文章目录
- TP/FP/FN/TN(TA/FA/FR/TR)
- 误报率(FAR)
- 漏报率(FRR)
- ROC曲线(Receiver Operating Characteristic Curve,受试者特征曲线)
- DET曲线(Detection Error Tradeoff Curve,检测误差权衡曲线)
- 检测代价函数DCF
- EER(Equal Error Rate,等错率)
- 混淆矩阵
TP/FP/FN/TN(TA/FA/FR/TR)
True positive: having the condition and tested positive with the condition
False positive: not having the condition but tested positive with the condition
True negative: not having the condition and tested negative with the condition
False negative: having the condition but tested negative with the condition
真阳性TP:患有该疾病并检测呈阳性
假阳性FP:没有这种情况,但检测结果呈阳性
真阴性TN:没有这种情况,检测结果呈阴性
假阴性FN:有这种情况,但检测结果呈阴性
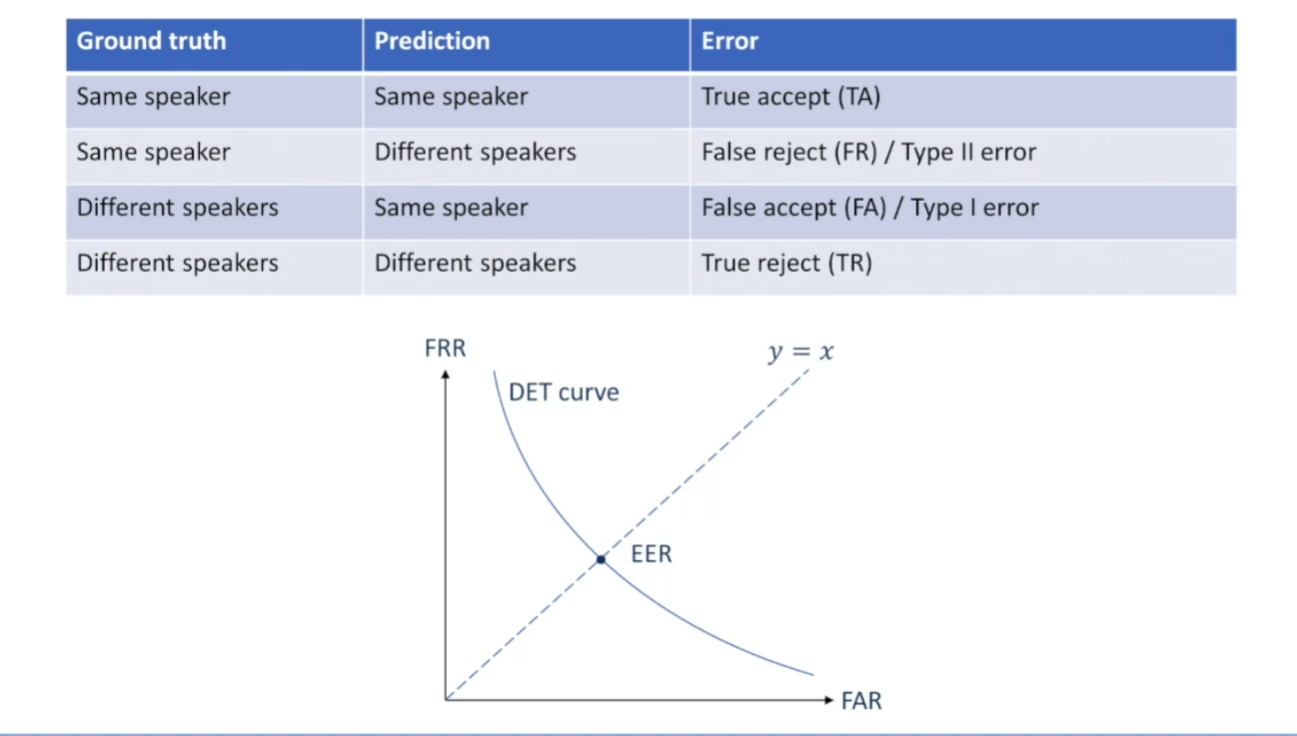
也可叫做TA/FA/FR/TR,即代表以下4种情况:真实接收(TA,实际是真的,也正确接收为真的),错误拒绝(FR,实际是真的,但错误拒绝为假的),错误接受(FA,实际是错的,但认定接收为真的),真实拒绝(TR,实际是错的,也真的拒绝了);
下列声纹识别的案例中,“Same speaker”代表“事实/预测为同一个说话人”,“Same speaker”代表“事实/预测为同一个说话人”,“Different speaker”代表“事实/预测为不同的说话人”。
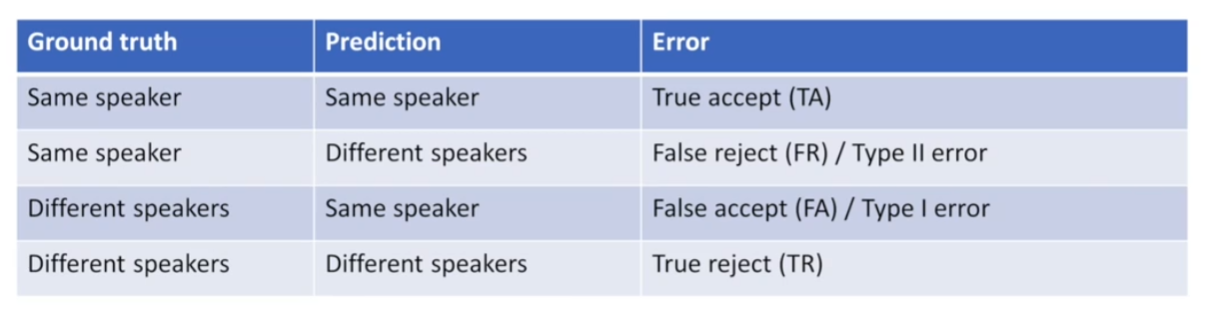
在概率统计中,FA称为第一类错误,FR称为第二类错误:
第一类错误(误报):拒绝本应接受的东西的错误,指的是本来正常(Condition negative),但是误认为是异常(Predicted condition positive);例如认定一个无辜的人有罪(冤案)。
第二类错误(漏报):接收本应该拒绝东西的错误,指的是本来异常(Condition positive),但是误认为是正常(Predicted condition negative);例如认定一个有罪的人无罪。
误报率(FAR)
误报率是被错误报告为阳性的阴性情况的比例(number of false positives / number of negative instances)
即 I e r r o r = 假阳 假阳 + 真阴 = F A F A + T R \Iota_{error}=\frac{假阳}{假阳+真阴}=\frac{FA}{FA+TR} Ierror=假阳+真阴假阳=FA+TRFA或 F P F P + T N \frac{FP}{FP+TN} FP+TNFP
漏报率(FRR)
漏报率是被错误地报道为阴性的阳性情况的比例(number of false positives / number of positive instances)
I I e r r o r = 假阴 假阴 + 真阳 = F R F R + T R \Iota\Iota_{error}=\frac{假阴}{假阴+真阳}=\frac{FR}{FR+TR} IIerror=假阴+真阳假阴=FR+TRFR或 F N F N + T N \frac{FN}{FN+TN} FN+TNFN
模型预测性能的准确率即:
A c c u r a c y = T P + F N T N + F N + T P + F P = T A + F R T A + F A + T R + F R Accuracy=\frac{TP+FN}{TN+FN+TP+FP}=\frac{TA+FR}{TA+FA+TR+FR} Accuracy=TN+FN+TP+FPTP+FN=TA+FA+TR+FRTA+FR
不同应用场景下,误报率和漏报率的重要程度有所区别,需综合考量。如在传播性很强的传染病判定时,误报为阳性犯第一类错误的危害通常没有阳性漏判为阴性的危害要大;而在声纹识别时,如智能音箱的语音唤醒情况下,误判为唤醒词犯第一类错误,通常没有第二类错误唤醒词漏判,导致经常识别不出来造成的用户体验更差,同时两类错误都会削弱语音解锁功能的鲁棒性。
ROC曲线(Receiver Operating Characteristic Curve,受试者特征曲线)

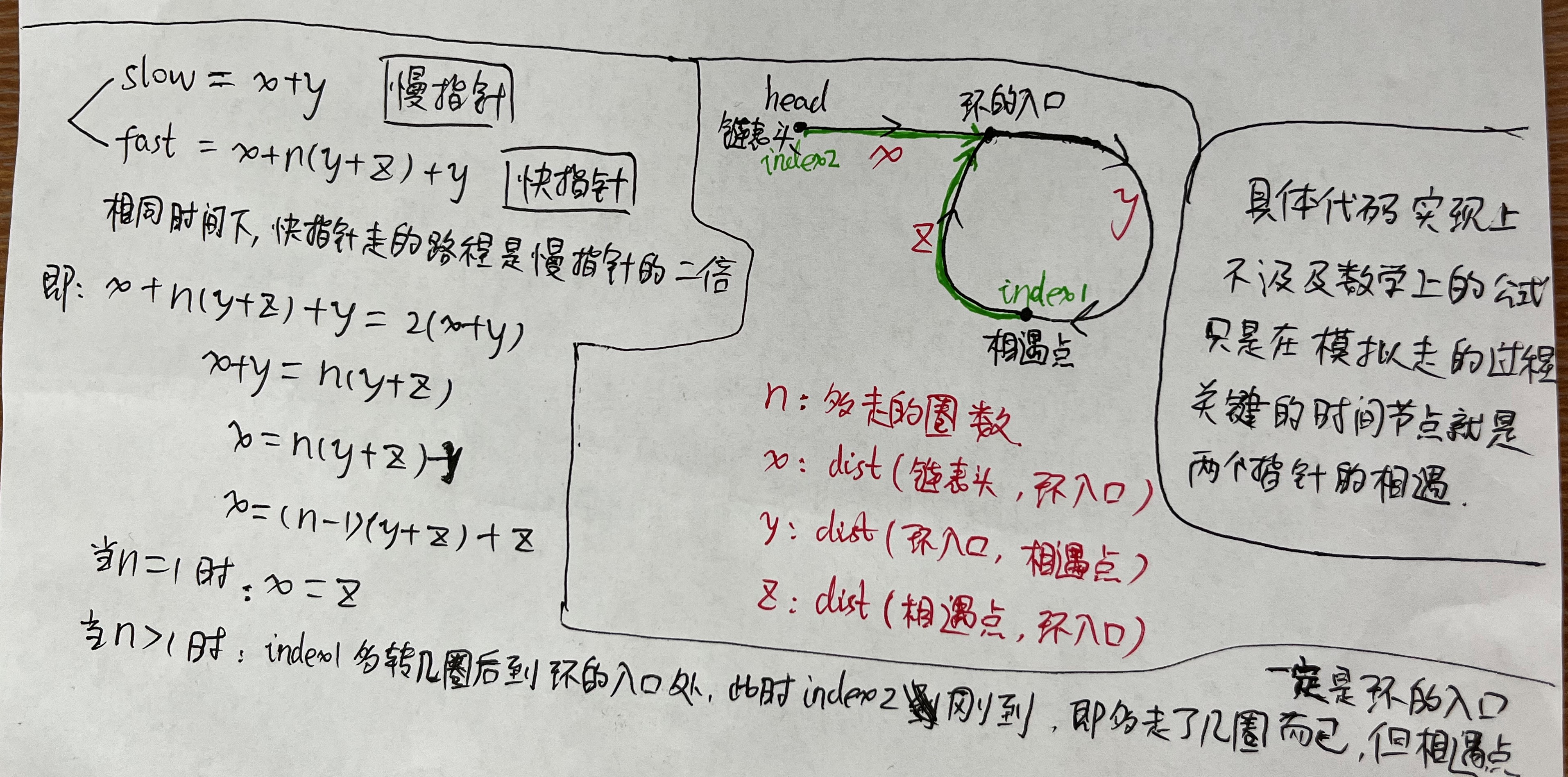
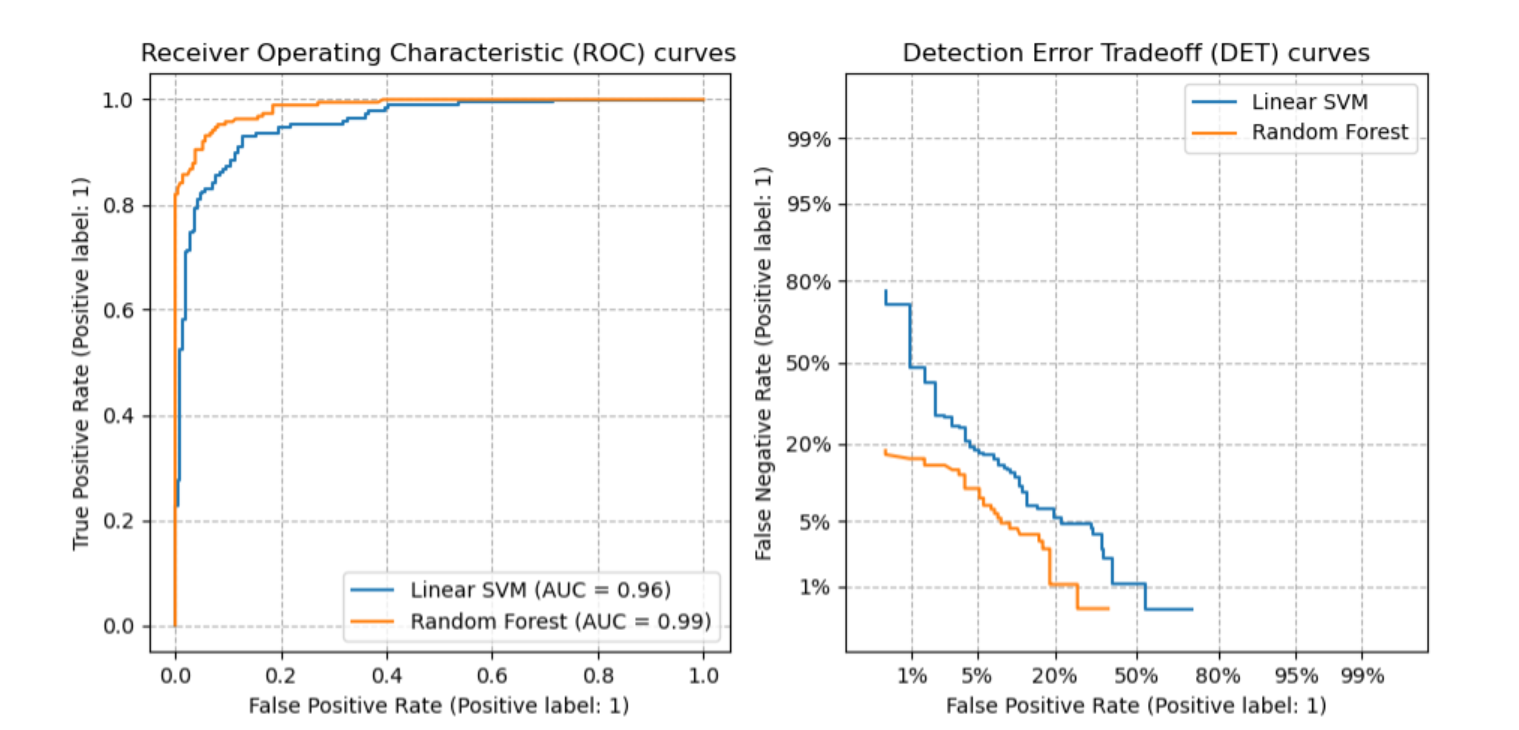
ROC曲线定义的横轴是FPR,纵轴是TPR,如果一个系统的评判方式是1/2的概率Ture/False随机分类的,代表红色虚线部分;若TPR>FPR,即真阳率的判定>假阳率的判定,曲线越往上,则代表系统的预测效果越好。
DET曲线(Detection Error Tradeoff Curve,检测误差权衡曲线)
DET曲线定义的横轴依旧是FPR,但纵轴是FNR,所以谁的假阴率越低,谁的效果越好;与ROC曲线相反,若曲线越往下,则代表系统的预测效果越好。
ROC曲线与DET曲线对比:
检测代价函数DCF

C_FRR为错误拒绝一个真实说话人的代价,cost of fr
C_FAR为错误接受一个冒认者的代价,cost of fa
PT为真实说话人出现的先验概率
PI为冒认者出现的先验概率
FRR为错误拒绝率
FAR为错误接受率
声纹识别任务中,DCF的计算考虑了两类错误发生的不同代价,也考虑了真实说话人和冒认者出现的先验概率,这些参数都是根据识别任务预先确定的。阈值选取时,有不同的FAR和FRR值就会得到不同的DCF值,选择使DCF取最小值的阈值作为说话人识别系统的确认阈值。根据不同的识别任务需求,确定不同的代价和先验概率等参数,从而就可以使最小DCF阈值适用于各种类型的识别任务。
最小检测代价函数DCF:

EER(Equal Error Rate,等错率)
单纯地使用错误率(FAR、FRR)来评定说话人确认系统性能是不合理的,通过FAR和FRR的交点可以综合确定出系统判决阈值(EER、DCF)

也可以通过DET曲线和y=x的交点来确定判决阈值:
python实现求解EER简化版代码:
给定一系列的正负trail pairs的分数,用Python编写函数计算其等错率。
这里我们给定一个CSV文件,文件的每一行包含两个数,即:label,score label若为0,表示负trial
pair,也就是不同说话人;label若为1,表示正trial pair,也就是相同说话人。 而score是相似度量的分数。
CSV文件从这里下载:https://github.com/wq2012/SpeakerRecognitionCourseChinese/blob/main/coding5/scores.csv
提示:可以考虑按以下步骤来实现:
- 使用csv模组来读取csv文件
- 对阈值的取值进行扫描,对每个取值计算对应的FAR和FRR
- 找到使FAR和FRR最为接近的那个阈值,然后取(FAR+FRR)/2作为对应的EER
import csv
SCORES = 'scores.csv'
def ComputeEER():
"""Compute the Equal Error Rate from the data in scores.csv
Returns:
a floating point number for the equal error rate (between 0 and 1)
"""
labels = []
scores = []
with open(SCORES) as csvfile:
spamreader = csv.reader(csvfile, delimiter=',')
for row in spamreader:
labels.append(int(row[0]))
scores.append(float(row[1]))
eer_threshold = None
eer = None
min_delta = 1
threshold = 0.0
while threshold < 1.0:
accept = [score >= threshold for score in scores]
fa = [a and (1 - l) for a, l in zip(accept, labels)] #计算fa,并以列表返回
fr = [(1 - a) and l for a, l in zip(accept, labels)] #计算fr,并以列表返回
far = sum(fa) / (len(labels) - sum(labels))
frr = sum(fr) / sum(labels)
delta = abs(far - frr) #当far==frr时,delta==0(相当于找到了DET与y=x的交点),触发循环终止
if delta < min_delta:
min_delta = delta
eer = (far + frr) / 2
eer_threshold = threshold
threshold += 0.005 #扫描阈值的步长
print('eer_threshold=', eer_threshold, 'eer=', eer)
return eer
if __name__ == "__main__":
ComputeEER()
eer_threshold= 0.5450000000000004 eer= 0.09375
循环终止时的各变量值:

其中accept和labels是两个列表,zip函数将它们打包成一个元组的列表,a和l分别表示元组中的两个元素。列表推导式中的表达式a and (1 - l)表示对a和(1-l)进行逻辑与运算,得到的结果作为新列表中的一个元素。最终得到的列表fa中包含了accept和labels中对应位置元素的逻辑与运算结果。
scores.csv中的数据格式:

混淆矩阵
每一行之和表示该类别的真实样本数量,每一列之和表示被预测为该类别的样本数量。通过混淆矩阵可以清晰辨识出二分类、多分类任务模型预测准确率的情况:
matlab生产混淆矩阵伪代码:
figure
cm = confusionchart(labelsTrueMat,labelsPredMat, ...
Title=["Confusion Matrix for 10-Fold Cross-Validation","Average Accuracy = " round(mean(labelsTrueMat==labelsPredMat)*100,1)], ...
ColumnSummary="column-normalized",RowSummary="row-normalized");
sortClasses(cm,categories(emptyEmotions))

python生成混淆矩阵代码示例:
import numpy as np
import seaborn as sns
from sklearn.metrics import confusion_matrix
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, average_precision_score, precision_score, f1_score,recall_score# 创建数据
y_true = np.array(["cat"]*15 + ["dog"]*15 + ["bird"]*20)
y_pred = np.array(["cat"]*10 + ["dog"]*4 + ["bird"]*1 +["cat"]*2 + ["dog"]*12 + ["bird"]*1 +["cat"]*2 + ["dog"]*1 + ["bird"]*17)
# 生成混淆矩阵
cm = confusion_matrix(y_true, y_pred, labels=["cat", "dog", "bird"])# # 创建数据,用数字也是可以。
# y_true = np.array([0]*15 + [1]*15 + [2]*20)
# y_pred = np.array([0]*10 + [1]*4 + [2]*1 +
# [0]*2 + [1]*12 + [2]*1 +
# [0]*2 + [1]*1 + [2]*17)
# # 生成混淆矩阵
# cm = confusion_matrix(y_true, y_pred)# 给混淆矩阵添加索引。
conf_matrix = pd.DataFrame(cm, index=['Cat','Dog','Pig'], columns=['Cat','Dog','Pig'])# 显示混淆矩阵。
fig, ax = plt.subplots(figsize = (4.5,3.5))
sns.heatmap(conf_matrix, annot=True, annot_kws={"size": 19}, cmap="Blues")
plt.ylabel('True label', fontsize=18)
plt.xlabel('Predicted label', fontsize=18)
plt.xticks(fontsize=18)
plt.yticks(fontsize=18)
plt.savefig('confusion.jpg', bbox_inches='tight')
plt.show()

参考文献:
[1] ChaoFeiLi-关于FPR和FNR (I类错误和II类错误)
[2] ROC曲线
[3] 那抹阳光1994-DET曲线(检测误差权衡曲线)
[4] 王泉-声纹识别:从理论到编程实战
[5] 蘑菇炖提莫-说话人确认系统性能评价指标EER和minDCF
[6] 玉堃-Detection:目标检测常用评价指标的学习总结(IoU、TP、FP、TN、FN、Precision、Recall、F1-score、P-R曲线、AP、mAP、 ROC曲线、TPR、FPR和AUC)
[7] MathWorks-Speech Emotion Recognition






![解决Dockerfile错误: ERROR [3/3] RUN yum install -y wget vim net-tools](https://img-blog.csdnimg.cn/645686d83bac4537b1bcf7c40f2dac7d.png)