目录
- 介绍
- 模型的后缀
- ckpt模型:
- safetensors模型
- 文件夹
- VAE
- 模型在哪下载
- Hugging face:<https://huggingface.co/models>
- 下载SD官方模型
- 文生图模型
- 标签介绍
- C站:<https://civitai.com/>
- 筛选模型的类型
- CheckPoint Type (模型的类型)
- Base model
- 类型筛选标签
- 模型下载
- 复制Prompt(提示词)
- 其他人做的图片分享
- 模型进阶
- Embedding 文本嵌入 嵌入式向量
- 应用
- 举例几个模型
- LoRa (Low-Rank Adaptation Models)低秩模型
- 使用
- 训练自己的 Lora模型
- Hypernetwork 超网络
- 使用
- 举例
- 文件夹
- 下载
- 总结
介绍
安装 StableDiffusion两种方式,一种是去 github 上下载工程部署,另一种是安装大佬的整合包,如果找不到整合包可以私信我。
这里不详细介绍安装部分,当我们安装完后,打开网页端时,会看到一个操作界面。而这个界面,有种既熟悉又陌生的感觉,会点直接生成按钮,直接生成图片,但是如何写提示词呢可以生成好看的图片呢,如何对图片进行二次修复呢,网上有好多好的模型如何导入我的 SD 中呢,有很多问题,那么我们怎么入门呢。这里介绍一些 SD 概念,让我们快速入门 SD。
模型的后缀
在 SD 中模型一般分为两种后缀:xxx.ckpt,xxx.safetensors
ckpt模型:
checkpoint模型,大模型,一般为2~7GB,检查点/关键点模型。
这种模型的训练类型玩游戏存档差不多,运行到关键位置,建立一个关键点保存已运算的部分,方便回滚及计算。
保存下来的checkpoint关键点模型,可以支持我们AI作图。
因为是检查点模型,大部分的模型具有不断往下迭代更新的能力。
safetensors模型
这种模型稍微小一些
是训练者为了让模型更加可靠、高效而开发的
文件夹
那么这些模型在哪个文件夹呢?
在sd-webui-aki-v4.1\models\Stable-diffusion文件夹下
VAE
有时候我们会看到 VAE 的标识,这是什么?
VAE 全称:variational Auto Encoder:变分自解码器
可以理解为调色滤镜,主要影响画面的色彩质感
现在大部分模型已经把VAE放到checkpoint模型下,不需要再加载。
也有一部分模型还是需要加载vae的,不然图片有可能发灰发白
这种模型的文件夹在sd-webui-aki-v4.1\models\VAE
模型在哪下载
模型的下载途径有很多,这里推荐两个比较好的Hugging face,C 站。
Hugging face:https://huggingface.co/models
下载SD官方模型
搜索栏输入:stable diffusion
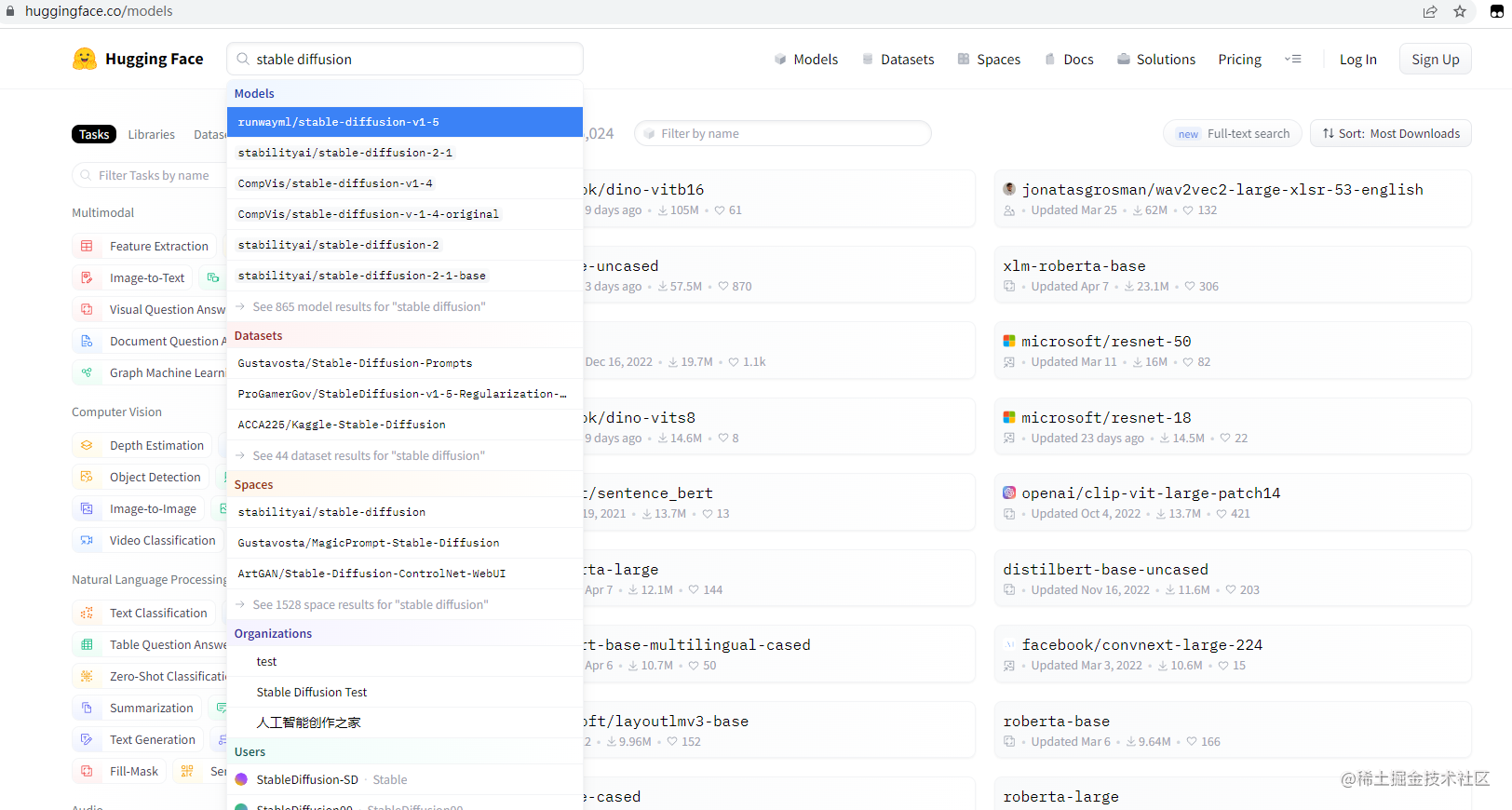
文生图模型
点击:Text-to-Image
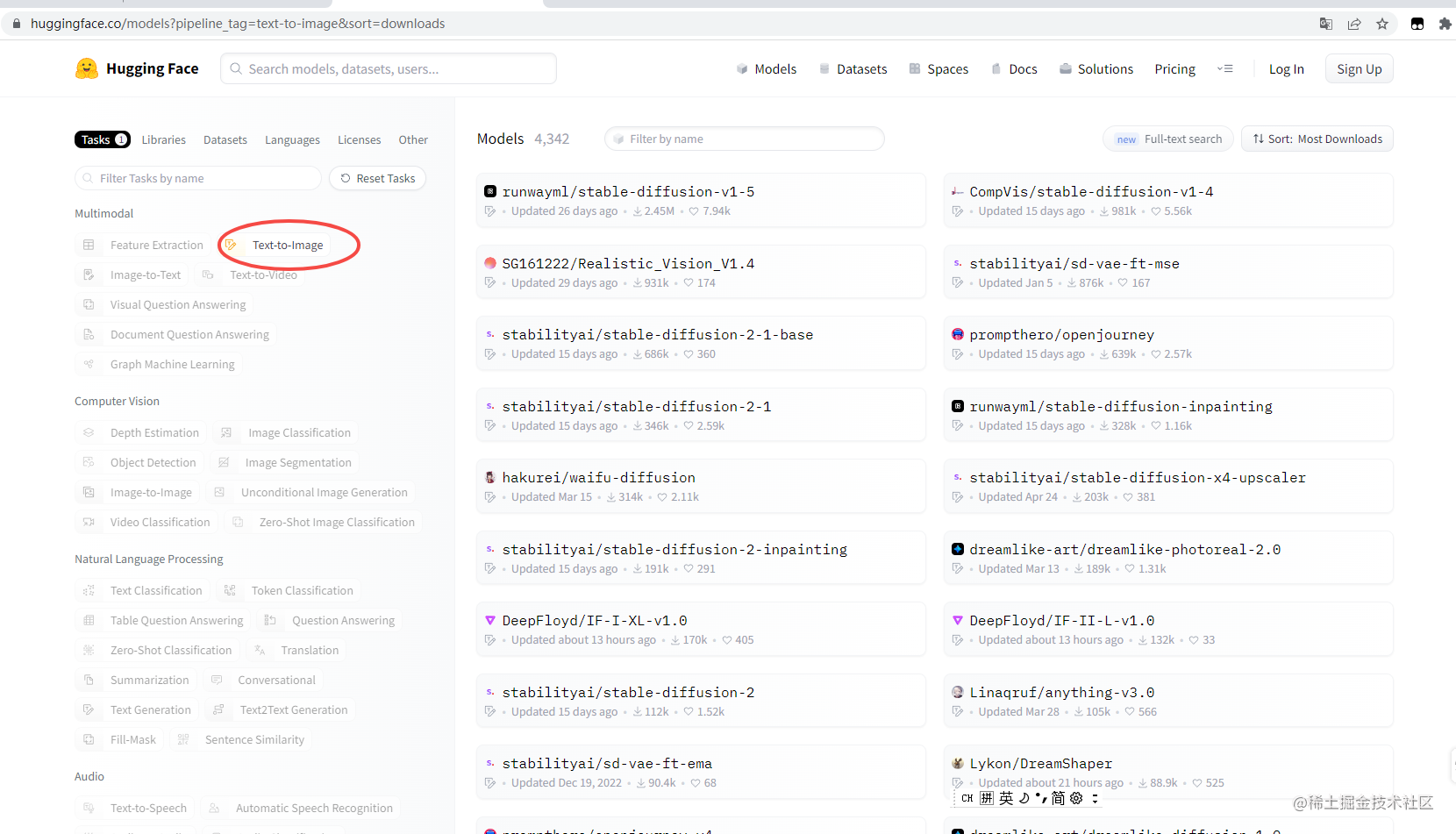
例如:waifu anythin dreamShaper模型
标签介绍
Model card:介绍
Files and versions:文件下载,模型文件一般再safety_checker文件夹
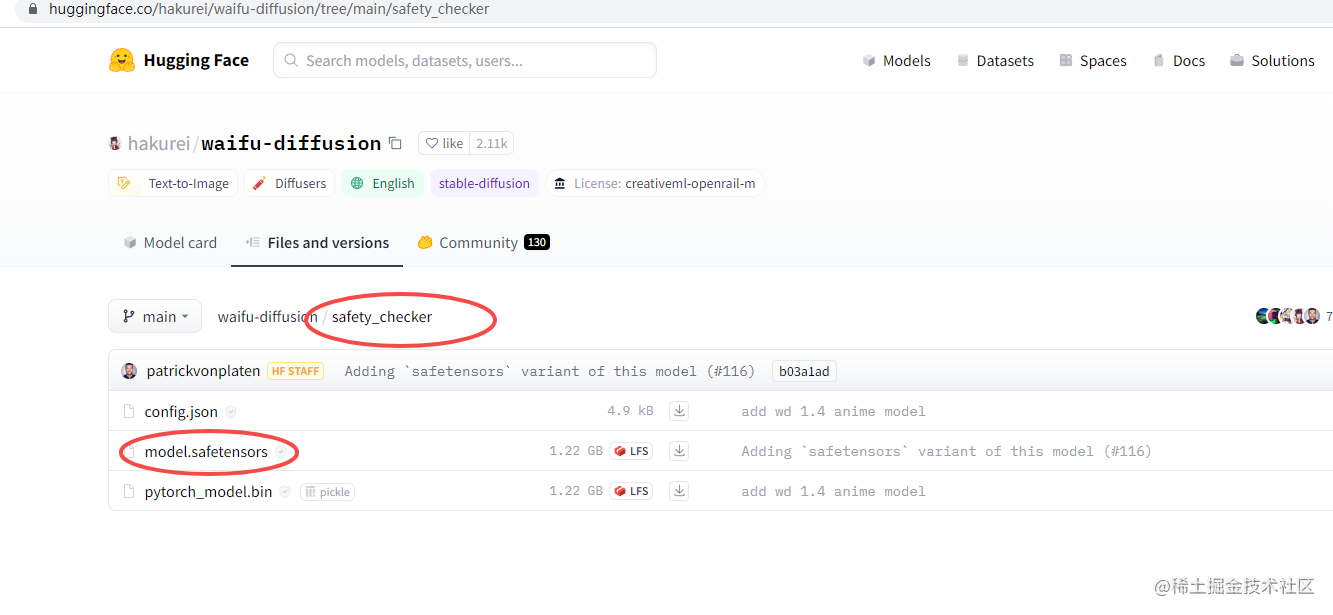
community:社区,讨论区
C站:https://civitai.com/
下面介绍一下如何使用该网站。
筛选模型的类型
例如选checkpoint模型,则选择checkpoint即可

CheckPoint Type (模型的类型)
CheckPoint Type 处有三个选项
- ALL:所有类型,这里一般选 ALL 即可
- Trained:这个一般是作者训练的一手模型
- Merge:这个融合模型,是把多个模型融合在一起,一般的名称为xxx_Mix

Base model
SD发展很快,因为开源,不少大佬不断更新,出现了很多 SD 的版本,而模型训练需要基于 SD 的底模进行训练,这里便是选择基于SD哪个版本为底模进行训练的。

类型筛选标签

模型下载
点击进入卡片,会看到有下载的按钮

复制Prompt(提示词)
那么下载模型后,如何能够生成作者类似图片呢,这里可以复制作者的提示词。
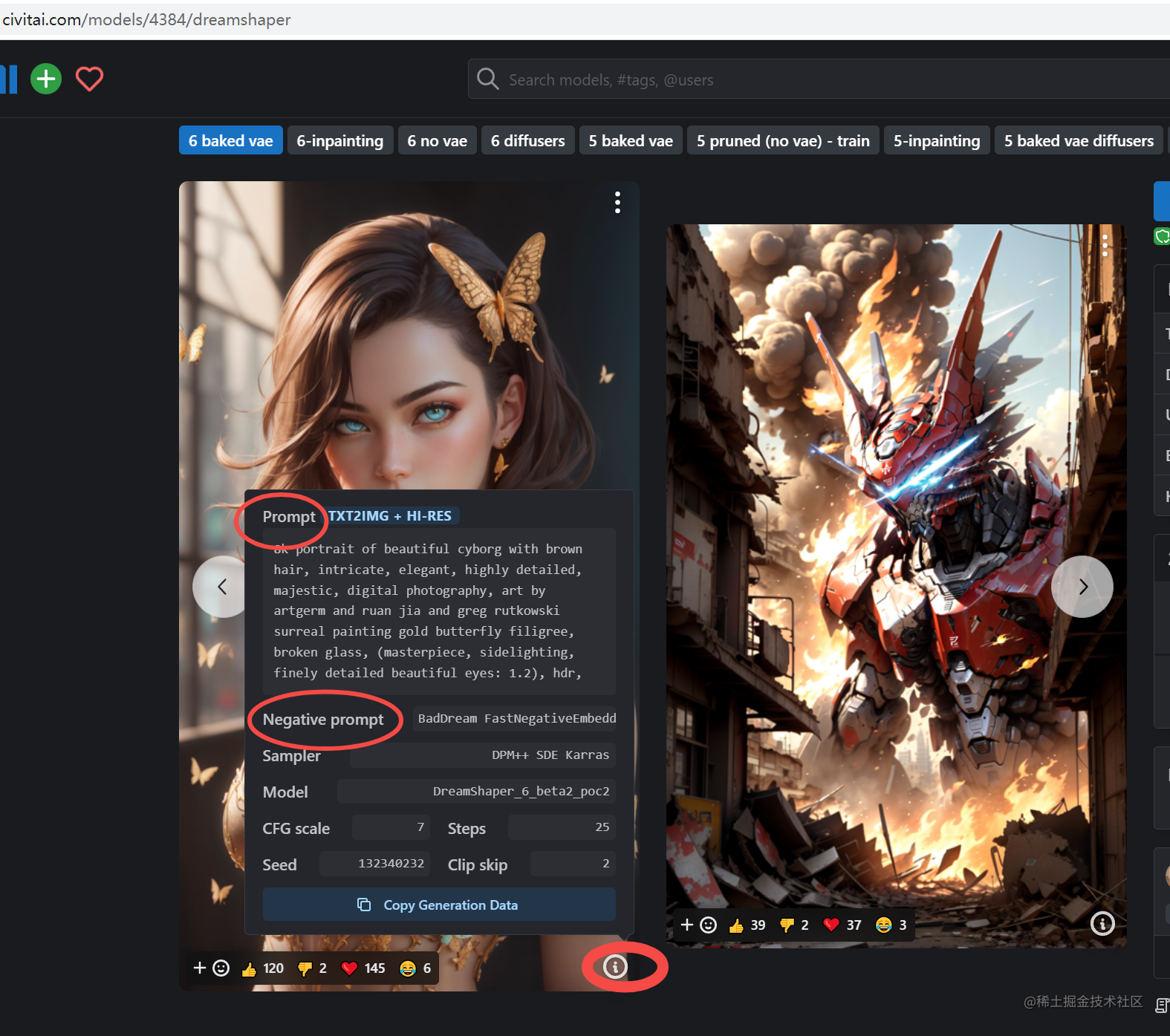
其他人做的图片分享
在这里可以找到很多其他的作者分享的图片,根据图片,可以找到图片使用的模型,以及使用的提示词,这里就像抄作业一样,复制好的提示词到我们自己的 SD 上。

模型进阶
上面我们提到基本是大模型,放在文件夹sd-webui-aki-v4.1\models\Stable-diffusion下,那么除了这些大模型外。
我们还需要了解三种小模型:
- Embedding:文本嵌入 嵌入式向量
- LoRa :(Low-Rank Adaptation Models)低秩模型
- Hypernetwork :超网络
既然有了大模型,我们可以根据提示词生成各种各样的图片,那么这些小模型有什么用呢?
上面的大模型我们可以比喻为上千页的大书,当我们输入提示词,AI会在大书中查找,根据提示词生成我们的图片。那么我们想生成特定种类的图片呢,这时候再写提示词,不管怎么尝试都打不到我们满意的程度,那么这时候就需要小模型了,小模型类似于书签、卡片记录了更多信息,让 AI 更加清楚的知道我们需要什么样的模型。
Embedding 文本嵌入 嵌入式向量
类似于书签,可以快速找到相应的模型类型,一般几十KB
在C站上对用这样的模型
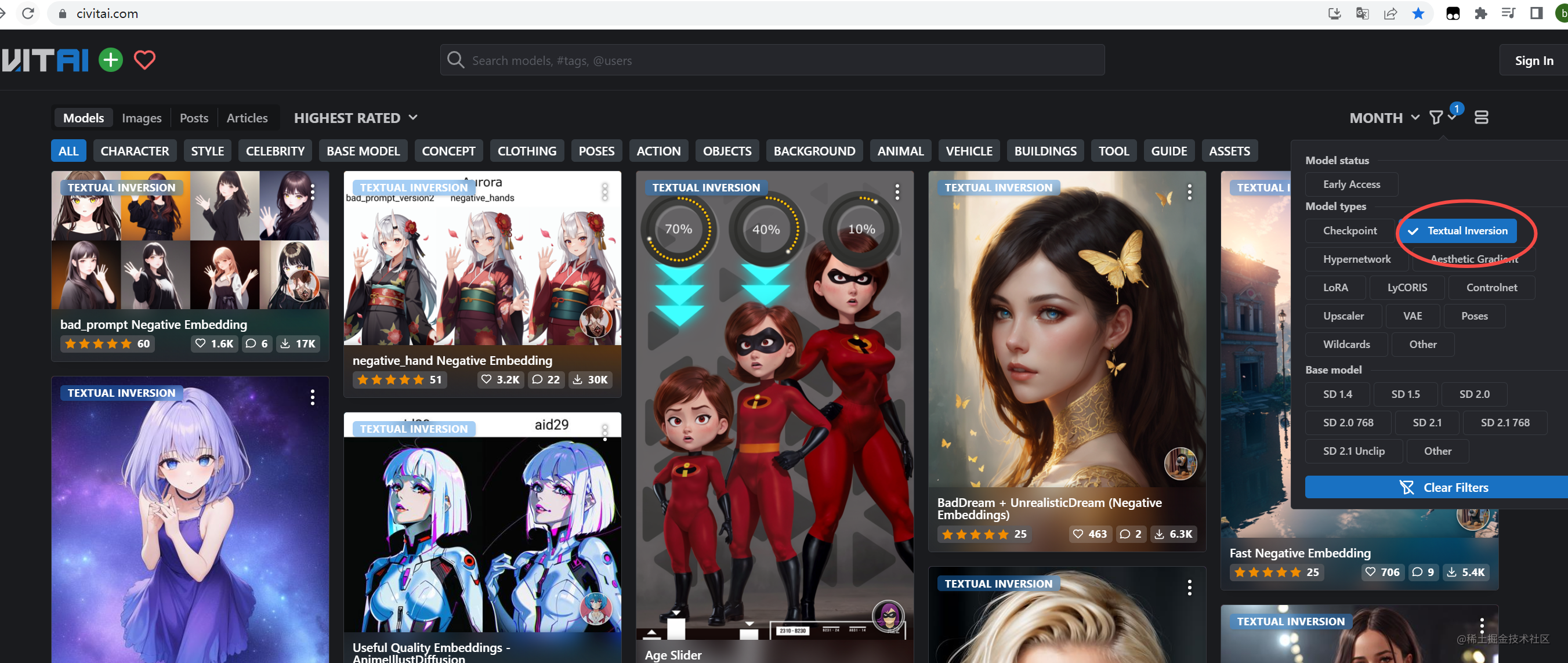
下载下来后缀一般与VAE一样,为.pt文件
放在文件夹sd-webui-aki-v4.1\embeddings下
应用
在提示词中加入关键提示词,可以在一个提示词里面加入多个Embedding
例如:复制下面的提示词
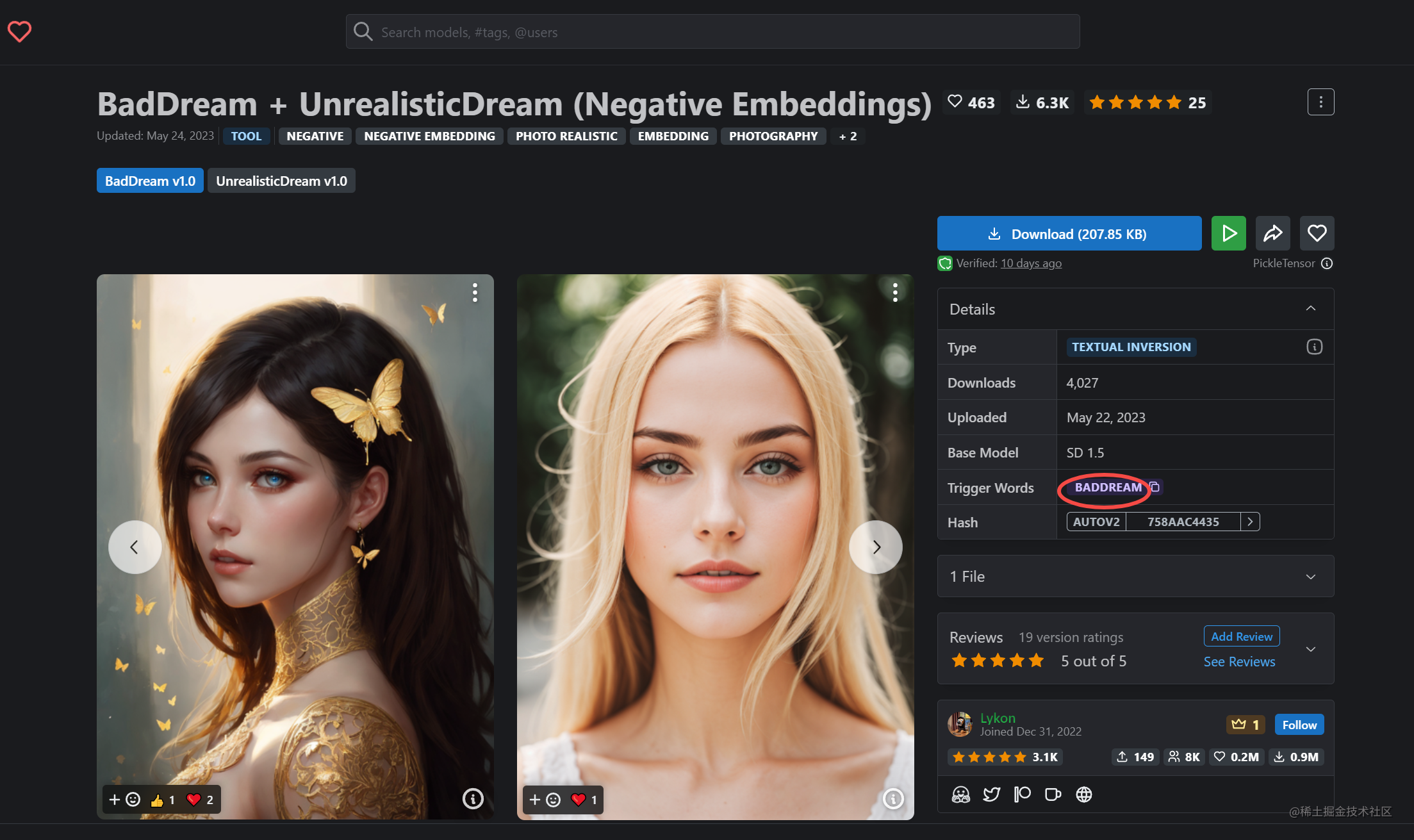
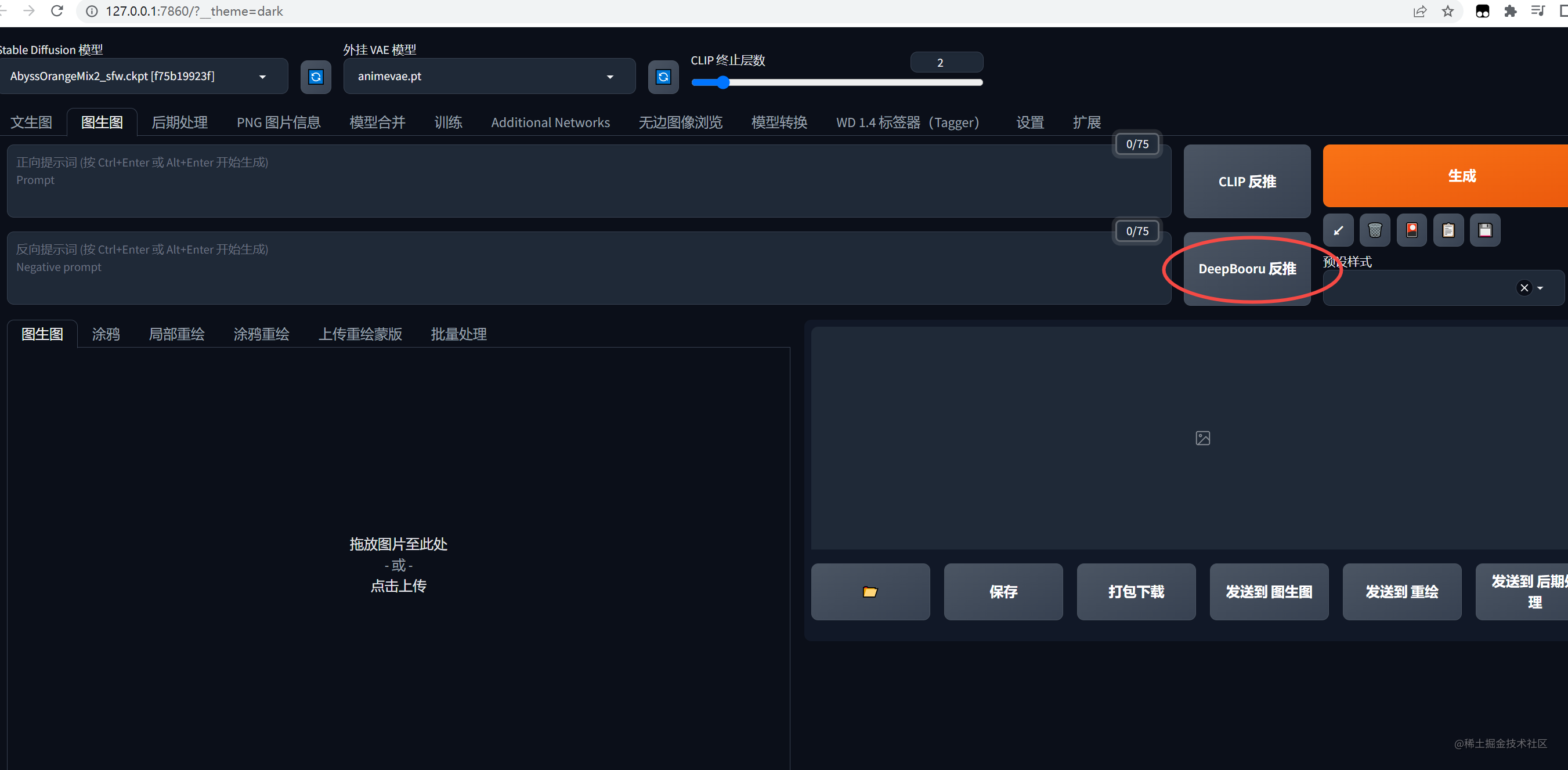
或者把图片上传到stable diffusion后使用反推出提示词
举例几个模型
-
三视图模型: CharTurner - Character Turnaround helper for 1.5 AND 2.1
链接:https://civitai.com/models/3036?modelVersionId=9857 -
解决AI画手的问题:EasyNegative
(主要针对二次元模型使用),Deep Nagative(主要针对真人使用)
把提示词放入负面提示词里
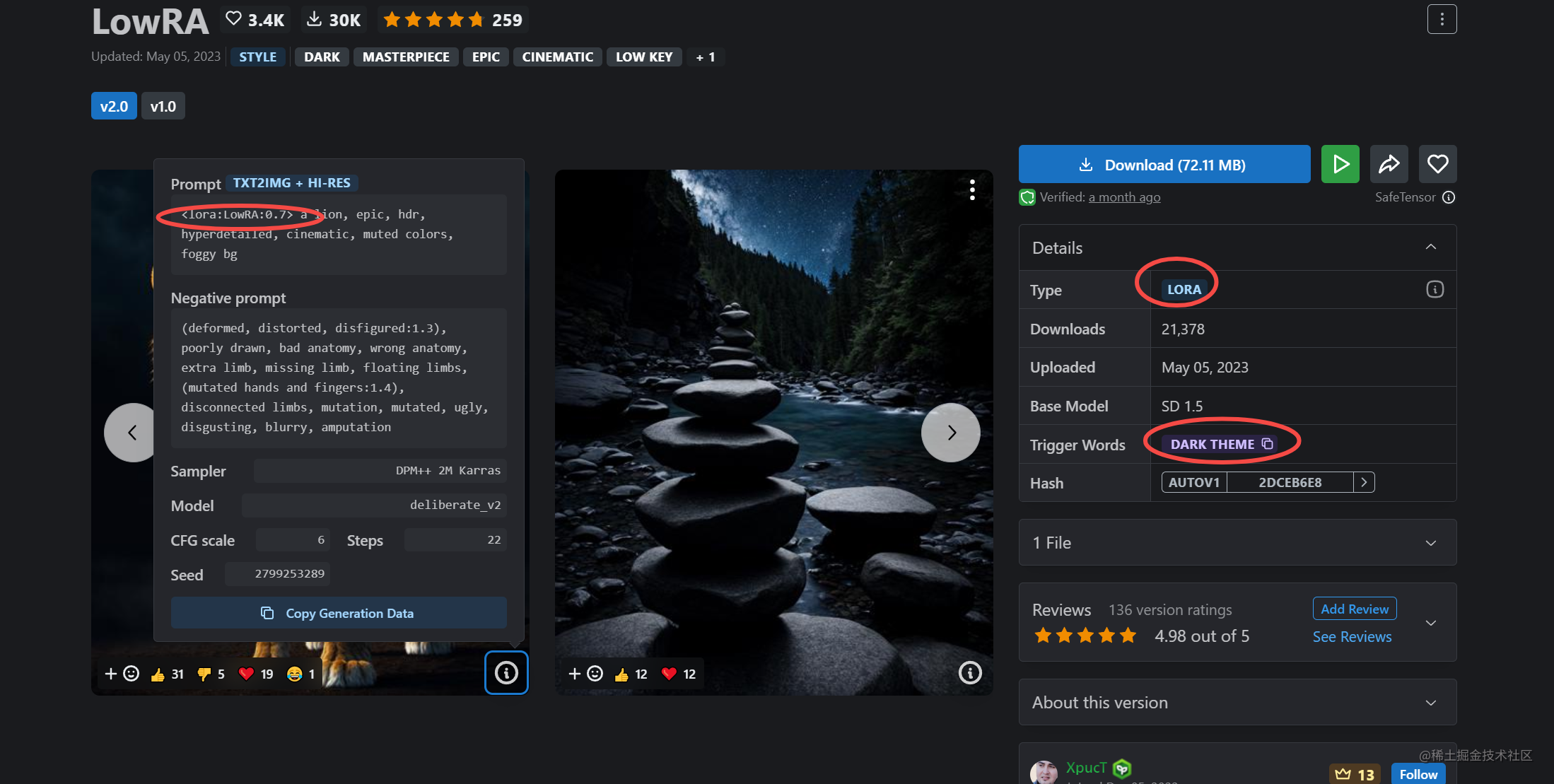
LoRa (Low-Rank Adaptation Models)低秩模型
类似于详细的描述一个东西,向 AI 传递特征准确,主体清晰的信息,让AI 可以创造出类似风格的图片,主要应用到游戏、动漫角色二次创作构建。
比如你可以让 AI 生成一只喜羊羊,那么 AI 会问了什么事喜羊羊呢?这时候通过提示词以及上面的书签我们已经无法实现。那么这时候就用到 LoRa 了,它类似一个彩色卡片,上面记录喜羊羊的信息,这样 AI 就全面认知了一个喜羊羊的信息,便能更好生成一只喜羊羊,生成一个AI里之前不认识的东西。
大小:几百兆,比大模型小很多了,因为Lora 是根据大模型进行训练的,类似彩色卡片,记录指定的信息。当然我们也可以自己训练模型,可以看这篇文章
下载放到文件夹\sd-webui-aki-v4.1\models\Lora,
使用
例如下面的例子:把文件名加入提示词里
<lora:dark theme:0.7>,0.7为权重
训练自己的 Lora模型
C 站上下载的都是别人训练好的,如果我想训练自己指定的模型,那么该怎么训练呢?这里有篇文章可以看看:链接
Hypernetwork 超网络
有点类似LoRa,主要针对于画风的改变,设置特定的艺术风格,例如把图片改成雕塑化、像素画、抽象化、Q版图等
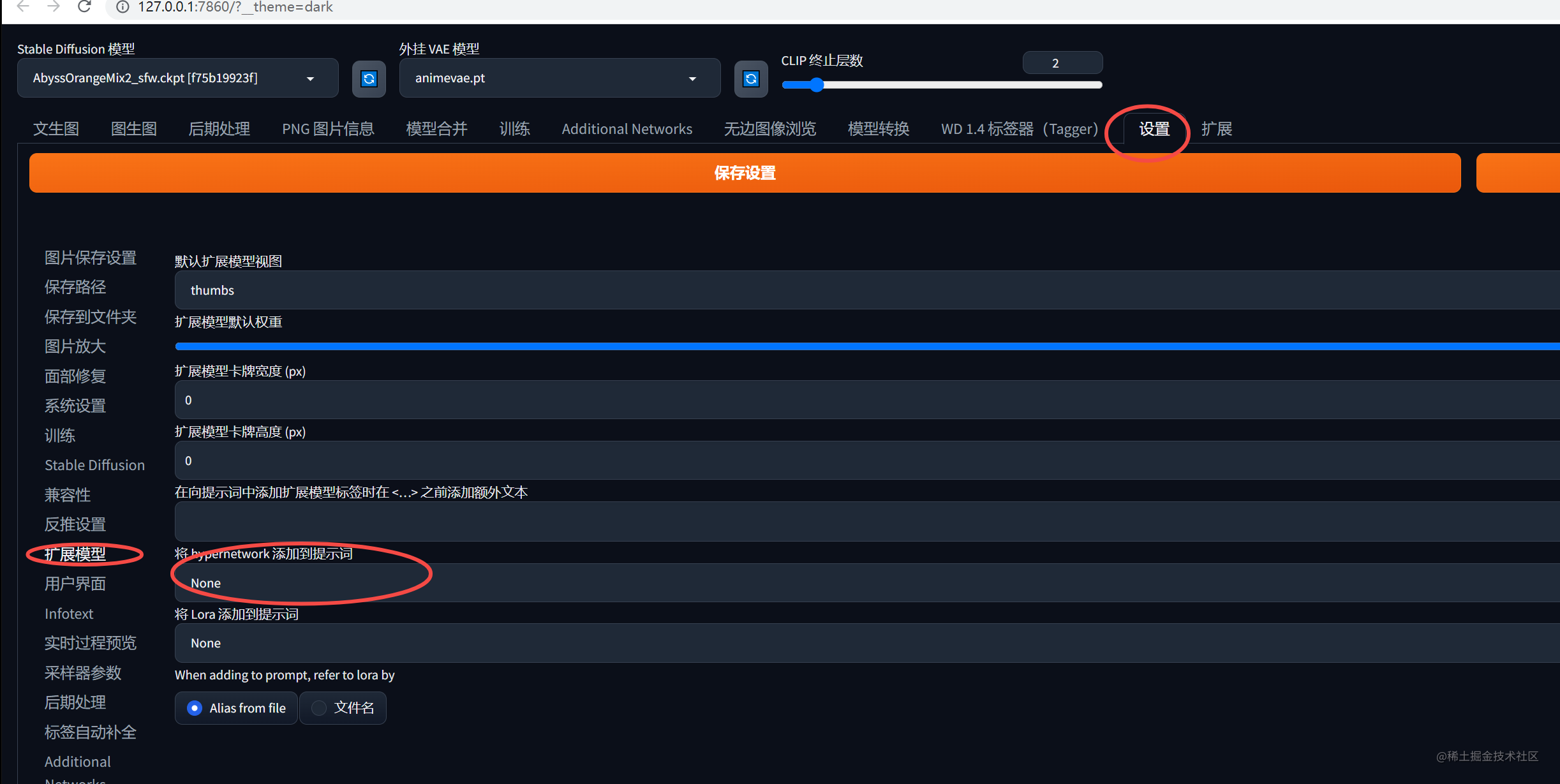
使用
设置–》扩展模型,选择放到文件夹下的模型,如果没有就刷新一下
举例
q版可爱画风:Waven Chibi Style
文件夹
下载后放到:sd-webui-aki-v4.1\models\hypernetworks
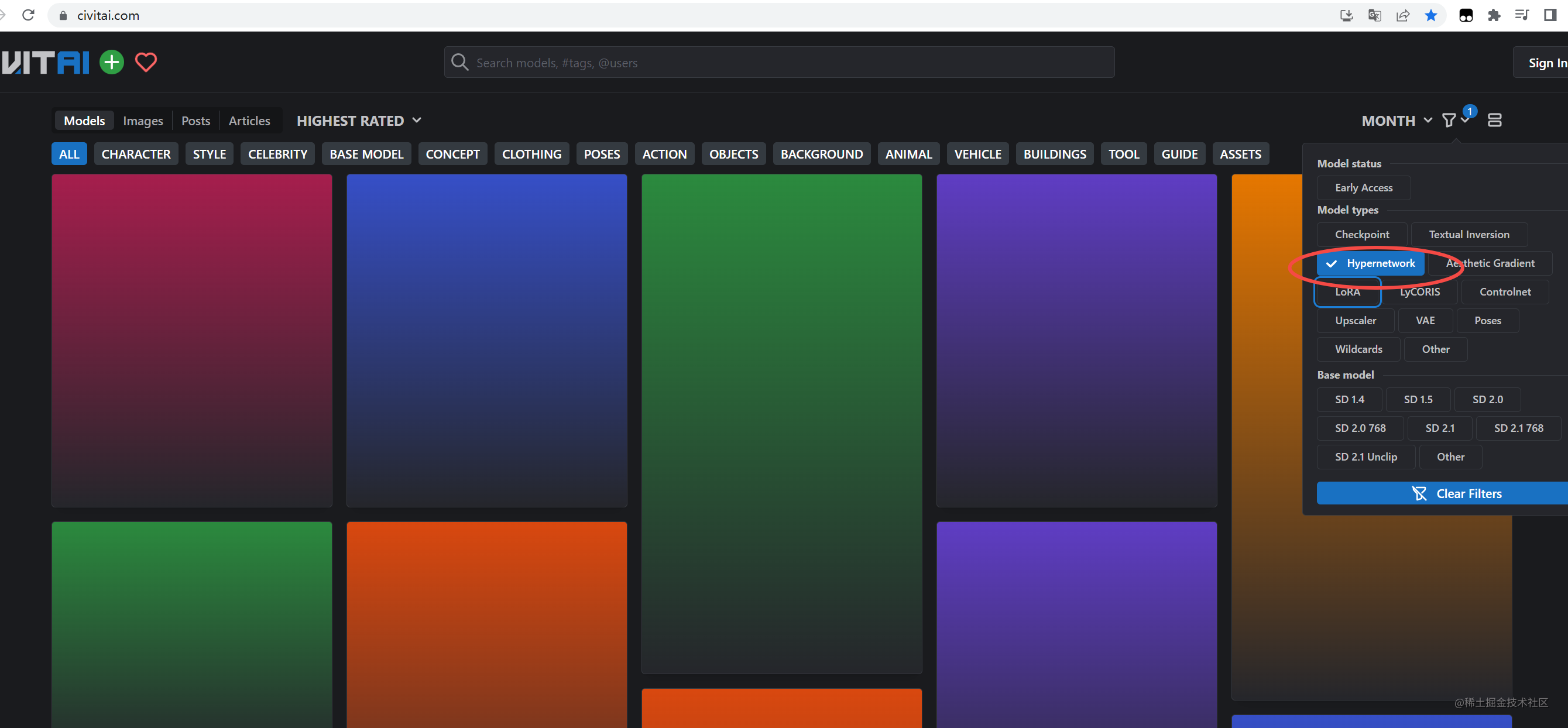
下载
C站下载,筛选Hypernetwork
总结
这里了解关于 StableDiffusion基础概念,再使用 SD 时,不至于摸不着头脑,当然还有一些别的操作,欢迎关注我,有时间会分享出来。
如果你想训练自己的Lora,比如想用指定模特图片,生成照片,可以查看这篇文章,详细介绍了如何训练自己的 Lora 模型。






![强化学习基础篇[3]:DQN、Actor-Critic详解](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)