文章目录
- 一,等值连接
- 二,表别名
- 三,多表等值连接
- 四,自然连接
- 五,自连接
- 六,非等值内连接
- 七,外连接
- (一)左外连接
- (二)右外连接
- (三)笛卡尔积
一,等值连接
等值连接的语法较为简单,语法如下:
select table1.column1,table2.column2
from table1, table2
where table1.column3 = table2.column4
其中 select 子句后可跟连接的表中任意字段,from 子句后跟用来连接的表,而 where 子句后的 table1.column=table2.column 即为连接条件。其含义是,将两表中符合条件的记录横向拼接起来,在此基础上选择结果集中要呈现的字段,也可以在 where 子句中追加过滤条件对记录进行筛选。 接下来举个例子,通过 countrycode 字段相等这个条件把 city 表和 countrylanguage 表连接起来,显示前 10 条记录的所有字段,这样在结果不仅可以看到城市信息还可以看到其对应国家的详细信息。SQL 语句如下:
MariaDB [world]> select * from city,countrylanguage
-> where city.countrycode = countrylanguage.countrycode limit 10;
+-----+----------------+-------------+----------+------------+-------------+------------+------------+------------+
| ID | Name | CountryCode | District | Population | CountryCode | Language | IsOfficial | Percentage |
+-----+----------------+-------------+----------+------------+-------------+------------+------------+------------+
| 129 | Oranjestad | ABW | – | 29034 | ABW | Dutch | T | 5.3 |
| 129 | Oranjestad | ABW | – | 29034 | ABW | English | F | 9.5 |
| 129 | Oranjestad | ABW | – | 29034 | ABW | Papiamento | F | 76.7 |
| 129 | Oranjestad | ABW | – | 29034 | ABW | Spanish | F | 7.4 |
| 1 | Kabul | AFG | Kabol | 1780000 | AFG | Balochi | F | 0.9 |
| 2 | Qandahar | AFG | Qandahar | 237500 | AFG | Balochi | F | 0.9 |
| 3 | Herat | AFG | Herat | 186800 | AFG | Balochi | F | 0.9 |
| 4 | Mazar-e-Sharif | AFG | Balkh | 127800 | AFG | Balochi | F | 0.9 |
| 1 | Kabul | AFG | Kabol | 1780000 | AFG | Dari | T | 32.1 |
| 2 | Qandahar | AFG | Qandahar | 237500 | AFG | Dari | T | 32.1 |
+-----+----------------+-------------+----------+------------+-------------+------------+------------+------------+
10 rows in set (0.000 sec)
结果解析:可以看到结果集中 countrycode 字段出现了两次,说明默认情况下等值连接并不会去掉重复字段。
在等值连接中,如果查询的字段在结果集中是唯一的,那么可直接写字段名。否则,必须在字段名前加上表名以示区分。
如下例所示,查询城市名称、国家代码以及该城市使用的语言,name、language 字段可以不加表名前缀,countrycode 字段则必须加表名前缀:
MariaDB [world]> select name,city.countrycode,language
-> from city,countrylanguage
-> where city.countrycode = countrylanguage.countrycode
-> limit 10;
+----------------+-------------+------------+
| name | countrycode | language |
+----------------+-------------+------------+
| Oranjestad | ABW | Dutch |
| Oranjestad | ABW | English |
| Oranjestad | ABW | Papiamento |
| Oranjestad | ABW | Spanish |
| Kabul | AFG | Balochi |
| Qandahar | AFG | Balochi |
| Herat | AFG | Balochi |
| Mazar-e-Sharif | AFG | Balochi |
| Kabul | AFG | Dari |
| Qandahar | AFG | Dari |
+----------------+-------------+------------+
10 rows in set (0.000 sec)
结果解析:name 和 language 字段在两个表中是唯一的、无歧义的,所以查询该字段的时候,字段前面没有加表名;而 countrycode 字段在两个表中都存在,所以查询的时候须在字段前面加上表名。 但是为了提高性能、避免字段名的使用产生歧义,在多表连接查询的时候,建议以
表名.字段名的方式来书写select子句。
二,表别名
上面例子实现的功能很简单,但 SQL 语句却很长。主要原因是表名比较长,书写出来的 select 子句和 from 子句也就变长。可使用表别名来解决这个问题。
表别名和字段别名类似,就是给表起另外一个名字。不过两者的不同点在于,字段别名是为了让结果易于理解;而表别名则是为了让 SQL 语句简单化。 表别名直接写在表名后即可,其语法如下:
select t1.column1,t2.column2
from table1 t1, table2 t2
where t1.column3 = t2.column4
在 from 子句中原表名的后面定义别名,在其他子句中就可以使用别名了。 根据语法,修改此前案例,将 city 表别名定为 ci,countrylanguage 表别名定为 co,修改后的 SQL 语句如下:
MariaDB [world]> select name,ci.countrycode,language
-> from city ci,countrylanguage co
-> where ci.countrycode = co.countrycode
-> limit 10;
+----------------+-------------+------------+
| name | countrycode | language |
+----------------+-------------+------------+
| Oranjestad | ABW | Dutch |
| Oranjestad | ABW | English |
| Oranjestad | ABW | Papiamento |
| Oranjestad | ABW | Spanish |
| Kabul | AFG | Balochi |
| Qandahar | AFG | Balochi |
| Herat | AFG | Balochi |
| Mazar-e-Sharif | AFG | Balochi |
| Kabul | AFG | Dari |
| Qandahar | AFG | Dari |
+----------------+-------------+------------+
10 rows in set (0.001 sec)
两条 SQL 语句相比,使用表别名后变得更简洁了。
需要说明的是,使用表别名时,表别名的作用范围仅限该条 SQL 语句中,离开这个 SQL 语句后无效。
三,多表等值连接
前面介绍的等值连接由两张表完成,如果连接的表超过两张,需要使用 and 来组合多个等值条件,具体语法如下:
select t1.column1,t2.column2,t3.column3
from table1 t1, table2 t2,table3 t3
where t1.column4 = t2.column5 and t1.column6 = t3. column7
在上例的基础上,除了显示城市名称和该城市的语言外,还需要显示城市所属区域,该怎么查询?我们发现,记录区域的字段信息存放在 country 表中,此时我们需要对三张表做等值连接,只显示连接后的前 10 条记录,实现的 SQL 语句如下:
MariaDB [world]> select ci.name,ci.countrycode,co.language,c.region
-> from city ci,countrylanguage co,country c
-> where ci.countrycode=co.countrycode and ci.countrycode=c.code
-> limit 10;
+----------------+-------------+------------+---------------------------+
| name | countrycode | language | region |
+----------------+-------------+------------+---------------------------+
| Oranjestad | ABW | Dutch | Caribbean |
| Oranjestad | ABW | English | Caribbean |
| Oranjestad | ABW | Papiamento | Caribbean |
| Oranjestad | ABW | Spanish | Caribbean |
| Kabul | AFG | Balochi | Southern and Central Asia |
| Qandahar | AFG | Balochi | Southern and Central Asia |
| Herat | AFG | Balochi | Southern and Central Asia |
| Mazar-e-Sharif | AFG | Balochi | Southern and Central Asia |
| Kabul | AFG | Dari | Southern and Central Asia |
| Qandahar | AFG | Dari | Southern and Central Asia |
+----------------+-------------+------------+---------------------------+
10 rows in set (0.001 sec)
等值连接的关键是找到表与表之间的桥梁(等值条件),通过桥梁构建一个信息更全面的表,达到多表查询的目的。
四,自然连接
在等值连接中,我们并没有强调用来连接的字段名必须相同,只要字段值相等即可进行连接。在等值连接中,如果用于连接的两个字段,其字段名与数据类型完全相同,比如 city 表中的 countrycode 字段与 countrylanguage 中的 countrycode 字段,这种特殊情况可使用自然连接。换句话说,自然连接是特殊的等值连接,特殊之处在于多个表中用于连接的字段同名且同类型。自然连接使用关键字 natural join,其 SQL 语法如下:
select t1.column1,t2.column2
from table1 t1
natural join table2 t2
使用该语法,解析引擎会自动探测两个表中相同的字段并设定等值条件,这样的字段可以不止一个,有多少个这样的字段就会生成多少个等值条件。相比显式等值连接来说语法更为简洁。
利用自然连接修改此前例子,SQL 语句如下:
MariaDB [world]> select ci.name,ci.countrycode,co.language
-> from city ci
-> natural join countrylanguage co
-> limit 10;
+----------------+-------------+------------+
| name | countrycode | language |
+----------------+-------------+------------+
| Oranjestad | ABW | Dutch |
| Oranjestad | ABW | English |
| Oranjestad | ABW | Papiamento |
| Oranjestad | ABW | Spanish |
| Kabul | AFG | Balochi |
| Qandahar | AFG | Balochi |
| Herat | AFG | Balochi |
| Mazar-e-Sharif | AFG | Balochi |
| Kabul | AFG | Dari |
| Qandahar | AFG | Dari |
+----------------+-------------+------------+
10 rows in set (0.000 sec)
可以看到,此 SQL 语句中没有使用 where 字句,也没有出现连接符,但是也达到了等值连接的效果。这是因为,自然连接会自动去查找两个表中是否有相同的字段(字段名相同、字段类型也相同),找到后自动完成等值连接。如果连接的表中,没有相同字段,会返回一个空结果,如下示例:
MariaDB [world]> select ci.name,ci.countrycode,co.code
-> from city ci natural join country co;
Empty set (0.082 sec)
自然连接还会自动去掉重复列:
MariaDB [world]> select * from city natural join countrylanguage limit 10;
+-------------+-----+----------------+----------+------------+------------+------------+------------+
| CountryCode | ID | Name | District | Population | Language | IsOfficial | Percentage |
+-------------+-----+----------------+----------+------------+------------+------------+------------+
| ABW | 129 | Oranjestad | – | 29034 | Dutch | T | 5.3 |
| ABW | 129 | Oranjestad | – | 29034 | English | F | 9.5 |
| ABW | 129 | Oranjestad | – | 29034 | Papiamento | F | 76.7 |
| ABW | 129 | Oranjestad | – | 29034 | Spanish | F | 7.4 |
| AFG | 1 | Kabul | Kabol | 1780000 | Balochi | F | 0.9 |
| AFG | 2 | Qandahar | Qandahar | 237500 | Balochi | F | 0.9 |
| AFG | 3 | Herat | Herat | 186800 | Balochi | F | 0.9 |
| AFG | 4 | Mazar-e-Sharif | Balkh | 127800 | Balochi | F | 0.9 |
| AFG | 1 | Kabul | Kabol | 1780000 | Dari | T | 32.1 |
| AFG | 2 | Qandahar | Qandahar | 237500 | Dari | T | 32.1 |
+-------------+-----+----------------+----------+------------+------------+------------+------------+
10 rows in set (0.000 sec)
可以看到结果集中 countrycode 字段只出现了一次。
自然连接需要 MySQL 判定表中相同的字段,在有多个相同字段时,如果想指定以某个字段进行等值连接,需要使用 join……using…… 语法来指定,其语法如下:
select t1.column1,t2.column2
from table1 t1
join table2 t2
using(字段)
注意:该语法中不再使用 natural join 。其中字段是指 table1 和 table2 中相同的列。上述例子使用 using 子句后,执行结果如下:
需要注意:
- using 里面的字段不能加表名作前缀,该字段此时是一个连接字段,不再属于某张单独的表。
- 连接的表中必须要拥有相同字段才能使用 using。 除了 join……using…… 子句,还可以使用 join……on…… 子句完成类似的功能,其语法如下:
select t1.column1,t2.column2
from table1 t1
join table2 t2
on(t1.字段=t2.字段)
其中 on 子句中的字段名可以不同。
上述例子用 on 语句修改后的 SQL 语句如下:
MariaDB [world]> select * from city ci join countrylanguage co on(ci.countrycode = co.countrycode) limit 10;
+-----+----------------+-------------+----------+------------+-------------+------------+------------+------------+
| ID | Name | CountryCode | District | Population | CountryCode | Language | IsOfficial | Percentage |
+-----+----------------+-------------+----------+------------+-------------+------------+------------+------------+
| 129 | Oranjestad | ABW | – | 29034 | ABW | Dutch | T | 5.3 |
| 129 | Oranjestad | ABW | – | 29034 | ABW | English | F | 9.5 |
| 129 | Oranjestad | ABW | – | 29034 | ABW | Papiamento | F | 76.7 |
| 129 | Oranjestad | ABW | – | 29034 | ABW | Spanish | F | 7.4 |
| 1 | Kabul | AFG | Kabol | 1780000 | AFG | Balochi | F | 0.9 |
| 2 | Qandahar | AFG | Qandahar | 237500 | AFG | Balochi | F | 0.9 |
| 3 | Herat | AFG | Herat | 186800 | AFG | Balochi | F | 0.9 |
| 4 | Mazar-e-Sharif | AFG | Balkh | 127800 | AFG | Balochi | F | 0.9 |
| 1 | Kabul | AFG | Kabol | 1780000 | AFG | Dari | T | 32.1 |
| 2 | Qandahar | AFG | Qandahar | 237500 | AFG | Dari | T | 32.1 |
+-----+----------------+-------------+----------+------------+-------------+------------+------------+------------+
10 rows in set (0.000 sec)
需要注意:
- 使用
on子句,不会消除重复列,因为on中的等值条件无需列相同; - 使用
on子句,连接的字段名可以不同,相当于是where **=**的一种替代品。 现在要完成对城市的名称、行政区名以及城市面积的查询,需要连接city表和country。使用on子句完成该查询,仅显示前 10 条记录,其 SQL 语句如下:
MariaDB [world]> select ci.name,ci.district,c.surfacearea
-> from city ci join country c
-> on(ci.countrycode = c.code)
-> limit 10;
+----------------+----------+-------------+
| name | district | surfacearea |
+----------------+----------+-------------+
| Oranjestad | – | 193.00 |
| Kabul | Kabol | 652090.00 |
| Qandahar | Qandahar | 652090.00 |
| Herat | Herat | 652090.00 |
| Mazar-e-Sharif | Balkh | 652090.00 |
| Luanda | Luanda | 1246700.00 |
| Huambo | Huambo | 1246700.00 |
| Lobito | Benguela | 1246700.00 |
| Benguela | Benguela | 1246700.00 |
| Namibe | Namibe | 1246700.00 |
+----------------+----------+-------------+
10 rows in set (0.000 sec)
通过对 using 子句和 on 子句的使用,可以得出以下结论:
- 使用
using子句进行连接时,结果中用于连接的列不会重复出现;而on子句的结果中,在不做干预的情况下,用于连接的列会出现两次。 - 使用
using子句时,连接的表必须有相同的字段;而on子句可以不相同,使用比较灵活。
五,自连接
自连接,就是一张表与自己进行连接。这种连接有什么意思呢?通过下面的例子进行说明。 现在准备有一张员工信息表(employee),其信息如下表所示:
| emp_id | emp_name | mgr_id | emp_salary |
|---|---|---|---|
| 1001 | 章 | null | 8000 |
| 1002 | 力 | 1001 | 6000 |
| 1003 | 潘 | 1002 | 4000 |
employ 表建立语句如下:
create table employee
(
emp_id int not null,
emp_name varchar(10),
mgr_id int,
emp_salary int,
primary key (emp_id)
);
数据插入语句如下:
insert into employee
values
(1001,'章',null,8000),
(1002,'力',1001,6000),
(1003,'潘',1002,4000);
emp_id 为 1001 的员工就是该企业最大的领导,所以其 mgr_id 为 null。查询所有员工的姓名以及上级领导的姓名,实现 SQL 语句如下:
select e1.emp_name,e2.emp_name mgr
from employee e1,employee e2
where e1.mgr_id = e2.emp_id;
输出结果:
MariaDB [world]> create table employee
-> (
-> emp_id int not null,
-> emp_name varchar(10),
-> mgr_id int,
-> emp_salary int,
-> primary key (emp_id)
-> );
Query OK, 0 rows affected (0.007 sec)
MariaDB [world]> insert into employee
-> values
-> (1001,'章',null,8000),
-> (1002,'力',1001,6000),
-> (1003,'潘',1002,4000);
Query OK, 3 rows affected (0.002 sec)
Records: 3 Duplicates: 0 Warnings: 0
MariaDB [world]> select e1.emp_name,e2.emp_name mgr
-> from employee e1,employee e2
-> where e1.mgr_id = e2.emp_id;
+----------+------+
| emp_name | mgr |
+----------+------+
| 力 | 章 |
| 潘 | 力 |
+----------+------+
2 rows in set (0.001 sec)
六,非等值内连接
非等值内连接,就是指连接的条件不是使用 = 计算,而是其他关系运算的结果。
比如,现在小学成绩实行等级制,只给出 A、B、C、D、E 几个等级。但是无论哪个等级都需要对应一个成绩范围。那么在成绩表中,如何查询出等级达到等级A的学生?
在这里建立 2 张表来说明这个问题。
第 1 张,学生成绩表(score),表结构:score(name,score),信息如下表所示:
| 姓名(name) | 成绩(score) |
|---|---|
| 小明 | 95 |
| 小张 | 85 |
| 小李 | 75 |
score 表建立语句如下:
create table score
(
name varchar(10) not null,
score int not null
);
数据插入语句如下:
insert into score
values
('小明',95),
('小张',85),
('小李',75);
第 2 张,成绩等级表(level),表结构:level(level,low,high),信息如下表所示:
| 等级(level) | 最低分(low) | 最高分(high) |
|---|---|---|
| A | 90 | 100 |
| B | 80 | 89 |
| C | 70 | 79 |
| D | 60 | 69 |
| E | 0 | 59 |
level 表建立语句如下:
create table level
(
level varchar(1) not null,
low int not null,
high int not null
);
数据插入语句如下:
insert into level
values
('A',90,100),
('B',80,89),
('C',70,79),
('D',60,69),
('E',0,59);
现通过非等值内连接,实现对学生姓名及对应等级的查询,其 SQL 语句如下:
select s.name,le.level
from score s,level le
where score between le.low and le.high;
输出结果:
MariaDB [world]> create table score
-> (
-> name varchar(10) not null,
-> score int not null
-> );
Query OK, 0 rows affected (0.006 sec)
MariaDB [world]> insert into score
-> values
-> ('小明',95),
-> ('小张',85),
-> ('小李',75);
Query OK, 3 rows affected (0.002 sec)
Records: 3 Duplicates: 0 Warnings: 0
MariaDB [world]> create table level
-> (
-> level varchar(1) not null,
-> low int not null,
-> high int not null
-> );
Query OK, 0 rows affected (0.006 sec)
MariaDB [world]> insert into level
-> values
-> ('A',90,100),
-> ('B',80,89),
-> ('C',70,79),
-> ('D',60,69),
-> ('E',0,59);
Query OK, 5 rows affected (0.002 sec)
Records: 5 Duplicates: 0 Warnings: 0
MariaDB [world]> select s.name,le.level
-> from score s,level le
-> where score between le.low and le.high;
+--------+-------+
| name | level |
+--------+-------+
| 小明 | A |
| 小张 | B |
| 小李 | C |
+--------+-------+
3 rows in set (0.000 sec)
七,外连接
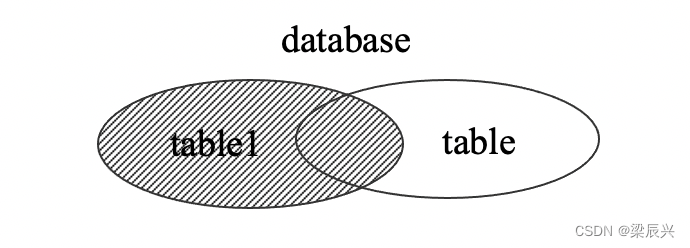
前面提到了内连接,自然也存在外连接。外连接分为左外连接和右外连接(MySQL 中没有全连接)。此外还有一种特殊的连接叫交叉连接,即笛卡尔积。
(一)左外连接
左外连接简称左连接,是指在两个表进行连接时,返回左表的全部记录及右表中符合条件的记录,右表没有匹配的记录用 null 补全。使用左连接的 SQL 语法如下:
select *
from table1 t1 left join table2 t2
on(t1.column1 = t2.column2)
其中 left join 是 left outer join 的缩写。左连接的结果如下图阴影部分所示。
举例说明:对 city 表与 country 表进行左连接,查询城市的代码和面积。其 SQL 语句如下:
select ci.countrycode,c.surfacearea
from city ci left join country c on(ci.name = c.name);
输出结果:
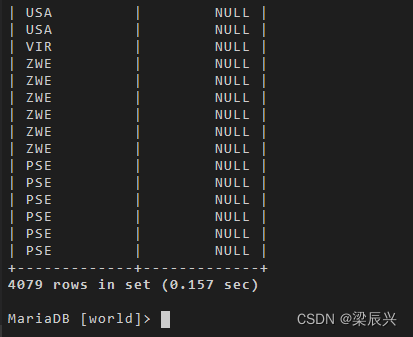
因为左表 city 表里面有 4079 条记录,左连接后的结果也是 4079 条记录。而满足条件的右表信息都正常显示出来,不满足的则使用 null 来补全。
(二)右外连接
右外连接简称右连接,右连接刚好和左连接相反,返回右表的全部记录及左表中符合条件的记录,左表没有匹配的记录用 null 补全。使用右连接的 SQL 语法如下:
select *
from table1 t1 right join table2 t2
on(t1.column1 = t2.column2);
其中 right join 是 right outer join 的缩写。右连接的结果如下图阴影部分所示。
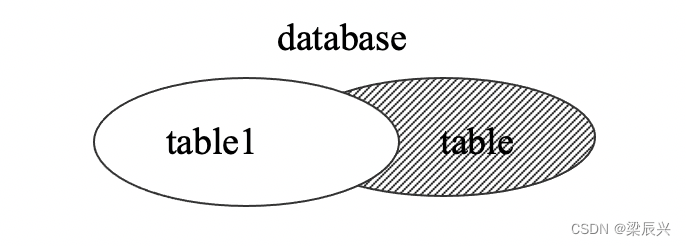
举例说明:对 city 表与 country 表进行右连接,查询城市的代码和面积。其 SQL 语句如下:
select ci.countrycode,c.surfacearea
from city ci right join country c
on(ci.name = c.name);
输出结果:
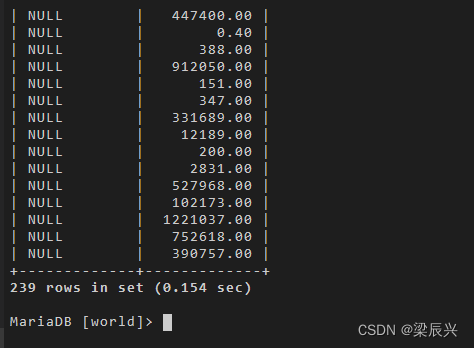
因为右表 country 表里面只有 239 条记录,右连接后的结果也是 239 条记录。而满足条件的左表信息都正常显示出来,不满足的则使用 null 来补全。
(三)笛卡尔积
笛卡尔积也叫交叉连接,原理就是一张表中的每一条记录都要和另一张表中的所有记录进行连接。如果两张表分别有 n 和 m 条记录,进行笛卡尔积的结果有 n*m 条记录。
笛卡尔积使用 join 来连接,基本语法如下:
select * from table1 join table2;
继续以成绩表和等级表为例,进行笛卡尔积,其 SQL 语句如下:
select * from score join level;
输出结果:
MariaDB [world]> select * from score join level;
+--------+-------+-------+-----+------+
| name | score | level | low | high |
+--------+-------+-------+-----+------+
| 小明 | 95 | A | 90 | 100 |
| 小张 | 85 | A | 90 | 100 |
| 小李 | 75 | A | 90 | 100 |
| 小明 | 95 | B | 80 | 89 |
| 小张 | 85 | B | 80 | 89 |
| 小李 | 75 | B | 80 | 89 |
| 小明 | 95 | C | 70 | 79 |
| 小张 | 85 | C | 70 | 79 |
| 小李 | 75 | C | 70 | 79 |
| 小明 | 95 | D | 60 | 69 |
| 小张 | 85 | D | 60 | 69 |
| 小李 | 75 | D | 60 | 69 |
| 小明 | 95 | E | 0 | 59 |
| 小张 | 85 | E | 0 | 59 |
| 小李 | 75 | E | 0 | 59 |
+--------+-------+-------+-----+------+
15 rows in set (0.000 sec)
简单来说,笛卡尔积是没有条件的连接,这会导致乘法效应,产生的数据量远远超过需要的数据,且多数配对不符合业务逻辑。应尽量避免连接查询中笛卡尔积的出现。