目录
- 1.SpringBuffer和SpringBuilder的区别是什么?
- 2.常用的集合类有哪些?HashMap的底层数据结构?推荐一下线程安全的Map?
- 3.TCP和UDP的差异是什么?
- 4.MySQL的左连接和右连接的区别?
- 5.MySQL慢查询如何排查?
- 6.深拷贝和浅拷贝的概念和区别?如何实现深拷贝?
- 7.Spring循环依赖问题是什么?如何解决?
- 8.Redis持久化的方式?
- 9.SpringCloud共有几大组件?
1.SpringBuffer和SpringBuilder的区别是什么?
tringBuffer是线程安全的,因为它每个操作方法都加了synchronized同步关键字。
StringBuilder不是线程安全的,所以在多线程环境下对字符串进行操作,应该使用StringBuffer,否则使用StringBuilder
2.常用的集合类有哪些?HashMap的底层数据结构?推荐一下线程安全的Map?
常用的集合类有哪些?
List:Vector,LinkedList,ArrayList
Set:HashSet,TreeSet
Map:HashMap,TreeMap,HashTable
HashMap的底层数据结构?
HashMap1.7:数组+链表
HashMap1.8:数组+链表/红黑树
推荐一下线程安全的Map?
concurrentHashMap
JDK1.7ConcurrentHashMap底层实现原理:
数据结构:Segment(大数组) + HashEntry(小数组) + 链表,每个 Segment 对应一把锁,如果多个线程访问不同的 Segment,则不会冲突
JDK1.8ConcurrentHashMap底层实现原理:
数据结构:Node 数组 + 链表或红黑树,数组的每个头节点作为锁,如果多个线程访问的头节点不同,则不会冲突。首次生成头节点时如果发生竞争,利用 cas 而非 syncronized,进一步提升性能
ConcurrentHashMap在性能方面做的优化
- 在JDK1.8中,ConcurrentHashMap锁的粒度是数组中的某一个节点,而在JDK1.7,锁定的是Segment,锁的范围要更大,因此性能上会更低。
- 引入红黑树,降低了数据查询的时间复杂度,红黑树的时间复杂度是O(logn)。
- 当数组长度不够时,ConcurrentHashMap需要对数组进行扩容,在扩容的实现上,ConcurrentHashMap引入了多线程并发扩容的机制,简单来说就是多个线程对原始数组进行分片后,每个线程负责一个分片的数据迁移,从而提升了扩容过程中数据迁移的效率。
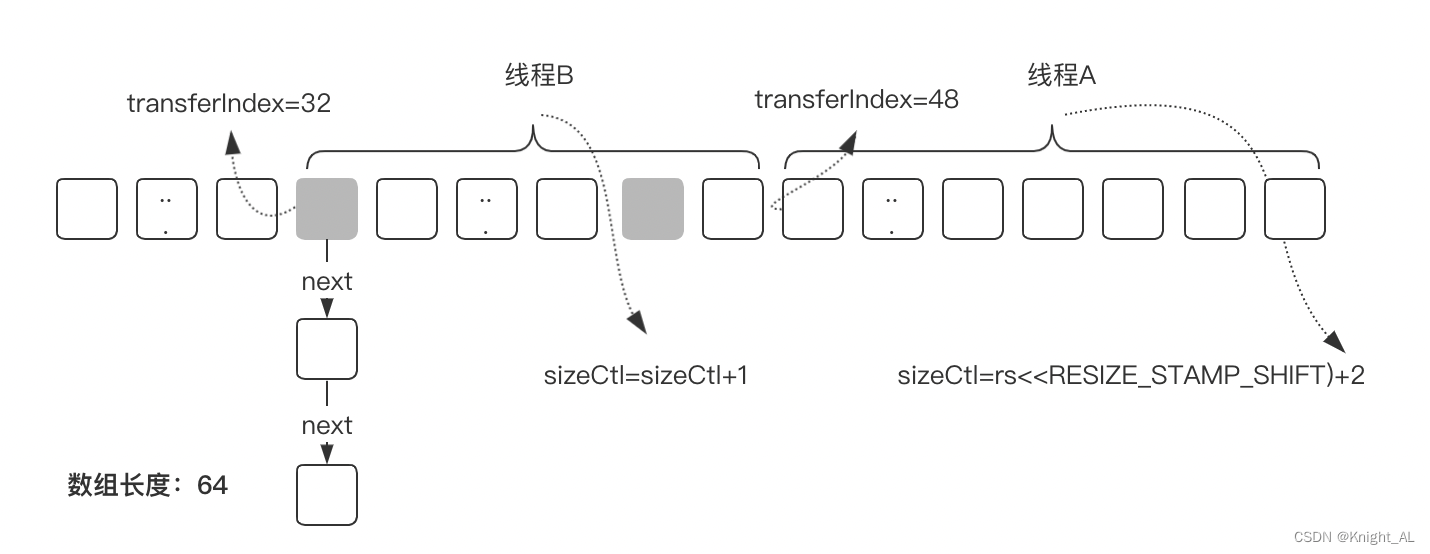
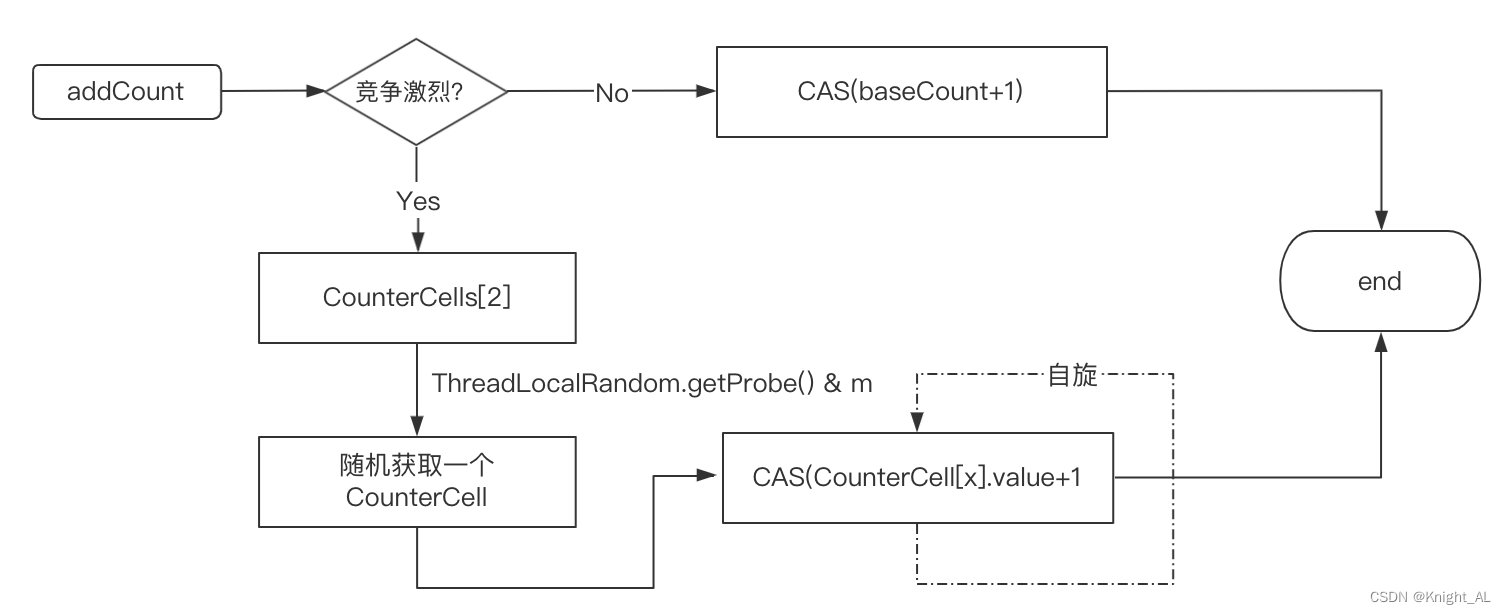
- ConcurrentHashMap中有一个size()方法来获取总的元素个数,而在多线程并发场景中,在保证原子性的前提下来实现元素个数的累加,性能是非常低的。ConcurrentHashMap在这个方面的优化主要体现在两个点:
- 当线程竞争不激烈时,直接采用CAS来实现元素个数的原子递增。
如果线程竞争激烈,使用一个数组来维护元素个数,如果要增加总的元素个数,则直接从数组中随机选择一个,再通过CAS实现原子递增。它的核心思想是引入了数组来实现对并发更新的负载。
3.TCP和UDP的差异是什么?
连接
TCP 是面向连接的传输层协议,传输数据前先要建立连接。
UDP 是不需要连接,即刻传输数据。
服务对象
TCP 是一对一的两点服务,即一条连接只有两个端点。
UDP 支持一对一、一对多、多对多的交互通信
可靠性
TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按需到达。
UDP 是尽最大努力交付,不保证可靠交付数据。
拥塞控制、流量控制
TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。
UDP 则没有,即使网络非常拥堵了,也不会影响 UDP 的发送速率。
首部开销
TCP 首部长度较长,会有一定的开销,首部在没有使用「选项」字段时是 20 个字节,如果使用了「选项」字段则会变长的。
UDP 首部只有 8 个字节,并且是固定不变的,开销较小。
传输方式
TCP 是流式传输,没有边界,但保证顺序和可靠。
UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序。
分片不同
TCP 的数据大小如果大于 MSS 大小,则会在传输层进行分片,目标主机收到后,也同样在传输层组装 TCP 数据包,如果中途丢失了一个分片,只需要传输丢失的这个分片。UDP 的数据大小如果大于 MTU 大小,则会在 IP 层进行分片,目标主机收到后,在 IP 层组装完数据,接着再传给传输层。
TCP 和 UDP 应用场景:
- 由于 TCP 是面向连接,能保证数据的可靠性交付,因此经常用于:
FTP 文件传输;
HTTP / HTTPS; - 由于 UDP 面向无连接,它可以随时发送数据,再加上UDP本身的处理既简单又高效,因此经常用于:
包总量较少的通信,如 DNS 、SNMP 等;视频、音频等多媒体通信;广播通信;
4.MySQL的左连接和右连接的区别?
左连接:返回包括左表中的所有记录和右表中连接字段相等的记录。
右连接:返回包括右表中的所有记录和左表中连接字段相等的记录。
5.MySQL慢查询如何排查?
如果不熟悉可以看这篇
Mysql查询截取分析_慢查询日志
开启慢查询
set global slow_query_log=1
设置慢查询的时间
SET GLOBAL long_query_time=0.1;
假如运行时间正好等于long_query_time的情况,并不会被记录下来。也就是说,在mysql源码里是判断大于long_query_time,而非大于等于。
使用mysqldumpslow去分析,查找sql,然后在使用explain进行分析

6.深拷贝和浅拷贝的概念和区别?如何实现深拷贝?
如果不熟悉可以看这篇
Java深拷贝和浅拷贝区别
深拷贝和浅拷贝都是对象拷贝
Object.clone()方法属于浅拷贝。如果想使用深拷贝,必须在类里面重写clone()方法。
- 拷贝浅是创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值,如果属性是引用类型,拷贝的就是内存地址,所以如果其中一个对象改变了这个地址,就会影响到另一个对象。
- 深拷贝是将一个对象从内存中完整的拷贝一份出来,从堆内存中开辟一个新的区域存放新对象,且修改新对象不会影响原对象。
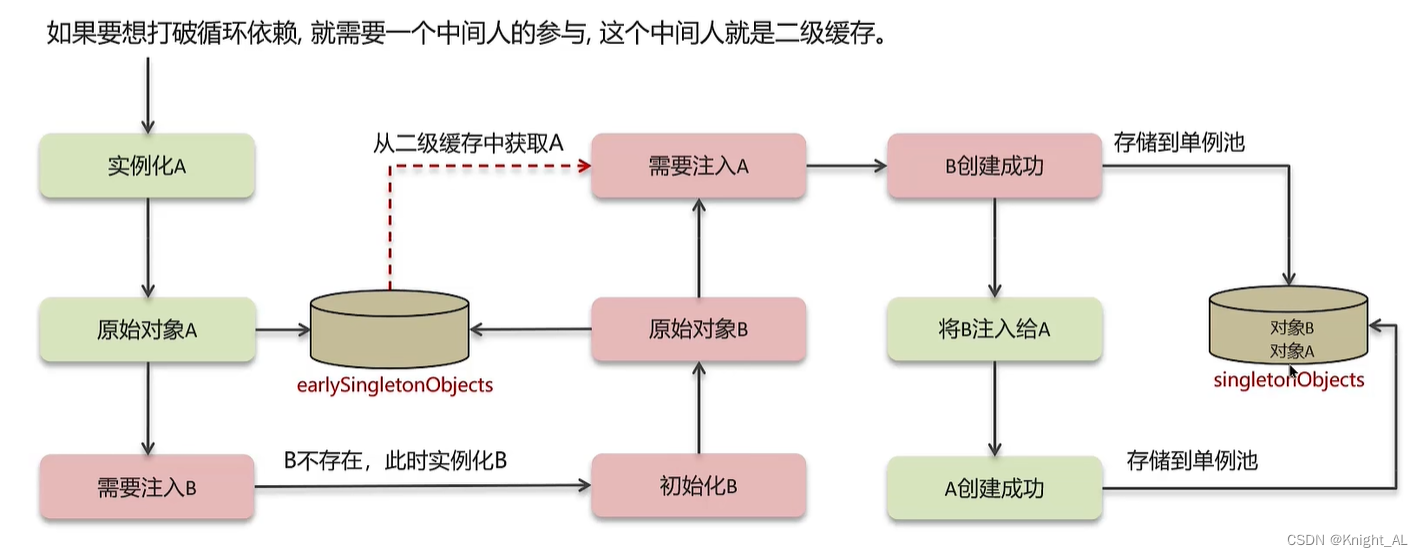
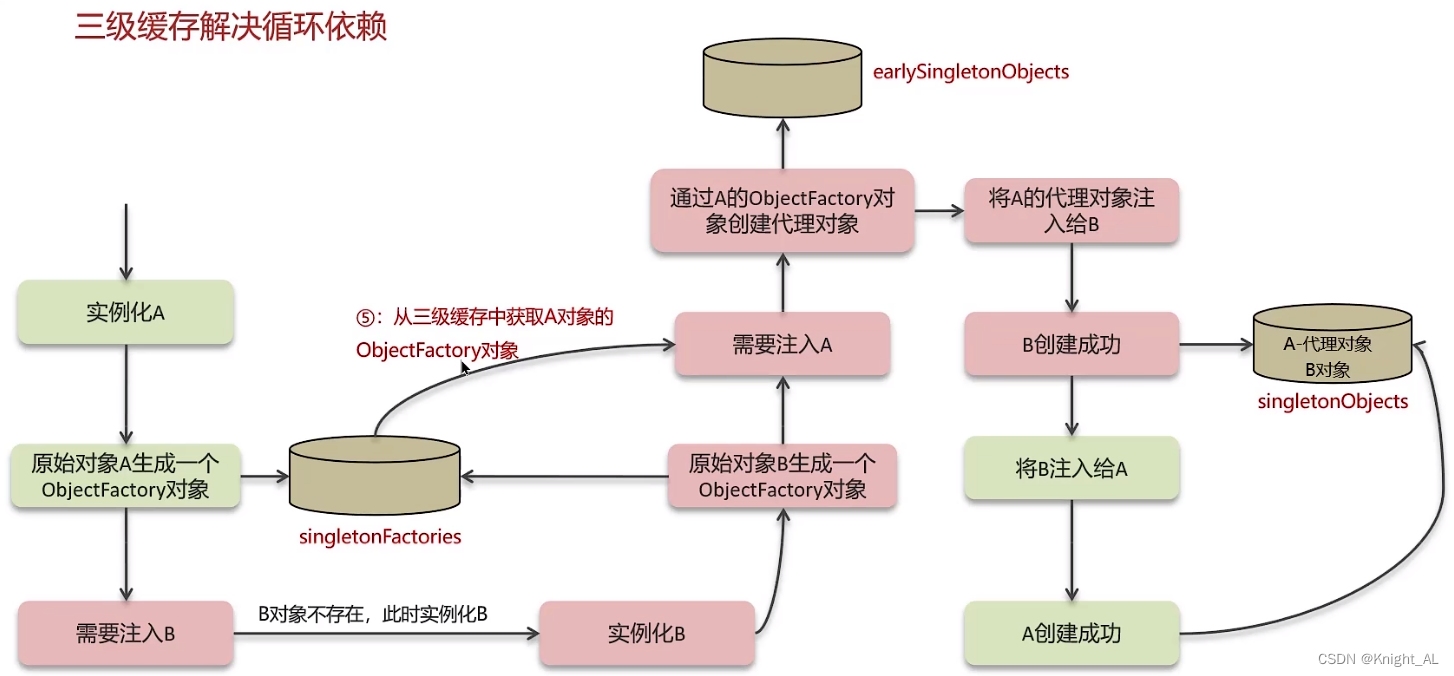
7.Spring循环依赖问题是什么?如何解决?
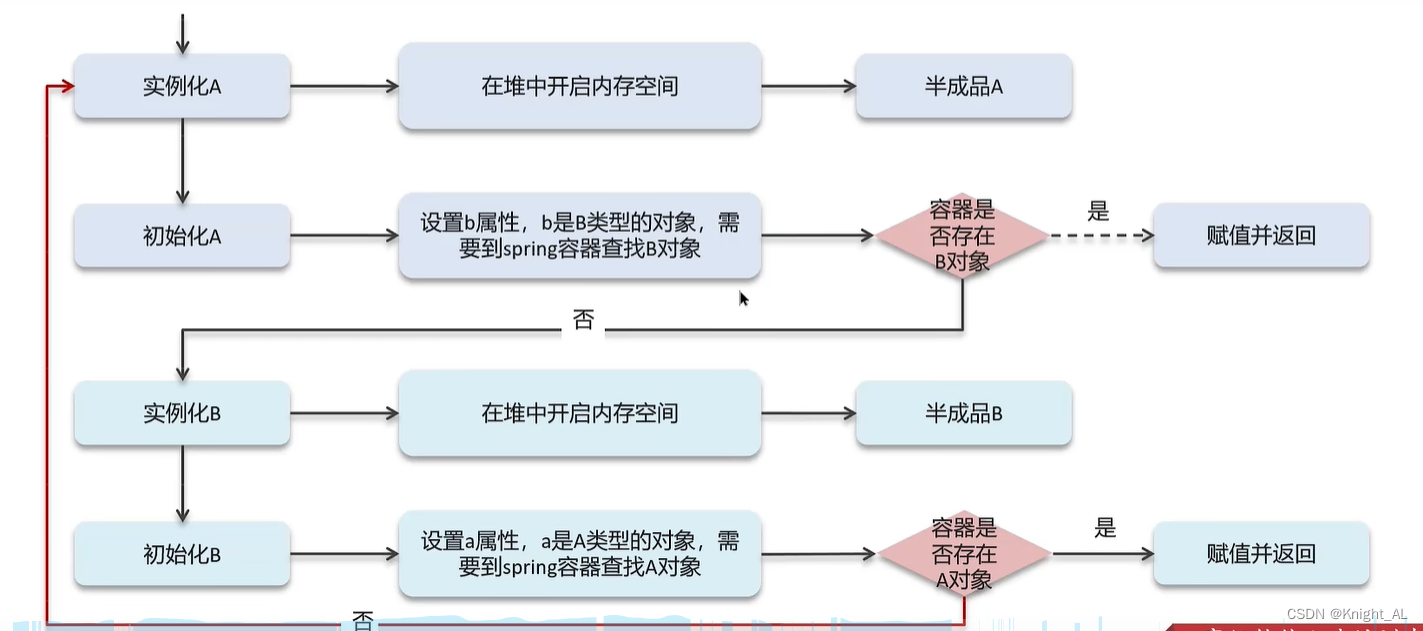
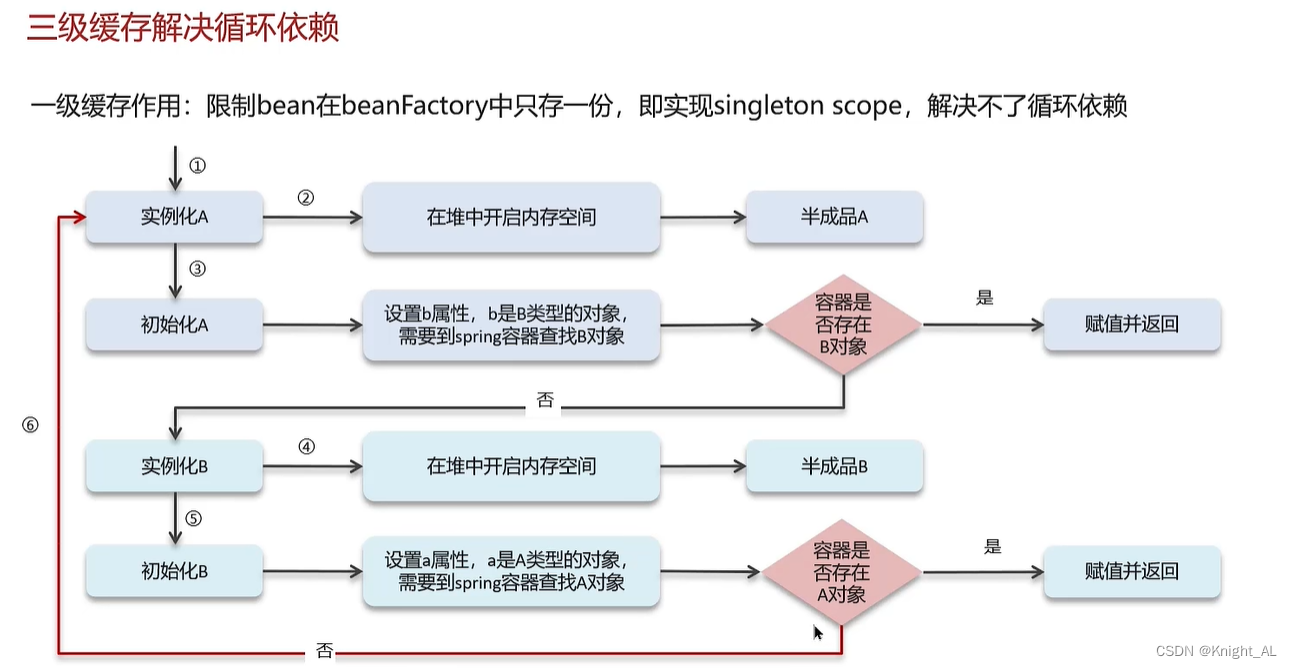
循环依赖:循环依赖其实就是循环引用,也就是两个或两个以上的bean互相持有对方,最终形成闭环。
比如A依赖于B,B依赖于A循环依赖在spring中是允许存在,spring框架依据三级缓存已经解决了大部分的循环依赖
一级缓存:单例池,缓存已经经历了完整的生命周期,已经初始化完成的bean对象
二级缓存:缓存早期的bean对象(生命周期还没走完)
三级缓存:缓存的是ObjectFactory,表示对象工厂,用来创建某个对象的

8.Redis持久化的方式?
Redis的持久化机制分别是RDB和AOF
RDB
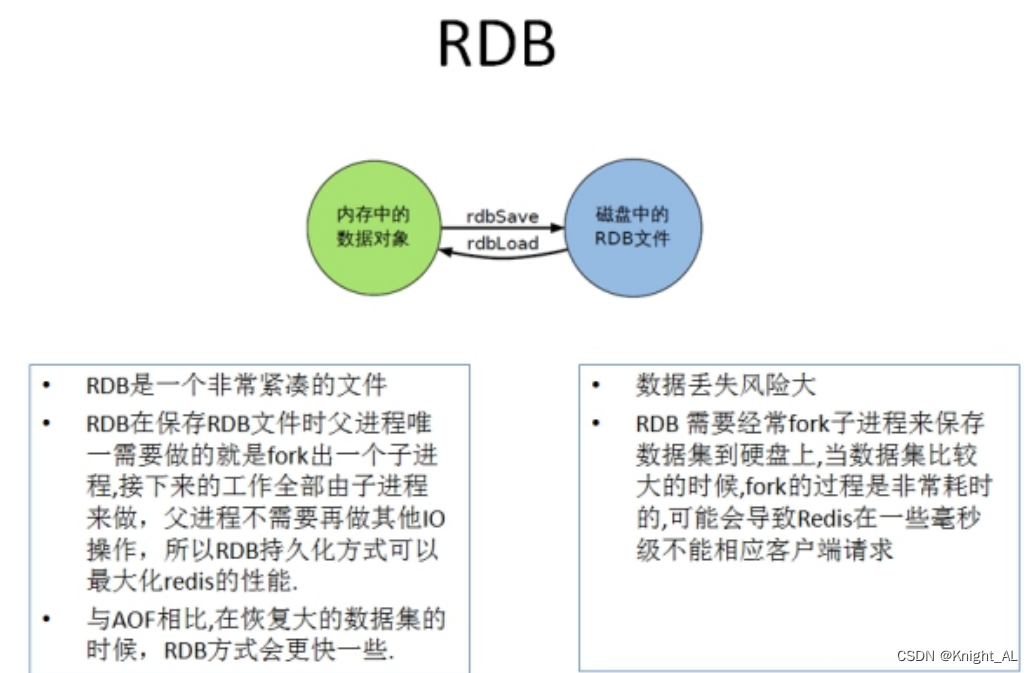
是什么
在指定的时间间隔内将内存中的数据集快照写入磁盘, 也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里
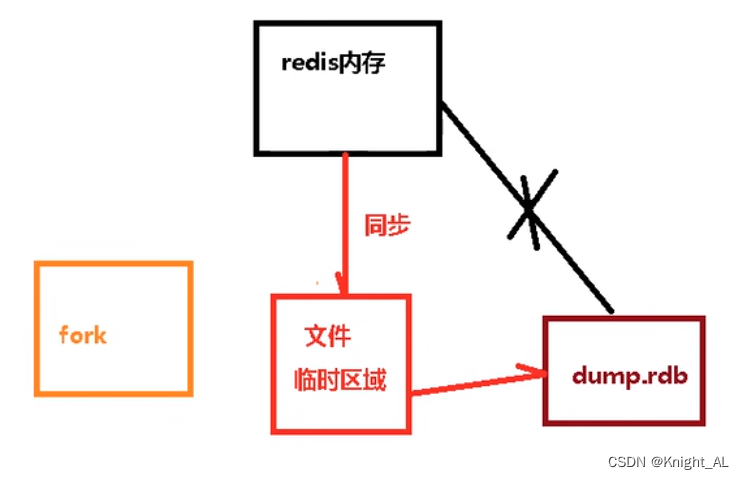
备份是如何执行的
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到 一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。
AOF
是什么
以日志的形式来记录每个写操作(增量保存),将Redis执行过的所有写指令记录下来(读操作不记录), 只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis 重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
AOF持久化流程
(1)客户端的请求写命令会被append追加到AOF缓冲区内;
(2)AOF缓冲区根据AOF持久化策略[always,everysec,no]将操作sync同步到磁盘的AOF文件中;
(3)AOF文件大小超过重写策略或手动重写时,会对AOF文件rewrite重写,压缩AOF文件容量;
(4)Redis服务重启时,会重新load加载AOF文件中的写操作,达到数据恢复的目的;

AOF和RDB同时开启,redis听谁的?
AOF和RDB同时开启,系统默认取AOF的数据(数据不会存在丢失)
9.SpringCloud共有几大组件?
- 注册中心/配置中心 Nacos
- 负载均衡 Ribbon
- 服务调用 Feign
- 服务保护 sentinel
- 服务网关 Gateway