基于机器学习的内容推荐算法目前在各类内容类APP中使用的非常普遍。在购物、时尚、新闻咨询、学习等领域,根据用户的喜好,进行较为精准的用户画像与内容推荐。此类算法不但可以较为准确的分析用户的特征,如年龄、性别等,还能通过长期的跟踪维护,大致确定用户的偏好。但过于精确的推荐,对用户的潜在心理学影响越来越受到科学界的重视。本文首先介绍推荐算法的基本原理,再介绍其对用户的心理学、社会学影响。
文章目录
- 1. 推荐算法简介
- 1.1 内容模型
- 1.2 没有用户画像的直接预测
- 1.3 基于用户模型的推荐
- 2.精确推荐的负面影响
- 2.1 信息茧房
- 2.2 群体割裂
- 3. 应对建议
1. 推荐算法简介
一个用户的浏览或者购买行为,以一定的颗粒度为单位,可以在历史时间轴上构成一串链条。但细分推荐场景,又大致可以分为两类。一是简单互动类,二是复杂互动类。
类别A,简单互动类:典型的是新闻、短视频。用户在一个内容上驻留的时间期望以分钟、秒计,以浏览为主,加以简单的弹幕、点赞等回复。用户在1天内可产生上百个颗粒的浏览行为。
类别B,复杂互动类:典型的是购物、学习。用户较为专注于一类内容,且在某几个单一内容的驻留时间很长,发生较为复杂的事务,如退货、结算、评价等。用户在1天内只会产生少量的颗粒。
尽管这两种类别的推荐算法在数据模型、训练方法上的侧重相当的不同,但依旧有一些共同点。
1.1 内容模型
要描述一个内容的属性,使得机器学习或者简单的模式分类算法可以对其进行处理,就要把内容转化为含有各类属性的向量。
如音乐,可能包含许多属性。既有流派、作曲、演唱、唱片集等枚举类型的标量,也有对波形进行处理后得到的变换域向量,往往体现了整个音轨的起伏、能量区间和频率组合关系。
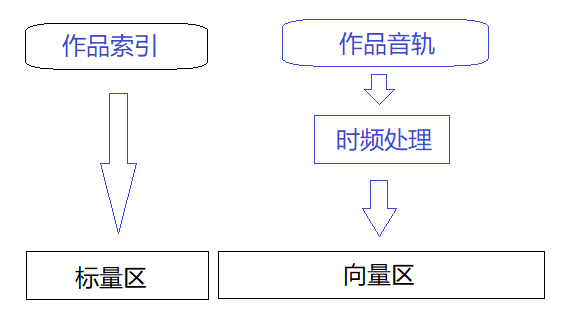
典型的作品数据含有长度为16的标量区,长度为128的向量区,构成一个144的特征向量。在内容模型中,这个向量就代表确定的一首歌。
M ⃗ = [ M c ⃗ M v ⃗ ] \vec{M}=\begin{bmatrix} \vec{M_c} & \vec{M_v} \end{bmatrix} M=[McMv]
一个用户的浏览习惯,就是以向量
M
⃗
\vec{M}
M为单位的向量列表,代表了这个用户的n次历史浏览。
{
M
⃗
0
,
M
⃗
1
,
M
⃗
2
,
.
.
.
,
M
⃗
n
−
1
}
\{\vec{M}_0,\vec{M}_1,\vec{M}_2,...,\vec{M}_{n-1}\}
{M0,M1,M2,...,Mn−1}
1.2 没有用户画像的直接预测
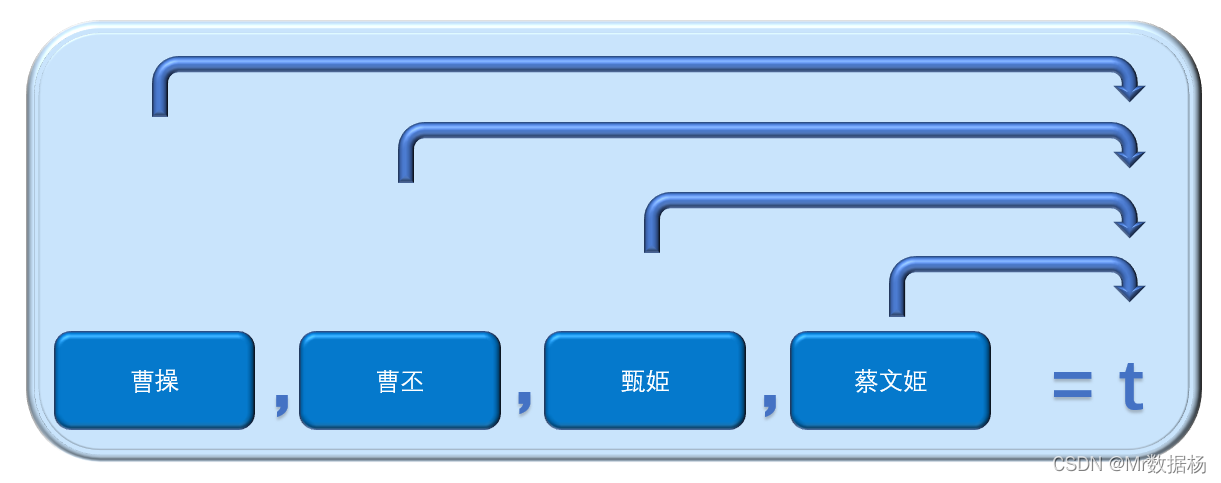
对于类别A,由于存在海量的浏览链条,可以采取一种简单朴素的预测算法。这种算法通过输入K次浏览数据,试图对下一颗粒的标量进行预测。
{ M ⃗ t − K , M ⃗ t − K + 1 , . . . , M ⃗ t − 1 } = = > M c , t ⃗ \{\vec{M}_{t-K},\vec{M}_{t-K+1},...,\vec{M}_{t-1}\}==> \vec{M_{c,t}} {Mt−K,Mt−K+1,...,Mt−1}==>Mc,t
一旦获取了预测标量,则可以推荐标量中涉及的唱片集、歌手、风格给用户。
1.3 基于用户模型的推荐
用户模型是对内容受众的数学化描述。比如用户的性别、年龄等等,以及数字化的喜好数据。这类算法目前门类很多,也有不少开源的模型。比较有意思的是,基于用户模型的推荐,并不强调必须要准确获知可被自然人理解的用户特征,比如年龄、性别。比如某一类推荐算法,看起来更像是一种信息压缩与解压的生成式算法。
这种算法,分为用户的特征提取(学习)、基于特征的推荐两步骤。思路是随机从用户习惯中抽取K组特征串{M}输入模型,经过A区的NN网络,输出用户画像 P,并经过B区生成内容模型{M’}。训练的目的,是控制P的规模,并期待输出的内容集合与用户的历史数据集合最为吻合。
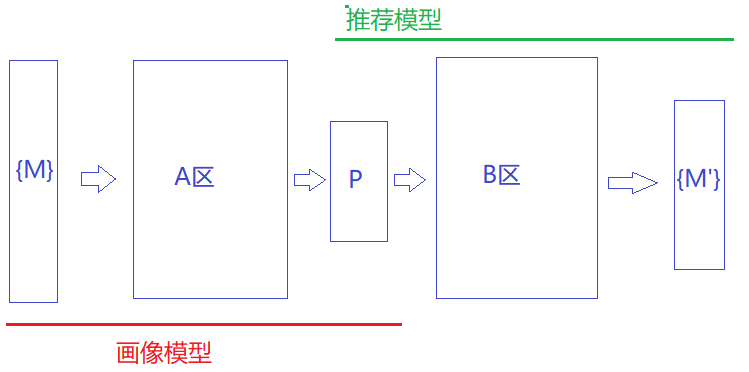
这种情况下,P虽然代表用户特征,但其中向量的具体意义已经不再重要了。在具备大量用户的网站,无需对用户全集进行完整的训练,只需要收集到小规模向量P的类别,即可根据新用户的类别直接查表获得推荐内容。
2.精确推荐的负面影响
过于精确的内容推荐,会产生意想不到的心理学、社会学影响,典型的是信息茧房与群体割裂。
2.1 信息茧房
一种典型的影响是信息茧房。当一个用户在初次浏览某个内容网站时,获取的咨询的属性非常宽泛与随机,其首页展现的内容的概率分布是平缓的、均匀的。这段时间是算法收集用户习惯的阶段。
随着浏览次数的增加,推荐算法对用户喜好的掌握越来越精确,使得用户获得的内容集中于感兴趣的若干点上,算法收敛。
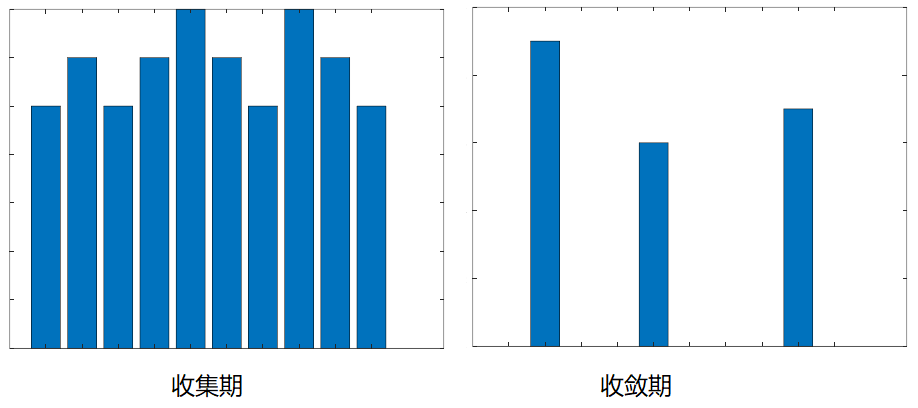
对推荐算法不了解的用户尤其会受到影响,他们不会认为早晨起来每天都看到这些内容,是自己被“投其所好”造成的现象。用户获取的信息被算法束缚在一个狭窄的集合内,无法了解到潜在重要的信息。
这种情况对于学习、科学网站,是没有问题的。但对综合类的内容网站,则存在弊端。假设用户在某段时间心理压力大,搜索了负面的内容,则推荐算法可能会推波助澜。尤其是对有抑郁倾向的用户,可能加重病情。
2.2 群体割裂
算法依靠用户习惯为用户画像,并精确推送内容。而用户被画像后推送的内容影响,会产生群体聚集效应。从种群角度来说,各种符号形成的群落会在算法编织的信息茧房里聚集,吸引具备同样特征的个体,而加剧群体的割裂。
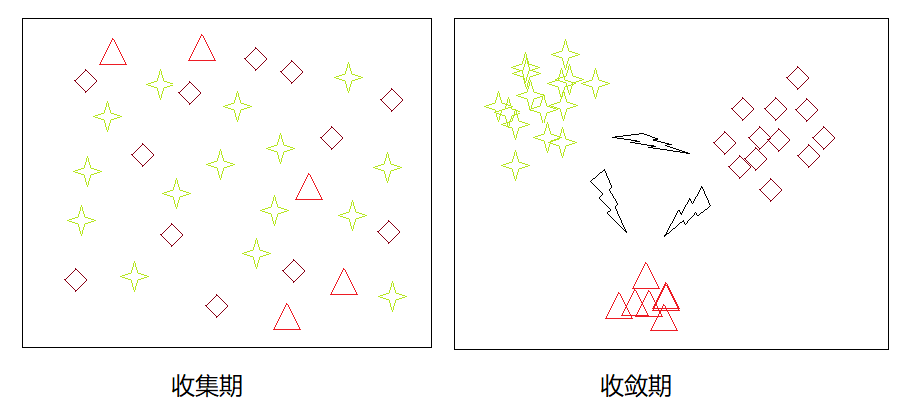
这使得整个群体被不断分割、强化,形成很多稳定而不包容的类。这些类无法站在对方的角度思考问题,因为各个类别都生活在算法编制的茧房里,一些统计学上显而易见的小概率事件在各自茧房中放大,一些需要注意的公共问题也无法在不同的群体中传播与取得共识。久而久之种群整体就会被分化,失去稳定性。
3. 应对建议
从算法角度,应该在涉及心理学、社会学的领域引入新的输入。比如在检获有抑郁倾向后,推送治愈系的内容,以及提高推荐算法的丰富程度。
![深度学习应用篇-计算机视觉-图像增广[1]:数据增广、图像混叠、图像剪裁类变化类等详解](https://img-blog.csdnimg.cn/img_convert/0dacfa2d1614c59f191480d8ed48c719.png)