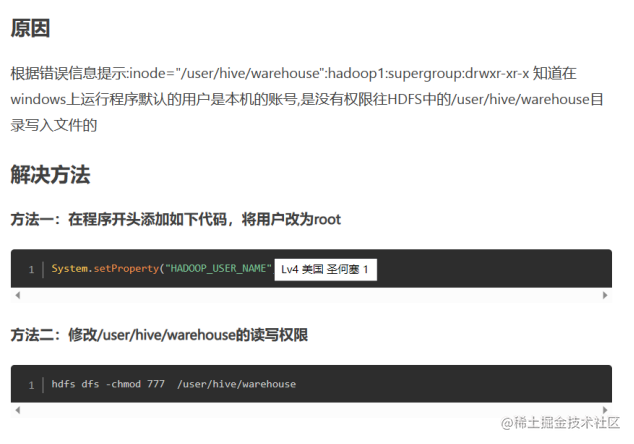
环境:ubuntu 18.04, Hadoop 3.3.5
参考资料:Hadoop官网:MapReduce Tutorial
前置工作
运行Hadoop。
参考:单节点模式,集群模式
单节点模式(for first-time users)
在YARN上以pseudo-distributed模式运行MapReduce任务。
- 格式化文件系统
$ bin/hdfs namenode -format
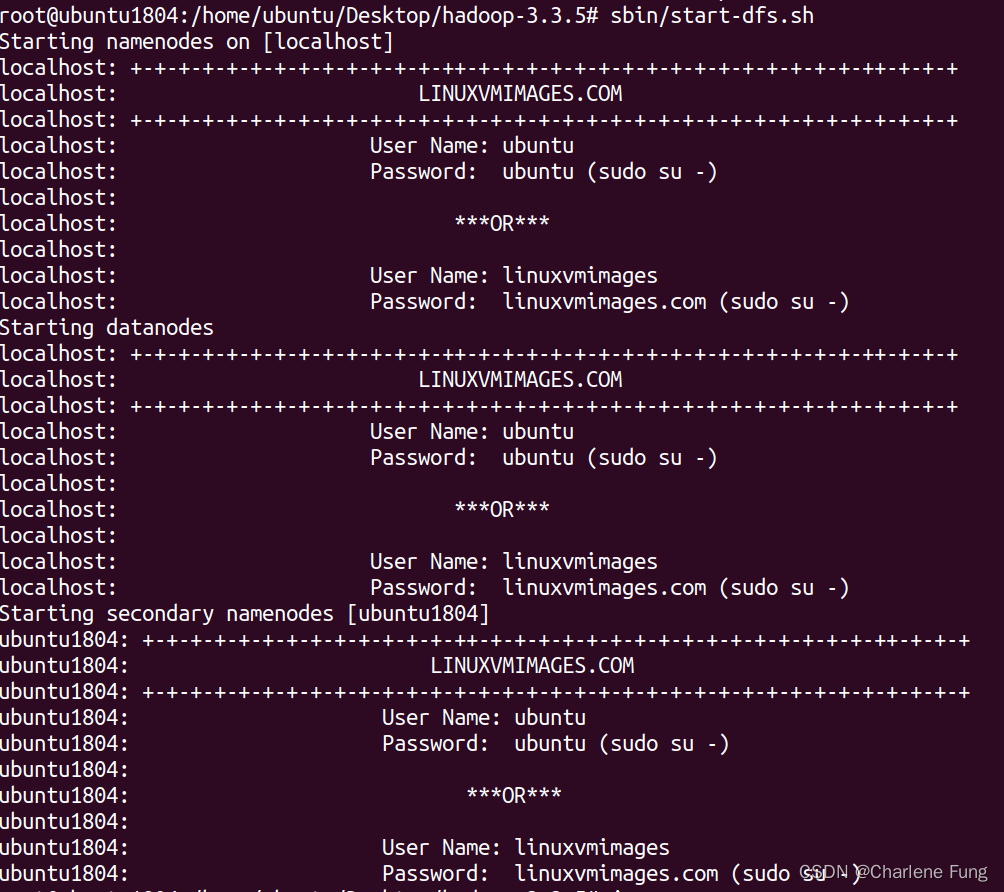
- 启动NameNode守护进程和DataNode守护进程
$ sbin/start-dfs.sh
-
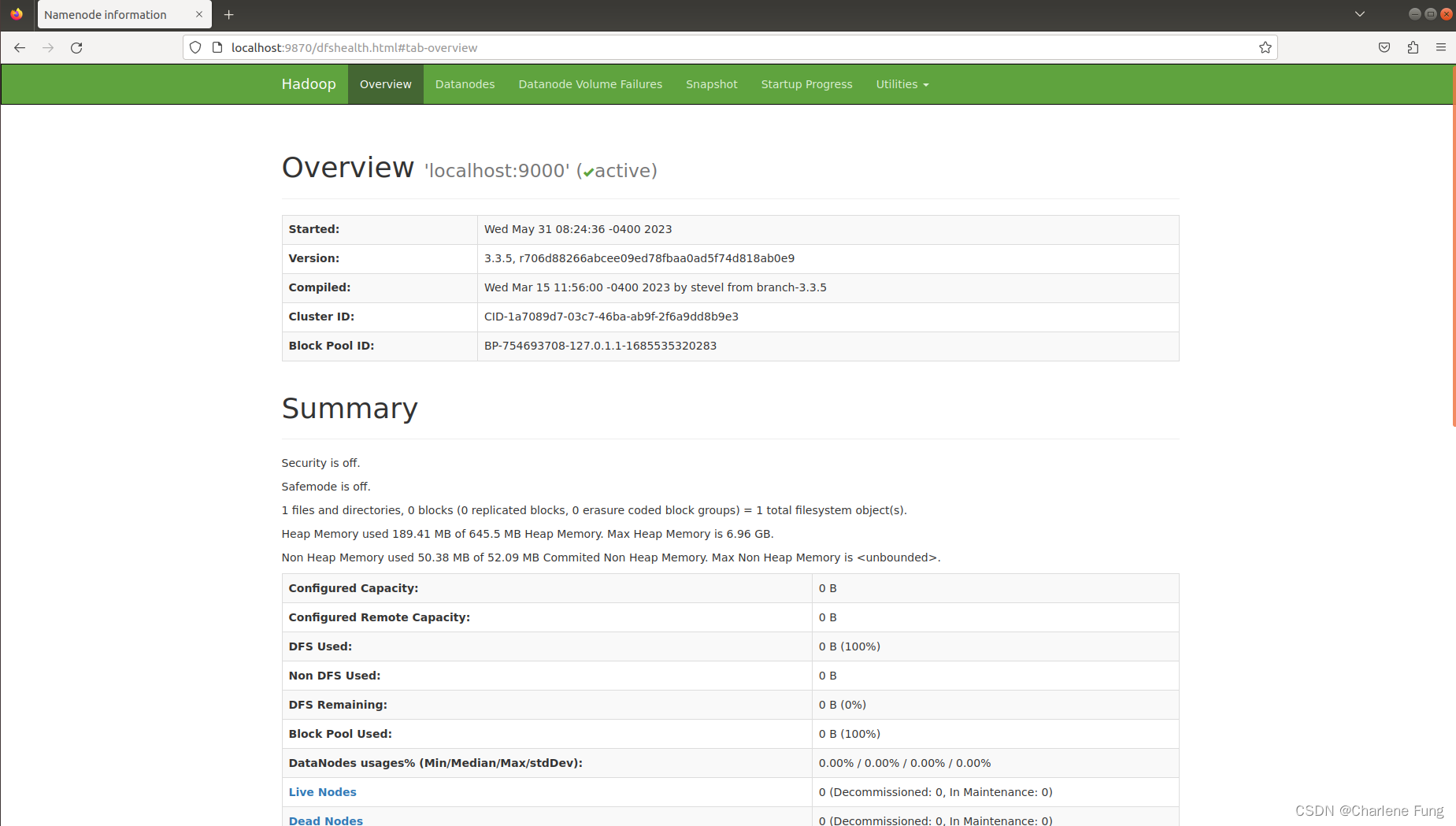
浏览NameNode的web界面。默认情况下,该地址为
http://localhost:9870/
-
创建执行MapReduce任务所需的HDFS目录:
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/<username>
#这里的username我用的是root,具体需要看前面的配置。
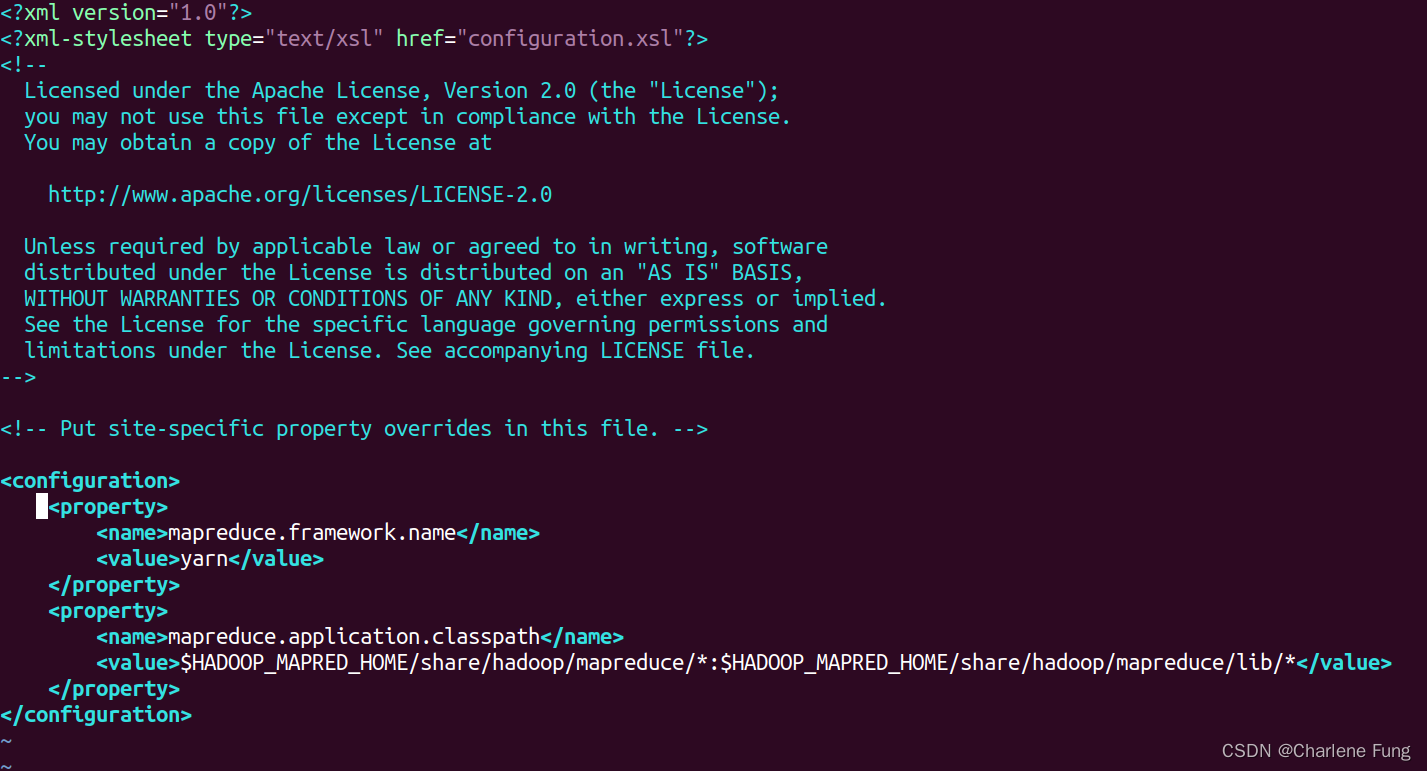
- 为mapreduce的xml文件新建配置。(如已添加可忽略)
<!--
etc/hadoop/mapred-site.xml
-->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
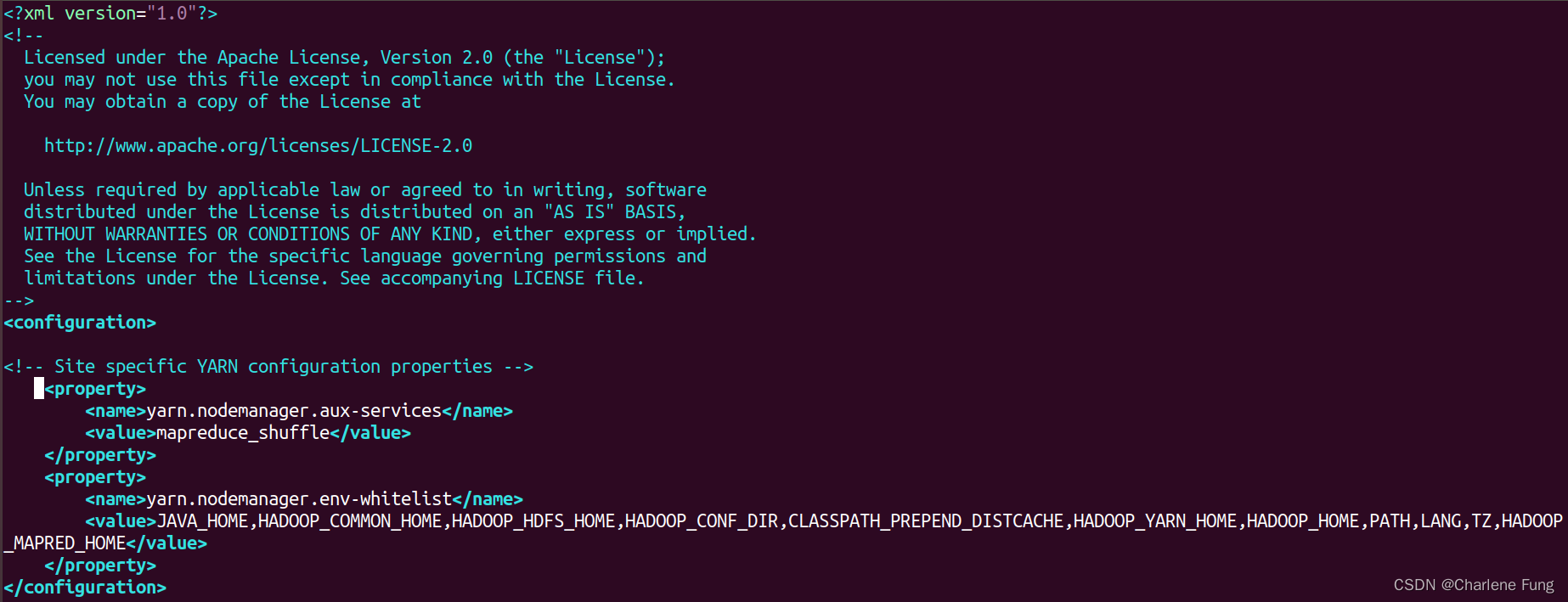
<!--
etc/hadoop/yarn-site.xml
-->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
- 启动ResourceManager守护进程和NodeManager守护进程:
$ sbin/start-yarn.sh
- 浏览ResourceManager的web界面。默认情况下,该地址为
http://localhost:8088/。
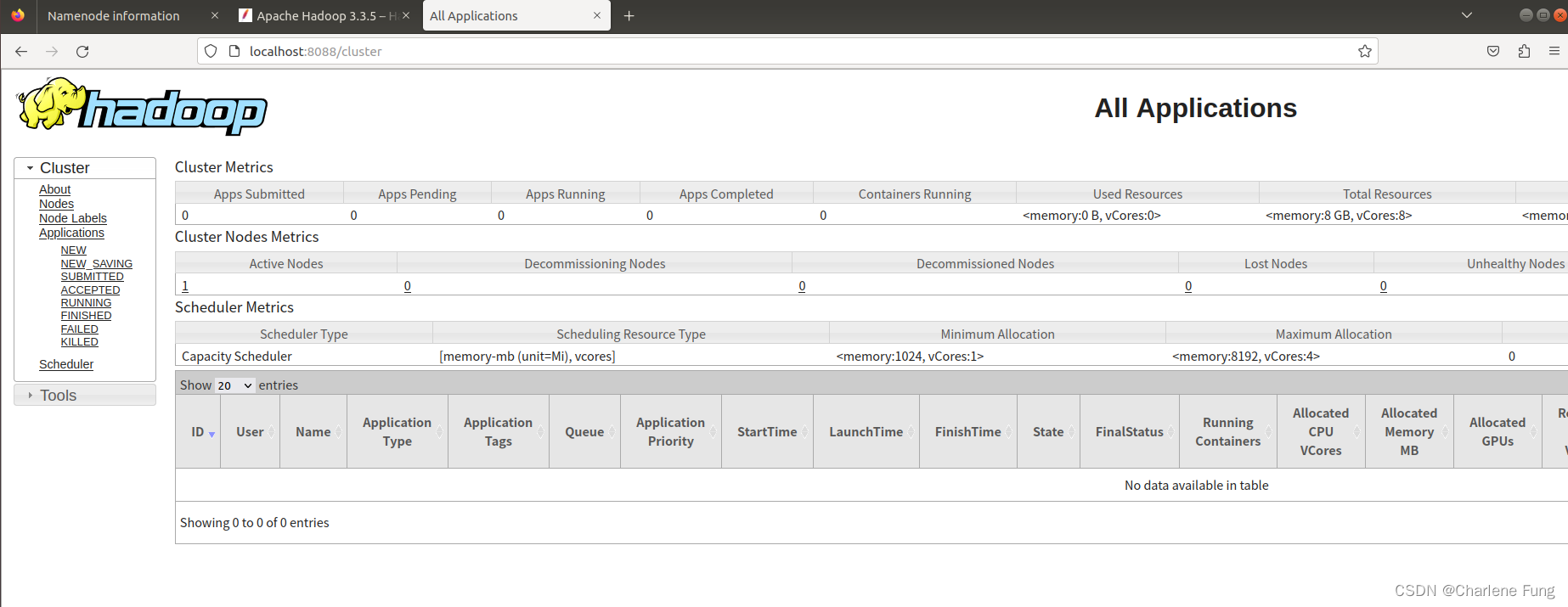 如果这一步没有打开,可能是前面的某个进程没有成功启动,用
如果这一步没有打开,可能是前面的某个进程没有成功启动,用jps检查一下。下面是正常启动的所有进程。如DataNode有缺失,可以参考我的这篇blog解决。
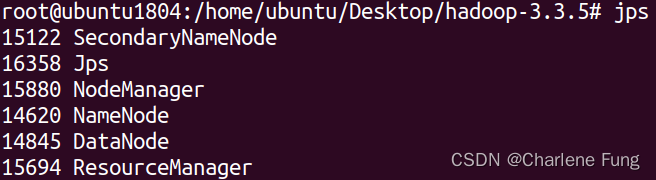
- 准备工作就绪,congrats!接下来我们进入正题。
WordCount v1.0
源代码(出自hadoop官网):
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 设定环境变量
JAVA_HOME(之前应该已经设置了),HADOOP_CLASSPATH,路径如下:
# 在~/.bashrc追加以下环境变量,JAVA_HOME根据实际情况设置
export JAVA_HOME=/usr/java/default
export PATH=${JAVA_HOME}/bin:${PATH}
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar
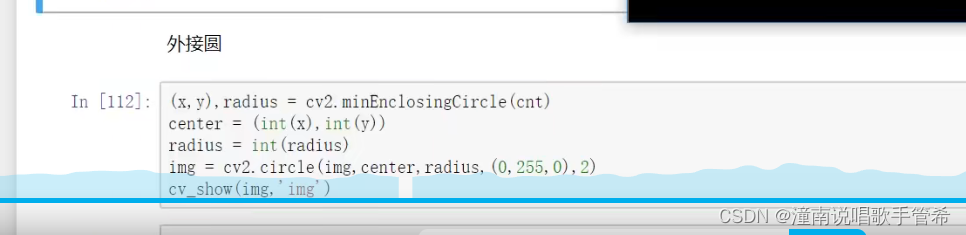
- 编译
WordCount.java文件,生成jar:
$ bin/hadoop com.sun.tools.javac.Main WordCount.java
运行出错:

上网搜了一通,最后突然醒悟,修改配置文件之后,忘记source ~/.bashrc了。配置生效后,可以成功编译!

接着执行:
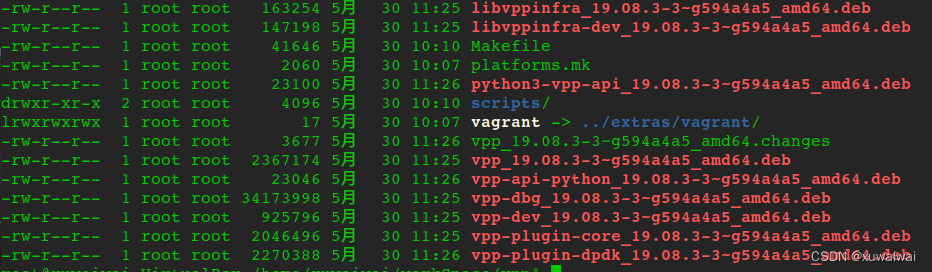
$ jar cf wc.jar WordCount*.class
路径下的文件如下所示。
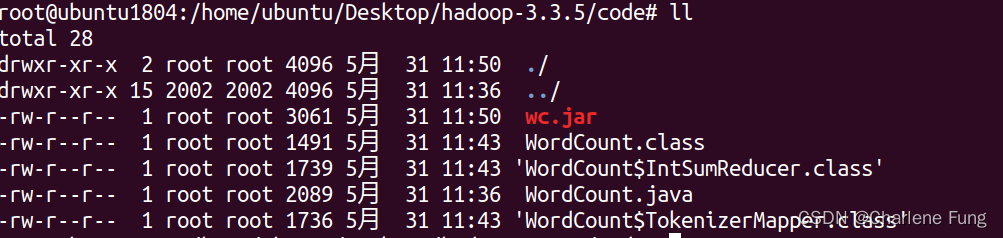
- 设定两个HDFS的输入输出路径,分别是:
/user/root/wordcount/input,/user/root/wordcount/output。

- 在代码目录下创建2个文件,分别是
file01和file02,里面的内容是:

- 上传这两个文件到HDFS的input目录下。
$ hdfs dfs -put file01 file02 wordcount/input
$ hadoop fs -cat /user/joe/wordcount/input/file01
Hello World Bye World
$ hadoop fs -cat /user/joe/wordcount/input/file02
Hello Hadoop Goodbye Hadoop
- 运行。
$ hadoop jar wc.jar WordCount /user/root/wordcount/input /user/root/wordcount/output
报错。
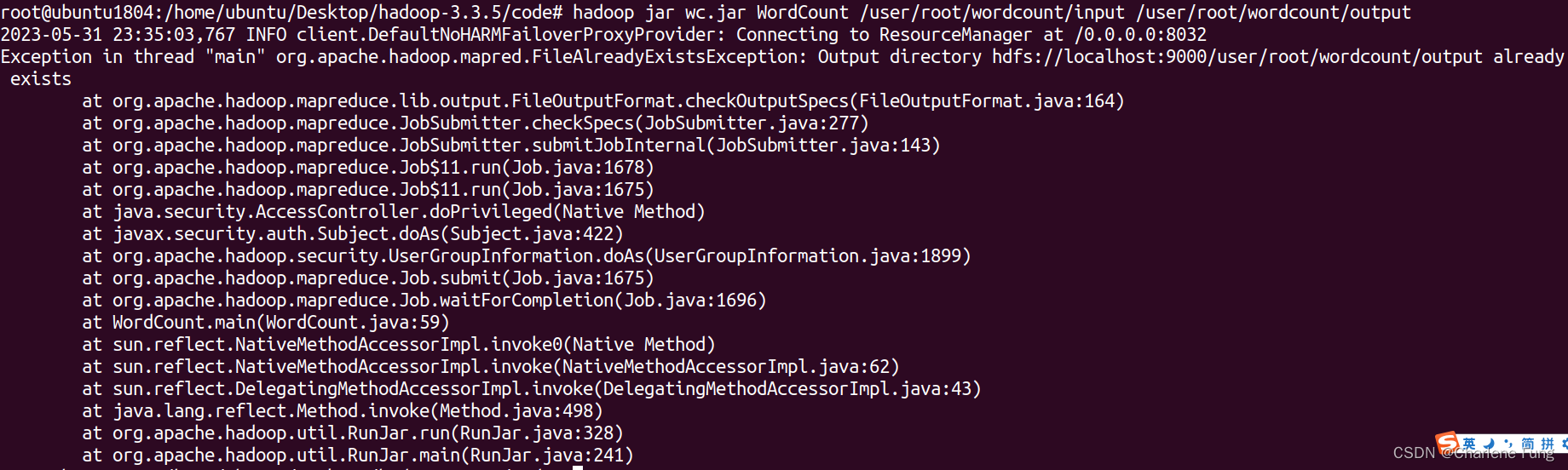
尝试将output目录删掉:hdfs dfs -rm -r /user/root/wordcount/output。

重新执行。成功运行。
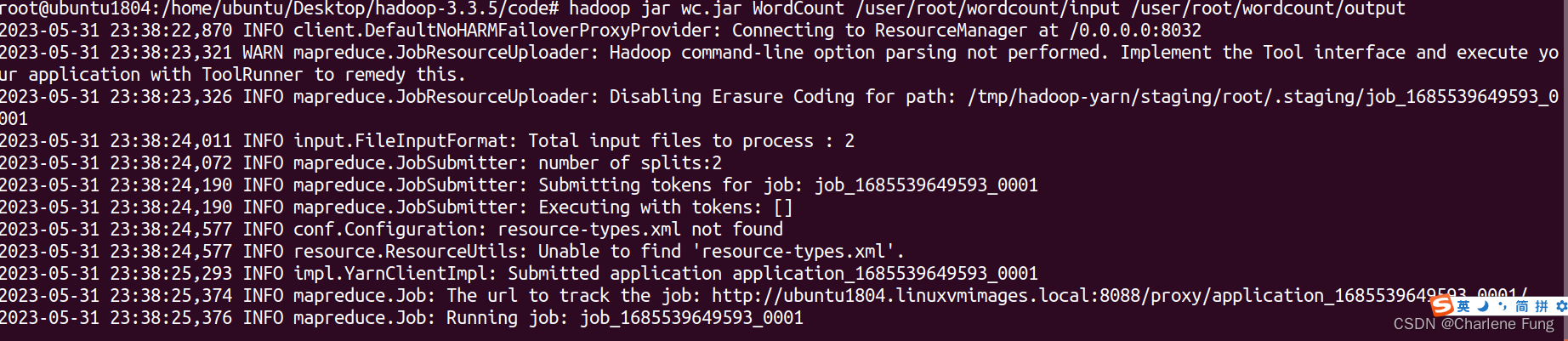
- 查看输出结果。
$ hadoop fs -cat /user/root/wordcount/output/part-r-00000