提示:不断更新中
文章目录
- 一、为什么要引入轻量化神经网络
- 二、模型压缩(Model Compression)
- 参数修建
- 低秩因子分解
- 参数量化
- 知识蒸馏
- 人工神经架构设计
- 三、自动压缩和神经架构搜索(Automated Compression and Neural Architecture Search)
- 自动模型压缩(Automated Model Compression)
- 自动化神经架构设计(Automated Neural Architecture Design)
- 联合压缩和神经架构搜索(Joint Compression and Neural Architecture Search)
一、为什么要引入轻量化神经网络
之前的神经网络的卓越性能是以牺牲高计算复杂度为代价的。
例如
- 最先进的机器翻译模型需要10G以上的乘加(MACs)来处理
- 一个只有30个单词的句子:流行的激光雷达感知模型]需要每秒2000G以上的MAC(即10帧)。
高额的计算成本与实际使用的大多数移动设备并不匹配,因为从车辆到手机和物联网(IoT)设备,因为它们的硬件资源受到外形、电池和散热的严格限制。但是由于一些信息处理需要保证的实时性(自动驾驶)和隐私安全(医疗保健),所以这些计算工作不能委托给云服务器。这时候我们必须提出高效的深度学习神经网络。
二、模型压缩(Model Compression)
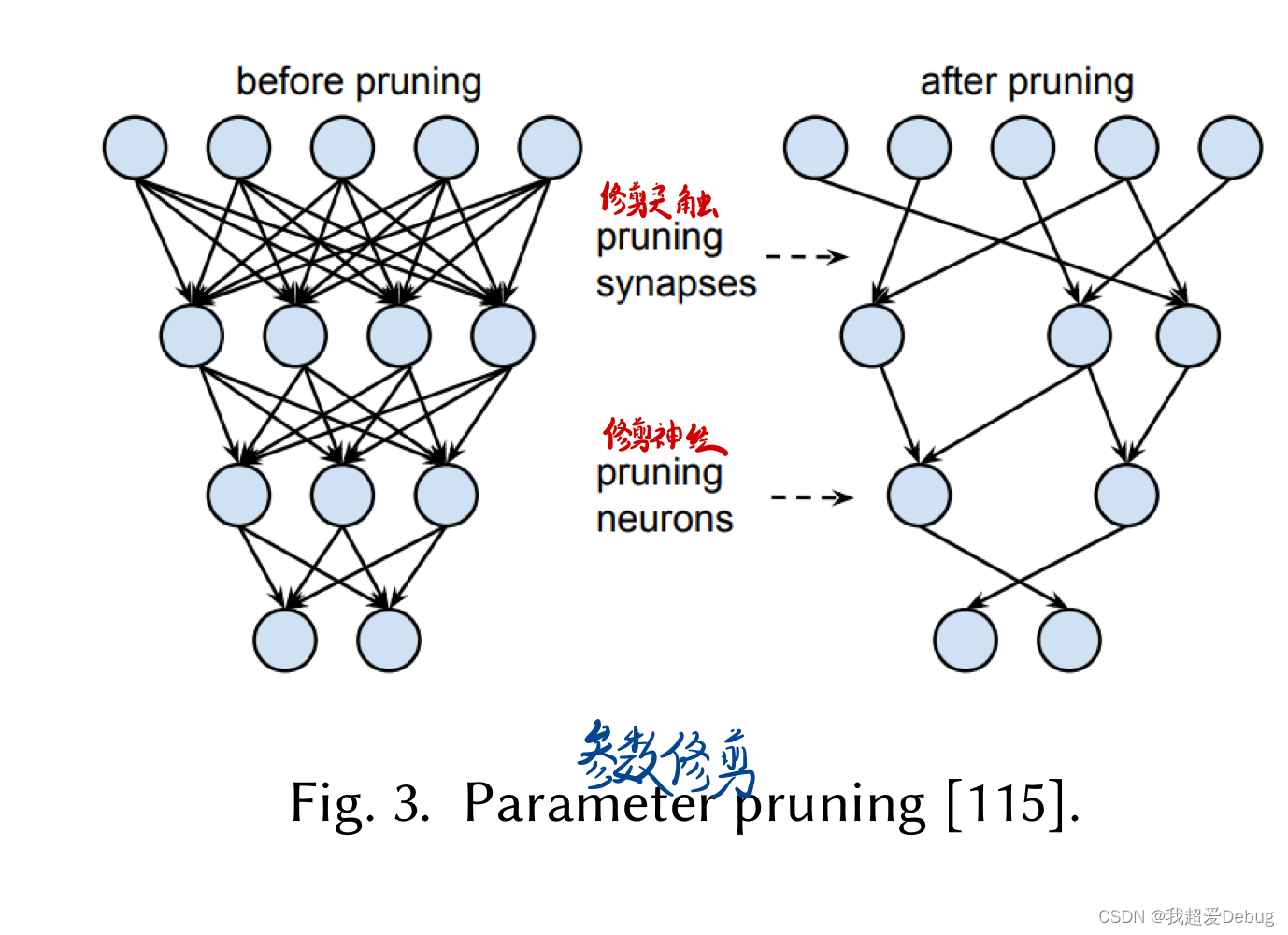
参数修建
深度神经网络通常是过度参数化的。剪枝去除神经网络中的冗余元素,以减小模型规模和计算成本
低秩因子分解
低秩分解利用矩阵/张量分解去估计深层卷积神经网络中最具信息量的参数从而达到降低深度神经网络中卷积层或全连接层的复杂度的效果
应用最广泛的分解是截断奇异值分解( Truncated Singular Value Decomposition,SVD ),该方法对于加速全连接层是有效的。
Kim等人使用Tucker Decomposition ( SVD的高阶扩展)对卷积核进行分解,获得了比使用SVD更高的压缩比。
参数量化
网络量化通过减少表示深度网络所需的每个权重的比特数来压缩网络。量化后的网络在硬件支持下可以有更快的推理速度。
说大白话就是,将一个浮点类型的数据根据舍入方案得到的数据来替代原始浮点数据。

知识蒸馏
知识提炼(KD) 可以将在大模型(表示为老师)中学到的“黑暗知识”转移到更小的模型(表示为学生)中,以提高更小模型的性能。
小模型要么是压缩模型,要么是更浅/更窄的模型。
人工神经架构设计
除了压缩现有的深度神经网络,另一种广泛采用的提高效率的方法是设计新的神经网络结构。
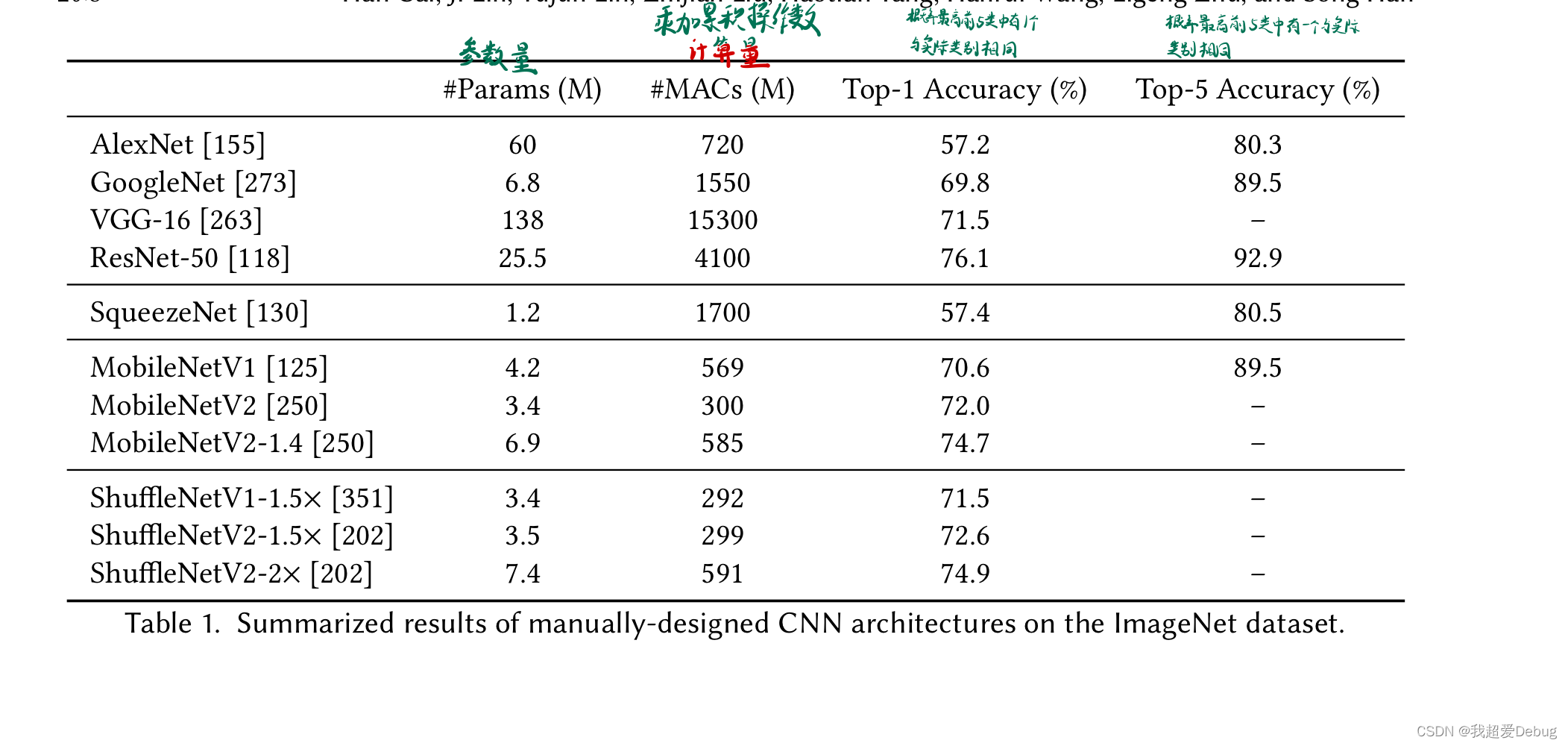
卷积层、池化层和全连接层,其中大部分计算来自卷积层。例如,在ResNet - 50中,超过99 %的乘累加操作( MAC )来自卷积层。因
此,设计高效的卷积层是构建高效CNN架构的核心。
目前广泛使用的高效卷积层有3种:
- 1 × 1 /点卷积
- 组卷积
- 深度卷积
基于这些高效卷积层,有三种代表性的人工设计高效CNN架构,包括SqueezeNet 、MobileNets和ShuffleNets。



![[附源码]Python计算机毕业设计SSM精品旅游项目管理系统(程序+LW)](https://img-blog.csdnimg.cn/54c7a48139864719ba1fd44bade6bfdf.png)