比赛链接:https://www.kaggle.com/competitions/feedback-prize-english-language-learning
在Kaggle Feedback Prize 3比赛总结:如何高效使用hidden states输出(2)中介绍了针对last layer hidden state的各种pooling的方法。
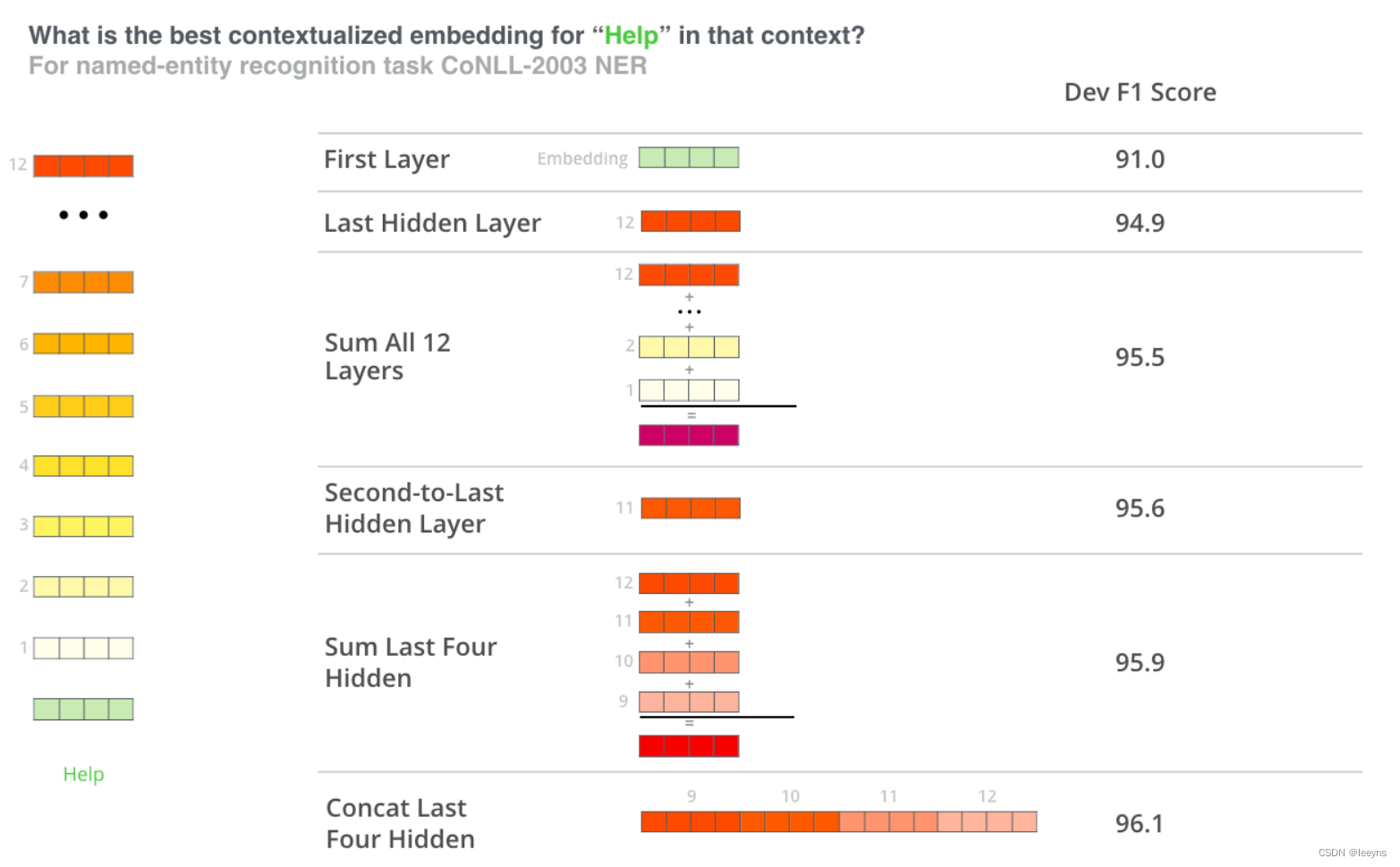
在利用Transformer类的预训练模型进行下游任务的微调过程中,最后一层的输出不一定是输入文本的最佳表示。如下图所示,Transformer encoder的每一层的hidden state都是对输入文本的上下文表征。对于预训练的语言模型,包括Transformer,输入文本的最有效的上下文表征往往发生在中间层,而顶层则专门用于专一任务的建模。因此,仅仅利用最后一层输出可能会限制预训练的表示的力量。本文将介绍几种常见的layer pooling的办法。

Concatenate Pooling
Concatenate pooling是将不同层的输出堆叠到一起。在这里我将介绍concatenate最后4层的输出。如下图的最后一行表示。例,如果模型的hidden state的大小为768,那么每一层的输出大小为[batch size, sequence length, 768]。如果将最后四层的输出concatenate到一起,那么输出为[batch size, sequence length, 768 * 4].
代码实现如下:
with torch.no_grad():
outputs = model(features['input_ids'], features['attention_mask'])
all_hidden_states = torch.stack(outputs[2])
concatenate_pooling = torch.cat(
(all_hidden_states[-1], all_hidden_states[-2], all_hidden_states[-3], all_hidden_states[-4]),-1
)
concatenate_pooling = concatenate_pooling[:, 0]
logits = nn.Linear(config.hidden_size*4, 1)(concatenate_pooling) # regression head
print(f'Hidden States Output Shape: {all_hidden_states.detach().numpy().shape}')
print(f'Concatenate Pooling Output Shape: {concatenate_pooling.detach().numpy().shape}')
print(f'Logits Shape: {logits.detach().numpy().shape}')
输出为:
Hidden States Output Shape: (13, 16, 256, 768)
Concatenate Pooling Output Shape: (16, 3072)
Logits Shape: (16, 1)
注:这里的例子是使用最后四层的 [CLS] token。
Weighted Layer Pooling
这个方法是较为常用的方法。这个方法是利用最后几层的hidden state,同时定义一个可学习的参数来决定每一层的hidden state占得比重。代码实现如下:
class WeightedLayerPooling(nn.Module):
def __init__(self, last_layers = CFG.weighted_layer_pooling_num, layer_weights = None):
super(WeightedLayerPooling, self).__init__()
self.last_layers = last_layers
self.layer_weights = layer_weights if layer_weights is not None \
else nn.Parameter(torch.tensor([ 1/ last_layers] * last_layers, dtype = torch.float))
def forward(self, features):
all_layer_embedding = torch.stack(features)
all_layer_embedding = all_layer_embedding[-self.last_layers:, :, :, :]
weight_factor = self.layer_weights.unsqueeze(-1).unsqueeze(-1).unsqueeze(-1).expand(all_layer_embedding.size())
print(f'weight_factor: {self.layer_weights}')
weighted_average = (weight_factor*all_layer_embedding).sum(dim=0) / self.layer_weights.sum()
return weighted_average
with torch.no_grad():
outputs = model(features['input_ids'], features['attention_mask'])
hidden_states = outputs.hidden_states
Last_layer_num = 4
WeightedLayerPooling = WeightedLayerPooling(last_layers=Last_layer_num, layer_weights=None)
weighted_layers_pooling_features = WeightedLayerPooling(hidden_states)
print(f'Hidden States Output Shape: {hidden_states.detach().numpy().shape}')
print(f'Weighted Pooling Output Shape: {weighted_layers_pooling_features.detach().numpy().shape}')
输出为:
Hidden States Output Shape: (13, 16, 256, 768)
Weighted Pooling Output Shape: (16, 256, 768)
Attention Pooling
Attention机制能够学习每一层的 [CLS] token的贡献程度。因此利用attention机制能够更好的利用不同层的[CLS]特征。这里介绍一种 dot-product attention 机制。这个过程可以被表示为:
o
=
W
h
T
S
o
f
t
m
a
x
(
q
∗
h
C
L
S
T
)
h
C
L
S
o=W^T_hSoftmax(q*h^T_{CLS})h_{CLS}
o=WhTSoftmax(q∗hCLST)hCLS
其中
W
h
T
W^T_h
WhT 和
q
q
q 是可学习参数。
代码实现如下:
with torch.no_grad():
outputs = model(features['input_ids'], features['attention_mask'])
all_hidden_states = torch.stack(outputs[2])
class AttentionPooling(nn.Module):
def __init__(self, num_layers, hidden_size, hiddendim_fc):
super(AttentionPooling, self).__init__()
self.num_hidden_layers = num_layers
self.hidden_size = hidden_size
self.hiddendim_fc = hiddendim_fc
self.dropout = nn.Dropout(0.1)
q_t = np.random.normal(loc=0.0, scale=0.1, size=(1, self.hidden_size))
self.q = nn.Parameter(torch.from_numpy(q_t)).float()
w_ht = np.random.normal(loc=0.0, scale=0.1, size=(self.hidden_size, self.hiddendim_fc))
self.w_h = nn.Parameter(torch.from_numpy(w_ht)).float()
def forward(self, all_hidden_states):
hidden_states = torch.stack([all_hidden_states[layer_i][:, 0].squeeze()
for layer_i in range(1, self.num_hidden_layers+1)], dim=-1)
hidden_states = hidden_states.view(-1, self.num_hidden_layers, self.hidden_size)
out = self.attention(hidden_states)
out = self.dropout(out)
return out
def attention(self, h):
v = torch.matmul(self.q, h.transpose(-2, -1)).squeeze(1)
v = F.softmax(v, -1)
v_temp = torch.matmul(v.unsqueeze(1), h).transpose(-2, -1)
v = torch.matmul(self.w_h.transpose(1, 0), v_temp).squeeze(2)
return v
hiddendim_fc = 128
pooler = AttentionPooling(config.num_hidden_layers, config.hidden_size, hiddendim_fc)
attention_pooling_embeddings = pooler(all_hidden_states)
logits = nn.Linear(hiddendim_fc, 1)(attention_pooling_embeddings) # regression head
print(f'Hidden States Output Shape: {all_hidden_states.detach().numpy().shape}')
print(f'Attention Pooling Output Shape: {attention_pooling_embeddings.detach().numpy().shape}')
输出为:
Hidden States Output Shape: (13, 16, 256, 768)
Attention Pooling Output Shape: (16, 128)
总结
不同的layer pooling method 对于不同的任务有不一样的性能表现,因此对于每一个任务还是需要进行探索的。但在这一次比赛中,最后4层的WeightLayerPooling,是相对而言改进模型表现最有效的方法。同时,值得注意的是,也可以将不同的pooling方法得到的特征最后再做一次concatenate 这样会让模型学到各种不同pooling方法的feature,也有可能在一定程度上改善模型的性能。






![[蓝牙 Mesh Zephyr]-[005]-Key](https://img-blog.csdnimg.cn/c2a66cf55e2c4e429af989e1c36f620b.png)
![[附源码]JAVA毕业设计客户台账管理(系统+LW)](https://img-blog.csdnimg.cn/f5b7e5c20cfd462496b7a8e4da85e210.png)