JVM 会在不影响正确性的前提下,可以调整语句的执行顺序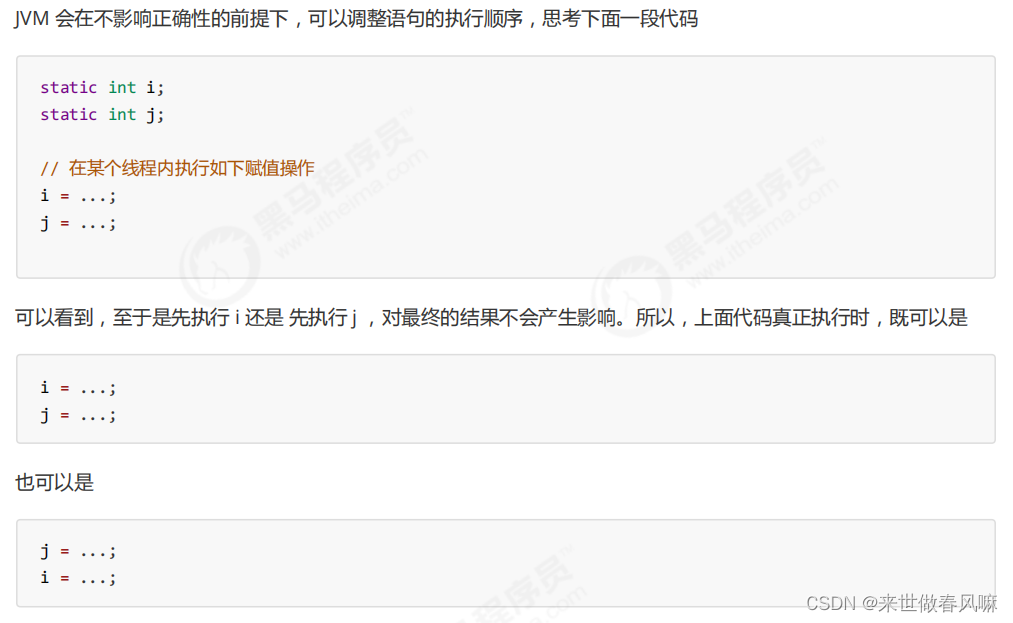 这种特性称之为『 指令重排 』,多线程下『指令重排』会影响正确性。为什么要有重排指令这项优化呢?从 CPU 执行指令的原理来理解一下吧
这种特性称之为『 指令重排 』,多线程下『指令重排』会影响正确性。为什么要有重排指令这项优化呢?从 CPU 执行指令的原理来理解一下吧
一、原理之指令级并行(了解)(P141)
1. 鱼罐头的故事

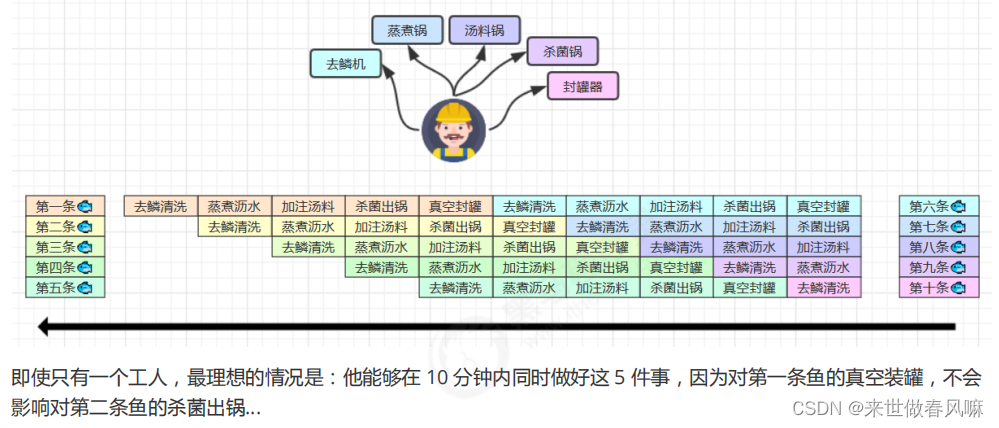
2. 名词
(1)Clock Cycle Time主频的概念大家接触的比较多,而 CPU 的 Clock Cycle Time (时钟周期时间),等于主频的倒数,意思是 CPU 能够识别的最小时间单位,比如说 4G 主频的 CPU 的 Clock Cycle Time 就是 0.25 ns,作为对比,我们墙上挂钟的 Cycle Time 是 1s例如,运行一条加法指令一般需要一个时钟周期时间
(2)CPI有的指令需要更多的时钟周期时间,所以引出了 CPI ( Cycles Per Instruction )指令平均时钟周期数
(3)IPCIPC ( Instruction Per Clock Cycle) 即 CPI 的倒数,表示每个时钟周期能够运行的指令数
CPU 执行时间程序的 CPU 执行时间,即我们前面提到的 user + system 时间,可以用下面的公式来表示程序 CPU 执行时间 = 指令数 * CPI * Clock Cycle Time
3. 指令重排序优化
在不改变程序结果的前提下,这些指令的各个阶段可以通过 重排序 和 组合 来实现 指令级并行 ,这一技术在 80's 中叶到 90's 中叶占据了计算架构的重要地位。

指令重排的前提是,重排指令不能影响结果
二、诡异的结果
public class ConcurrencyTest { int num = 0; boolean ready = false; @Actor public void actor1(I_Result r) { if(ready) { r.r1 = num + num; } else { r.r1 = 1; } } @Actor public void actor2(I_Result r) { num = 2; ready = true; } }

三、解决方法
volatile 修饰的变量,可以禁用指令重排
四、原理之 volatile
volatile 的底层实现原理是内存屏障,Memory Barrier(Memory Fence)
(1)对 volatile 变量的写指令后会加入写屏障
(2)对 volatile 变量的读指令前会加入读屏障
1. 如何保证可见性
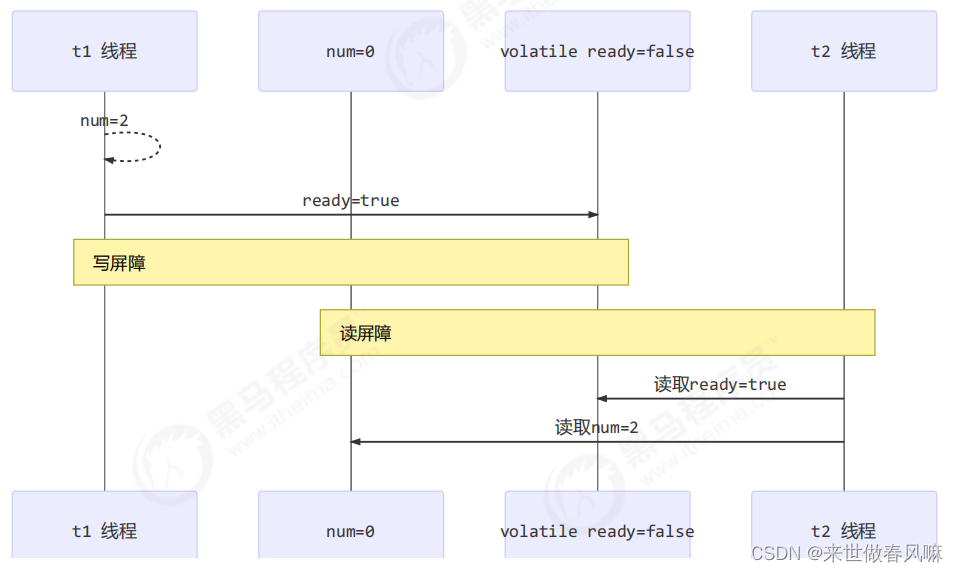
写屏障(sfence)保证在该屏障之前的,对共享变量的改动,都同步到主存当中
而读屏障(lfence)保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据

2. 如何保证有序性
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
还是那句话,不能解决指令交错:(1)写屏障仅仅是保证之后的读能够读到最新的结果,但不能保证读跑到它前面去(2)而有序性的保证也只是保证了本线程内相关代码不被重排序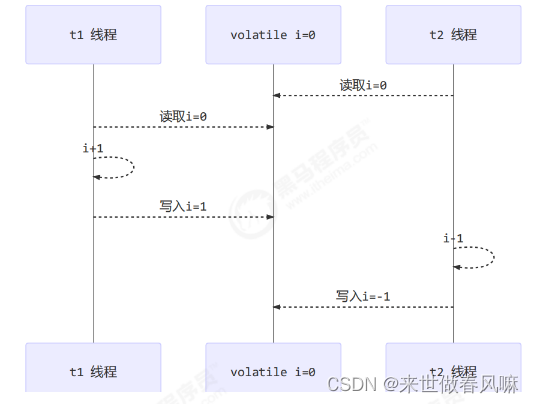
3. 以著名的 double-checked locking 单例模式为例
public final class Singleton { private Singleton() { } private static Singleton INSTANCE = null; public static Singleton getInstance() { if(INSTANCE == null) { // t2 // 首次访问会同步,而之后的使用没有 synchronized synchronized(Singleton.class) { if (INSTANCE == null) { // t1 INSTANCE = new Singleton(); } } } return INSTANCE; } }很关键的一点:第一个 if 使用了 INSTANCE 变量,是在同步块之外
INSTANCE 没完全受到 synchronized 的保护,所以 INSTANCE 可能会指令重排
4. double-checked locking 解决
对 INSTANCE 使用 volatile 修饰即可,可以禁用指令重排,但要注意在 JDK 5 以上的版本的 volatile 才会真正有效
读写 volatile 变量时会加入内存屏障( Memory Barrier ( Memory Fence)),保证下面两点:(1)可见性1️⃣ 写屏障( sfence )保证在该屏障之前的 t1 对共享变量的改动,都同步到主存当中2️⃣而读屏障( lfence )保证在该屏障之后 t2 对共享变量的读取,加载的是主存中最新数据(2)有序性1️⃣写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后2️⃣读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前(3)更底层是读写变量时使用 lock 指令来多核 CPU 之间的可见性与有序性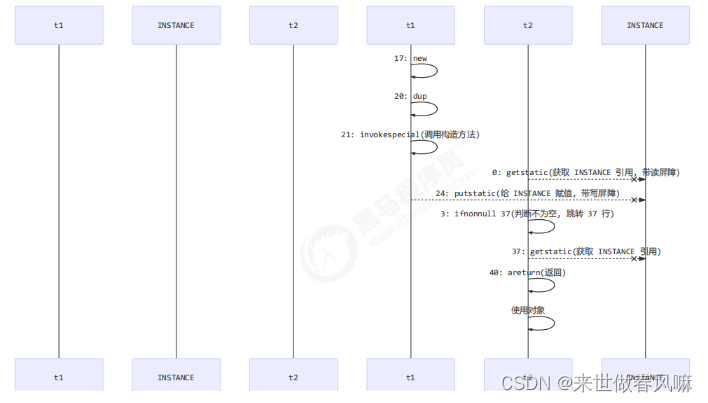
五、happens-before
happens-before 规定了对共享变量的写操作对其他线程的读操作可见,它是可见性与有序性的一套规则总结,抛开以下 happens-before 规则,JMM 并不能保证一个线程对共享变量的写,对于其他线程对该共享变量的读可见。
(1)线程解锁 m 之前对变量的写,对于接下来对 m 加锁的其它线程对该变量的读可见
public class Ces { static int x; static Object m = new Object(); public static void main(String[] args) { new Thread(() -> { synchronized (m) { x = 10; } }, "t1").start(); new Thread(() -> { synchronized (m) { System.out.println(x); } }, "t2").start(); } }
(2)线程对 volatile 变量的写,对接下来其它线程对该变量的读可见
public class Ces { volatile static int x; public static void main(String[] args) { new Thread(()->{ x = 10; },"t1").start(); new Thread(()->{ System.out.println(x); },"t2").start(); } }
(3)线程 start 前对变量的写,对该线程开始后对该变量的读可见
public class Ces { static int x; public static void main(String[] args) { x = 10; new Thread(()->{ System.out.println(x); },"t2").start(); } }
(4)线程结束前对变量的写,对其它线程得知它结束后的读可见(比如其它线程调用 t1.isAlive() 或 t1.join()等待它结束)
public class Ces { static int x; public static void main(String[] args) throws InterruptedException { Thread t1 = new Thread(()->{ x = 10; },"t1"); t1.start(); t1.join(); System.out.println(x); } }
(5)线程 t1 打断 t2(interrupt)前对变量的写,对于其他线程得知 t2 被打断后对变量的读可见(通过 t2.interrupted 或 t2.isInterrupted)
public class Ces { static int x; public static void main(String[] args) { Thread t2 = new Thread(()->{ while(true) { if(Thread.currentThread().isInterrupted()) { System.out.println(x); break; } } },"t2"); t2.start(); new Thread(()->{ try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } x = 10; t2.interrupt(); },"t1").start(); while(!t2.isInterrupted()) { Thread.yield(); } System.out.println(x); } }
(6)对变量默认值(0,false,null)的写,对其它线程对该变量的读可见
(7)具有传递性,如果 x hb-> y 并且 y hb-> z 那么有 x hb-> z ,配合 volatile 的防指令重排,有下面的例子
public class Ces { volatile static int x; static int y; public static void main(String[] args) { new Thread(()->{ y = 10; x = 20; },"t1").start(); new Thread(()->{ // x=20 对 t2 可见, 同时 y=10 也对 t2 可见 System.out.println(x); },"t2").start(); } }
![[附源码]Python计算机毕业设计Django企业人事管理系统](https://img-blog.csdnimg.cn/59c4e7462c3a49a481ee513575d87500.png)








![[蓝牙 Mesh Zephyr]-[005]-Key](https://img-blog.csdnimg.cn/c2a66cf55e2c4e429af989e1c36f620b.png)