文章目录
- 一、RDD为何物
- (一)RDD概念
- (二)RDD示例
- (三)RDD主要特征
- 二、做好准备工作
- (一)准备文件
- 1、准备本地系统文件
- 2、启动HDFS服务
- 3、上传文件到HDFS
- (二)启动Spark Shell
- 1、启动Spark服务
- 2、启动Spark Shell
- 三、创建RDD
- (一)通过并行集合创建RDD
- 1、利用`parallelize()`方法创建RDD
- 2、利用`makeRDD()`方法创建RDD
- 3、简单说明
- (二)从外部存储创建RDD
- 1、从文件系统加载数据创建RDD
- 课堂练习:给输出数据添加行号
- 2、从HDFS中加载数据创建RDD
- 四、读取文件的问题
- (一)以集群方式启动Spark Shell
- 1、读取本地文件
- 2、读取HDFS文件
- (二)以本地模式启动Spark Shell
- 1、读取本地文件
- 2、访问HDFS文件
- (三)结论
一、RDD为何物

(一)RDD概念
Spark提供了一种对数据的核心抽象,称为弹性分布式数据集(Resilient Distributed Dataset,RDD)。这个数据集的全部或部分可以缓存在内存中,并且可以在多次计算时重用。RDD其实就是一个分布在多个节点上的数据集合。RDD的弹性主要是指当内存不够时,数据可以持久化到磁盘,并且RDD具有高效的容错能力。分布式数据集是指一个数据集存储在不同的节点上,每个节点存储数据集的一部分。
传统的MapReduce虽然具有自动容错、平衡负载和可拓展性的优点,但是其最大缺点是采用非循环式的数据流模型,使得在迭代计算式要进行大量的磁盘IO操作。Spark中的RDD可以很好的解决这一缺点。RDD是Spark提供的最重要的抽象概念,我们可以将RDD理解为一个分布式存储在集群中的大型数据集合,不同RDD之间可以通过转换操作形成依赖关系实现管道化,从而避免了中间结果的I/O操作,提高数据处理的速度和性能。
(二)RDD示例
将数据集(hello, world, scala, spark, love, spark, happy)存储在三个节点上,节点一存储(hello, world),节点二存储(scala, spark, love),节点三存储(spark, happy),这样对三个节点的数据可以并行计算,并且三个节点的数据共同组成了一个RDD。
分布式数据集类似于HDFS中的文件分块,不同的块存储在不同的节点上;而并行计算类似于使用MapReduce读取HDFS中的数据并进行Map和Reduce操作。Spark则包含这两种功能,并且计算更加灵活。
在编程时,可以把RDD看作是一个数据操作的基本单位,而不必关心数据的分布式特性,Spark会自动将RDD的数据分发到集群的各个节点。Spark中对数据的操作主要是对RDD的操作(创建、转化、求值)。
(三)RDD主要特征
RDD是不可变的,但可以将RDD转换成新的RDD进行操作。
RDD是可分区的。RDD由很多分区组成,每个分区对应一个Task任务来执行。
对RDD进行操作,相当于对RDD的每个分区进行操作。
RDD拥有一系列对分区进行计算的函数,称为算子。
RDD之间存在依赖关系,可以实现管道化,避免了中间数据的存储。
二、做好准备工作
(一)准备文件
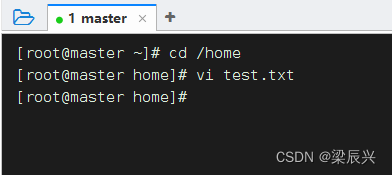
1、准备本地系统文件
在/home目录里创建test.txt
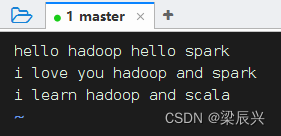
单词用空格分隔
2、启动HDFS服务
执行命令:start-dfs.sh
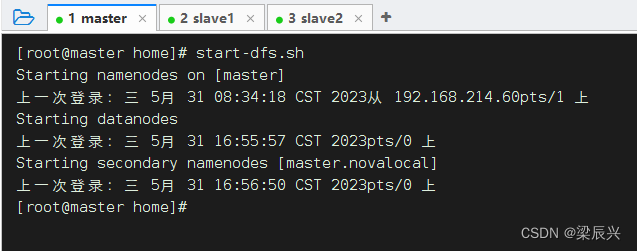
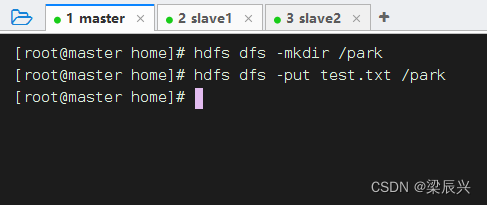
3、上传文件到HDFS
将test.txt上传到HDFS的/park目录里
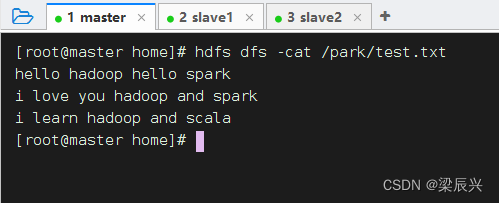
查看文件内容
(二)启动Spark Shell
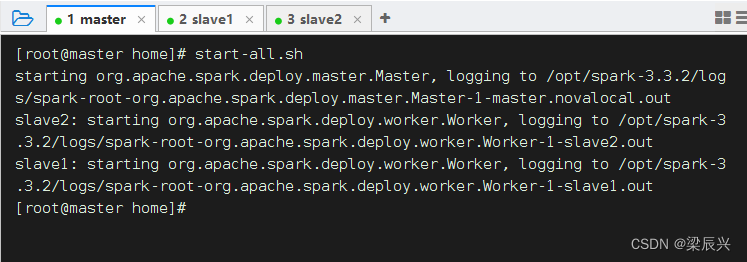
1、启动Spark服务
执行命令:start-all.sh
2、启动Spark Shell
执行命令:spark-shell(既可以读取本地文件,也可以读取HDFS文件)
 查看Spark Shell的WebUI界面:http://master:4040/jobs/
查看Spark Shell的WebUI界面:http://master:4040/jobs/
查看执行器
三、创建RDD
RDD中的数据来源可以是程序中的对象集合,也可以是外部存储系统中的数据集,例如共享文件系统、HDFS、HBase或任何提供HadoopInputFormat的数据源。
(一)通过并行集合创建RDD
Spark可以通过并行集合创建RDD。即从一个已经存在的集合、数组上,通过SparkContext对象调用parallelize()或makeRDD()方法创建RDD。
1、利用parallelize()方法创建RDD
执行命令:val rdd = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8))
 执行命令:
执行命令:val rdd = sc.parallelize(Array(100, 300, 200, 600, 500, 900))

说明:不能基于Map、Tuple和Set来创建RDD
2、利用makeRDD()方法创建RDD
执行命令:val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8))
 执行命令:
执行命令:rdd.collect(),收集rdd数据进行显示
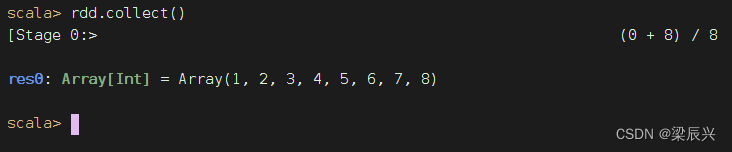
其实,行动算子[action operator]collect()的括号可以省略的
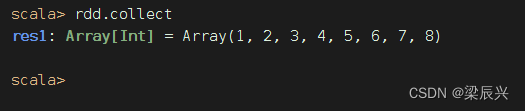
思考题:取出rdd中的偶数
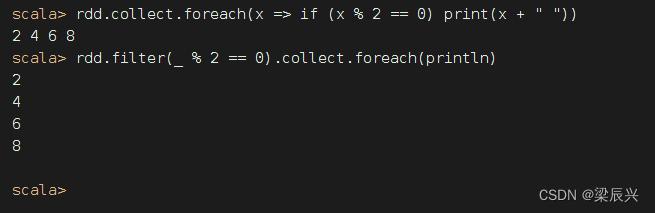
下一节,我们会详细学习RDD算子(转换算子和行动算子)
3、简单说明
从上述命令执行的返回信息可以看出,上述创建的RDD中存储的是Int类型的数据。实际上,RDD也是一个集合,与常用的List集合不同的是,RDD集合的数据分布于多台机器上。
(二)从外部存储创建RDD
Spark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统。我们通过Spark中的SparkContext对象调用textFile()方法加载数据创建RDD。
Spark的textFile()方法可以读取本地文件系统或外部其他系统中的数据,并创建RDD。不同的是,数据的来源路径不同。
先前我们以本地模式启动了Spark Shell,既可以访问本地文件,也可以访问HDFS文件。
1、从文件系统加载数据创建RDD
执行命令:val rdd = sc.textFile("file:///home/test.txt")

注意:访问本地文件,必须加file://前缀,否则系统会认为是访问hdfs://master:9000/home/test.txt,从而会报错。
执行命令:val lines = rdd.collect,查看RDD中的内容,保存到常量lines
 执行命令:
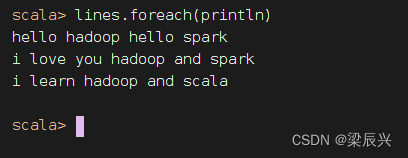
执行命令:lines.foreach(println)(利用foreach遍历算子)
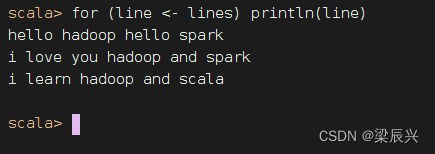
执行命令:for (line <- lines) println(line)
课堂练习:给输出数据添加行号
利用for循环来实现
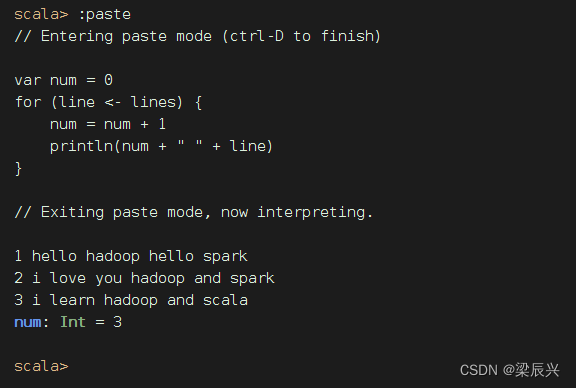
利用foreach遍历算子来实现
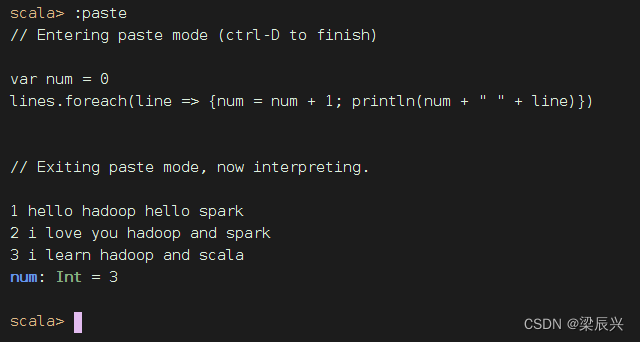
2、从HDFS中加载数据创建RDD
执行命令:val rdd = sc.textFile("hdfs://master:9000/park/test.txt")

执行命令:val lines = rdd.collect,查看RDD中的内容

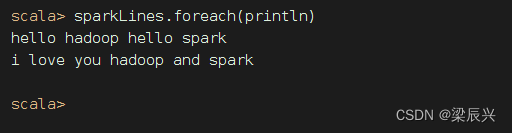
获取包含spark的行,执行命令:val sparkLines = rdd.filter(line => line.contains("spark"))(filter是一个转换算子[transformation operator])
 其实,有更简单的写法,执行命令:
其实,有更简单的写法,执行命令:val sparkLines = rdd.filter(_.contains("spark"))

利用遍历算子显示sparkLines内容
四、读取文件的问题
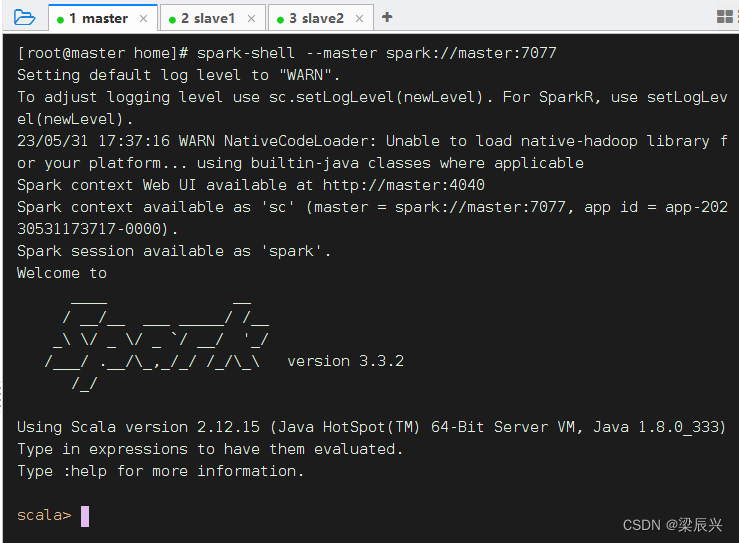
(一)以集群方式启动Spark Shell
执行命令:spark-shell --master spark://master:7077
1、读取本地文件
执行命令:val rdd = sc.textFile("file:///home/test.txt")
 执行命令: rdd.collect,报错 - Input path does not exist: hdfs://master:9000/home/test.txt
执行命令: rdd.collect,报错 - Input path does not exist: hdfs://master:9000/home/test.txt

结论:集群模式启动的Spark Shell不能读取本地文件
2、读取HDFS文件
执行命令:val rdd = sc.textFile("hdfs://master:9000/park/test.txt")
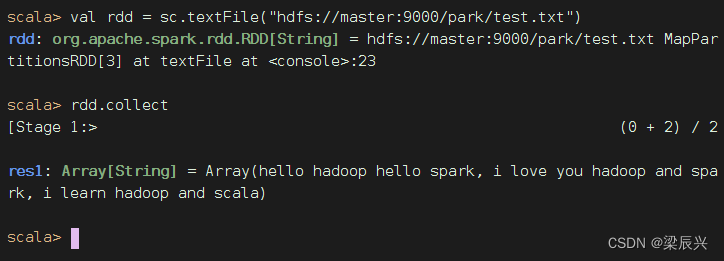 结论:默认就是访问HDFS上的文件,因此
结论:默认就是访问HDFS上的文件,因此 hdfs://master:9000 前缀可以不写
(二)以本地模式启动Spark Shell
执行命令:spark-shell --master local[*]
1、读取本地文件
执行命令:val rdd = sc.textFile("file:///home/test.txt")
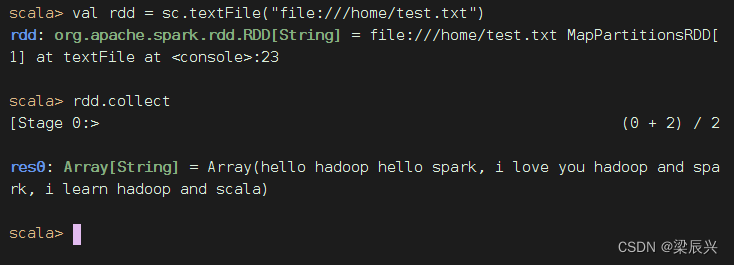 执行命令:
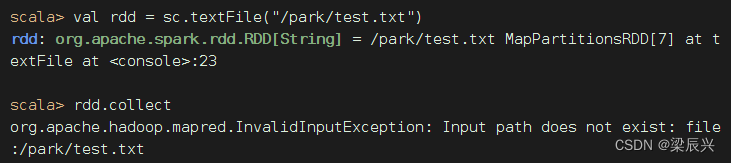
执行命令:val rdd = sc.textFile("/home/test.txt")
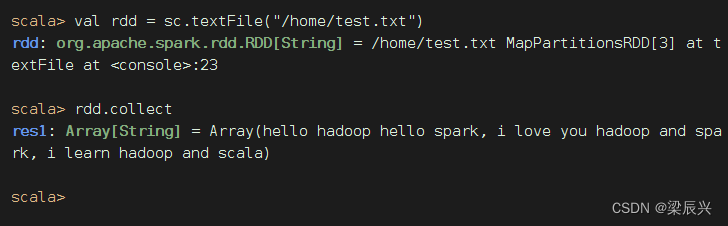
结论:本地模式启动的Spark Shell,默认读取的依然是HDFS文件,要访问本地文件,必须加file://前缀
2、访问HDFS文件
执行命令:val rdd = sc.textFile("hdfs://master:9000/park/test.txt")
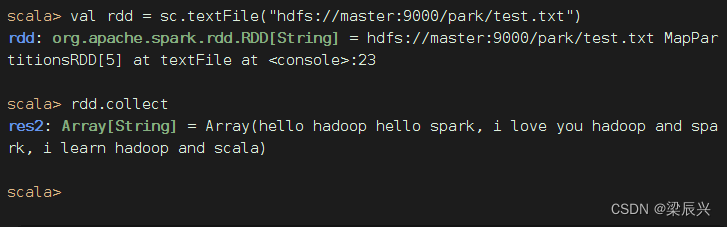
执行命令:val rdd = sc.textFile("/park/test.txt")
结论:默认就是访问HDFS文件,因此加不加hdfs://master:9000前缀都是一样的效果
(三)结论
无论以本地模式还是以集群模式启动Spark Shell,都可以访问HDFS文件。集群模式启动的Spark Shell,不能访问本地文件,只能访问HDFS文件,加不加hdfs://master:9000前缀都是一样的效果。如果访问本地文件,必须以本地模式启动Spark Shell,而且还必须加file://前缀。总之,Spark Shell默认都是访问HDFS文件。