系列文章目录
文章目录
- 系列文章目录
- Page Fault
- COPY ON WRITE
Page Fault
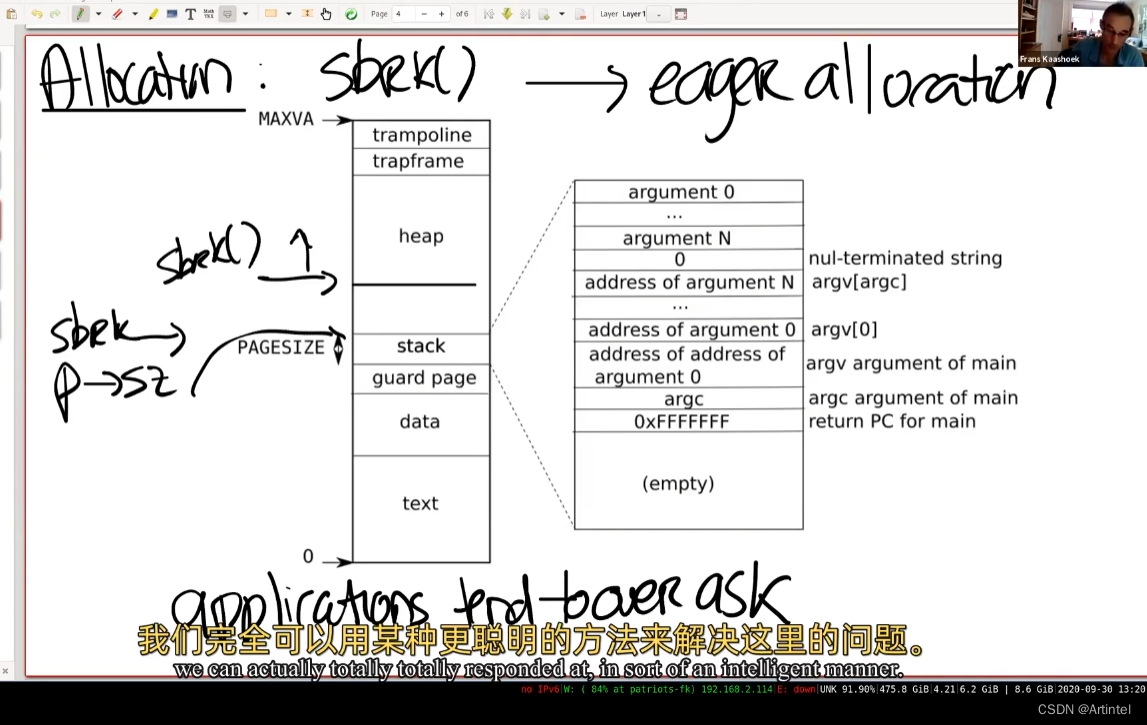
eager allocation
通常,因为应用程序无法非常准确地估计自己要增加的内存有多少,所以通常申请的内存会比真实要使用的内存要多。
在XV6中,sbrk的实现默认是eager allocation。这表示了,一旦调用了sbrk,内核会立即分配应用程序所需要的物理内存。但是实际上,对于应用程序来说很难预测自己需要多少内存,所以通常来说,应用程序倾向于申请多于自己所需要的内存。这意味着,进程的内存消耗会增加许多,但是有部分内存永远也不会被应用程序所使用到。
lazy allocation
原则上来说,这不是一个大问题。但是使用虚拟内存和page fault handler,我们完全可以用某种更聪明的方法来解决这里的问题,这里就是利用lazy allocation。核心思想非常简单,sbrk系统调基本上不做任何事情,唯一需要做的事情就是提升p->sz,将p->sz增加 n ,其中 n 是需要新分配的内存page数量。但是内核在这个时间点并不会分配任何物理内存。之后在某个时间点,应用程序使用到了新申请的那部分内存,这时会触发page fault,因为我们还没有将新的内存映射到page table。所以,如果我们解析一个大于旧的 p->sz,但是又小于新的p->sz(注,也就是旧的 p->sz + n)的虚拟地址,我们希望内核能够分配一个内存page,并且重新执行指令。
所以,当我们看到了一个page fault,相应的虚拟地址小于当前p->sz,同时大于stack,那么我们就知道这是一个来自于heap的地址,但是内核还没有分配任何物理内存。所以对于这个page fault的响应也理所当然的直接明了:在page fault handler中,通过kalloc函数分配一个内存page;初始化这个page内容为0;将这个内存page映射到user page table中;最后重新执行指令。比方说,如果是load指令,或者store指令要访问属于当前进程但是还未被分配的内存,在我们映射完新申请的物理内存page之后,重新执行指令应该就能通过了。
student: 在eager allocation的场景,一个进程可能消耗了太多的内存进而耗尽了物理内存资源。如果我们不使用eager allocation,而是使用lazy allocation,应用程序怎么才能知道当前已经没有物理内存可用了?
Frans: 这是个非常好的问题。从应用程序的角度来看,会有一个错觉:存在无限多可用的物理内存。但是在某个时间点,应用程序可能会用光了物理内存,之后如果应用程序再访问一个未被分配的page,但这时又没有物理内存,这时内核可以有两个选择,我稍后会介绍更复杂的那个。你们在lazy lab中要做的是,返回一个错误并杀掉进程。因为现在已经OOM(Out Of Memory)了,内核也无能为力,所以在这个时间点可以杀掉进程。
在这节课稍后的部分会介绍,可以有更加聪明的解决方案。
student: 如何判断一个地址是新分配的内存还是一个无效的地址?
Frans: 在地址空间中,我们有
stack,data和text。通常来说我们将p->sz设置成一个更大的数,新分配的内存位于旧的p->sz和新的p->sz之间,但是这部分内存还没有实际在物理内存上进行分配。如果使用的地址低于p->sz,那么这是一个用户空间的有效地址。如果大于p->sz,对应的就是一个程序错误,这意味着用户应用程序在尝试解析一个自己不拥有的内存地址。希望这回答了你的问题。
student: 为什么我们需要杀掉进程?操作系统不能只是返回一个错误说现在已经OOM了,尝试做一些别的操作吧。
Frans教授:让我们稍后再回答这个问题。在XV6的page fault中,我们默认会直接杀掉进程,但是这里的处理可以更加聪明。实际的操作系统的处理都会更加聪明,尽管如此,如果最终还是找不到可用内存,实际的操作系统还是可能会杀掉进程。
COPY ON WRITE
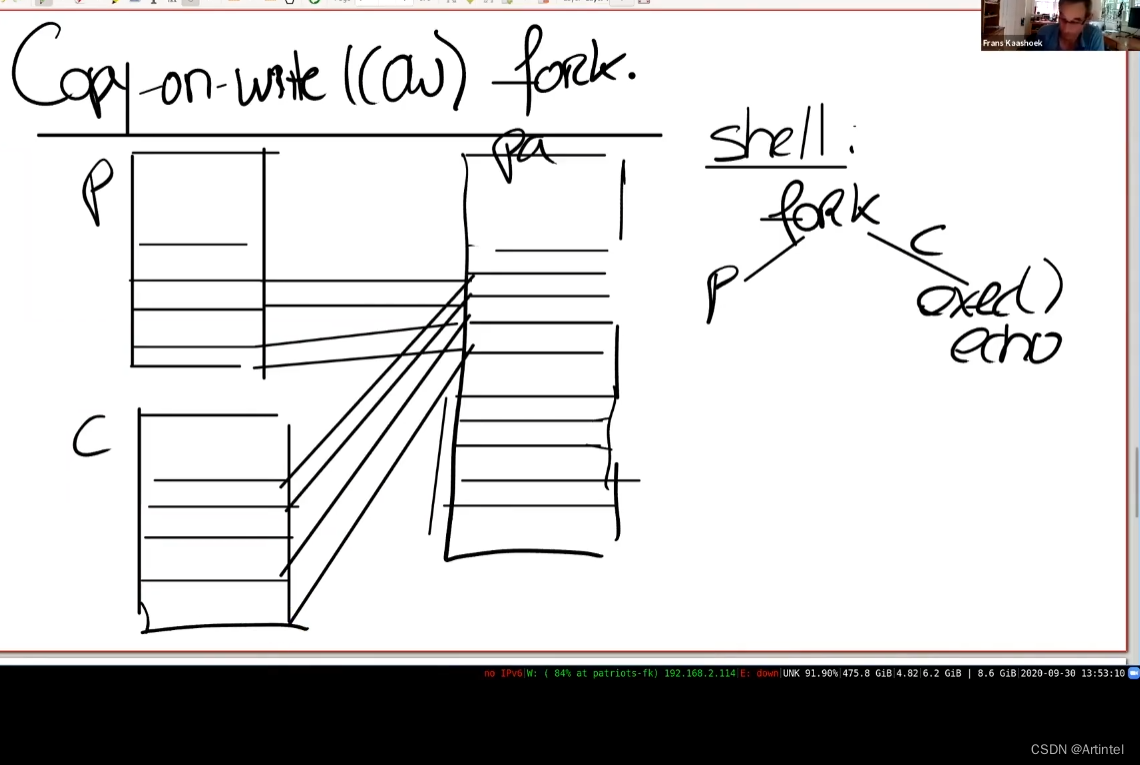
当我们创建子进程时,与其创建,分配并拷贝内容到新的物理内存,其实我们可以直接共享父进程的物理内存page。所以这里,我们可以设置子进程的PTE指向父进程对应的物理内存page。
当然,再次要提及的是,我们这里需要非常小心。因为一旦子进程想要修改这些内存的内容,相应的更新应该对父进程不可见,因为我们希望在父进程和子进程之间有强隔离性,所以这里我们需要更加小心一些。为了确保进程间的隔离性,我们可以将这里的父进程和子进程的PTE的标志位都设置成只读的。
在某个时间点,当我们需要更改内存的内容时,我们会得到page fault。因为父进程和子进程都会继续运行,而父进程或者子进程都可能会执行store指令来更新一些全局变量,这时就会触发page fault,因为现在在向一个只读的PTE写数据。
在得到page fault之后,我们需要拷贝相应的物理page。假设现在是子进程在执行store指令,那么我们会分配一个新的物理内存page,然后将page fault相关的物理内存page拷贝到新分配的物理内存page中,并将新分配的物理内存page映射到子进程。这时,新分配的物理内存page只对子进程的地址空间可见,所以我们可以将相应的PTE设置成可读写,并且我们可以重新执行store指令。实际上,对于触发刚刚page fault的物理page,因为现在只对父进程可见,相应的PTE对于父进程也变成可读写的了。
所以现在,我们拷贝了一个page,将新的page映射到相应的用户地址空间,并重新执行用户指令。重新执行用户指令是指调用userret函数(注,详见6.8),也即是lec06中介绍的返回到用户空间的方法。
student: 我们如何发现父进程写了这部分内存地址?是与子进程相同的方法吗?
Frans教授:是的,因为子进程的地址空间来自于父进程的地址空间的拷贝。如果我们使用了特定的虚拟地址,因为地址空间是相同的,不论是父进程还是子进程,都会有相同的处理方式。
student: 对于一些没有父进程的进程,比如系统启动的第一个进程,它会对于自己的PTE设置成只读的吗?还是设置成可读写的,然后在fork的时候再修改成只读的?
Frans教授:这取决于你。实际上在lazy lab之后,会有一个copy-on-write lab。在这个lab中,你自己可以选择实现方式。当然最简单的方式就是将PTE设置成只读的,当你要写这些page时,你会得到一个page fault,之后你可以再按照上面的流程进行处理。
因为我们经常会拷贝用户进程对应的page,内存硬件有没有实现特定的指令来完成拷贝,因为通常来说内存会有一些读写指令,但是因为我们现在有了从page a拷贝到page b的需求,会有相应的拷贝指令吗?
Frans教授:x86有硬件指令可以用来拷贝一段内存。但是RISC-V并没有这样的指令。当然在一个高性能的实现中,所有这些读写操作都会流水线化,并且按照内存的带宽速度来运行。
在我们这个例子中,我们只需要拷贝1个page,对于一个未修改的XV6系统,我们需要拷贝4个page。所以这里的方法明显更好,因为内存消耗的更少,并且性能会更高,fork会执行的更快。
学生提问:当发生page fault时,我们其实是在向一个只读的地址执行写操作。内核如何能分辨现在是一个copy-on-write fork的场景,而不是应用程序在向一个正常的只读地址写数据。是不是说默认情况下,用户程序的PTE都是可读写的,除非在copy-on-write fork的场景下才可能出现只读的PTE?
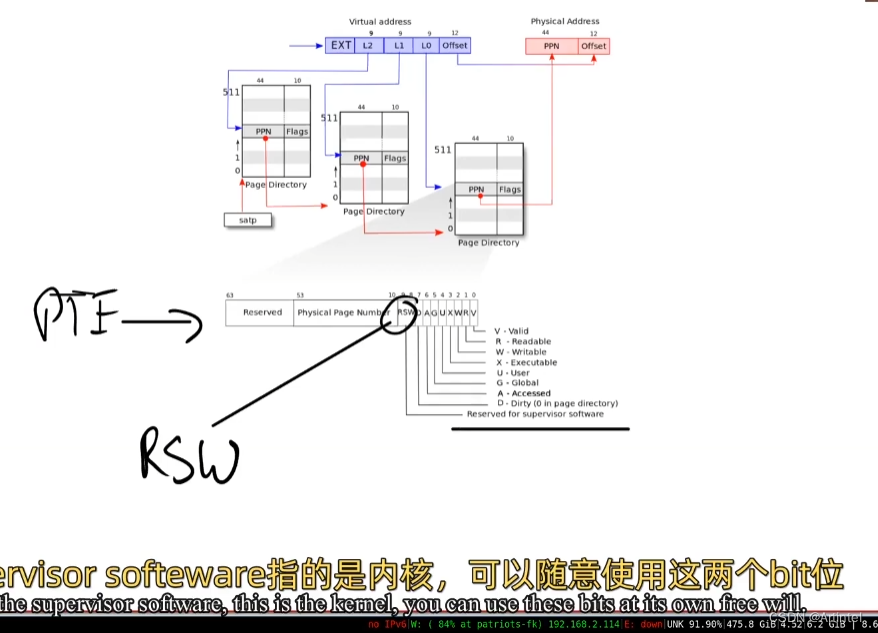
Frans教授:内核必须要能够识别这是一个copy-on-write场景。几乎所有的page table硬件都支持了这一点。我们之前并没有提到相关的内容,下图是一个常见的多级page table。对于PTE的标志位,我之前介绍过第0bit到第7bit,但是没有介绍最后两位RSW。这两位保留给supervisor software使用,supervisor softeware指的就是内核。内核可以随意使用这两个bit位。所以可以做的一件事情就是,将bit8标识为当前是一个copy-on-write page。
当内核在管理这些page table时,对于copy-on-write相关的page,内核可以设置相应的bit位,这样当发生page fault时,我们可以发现如果copy-on-write bit位设置了,我们就可以执行相应的操作了。否则的话,比如说lazy allocation,我们就做一些其他的处理操作。
在copy-on-write lab中,你们会使用RSW在PTE中设置一个copy-on-write标志位。

![[蓝牙 Mesh Zephyr]-[005]-Key](https://img-blog.csdnimg.cn/c2a66cf55e2c4e429af989e1c36f620b.png)
![[附源码]JAVA毕业设计客户台账管理(系统+LW)](https://img-blog.csdnimg.cn/f5b7e5c20cfd462496b7a8e4da85e210.png)