文章目录
- 前言
- 效果截图如下
- 代码解析
- 完整代码
- 完结 撒花
前言
在网上看了好多 , 都是对香农进行编码的案例 , 却没有 进行解码的操作 , 今天就来补齐这个欠缺
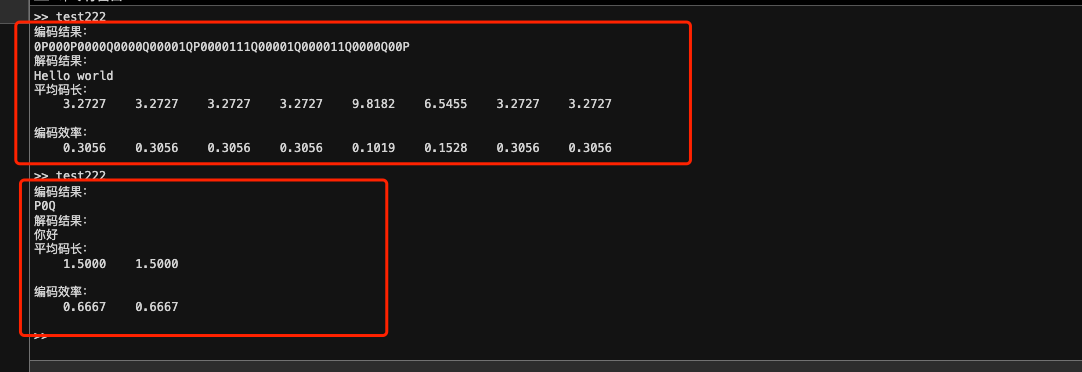
效果截图如下
代码解析
text = '你好'; % 待编码的文本
- 定义一个字符串类型的变量text,其值为’你好’。
[encoded, decoded, avgCodeLength, efficiency] = shannonCoding(text);
- 调用函数shannonCoding对文本信息进行编码,并将编码、解码、平均码长和编码效率作为四个返回值保存到变量encoded, decoded, avgCodeLength和efficiency中。
disp('编码结果:');
disp(encoded);
disp('解码结果:');
disp(decoded);
disp('平均码长:');
disp(avgCodeLength);
disp('编码效率:');
disp(efficiency);
- 打印输出编码结果、解码结果、平均码长和编码效率。
function [encoded, decoded, avgCodeLength, efficiency] = shannonCoding(text)
- 定义一个名为shannonCoding的函数,输入参数为待编码的文本字符串text。输出参数为编码结果encoded、解码结果decoded、平均码长avgCodeLength和编码效率efficiency。
symbols = unique(text);
freq = zeros(size(symbols));
for i = 1:length(symbols)
freq(i) = sum(text == symbols(i));
end
freq = freq / numel(text);
- 对于字符串text中所有不同的字符,使用unique()函数提取出来并存到symbols数组中,然后计算它们在字符串text中的出现频率。具体来说,利用for循环遍历symbols数组中的每一个字符,并计算其在字符串text中出现的次数,最后将频率存储到freq数组中。最后,将freq数组中的每个元素除以总的字符数numel(text),即可得到每个字符的频率。
cumProb = cumsum(freq);
- 计算符号累计概率(按照符号出现概率从大到小排列)。
codeTable = cell(length(symbols), 2);
for i = 1:length(symbols)
codeTable{i, 1} = symbols(i);
codeTable{i, 2} = ''; % 初始化编码为空
end
- 初始化编码表codeTable,用cell数组表示。codeTable的行数等于symbols中不同字符的个数,每行有两个元素:第一个是字符本身,第二个是该字符的编码(最开始为空字符串)。
codeTable = buildCodeTable(codeTable, cumProb, 1, '');
- 调用函数buildCodeTable递归地构建Huffman编码表。
encoded = '';
for i = 1:numel(text)
symbol = text(i);
index = find(strcmp(codeTable(:, 1), symbol));
code = codeTable{index, 2};
encoded = [encoded, code];
end
- 遍历文本text中的每个字符,找到对应的Huffman编码,最终将所有字符的编码串联起来,存储在变量encoded中。
decoded = '';
code = '';
for i = 1:length(encoded)
code = [code, encoded(i)];
index = -1;
for j = 1:length(codeTable)
if strcmp(codeTable{j, 2}, code)
index = j;
break;
end
end
if index >= 0
decoded = [decoded, codeTable{index, 1}];
code = '';
end
end
- 解码过程,将encoded按照长度依次取出一部分,逐个检查编码表codeTable中是否有对应的码。如果有,则对应的字符添加到decoded中,并清空code。
codeLengths = cellfun(@length, codeTable(:, 2));
avgCodeLength = sum(codeLengths .* freq);
- 计算平均码长,将每个字符的编码长度乘以其在文本中的频率,最后相加即可。
efficiency = 1 ./ avgCodeLength;
- 计算编码效率,用单位1表示所需的二进制位数,所以编码效率是1除以平均码长。这里使用了向量化操作,相当于计算每个码字所需的二进制位数之和再除以总的码字个数。
end
- 函数定义结束。
完整代码
text = '你好'; % 待编码的文本
[encoded, decoded, avgCodeLength, efficiency] = shannonCoding(text);
disp('编码结果:');
disp(encoded);
disp('解码结果:');
disp(decoded);
disp('平均码长:');
disp(avgCodeLength);
disp('编码效率:');
disp(efficiency);
function [encoded, decoded, avgCodeLength, efficiency] = shannonCoding(text)
% 计算字符频率
symbols = unique(text);
freq = zeros(size(symbols));
for i = 1:length(symbols)
freq(i) = sum(text == symbols(i));
end
freq = freq / numel(text);
% 计算累积概率
cumProb = cumsum(freq);
% 构建编码表
codeTable = cell(length(symbols), 2);
for i = 1:length(symbols)
codeTable{i, 1} = symbols(i);
codeTable{i, 2} = ''; % 初始化编码为空
end
% 递归构建编码表
codeTable = buildCodeTable(codeTable, cumProb, 1, '');
% 编码
encoded = '';
for i = 1:numel(text)
symbol = text(i);
index = find(strcmp(codeTable(:, 1), symbol));
code = codeTable{index, 2};
encoded = [encoded, code];
end
% 解码
decoded = '';
code = '';
for i = 1:length(encoded)
code = [code, encoded(i)];
index = -1;
for j = 1:length(codeTable)
if strcmp(codeTable{j, 2}, code)
index = j;
break;
end
end
if index >= 0
decoded = [decoded, codeTable{index, 1}];
code = '';
end
end
% 计算平均码长
codeLengths = cellfun(@length, codeTable(:, 2));
avgCodeLength = sum(codeLengths .* freq);
% 计算编码效率
efficiency = 1 ./ avgCodeLength;
end
% 递归构建编码表
function codeTable = buildCodeTable(codeTable, cumProb, index, code)
if index > length(codeTable)
return;
end
if cumProb(index) <= 0.5
codeTable{index, 2} = [code, '0'+' '];
codeTable = buildCodeTable(codeTable, cumProb, index+1, [code, '0']);
else
codeTable{index, 2} = [code, '1'+' '];
codeTable = buildCodeTable(codeTable, cumProb, index+1, [code, '1']);
end
end