在本篇文章中,我们来讲述 Elasrticsearch 集群中重要的一个概念 replication,也即复制。
了解 Elasticsearch 中的分片复制
默认情况下,索引由单个分片组成,但是如果存储分片的节点出现故障(例如磁盘故障)会怎样? 数据丢失是因为我们没有它的副本。 这是一个严重的问题,因为硬件故障随时可能发生。 用于运行集群的硬盘驱动器越多,失败的可能性就越高。 因此,确保容错和故障转移机制至关重要。
幸运的是,Elasticsearch 原生支持分片复制,默认启用,无需任何配置。 这非常酷,因为许多数据库都有复杂的复制设置。
但是 Elasticsearch 中的复制是如何工作的呢?
复制在 Elasticsearch 中的工作原理
索引将其数据存储在多个分片中,这些分片可能存储在多个节点上。 同样,复制也是在索引级别配置的。 复制通过在索引中创建每个分片的副本来工作。 这些副本称为副本或副本分片。 已被复制一次或多次的分片称为主分片。 主分片及其副本分片统称为复制组。

副本分片是分片的完整副本,可以为搜索请求提供服务,类似于主分片。 在创建索引时,我们可以选择每个分片有多少个副本,默认值为一个。 需要注意的是,副本数量越多,冗余和容错级别就越高。
如果主分片出现故障,副本分片将接管并继续为搜索请求提供服务。 Elasticsearch 自动协调查询的执行位置和并行化。 Elasticsearch 会自动选择执行给定查询的分片,这取决于我们稍后会讲到的许多因素。
值得一提的是,Elasticsearch 只为具有多个节点的集群添加副本分片,因为复制仅在此类集群中有意义。 如果你的集群只有一个节点,如果该节点发生故障,复制将无济于事。 因此,有必要在生产设置中至少有两个节点以防止数据丢失。
在 Elasticsearch 中使用副本分片的好处
除了防止数据丢失外,复制还可以增加给定索引的吞吐量。 在这种情况下,副本分片本身就是一个功能齐全的索引,就像主分片一样。 这意味着可以同时查询两个副本分片。 任何不到 10 年历史的 CPU 都有多个内核,通常至少有四个内核。 这使 CPU 能够通过使用线程在每个内核上同时运行任务。 因此,托管两个副本分片的节点可以在每个分片上并行运行搜索查询,从而增加索引的吞吐量。
选择理想的副本分片数量取决于你的设置的重要性。 通常,你可以使用一个或两个副本,但关键系统应该复制它们两次或更多次。 例如,使用 Elasticsearch 为你的个人 WordPress 博客提供搜索功能,你可能会接受这种非常小的风险。 另一方面,Elasticsearch 用于医院内的关键事物将需要更多副本以确保容错和故障转移机制。

因此,索引包含分片,而分片又可能包含副本分片。 在此示例中,一个索引已拆分为两个主分片,每个主分片有两个副本分片。 因此,该索引包含两个复制组。
太好了,所以我们有每个分片的物理副本,但是如果整个磁盘停止工作并且我们丢失了所有数据,这有什么帮助呢? 为防止这种情况发生,副本分片永远不会与其主分片存储在同一节点上。
这意味着如果一个节点消失了,总会有至少一个分片数据的副本在另一个节点上可用。
将留下多少副本取决于为索引配置了多少个副本以及集群包含多少个节点。 在图中,你可以看到副本分片与它们所属的主分片放置在不同的节点上。
复制只对包含多个节点的集群有意义,否则如果唯一可用的节点发生故障,复制将无济于事。 因此,Elasticsearch 只会为具有多个节点的集群添加副本分片。
你仍然可以将索引配置为包含每个分片的一个或多个副本,但在添加其他节点之前它不会有任何影响。
让我们通过一个示例来了解 Elasticsearch 集群中的复制是如何工作的。 为了简单起见,假设我们在集群中只有两个索引,并且两个索引都使用默认配置。
我们从一个由单个节点组成的集群开始。 每个索引只包含一个分片,因此节点将包含总共两个分片。 即使索引被配置为复制每个分片一次,副本分片也将被取消分配,因为我们只有一个节点在运行。
这对于开发环境来说很好,因为只有在我们丢失数据时才会带来不便。 但是,对于生产环境,我们真的不想冒丢失数据的风险,因此我们决定向集群添加一个额外的节点。
请记住,这些节点根本不需要很强大; 它们只需要在独立的硬件上运行,这样就不会有单点故障。
一旦 Elasticsearch 识别出我们添加了一个额外的节点,它将启用复制,这意味着将分配副本分片。
如果我们随后向集群添加一个额外的节点,我们会看到副本分片会分散开来进一步提高可用性。 在那种情况下,即使两个节点同时宕机,我们也不会丢失任何数据。
选择副本分片的数量
理想的副本分片数量是多少? 通常,你可以使用一个或两个副本,但这取决于你的设置有多重要。
如果两个节点同时发生故障,你是否可以从另一个数据源(例如关系数据库)恢复存储在它们上的数据? 恢复数据时数据不可用是否可以接受?
如果你使用 Elasticsearch 为你的个人 WordPress 博客提供搜索功能,你可能会接受这个非常小的风险。
另一方面,如果你在医院内使用 Elasticsearch 处理一些重要的事情,你可能承担不起这种风险。
根据经验,你应该复制分片一次,对于关键系统,你应该复制它们两次或更多次。 这也意味着对于生产设置,你将需要至少两个节点来保护自己免受数据丢失。
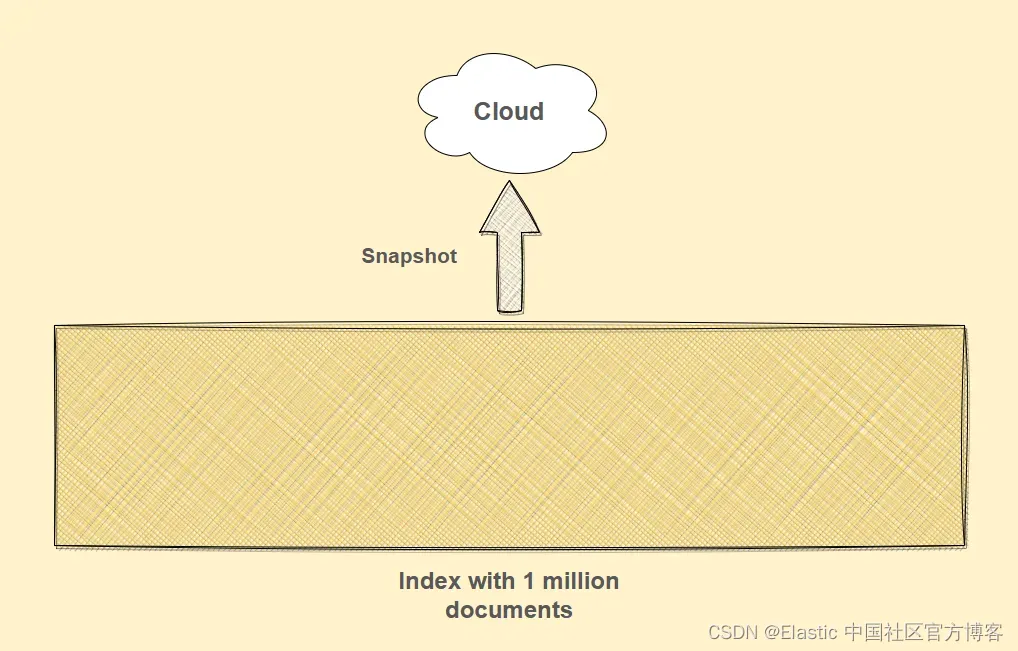
当我们谈论防止数据丢失时,我想简单地提一下,Elasticsearch 也支持拍摄快照(snapshot),就像许多数据库一样。
快照提供了一种备份方式,以便你可以将数据恢复到某个时间点。 你可以对特定索引或整个集群进行快照。
那么,如果我们可以拍摄快照(snapshot),为什么还需要复制呢?
复制确实是一种防止数据丢失的方法,但复制只适用于实时数据。 这实质上意味着复制确保你不会丢失给定索引在当前时间点存储的数据。
另一方面,快照使你能够将集群的当前状态或特定索引导出到文件中。 然后可以使用此文件将集群或索引的状态恢复到该状态。
例如,假设我们的任务是重组数百万文档在索引中的存储方式。

当然,我们相信它会起作用,并且我们已经在我们的开发环境中对其进行了测试。
为了确保我们可以从任何问题中恢复,我们在运行任何查询之前拍摄索引快照。
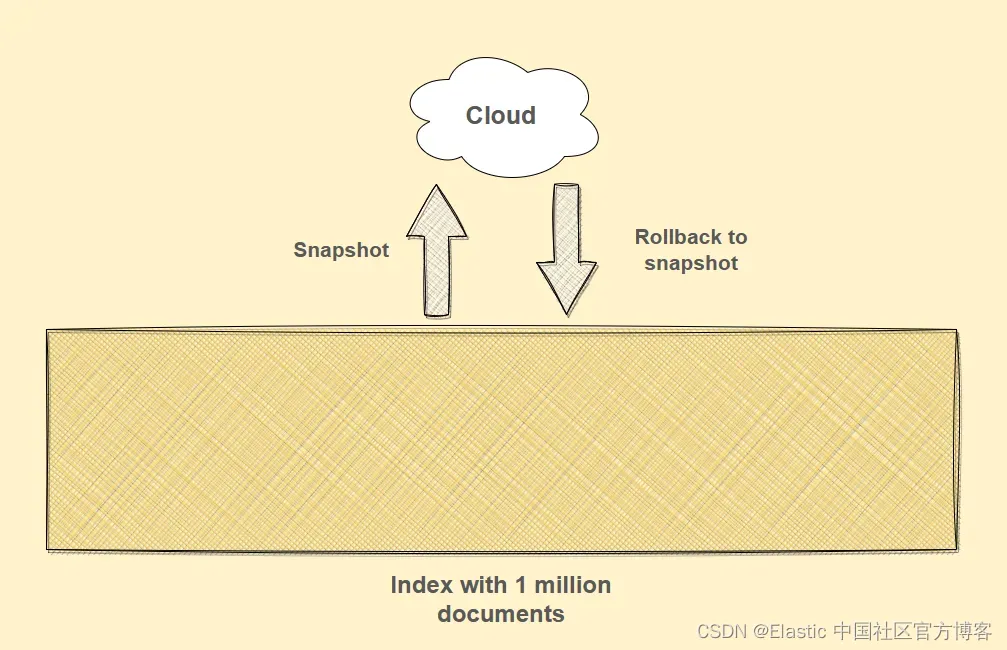
运行查询时,事情没有按计划进行,可能是因为我们的测试文档与存储在实时索引中的文档不同。 不管是什么原因,文档都弄乱了,我们需要还原更改以使事情恢复到工作状态。
复制对此无能为力,因为复制只能确保我们不会丢失最新数据,这些数据已在本例中进行了修改。 相反,我们需要将索引的状态恢复到我们拍摄的快照。 通过这样做,我们应该一切顺利,并准备好在修复所有错误后再次尝试。
希望你了解快照和复制之间的区别。
快照通常用于日常备份,并且可以在对数据应用更改之前拍摄手动快照,只是为了确保在出现问题时有办法回滚更改。
如何在不增加节点的情况下提高索引吞吐量?
复制确保索引可以从节点故障中恢复并继续为请求提供服务,就好像什么也没发生一样。
除了防止数据丢失外,复制还可以增加给定索引的吞吐量。
例如,让我们考虑一个网上商店,其中产品存储在名为 products 的索引中。 最受欢迎的产品显示在首页上,当用户搜索产品时,会针对索引运行查询。 不用说,这个索引经常被查询。

索引配置为只有一个分片,因为我们没有很多文档,但我们对索引运行了很多查询。 副本计数也设置为 0。
我们开始遇到在高峰时段针对索引运行的查询的性能瓶颈,因此我们需要找到一种方法来处理它。
最初的想法可能是向这个集群添加一个额外的节点,该集群目前由两个节点组成。 但是,只有一个主分片和一个副本分片无济于事,因为无论如何我们都不能将它们分布在两个以上的节点上。
要利用额外的节点,我们必须增加分片的数量或副本分片的数量。 我们真的不需要另一个节点,我们也不想增加成本。 相反,我们可以将副本分片的数量增加一个或我们需要的任何数量。
由于我们只有两个节点,我们并没有真正增加索引的可用性,而是增加了索引的吞吐量。 但是为什么呢?
还记得我是怎么告诉你的,副本分片本身就是一个功能齐全的索引,就像分片一样吗? 这意味着可以同时查询两个副本分片。 这是可能的,因为两件事:
- Elasticsearch 自动协调查询的执行位置和并行化。 Elasticsearch 会自动选择执行给定查询的分片,这取决于我们稍后会讲到的许多因素。
- 任何不到十年的 CPU 都有多个内核,通常至少有四个内核。 这使 CPU 能够通过使用线程在每个内核上同时运行任务。
在此示例中,这意味着托管两个副本分片的节点可以在每个分片上并行运行搜索查询,从而增加索引的吞吐量。
当然,只有在节点的硬件资源还没有被充分利用的情况下,增加更多的副本分片才会对性能有好处。
在我们的示例中就是这种情况,因为负载在我们的索引中分布不均。 如果节点已经忙于处理对其他索引的请求,我们几乎看不到添加额外副本分片的影响。
除此之外,我们还需要额外的磁盘空间来存储副本分片,因为它是主分片的完整副本。
正如我确信你现在已经看到的那样,有很多变量会影响最佳节点、分片和副本分片的数量。
这只是一个如何使用复制来增加索引吞吐量的示例。
因此,总而言之,复制有两个目的:
- 增加可用性。
- 增加索引的吞吐量。
在 Kibana 中探索集群健康和复制
让我们暂时转到 Kibana,因为我想向你展示一些东西。
首先,让我们创建一个新索引。 这非常容易。 我们只需指定 PUT 动词,后跟我们要创建的索引的名称,比如:
PUT /pages太好了,我们的索引现已创建。
由于我们没有指定任何设置,它是使用默认设置创建的,即一个主分片和一个副本分片。
让我们再次检查集群。
因此,让我们从检查集群的健康状况开始:
GET /_cluster/health
请注意集群的运行状况如何从绿色变为黄色。 那么,这是怎么回事?
让我们列出我们的集群包含的索引以获取线索:
GET /_cat/indices?v
在这里我们可以看到我们新创建的索引的状态设置为黄色(yellow)。 原因是索引包含一个副本分片,但该分片没有分配给任何节点。
如你所知,副本分片永远不会分配到与其主分片相同的节点。 由于我们的集群只包含一个节点,Elasticsearch 无处可分配副本分片。
因此,副本分片正在等待分配,这就是我们的集群和索引处于黄色状态的原因。
该索引功能齐全,但如果节点出现故障,你将面临数据丢失的风险。 黄色状态是对此的警告。
现在,让我们列出集群中的所有分片并查看它们的分配位置。 为此,我们可以使用 _cat API 及其分片命令:
GET /_cat/shards?v 
结果显示每个分片的列表以及关于它的各种信息,包括它属于哪个索引。 在顶部,我们可以看到新创建的索引有两个分片,一个是主分片,一个是副本分片。
这是在 preirep 列中指定的,其中 p 对应于主分片,r 对应于副本分片。 下一列指定每个分片的状态。 正如我们所见,主分片的状态为 STARTED,这意味着它是一个功能齐全的分片并且可以用于请求。 另一方面,副本分片的状态为 UNASSIGNED,这是因为我们需要向集群添加另一个节点才能使复制生效。
现在你知道了我们的集群处于黄色状态的原因,让我们再次查看索引列表,因为我想向你展示最后一件事。

你是否注意到 Kibana 索引(.kibana*)配置为一个分片和零个副本? 一个分片是有意义的,因为这些索引将存储非常少量的数据,并且查询吞吐量将受到限制。
但是没有副本分片不会让我们面临丢失数据的风险吗? 是的,确实如此。 不要被这些零所迷惑,因为如果我们向集群中添加另一个节点,这些零会增加到一。 如何? 因为 Kibana 索引配置了值为 0-1 的设置 auto_expand_replicas。
此设置的作用是根据集群包含的节点数动态更改副本数。
当我们只有一个节点时,将有零个副本,而对于多个节点,将有一个副本。 你很快就会看到这个动作,所以我只是想指出它以防你想知道。