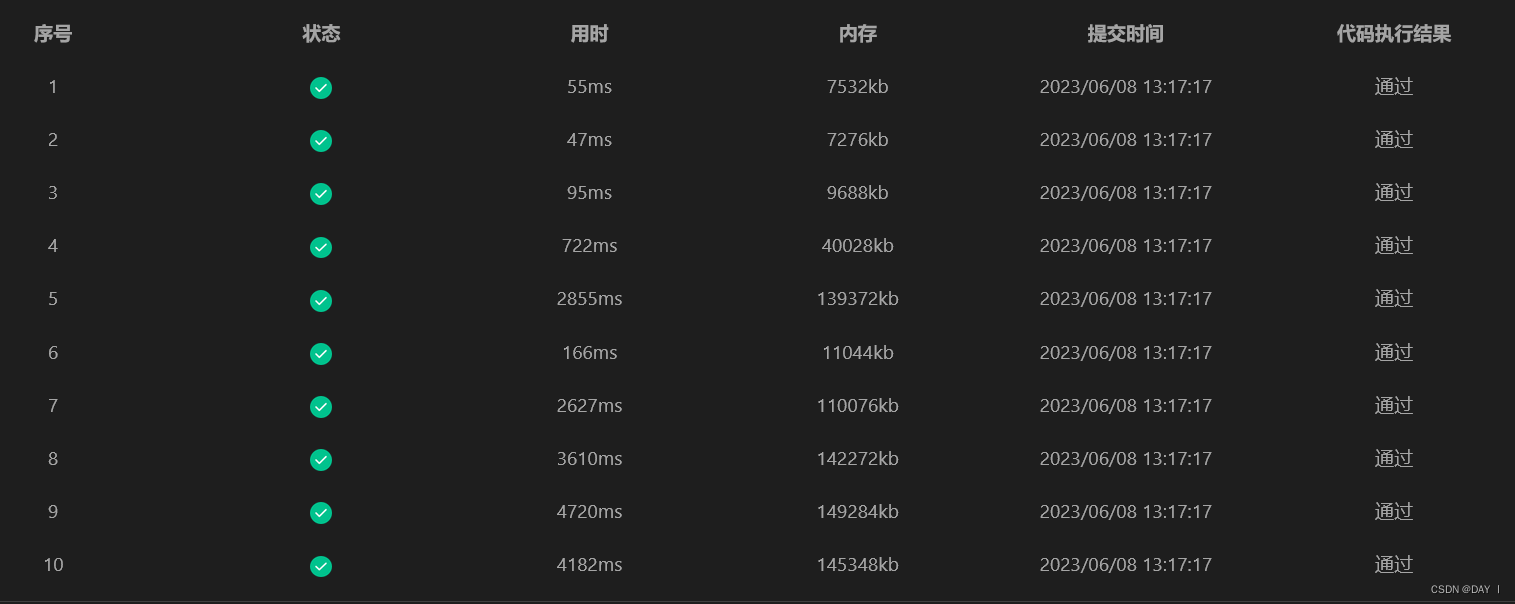
蓝桥杯2022国赛真题——交通信号

题目导航:
交通信号

🎇思路: d i j k s t r a dijkstra dijkstra
🔱思路分析:
要求从一点到另一点的最短距离,即为单源最短路径问题,用 d i j k s t r a dijkstra dijkstra算法
step:
🚀1.构图:
本题描述为有向图,但其实是一个的无向图,其权值相同,只是能通过时所对应的灯的颜色不同,正向走对应绿灯时能通过,反向走对应红灯时能通过

而难点就在于如何构图,每条边之间不仅有权值(边长 = = == ==黄灯时间),还可能存在等待相应灯的时间,也就是说,每到一个新的结点时,在继续前往下一个结点之前,要先看红绿灯,因此,对于此类边上信息复杂的图,我们 用类表示一条边:
c l a s s E d g e : class\ Edge: class Edge:
self.to_red:到达红灯的时间self.circle:一个周期:绿 → → →黄 → → →红 → → →黄forward(t):表示当前结点到另一结点时正向走的,即只有绿灯时能走, t t t 表示当前时间, r e t u r n return return 到绿灯时需要等待的时间back(t):表示当前结点到另一结点是反向走的,即只有红灯时能走, t t t 表示当前时间, r e t u r n return return 到红灯时需要等待的时间
class Edge:
def __init__(self,green,red,yellow):
self.g,self.r,self.d=green,red,yellow # 存放该边上的绿灯、红灯时间和距离
self.to_red=self.g+self.d # 到达红灯的时间
# 一个循环的时间: 绿 -> 黄 -> 红 -> 黄
self.circle=self.g+self.r+self.d+self.d # 一个周期的时间
def forward(self,t): # 计算正向时的时间
t%=self.circle
return self.d+ (0 if t<self.g else self.circle-t) # 通过时间+等待时间
def back(self,t): # 计算反向时的时间
t=(t-self.to_red)%self.circle # 以红灯为周期起点
return self.d+ (0 if t<self.r else self.circle-t)
再用邻接表存放这些结点和边,对于给出的点 i , j i,j i,j 来说,正向为: i → j i→j i→j,反向为: j → i j→i j→i
而这里涉及到了 p y t h o n python python的两个语法:
✅ 1. ∗ * ∗ 打包与解引用:
①*a=tuple(map(int,input().split())):表示打包,将输入的元素打包为元组(或列表)类型,带
∗
*
∗ 的赋值目标必须位于列表或元组中
②e=Edge(*a):表示对打包的元组
a
a
a 进行解引用再作为参数到类中
✅ 2. 元组内存放类内方法:
在 P y t h o n Python Python中,方法实际上是定义在类中的函数,可以像其他函数一样存储在元组中,但是需要注意,通过元组调用方法时,需要使用对应的对象或类来调用。例如:
class MyClass:
def my_method(self,t):
print("Hello World"+t)
my_tuple = (MyClass().my_method,1)
my_tuple[0]('!') # 输出:Hello World!
因此,我们可以在结点 i , j i,j i,j 对应的元组中存放不同的方法,在调用时,直接按照对应的方法得到等待时间即可,对于正向 i → j i→j i→j,到绿灯的时间即为等待时间,存放 f o r w a r d forward forward 方法;反向为 j → i j→i j→i,到红灯的时间即为等待时间,存放 b a c k back back 方法:
n,m,start,end=map(int,input().split())
g=[[] for _ in range(n+1)] # 存图
for _ in range(m):
i,j,*a=tuple(map(int,input().split())) # 这里*a是将剩余的传入的参数打包为元组(g,r,d)
e=Edge(*a) # 这里的*a是将元组a=(g,r,d)解包为g,r,d初始化一个类
g[i].append((j,e.forward)) # 对于i来说,到结点j为正向,并传递计算时间类内方法
g[j].append((i,e.back)) # 对于j来说,到结点i为反向
🚀2. D i j k s t r a Dijkstra Dijkstra 算法
D i j k s t r a Dijkstra Dijkstra 算法:即每一轮不断选取当前的路径最短且未被确定为最短路径的点,该点的值即为到达该点的最短路径,做上标记,并以该点去更新与之相邻且未确定最短路径的结点的值,取 m i n min min,直到所有结点都已经得到了最短路径
🎁图解算法:
-
先构建一张图,初始化到所有点的最短路径为 ∞ ∞ ∞

-
假设要求点 A → F A→F A→F 的最短路径,我们则以点 A A A 为源点,则到点 A A A 的最短距离为 0 0 0

-
此时不难发现,所有点中,路径最小的点即为 A A A,则表示 A A A 已经找到了最短路径,做上标记,并更新与 A A A 相邻点 B , C B,C B,C 的最短距离

-
更新之后,此时的最短路径对应的点为点 C C C,表示点 C C C 已经找到了最短路径,做上标记之后,更新与 C C C 相邻的未做标记的点 B , D , E B,D,E B,D,E 的最短路径

-
重复操作,直到遍历完整张图,得到源点到 F F F 点的最短路径

由于 d i j k s t r a dijkstra dijkstra 算法需要不断得到当前的最小路径对应的结点,因此我们用小根堆对当前结点进行储存
💫 p y t h o n python python中的优先队列即为小根堆,即内部的存储结构为二叉树,树的根结点保证为最小权值点,其数组的存储方式为层序存储:

🎇优先队列 P r i o r i t y Q u e u e PriorityQueue PriorityQueue:
- 导包: f r o m q u e u e i m p o r t P r i o r i t y Q u e u e from\ queue\ import\ PriorityQueue from queue import PriorityQueue
- 入队: q . p u t ( ) q.put() q.put()
- 出队: q . g e t ( ) q.get() q.get()
- 队列大小: q . q s i z e ( ) q.qsize() q.qsize()
代码实现:
from queue import PriorityQueue
def dijkstra(start):
"""
源点:start
到源点某结点的最短时间数组:d
优先队列:v
结点的被标记情况:vis
"""
d=[float('inf') for _ in range(n+1)] # d[i]表示源点start到点i的最短时间
d[start]=0
vis=[True for _ in range(n+1)] # True:已找到最短路径;False:未找到最短路径
v=PriorityQueue() # 实例化优先队列
v.put((0,start)) # 记录当前到结点node的最短距离 (d,node)
while v:
m=v.get()[1] # 利用优先队列得到当前距里源点最近的点
if m==end:
break
if vis[m]: # 如果点m还未找到最短路径
vis[m]=False
for m_node,get_time in g[m]: # 访问与结点m相邻的点
if vis[m_node]: # 还是先判断与m相邻的点是否被标记过,避免重复判断
time=d[m]+get_time(d[m]) # 得到这条路径到m_node的时间
if time<d[m_node]:
d[m_node]=time
v.put((d[m_node],m_node))
else:
continue # 表示当前结点是之前已经找到最短距离的点
return d[end]
d i j k s t r a dijkstra dijkstra 算法实现:
from queue import PriorityQueue
class Edge:
def __init__(self,green,red,yellow):
self.g,self.r,self.d=green,red,yellow # 存放该边上的绿灯、红灯时间和距离
self.to_red=self.g+self.d # 到达红灯的时间
# 一个循环的时间: 绿 -> 黄 -> 红 -> 黄
self.circle=self.g+self.r+self.d+self.d # 一个周期的时间
def forward(self,t): # 计算正向时的时间
t%=self.circle
return self.d+ (0 if t<self.g else self.circle-t) # 通过时间+等待时间
def back(self,t): # 计算反向时的时间
t=(t-self.to_red)%self.circle # 以红灯为周期起点
return self.d+ (0 if t<self.r else self.circle-t)
def dijkstra(start):
"""
源点:start
到源点某结点的最短时间数组:d
优先队列:v
结点的被标记情况:vis
"""
global d,vis
v=PriorityQueue() # 实例化优先队列
v.put((0,start)) # 记录当前到结点node的最短距离 (d,node)
while v:
m=v.get()[1] # 利用优先队列得到当前距里源点最近的点
if m==end:
break
if vis[m]: # 如果点m还未找到最短路径
vis[m]=False
for m_node,get_time in g[m]: # 访问与结点m相邻的点
if vis[m_node]: # 还是先判断与m相邻的点是否被标记过,避免重复判断
time=d[m]+get_time(d[m]) # 得到这条路径到m_node的时间
if time<d[m_node]:
d[m_node]=time
v.put((d[m_node],m_node))
else:
continue # 表示当前结点是之前已经找到最短距离的点
return d[end]
n,m,start,end=map(int,input().split())
g=[[] for _ in range(n+1)] # 存图
for _ in range(m):
i,j,*a=tuple(map(int,input().split())) # 这里*a是将剩余的传入的参数打包为元组(g,r,d)
e=Edge(*a) # 这里的*a是将元组a=(g,r,d)解包为g,r,d初始化一个类
g[i].append((j,e.forward)) # 对于i来说,到结点j为正向,并传递计算时间类内方法
g[j].append((i,e.back)) # 对于j来说,到结点i为反向
d=[float('inf') for _ in range(n+1)] # d[i]表示源点start到点i的最短时间
d[start]=0
vis=[True for _ in range(n+1)] # True:已找到最短路径;False:未找到最短路径
res=dijkstra(start)
if res<float('inf'):
print(res)
else:
print(-1)
输出结果: