概要:
ClickHouse 最为擅长的领域是一个大宽表来进行查询,多表 JOIN 时Clickhouse 性能表现不佳。
CK执行模式
第一阶段,Coordinator 收到查询后将请求发送给对应的 worker 节点;第二阶段,Coordinator 收到各个 worker 节点的结果后汇聚起来处理后返回。
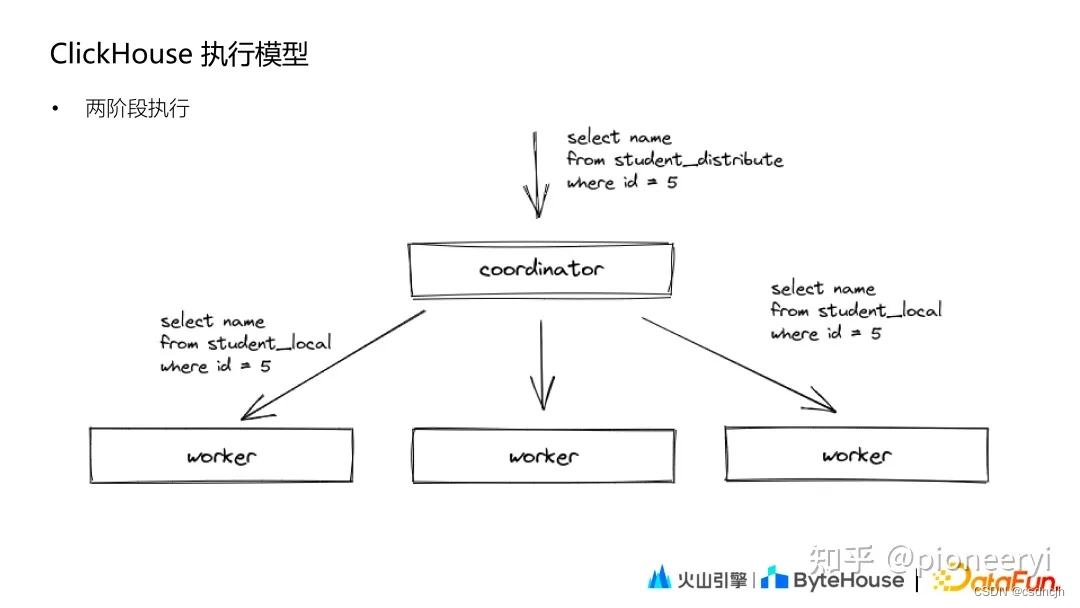
来源:ClickHouse Join为什么被大家诟病? - 知乎
优化建议
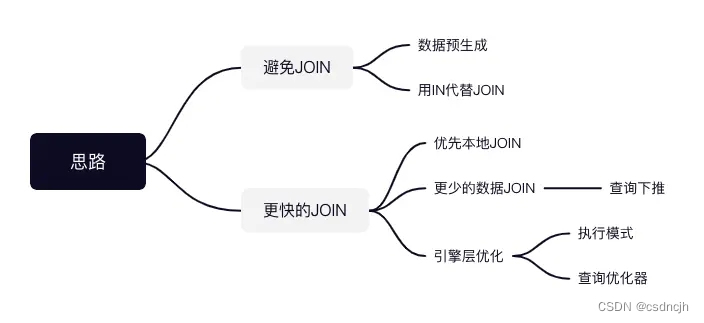
用IN代替JOIN
JOIN 需要基于内存构建 hash table 且需要存储右表全部的数据,然后再去匹配左表的数据。而 IN 查询会对右表的全部数据构建 hash set,但是不需要匹配左表的数据,且不需要回写数据到block。
SELECT event_date,
count()
FROM tob_apps_all
WHERE app_id = 10000000
AND event_date >= '2022-01-01'
AND event_date <= '2022-08-02'
AND hash_uid global IN
(SELECT hash_uid
FROM users_unique_all
WHERE (tea_app_id = 10000000)
AND (last_active_date >= '2022-01-01') )
GROUP BY event_date优先本地join
数据预先相同规则分区,也就是 Colocate JOIN。优先将需要关联的表按照相同的规则进行分布,查询时就不需要分布式的 JOIN。
SELECT
et.os_name,
ut.device_id AS user_device_id
FROM tob_apps_all AS et
ANY LEFT JOIN
(
SELECT
device_id,
hash_uid
FROM users_unique_all
WHERE (tea_app_id = 268411) AND (last_active_date >= '2022-08-06')
) AS ut ON et.hash_uid = ut.hash_uid
WHERE (tea_app_id = 268411)
AND (event = 'app_launch')
AND (event_date = '2022-08-06')
settings distributed_perfect_shard=1比如事件表 tob_apps_all 和用户表 users_unique_all 都是按照用户 ID 来分 shard 存储的,相同的用户的两个表的数据都在同一个 shard 上,因此这两个表的 JOIN 就不需要分布式 JOIN 了。
来源:ClickHouse 引擎在行为分析场景下的 JOIN 优化 - 简书
引擎层优化
Join 表引擎可以说是为 JOIN 查询而生的,它等同于将 JOIN 查询进行了一层简单封装。
说明:
需要说明的是:Join表引擎更加通常的用途,是用于Join连接查询的右侧表。且Join表的数据是首先被写至内存,然后才被同步到磁盘文件上。这意味着两件事:
1.Join表的查询速度很快,因为它的存在本来就是为了优化连接查询的速度;
2.Join表不适合存放千万级以上的大表,否则会占用过多的服务器内存,它更适合存放需要经常查询的小表,且通常为join语句的右侧表。
Join(ANY|ALL, LEFT|INNER, k1[, k2, ...])
引擎参数:ANY|ALL – 连接修饰;LEFT|INNER – 连接类型。更多信息可参考 JOIN子句。
这些参数设置不用带引号,但必须与要 JOIN 表匹配。 k1,k2,……是 USING 子句中要用于连接的关键列。
此引擎表不能用于 GLOBAL JOIN 。
类似于 Set 引擎,可以使用 INSERT 向表中添加数据。设置为 ANY 时,重复键的数据会被忽略(仅一条用于连接)。设置为 ALL 时,重复键的数据都会用于连接。不能直接对 JOIN 表进行 SELECT。检索其数据的唯一方法是将其作为 JOIN 语句右边的表。
跟 Set 引擎类似,Join 引擎把数据存储在磁盘中。
创建基于join引擎的表
数据表
CREATE TABLE join_tb1 (
id UInt8,
name String,
time Datetime
) ENGINE = Log
join表
CREATE TABLE id_join_tb1 (
id UInt8,
price UInt32,
time Datetime
) ENGINE = Join (ANY, LEFT, id);
插入测试数据
INSERT INTO TABLE join_tb1 VALUES
(1,'ClickHouse','2019-05-01 12:00:00'),
(2,'Spark', '2019-05-01 12:30:00'),
(3,'ElasticSearch','2019-05-01 13:00:00');
INSERT INTO TABLE id_join_tb1 VALUES
(1,100,'2019-05-01 11:55:00'),
(1,105,'2019-05-01 11:10:00'),
(2,90,'2019-05-01 12:01:00'),
(3,80,'2019-05-01 13:10:00'),
(5,70,'2019-05-01 14:00:00'),
(6,60,'2019-05-01 13:50:00');
join查询
#这段的意思是数据表 join_tb1 用id字段 关联join表 id_join_tb1 关联出 id_join_tb1的price字段。
SELECT id,name,joinGet ('id_join_tb1', 'price', id) as price
FROM join_tb1 ;
取特定某条
SELECT joinGet ('id_join_tb1', 'price', toUInt8 (1));
来源:Join Table Engine | ClickHouse Docs
创建基于join引擎的视图
创建数据表
drop table if exists user_order;
create table user_order
(
user_id String, // 用户ID
event_date String, // 付款日期
order_no String, // 订单号
amount Int32 // 金额
) ENGINE = MergeTree()
ORDER BY (user_id, event_date)创建视图
drop view if exists user_order_userid_j;
CREATE MATERIALIZED VIEW user_order_userid_j
ENGINE = Join(ANY, INNER, user_id)
POPULATE
AS
select user_id, event_date, order_no, amount
from user_order插入数据
insert into user_order(user_id, event_date, order_no, amount)
values
('user1', '2022-01-01', 'B', 4),
('user1', '2022-01-01', 'C', 8),
('user1', '2022-01-01', 'A', 2),
('user2', '2022-01-02', 'E', 3),
('user2', '2022-01-02', 'D', 7),
('user1', '2022-01-02', 'X', 6),
('user1', '2022-01-02', 'Y', 9) join查询
select * from user_order_userid_j来源:
clickhouse中使用Join表引擎 - 技术 - 张子阳的博客
ClickHouse学习笔记(二):ClickHouse常见表引擎简介_clickhouse url格式_leo825...的博客-CSDN博客