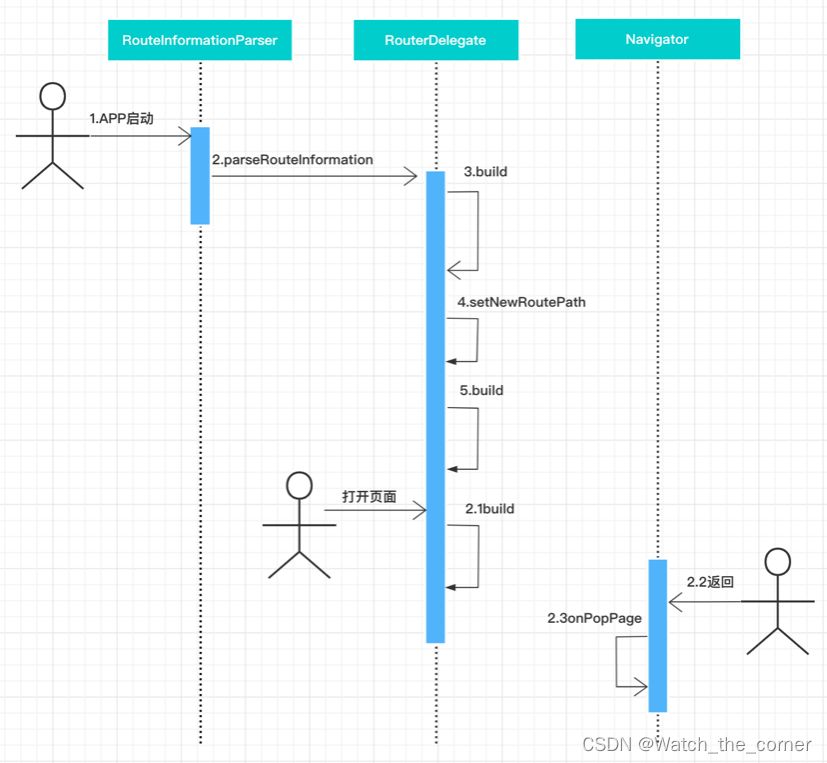
Scrapy是一个Python编写的高级网络爬虫框架,它可以帮助开发者快速、高效地从网站上获取数据。以下是学习Scrapy框架的一些步骤和建议:
-
学习Python基础知识:Scrapy是用Python编写的,因此需要掌握Python的基础知识,包括语法、数据类型、函数、模块等。
-
学习HTTP协议和HTML语言:Scrapy是基于HTTP协议和HTML语言的,因此需要了解HTTP协议和HTML语言的基本知识,包括请求和响应、状态码、标签、属性等。
-
学习Scrapy框架的基本概念:Scrapy框架有一些基本概念,如Spider、Item、Pipeline、Downloader等,需要了解它们的作用和使用方法。
-
安装Scrapy框架:可以使用pip命令安装Scrapy框架,也可以从官网下载源码进行安装。
-
编写第一个Spider:可以从一个简单的例子开始,编写一个Spider来爬取网站上的数据,了解Spider的基本用法和流程。
-
学习Scrapy框架的高级功能:Scrapy框架还有一些高级功能,如中间件、调度器、扩展等,需要深入学习和掌握。
-
实践项目:通过实践项目来巩固和应用所学的知识,可以选择一些简单的项目,如爬取新闻、图片、电影等数据。
Scrapy框架实例
以下是一个简单的Scrapy爬虫框架实例,用于爬取豆瓣电影Top250的电影信息:
import scrapy
class DoubanMovieSpider(scrapy.Spider):
name = 'douban_movie'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
# 获取电影列表
movie_list = response.xpath('//div[@class="article"]//ol[@class="grid_view"]/li')
for movie in movie_list:
# 获取电影信息
title = movie.xpath('.//span[@class="title"]/text()').extract()
rating = movie.xpath('.//span[@class="rating_num"]/text()').extract()
yield {
'title': title,
'rating': rating
}
# 获取下一页链接
next_page = response.xpath('//span[@class="next"]/a/@href')
if next_page:
url = response.urljoin(next_page[0].extract())
yield scrapy.Request(url, self.parse)
在这个例子中,我们定义了一个名为DoubanMovieSpider的爬虫,它会爬取豆瓣电影Top250的电影信息。我们指定了爬虫的起始URL和允许的域名,然后在parse方法中解析响应并提取电影信息。我们使用XPath选择器来获取电影标题和评分,并将它们作为字典的键值对返回。最后,我们使用XPath选择器获取下一页链接,并使用scrapy.Request方法发送请求来继续爬取下一页。
要运行这个爬虫,可以在命令行中输入以下命令:
scrapy runspider douban_movie.py -o movies.csv
这将运行我们的爬虫,并将结果保存到名为movies.csv的CSV文件中。
总之,学习Scrapy框架需要掌握Python基础知识、HTTP协议和HTML语言,了解Scrapy框架的基本概念和使用方法,深入学习和掌握高级功能,并通过实践项目来巩固和应用所学的知识。