pandas数据预处理
- pandas及其数据结构
- pandas简介
- Series数据结构及其创建
- DataFrame数据结构及其创建
- 利用pandas导入导出数据
- 导入外部数据
- 导入数据文件
- 导出外部数据
- 导出数据文件
- 数据概览及预处理
- 数据概览分析
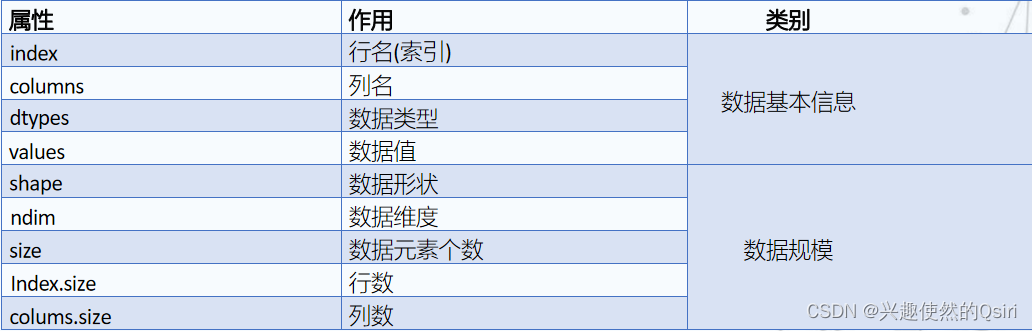
- 利用DataFrame的常用属性
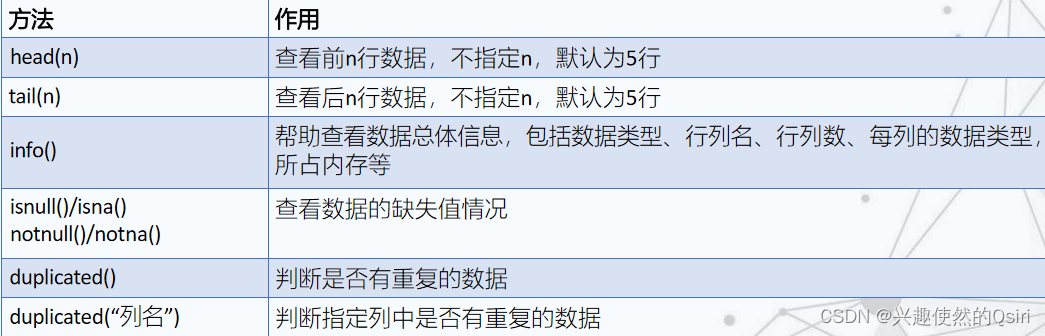
- 利用DataFrame的常用方法
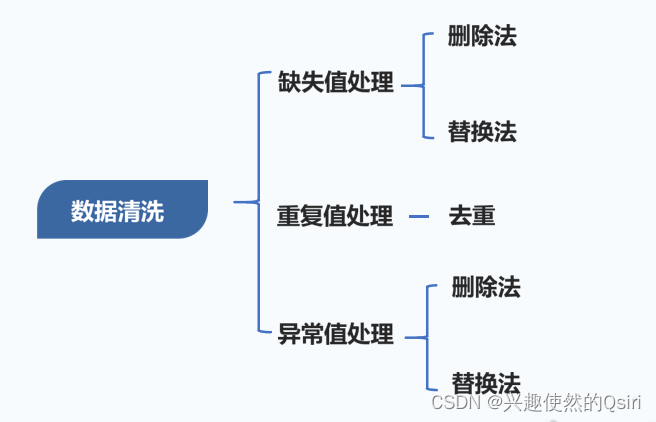
- 数据清洗
- 缺失值处理
- 删除法
- 替换法
- 重复值处理
- 去重
- 异常值检测与处理
- 数据抽取与合并
- 数据抽取
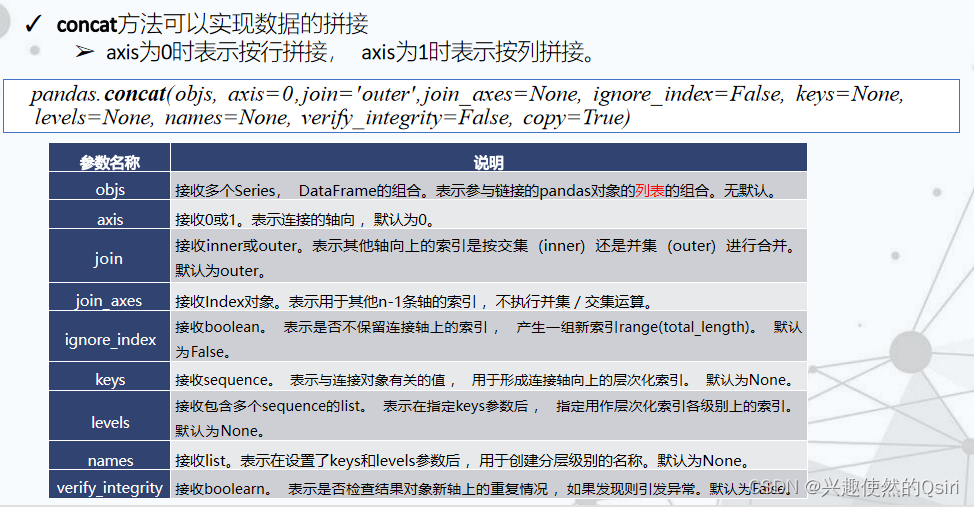
- 数据合并
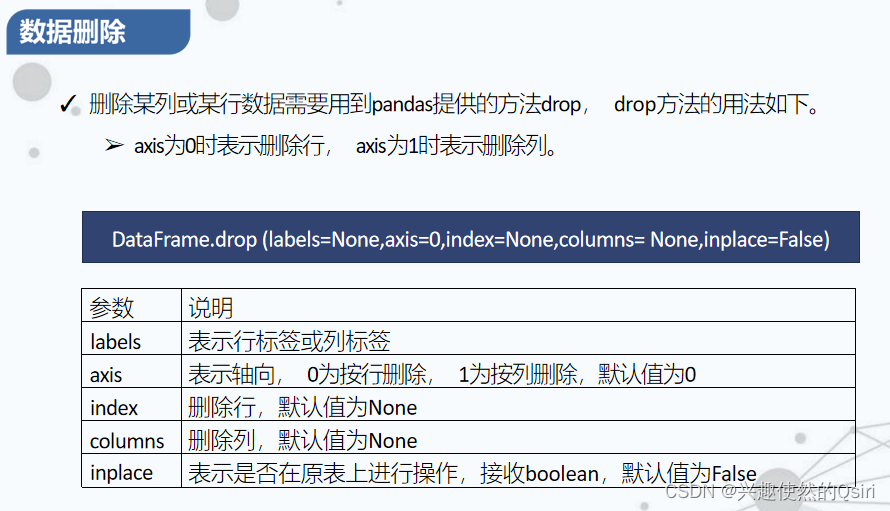
- 数据增删改
- 数据转换
- 数据的描述性统计分析
- 数据排序
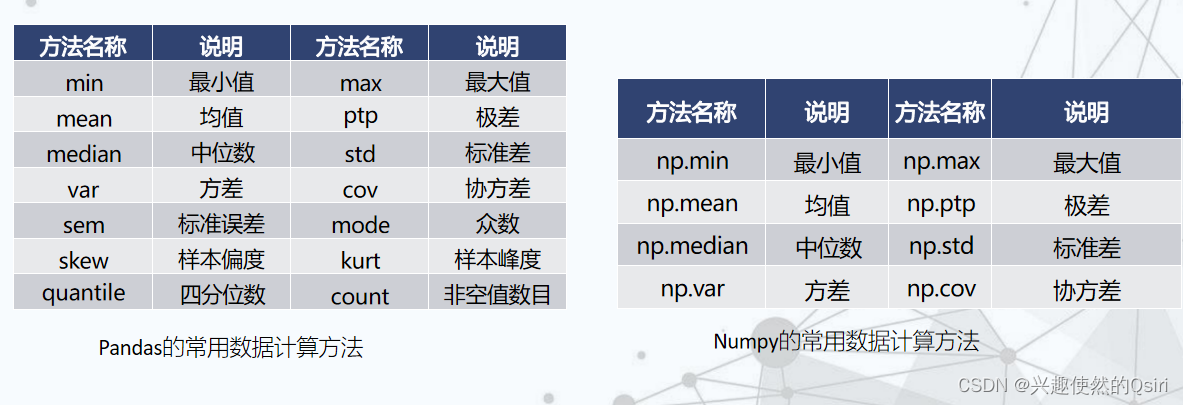
- 常见数据计算
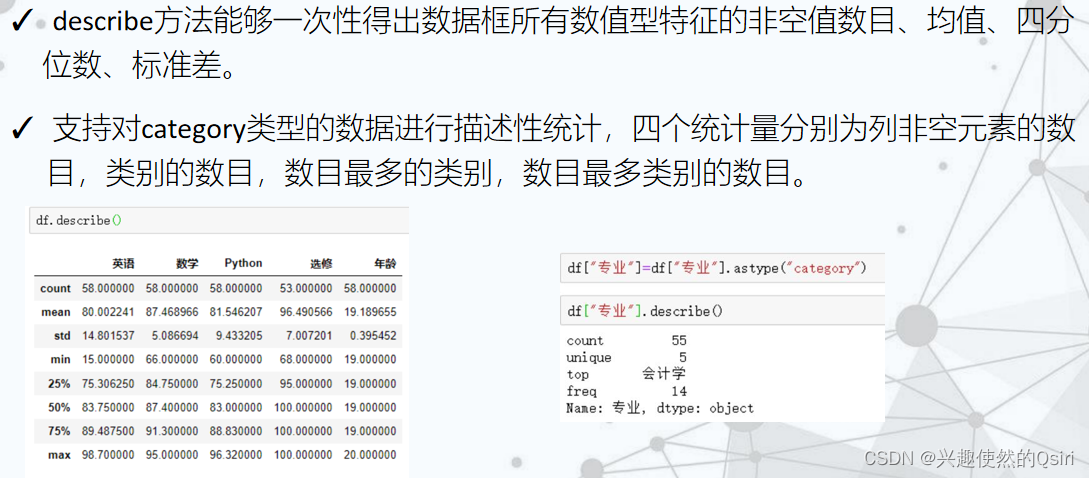
- 数值型特征的描述性统计
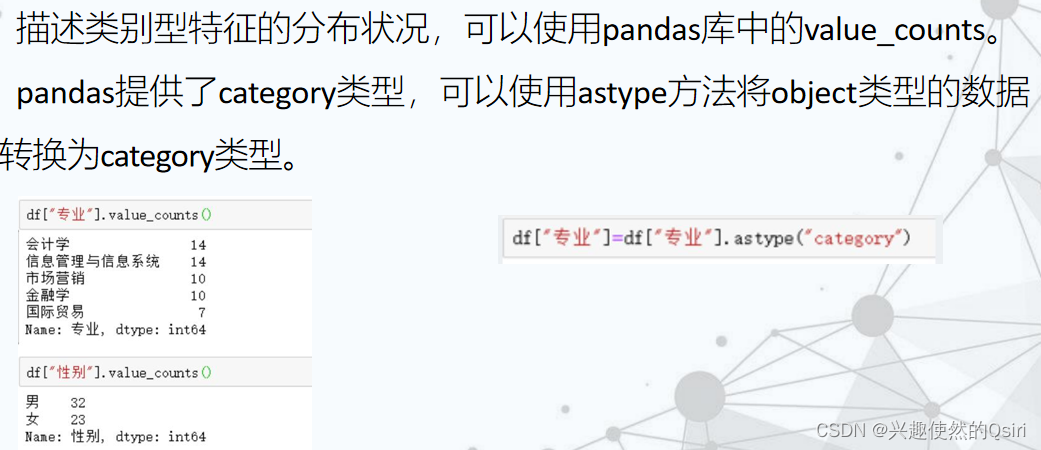
- 类别型特征的描述统计
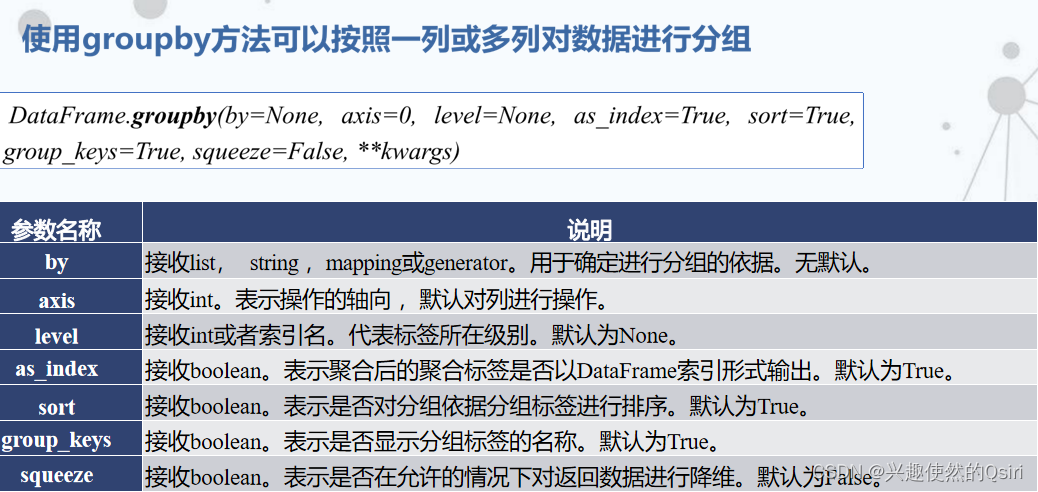
- 分组统计分析
- 数据分组
- 分组聚合
pandas及其数据结构
pandas简介
pandas是Python语言的一个第三方库,开放源码,提供高性能、易于使用的数据结构和数据分析工具。pandas是一个强大的分析结构化数据的工具集,基于numpy实现的。

Series数据结构及其创建
pandas的核心是Series和DataFrame两大数据结构
- Series数据结构是用于存储一个序列的一维数组,而DataFrame数据结构则是用于存储复杂数据的二维数据结构。
- Series是一种类似于一维数组的对象,它是由一组数据,这组数据可以是Numpy中任意类型的数据,以及一组与之相关的数据标签组成。
- Series对象的内部结构是由两个相互关联的数组组成,即数值和索引。
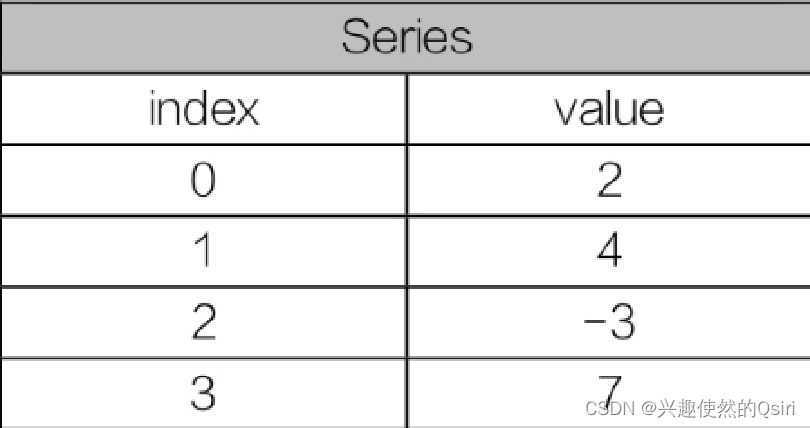
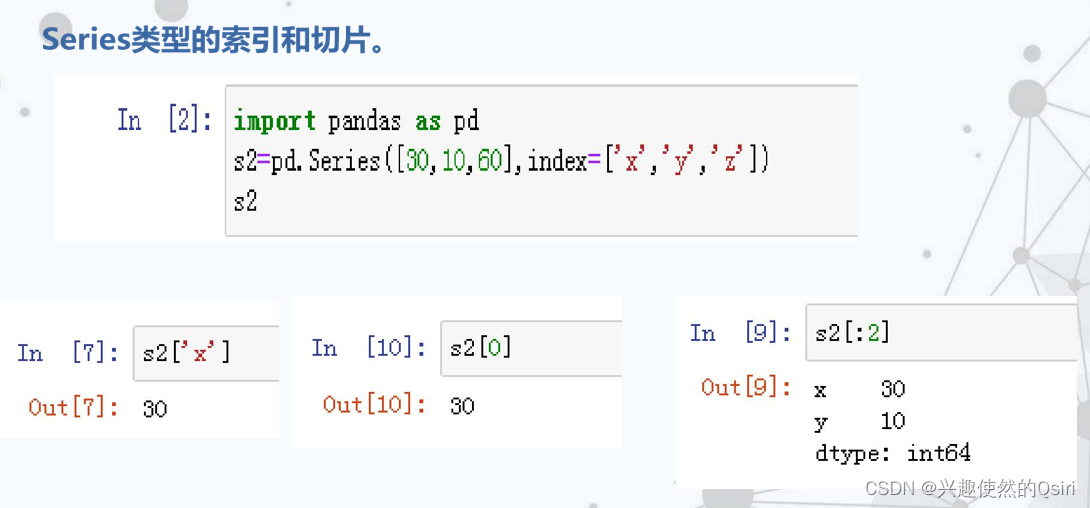
Series类型是带索引的一维数组对象。包含了一个值序列,并且包含了数据标签,称为索引(index),可通过索引来访问数组中的数据。
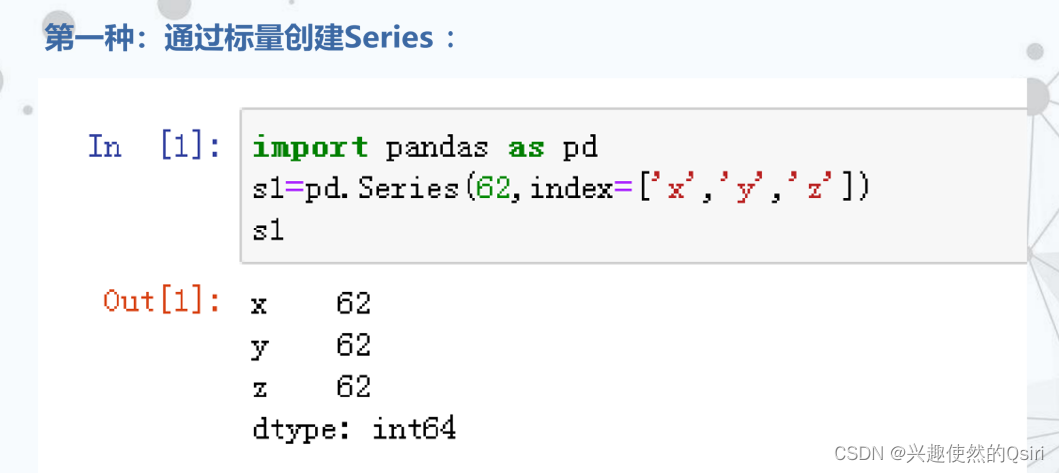
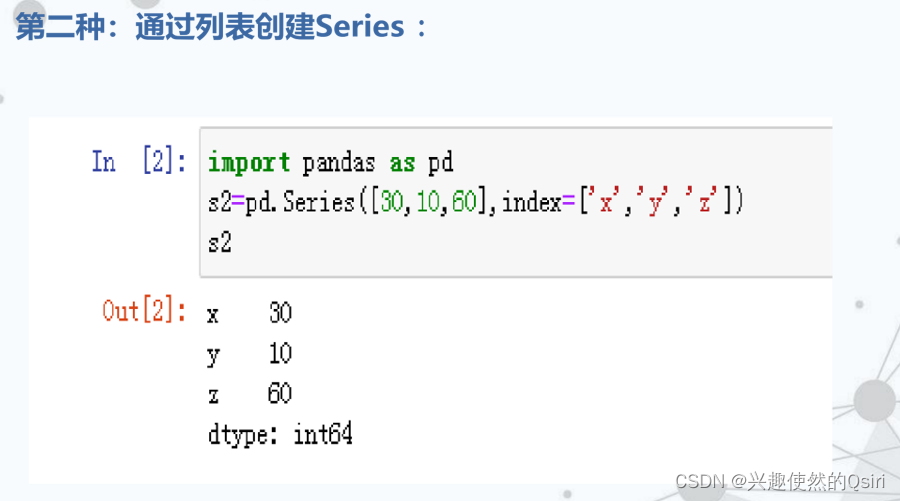
Series的创建格式:
pandas.Series(data[, index])
函数中的参数:
data是输入给Series构造器的数据。
index是Series对象中数据的标签(即索引)。
例如:
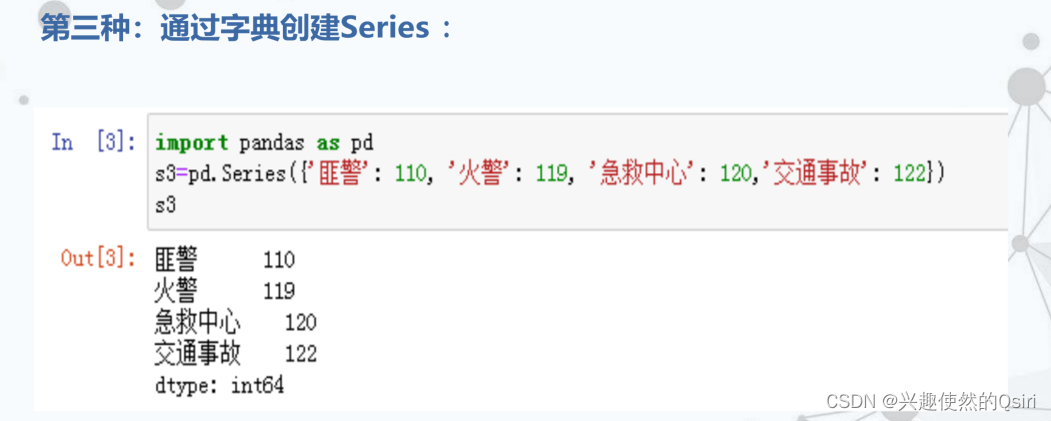
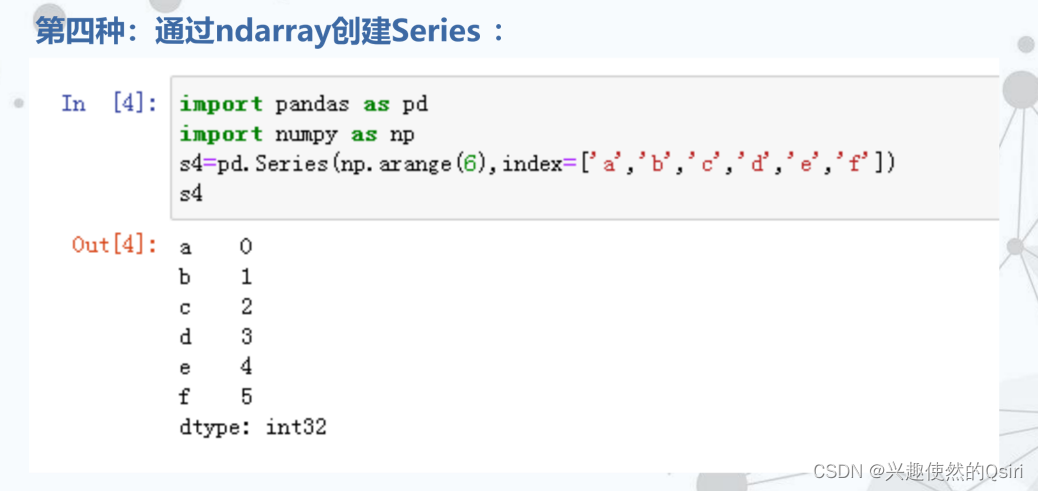

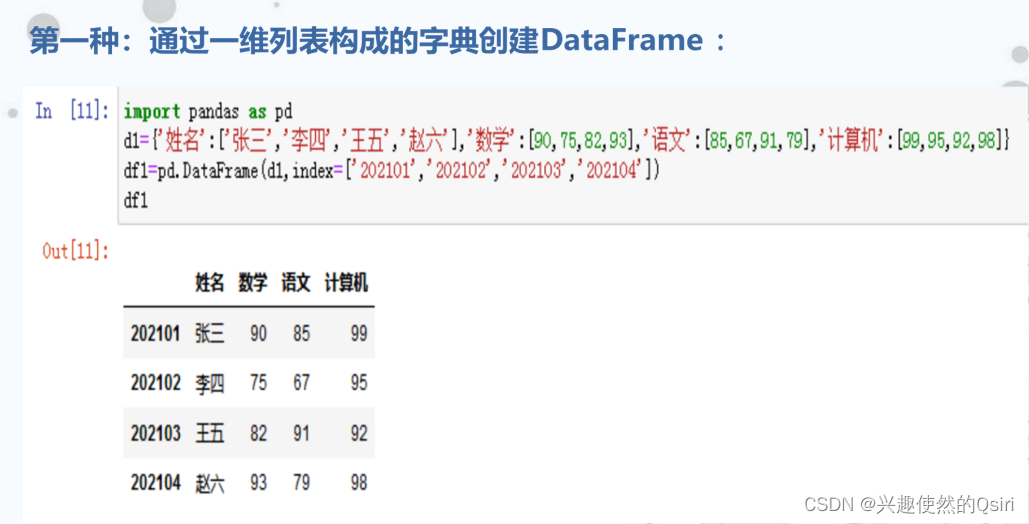
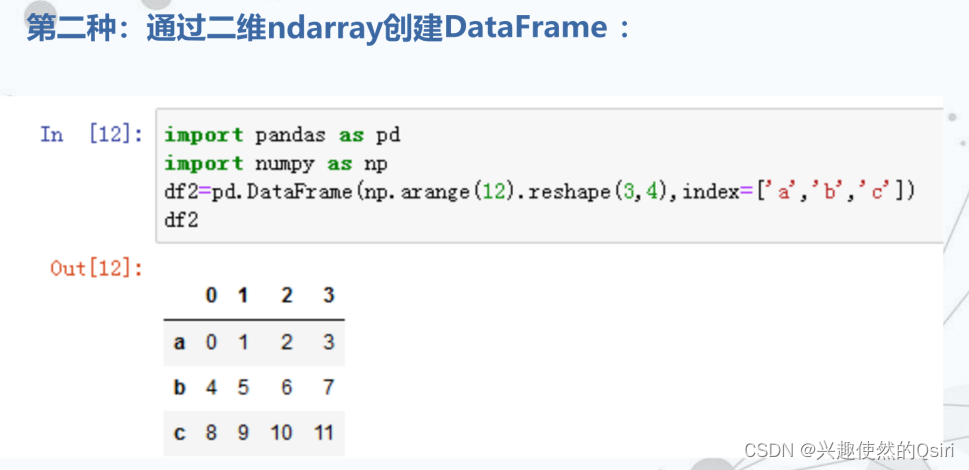
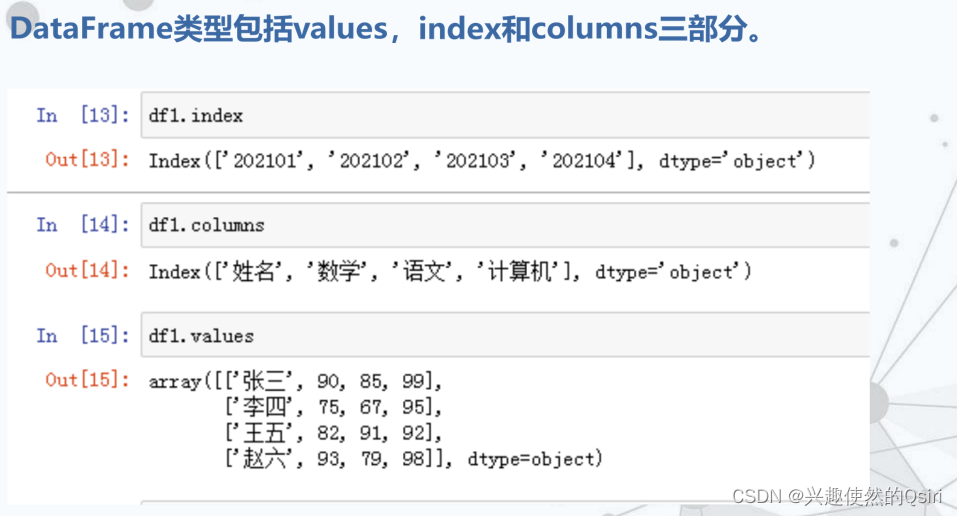
DataFrame数据结构及其创建
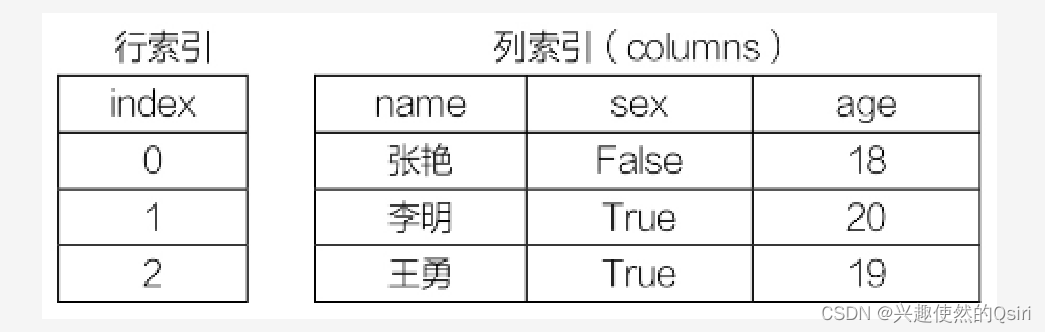
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
分别有行索引和列索引。
常用于表达二维数组,也可以表达多维数组。DataFrame的创建格式:
pandas.DataFrame(data[,index[,columns]])
函数中的参数说明:
- data是输入给DataFrame构造器的数据,见下页。
- Index是DataFrame对象中行索引的标签。
- columns是DataFrame对象中列索引的标签。
利用pandas导入导出数据
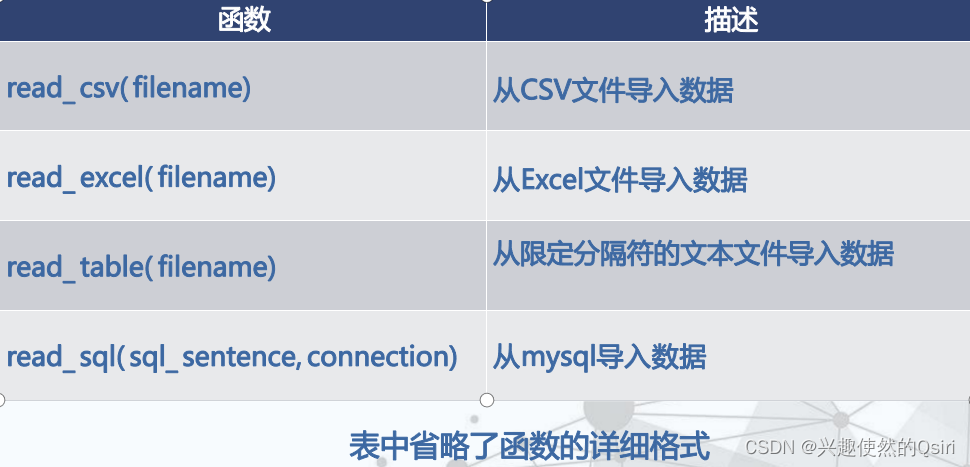
导入外部数据
导入数据文件
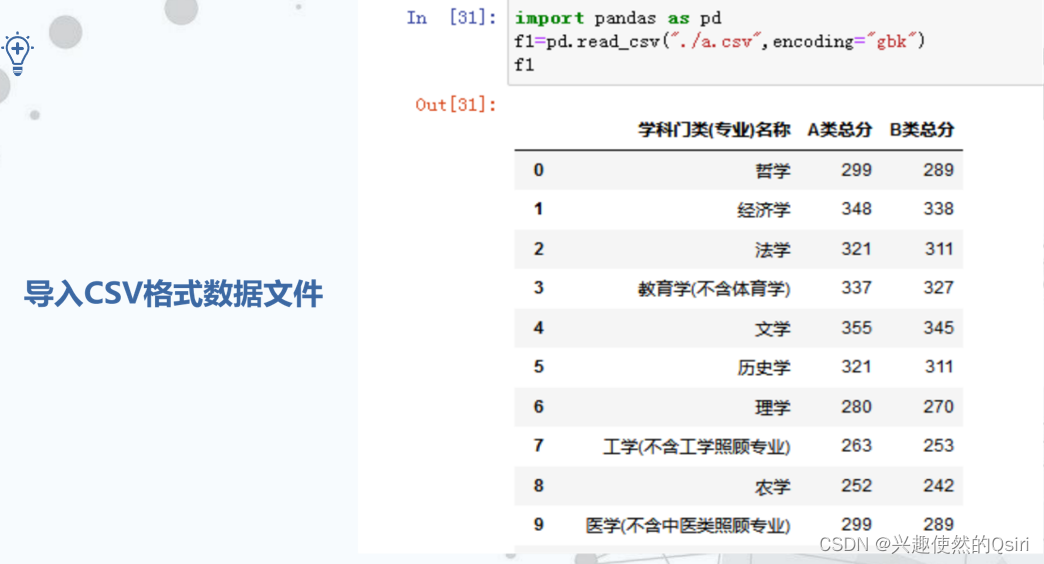
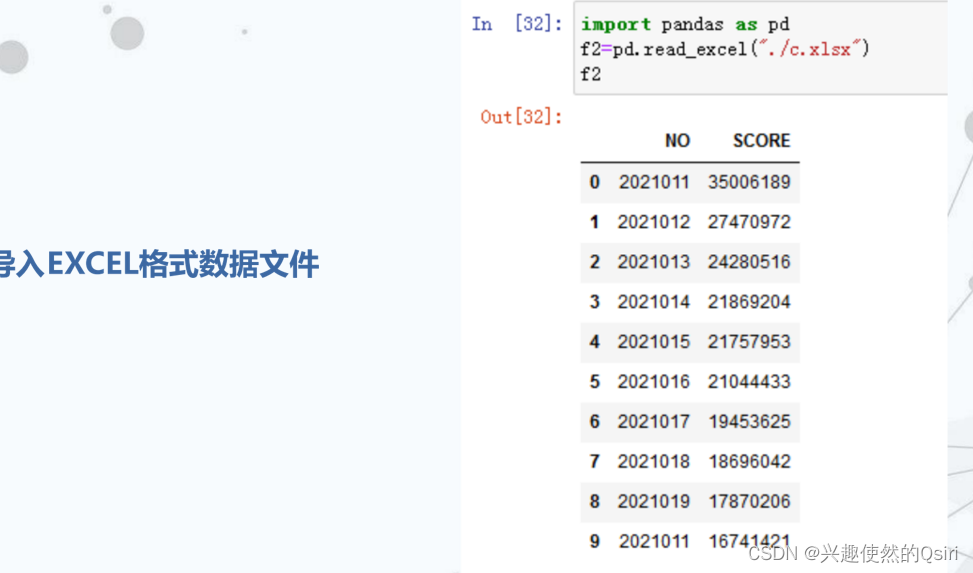
导出外部数据
导出数据文件
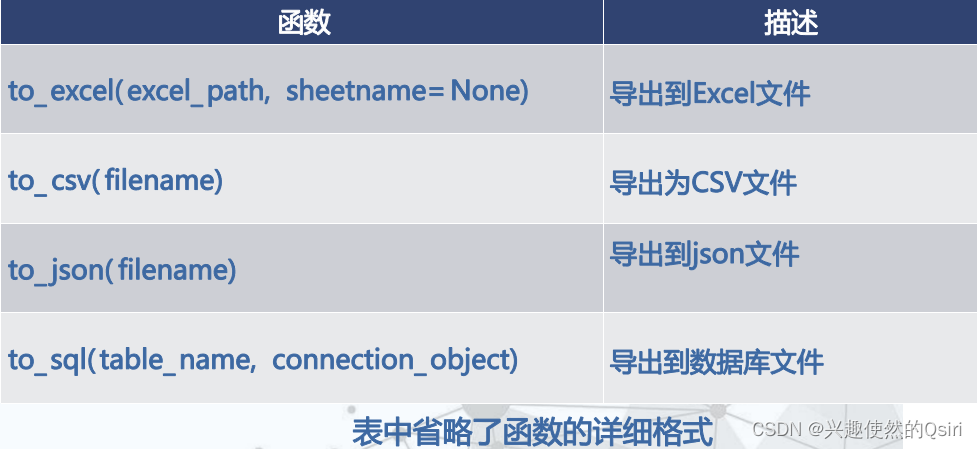
数据概览及预处理
数据概览分析
数据概览是在数据分析之前对数据的规模、数据的类型及数据的质量等进行概览性的分析
利用DataFrame的常用属性
利用DataFrame的常用方法

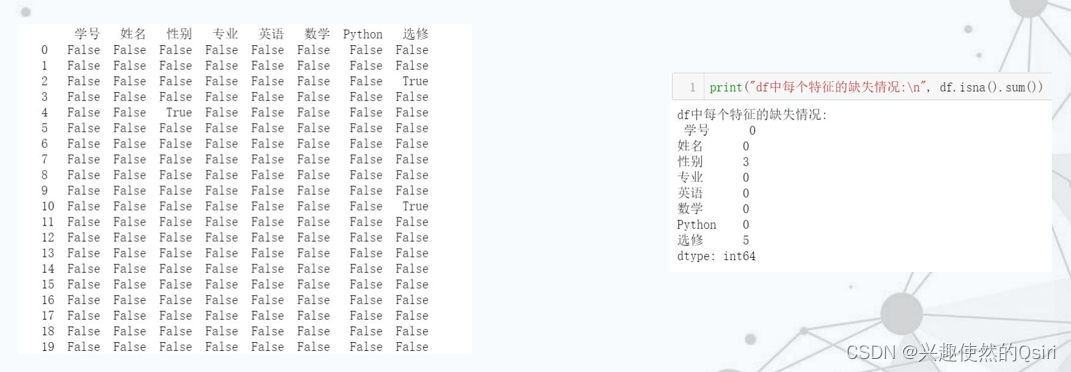
数据清洗
数据清洗是通过预处理,剔除数据中的噪声,恢复数据完整性和一致性
缺失值处理
删除法
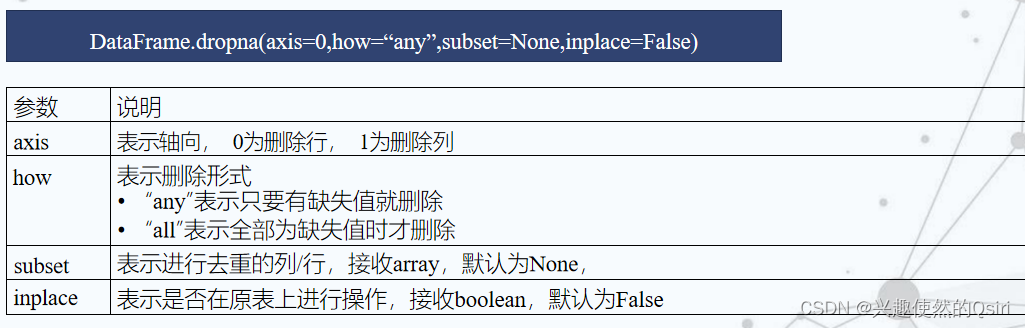
替换法
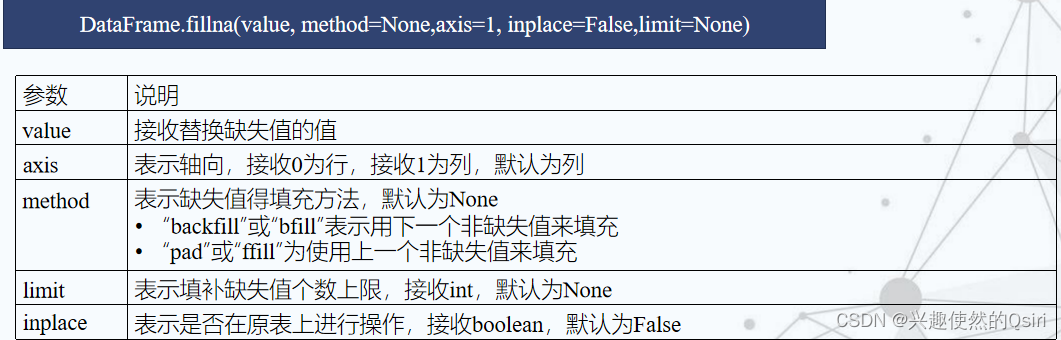
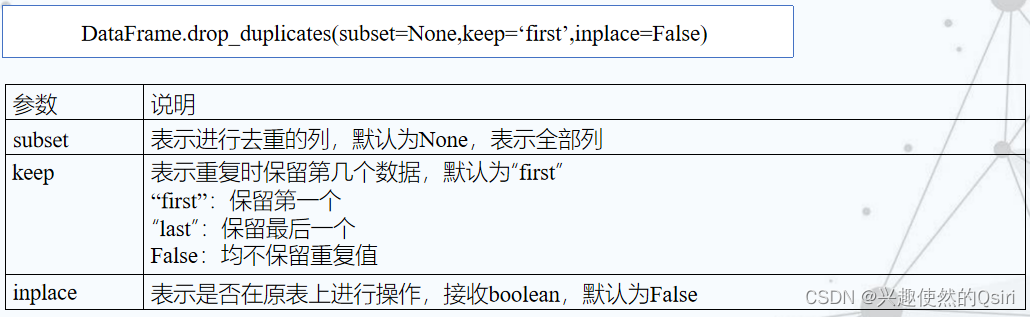
重复值处理
去重
异常值检测与处理

数据抽取与合并
数据抽取
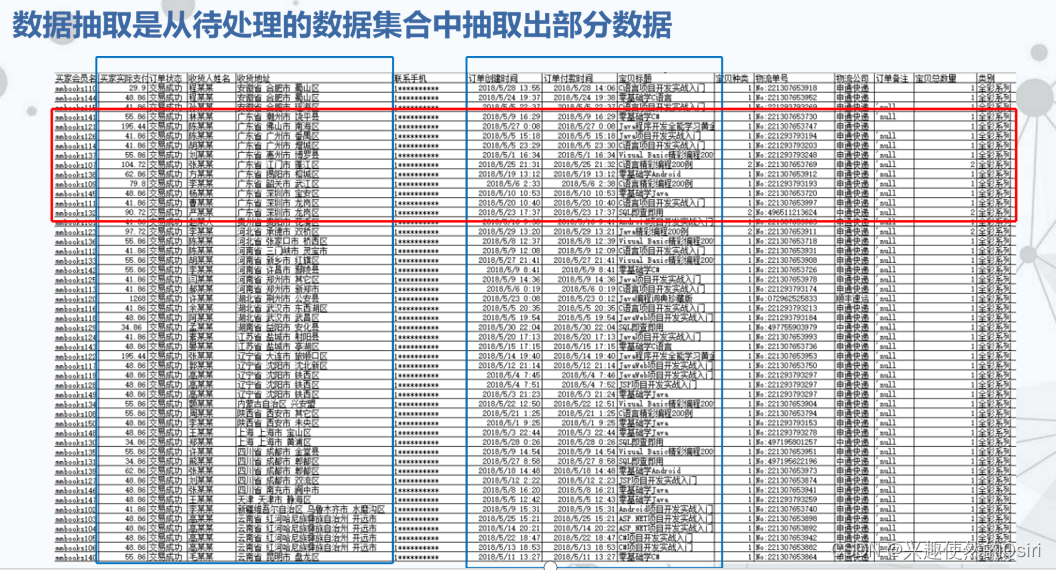
数据合并
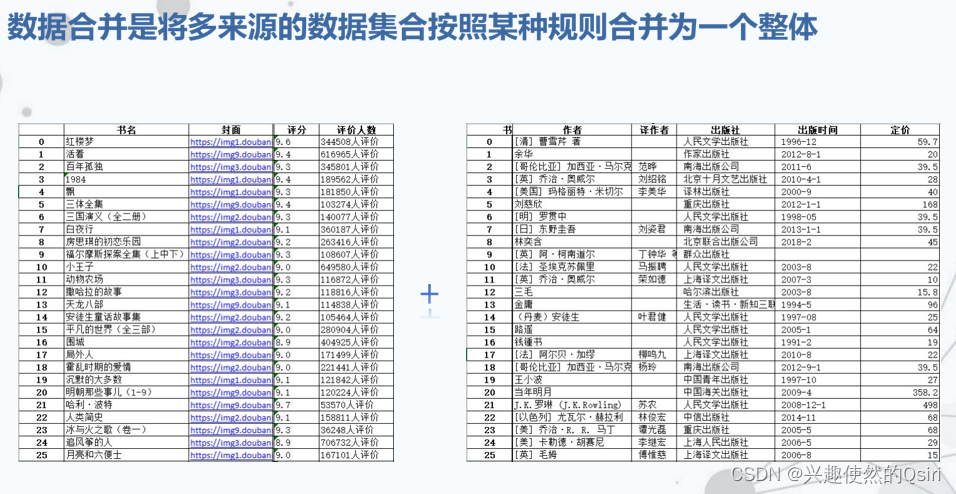
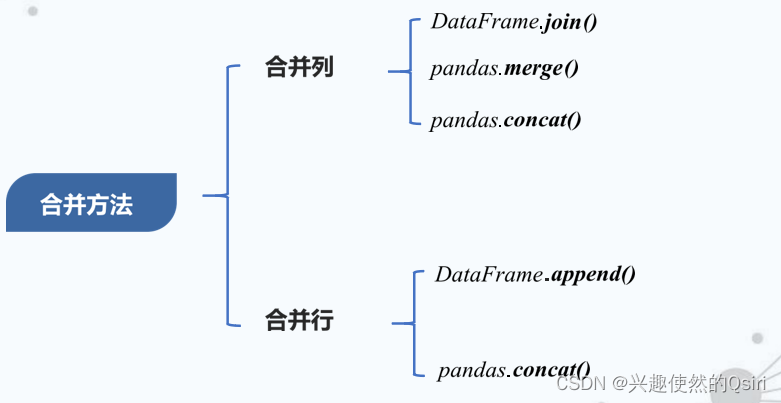

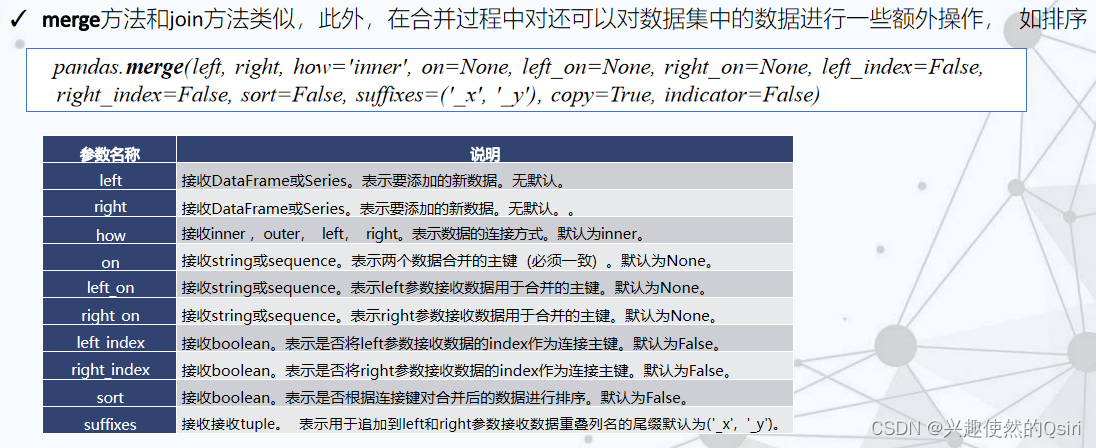
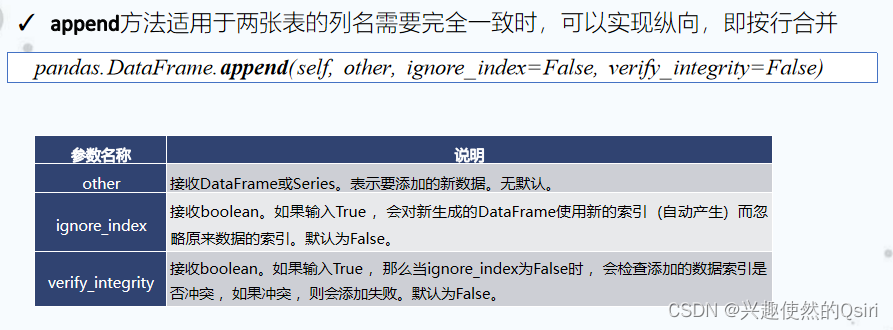
数据增删改


数据转换

数据的描述性统计分析
数据排序


常见数据计算

数值型特征的描述性统计
类别型特征的描述统计
分组统计分析
数据分组
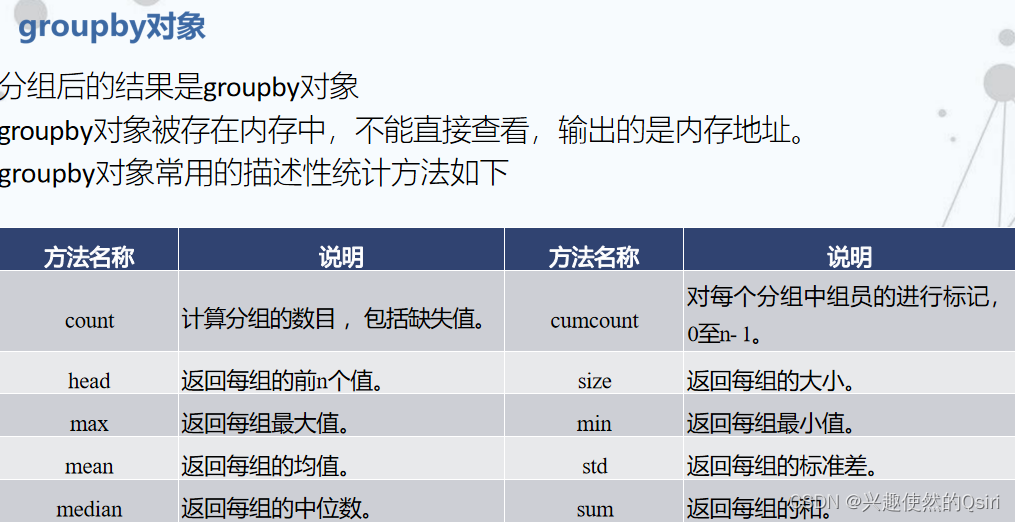
分组聚合








![强化学习基础篇[3]:DQN、Actor-Critic详解](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)