Pandas 是一个强大的数据分析 Python 库,提供了一系列用于数据清洗、转换、分析和可视化的 API。在使用 Pandas 进行数据处理时,常见的指令包括:
数据读取和解析
read_csv():用于读取 CSV、Excel等格式的数据文件,并将其转换为 Pandas DataFrame 对象。
import pandas as pd
# 读取 CSV 文件为 DataFrame
df = pd.read_csv('data.csv')
# 打印 DataFrame
print(df)read_excel():用于读取 Excel 文件,并将其转换为 Pandas DataFrame 对象。
利用pandas读取Excel多个表单
import pandas as pd
# 指定文件
excel_reader=pd.ExcelFile('文件.xlsx')
# 读取文件的所有表单名,得到列表
sheet_names = excel_reader.sheet_names
# 读取表单的内容,i是表单名的索引,等价于
# pd.read_excel('文件.xlsx', sheet_name=sheet_names[i])
df_data = excel_reader.parse(sheet_name=sheet_names[i])
# 关闭reader
excel_reader.close()利用pandas写入Excel多个sheet表单
import pandas as pd
# 定义writer,选择文件(文件可以不存在)
excel_writer = pd.ExcelWriter('文件.xlsx')
# 写入指定表单
df1.to_excel(excel_writer, sheet_name='自定义sheet_name1', index=False)
df2.to_excel(excel_writer, sheet_name='自定义sheet_name2', index=False)
# 储存文件
excel_writer.save()
# 关闭writer
excel_writer.close() read_json():用于读取 JSON 格式的数据文件,并将其转换为 Pandas DataFrame 对象。
import pandas as pd
from json import load
# 加载 JSON 文件为 DataFrame,注意需要使用 load() 函数而不是 from json import load()
df = pd.read_json('data.json', lines=True, dtype={'Name': str})数据转换和筛选
apply():用于将指定函数应用于每行数据,返回一个包含结果的新数组。
函数功能展示:
# 定义一个函数,将每个元素加倍
def double(x):
return x * 2
# 创建DataFrame
data = {'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
# 将函数应用于每个元素
df['C'] = df['A'].apply(double)
print(df)结果输出:
A B C
0 1 10 2
1 2 20 4
2 3 30 6
3 4 40 8
4 5 50 10agg():用于对数据进行聚合操作,例如求平均值、总和等。
函数功能展示:
# 创建DataFrame
data = {'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
# 对列A求平均值和总和
result = df['A'].agg(['mean', 'sum'])
print(result)结果输出:
mean 3.0
sum 15.0
Name: A, dtype: float64groupby():用于根据某个字段对数据进行分组,返回每组的数据。
函数功能展示:
# 创建DataFrame
data = {'Name': ['John', 'Jane', 'Mike', 'Emily', 'John'],
'Age': [25, 30, 35, 40, 45],
'City': ['New York', 'Paris', 'London', 'Paris', 'New York']}
df = pd.DataFrame(data)
# 根据City字段进行分组,并计算每组的平均年龄
result = df.groupby('City')['Age'].mean()
print(result)结果输出:
City
London 35
New York 35
Paris 35
Name: Age, dtype: int64head():用于获取数据开头的一部分数据。
函数功能展示:
# 创建DataFrame
data = {'A': [1, 2, 3, 4, 5]}
df = pd.DataFrame(data)
# 获取前3行数据
result = df.head(3)
print(result)结果输出:
A
0 1
1 2
2 3tail():用于获取数据末尾的一部分数据。
函数功能展示:
# 创建DataFrame
data = {'A': [1, 2, 3, 4, 5]}
df = pd.DataFrame(data)
# 获取最后3行数据
result = df.tail(3)
print(result)结果输出:
A
2 3
3 4
4 5数据排序和过滤
sort_values():用于按照指定列对数据进行排序。
函数功能展示:
# 创建DataFrame
data = {'Name': ['John', 'Jane', 'Mike', 'Emily'],
'Age': [25, 30, 35, 40]}
df = pd.DataFrame(data)
# 按照Age列进行升序排序
df_sorted = df.sort_values('Age')
print(df_sorted)结果输出:
Name Age
0 John 25
1 Jane 30
2 Mike 35
3 Emily 40drop_duplicates():用于删除数据中重复的行,返回唯一的数据。
函数功能展示:
# 创建DataFrame
data = {'Name': ['John', 'Jane', 'Mike', 'Emily', 'John'],
'Age': [25, 30, 35, 40, 25]}
df = pd.DataFrame(data)
# 删除重复的行
df_unique = df.drop_duplicates()
print(df_unique)结果输出:
Name Age
0 John 25
1 Jane 30
2 Mike 35
3 Emily 40dropna():用于删除数据中符合条件的行,返回符合条件的数据。
函数功能展示:
# 创建DataFrame
data = {'Name': ['John', 'Jane', np.nan, 'Emily'],
'Age': [25, np.nan, 35, 40]}
df = pd.DataFrame(data)
# 删除包含缺失值的行
df = df.dropna()
print(df)结果输出:
Name Age
0 John 25.0
2 Emily 35.0数据汇总和连接
join():用于将多个数据集合并成一个数据集。可以通过指定两个或更多的函数将两个数据集合并为一个新的数据集。
函数功能展示:
# 创建两个DataFrame
data1 = {'Name': ['John', 'Jane', 'Mike'],
'Age': [25, 30, 35]}
df1 = pd.DataFrame(data1)
data2 = {'Name': ['Emily', 'Tom', 'Kate'],
'City': ['New York', 'Paris', 'London']}
df2 = pd.DataFrame(data2)
# 使用join()函数将两个DataFrame按照Name列进行合并
df_merged = df1.join(df2.set_index('Name'), on='Name')
print(df_merged)结果输出:
Name Age City
0 John 25 NaN
1 Jane 30 NaN
2 Mike 35 NaNmerge():用于将两个或多个数据集合并成一个新的数据集。可以通过指定多个函数将两个或多个数据集合并为一个新的数据集。
函数功能展示:
# 创建两个DataFrame
data1 = {'Name': ['John', 'Jane', 'Mike'],
'Age': [25, 30, 35]}
df1 = pd.DataFrame(data1)
data2 = {'Name': ['Emily', 'Tom', 'Kate'],
'City': ['New York', 'Paris', 'London']}
df2 = pd.DataFrame(data2)
# 使用merge()函数将两个DataFrame按照Name列进行合并
df_merged = pd.merge(df1, df2, on='Name')
print(df_merged)结果输出:
Name Age City
0 John 25 New York
1 Jane 30 NaN
2 Mike 35 NaN需要注意的是,join()和merge()函数默认进行左连接(left join),即保留左边DataFrame的所有行,并根据指定的列进行合并。如果需要其他类型的连接(如内连接、外连接等),可以通过指定how参数来实现。例如,使用merge()函数进行内连接:
df_merged = pd.merge(df1, df2, on='Name', how='inner')还可以通过指定left_on和right_on参数来连接不同列名的DataFrame。
多维分析
pivot_table():用于将数据转换为表格形式,方便进行多维分析。
函数功能展示:
# 创建DataFrame
data = {'Name': ['John', 'Jane', 'John', 'Jane', 'John', 'Jane'],
'Subject': ['Math', 'Math', 'Science', 'Science', 'Math', 'Science'],
'Score': [80, 90, 85, 95, 75, 80]}
df = pd.DataFrame(data)
# 使用pivot_table()函数进行数据透视
pivot_table = df.pivot_table(index='Name', columns='Subject', values='Score', aggfunc='mean')
print(pivot_table)结果输出:
Subject Math Science
Name
Jane 90.0 87.5
John 77.5 85.0在上述示例中,我们通过指定index='Name'将姓名作为行索引,columns='Subject'将科目作为列索引,values='Score'将成绩作为要汇总的值,aggfunc='mean'指定了聚合函数为平均值。
pivot_table()函数根据指定的行、列和值对数据进行汇总和计算,生成了一个新的表格,其中行是姓名,列是科目,值是对应的平均分。这样,我们可以方便地进行多维分析,比如查看不同学生在不同科目上的平均分。
除了平均值,aggfunc参数还可以指定其他聚合函数,比如'sum'、'count'、'min'、'max'等,根据具体需求进行设置。
数据可视化
plot():用于绘制各种类型的图表,如柱状图、折线图、散点图等。它基于Matplotlib库,可以直接在Pandas中进行调用。
函数功能展示:
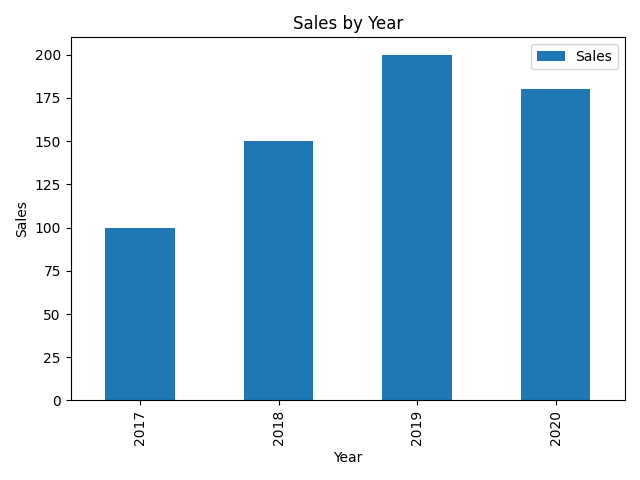
import pandas as pd
import matplotlib.pyplot as plt
# 创建DataFrame
data = {'Year': [2017, 2018, 2019, 2020],
'Sales': [100, 150, 200, 180]}
df = pd.DataFrame(data)
# 绘制柱状图
df.plot(x='Year', y='Sales', kind='bar')
plt.xlabel('Year')
plt.ylabel('Sales')
plt.title('Sales by Year')
plt.show()输出结果是一个柱状图,横轴是年份,纵轴是销售额。在这个示例中,我们通过指定x='Year'和y='Sales'来选择要绘制的数据列,然后指定kind='bar'来绘制柱状图。
结果输出:
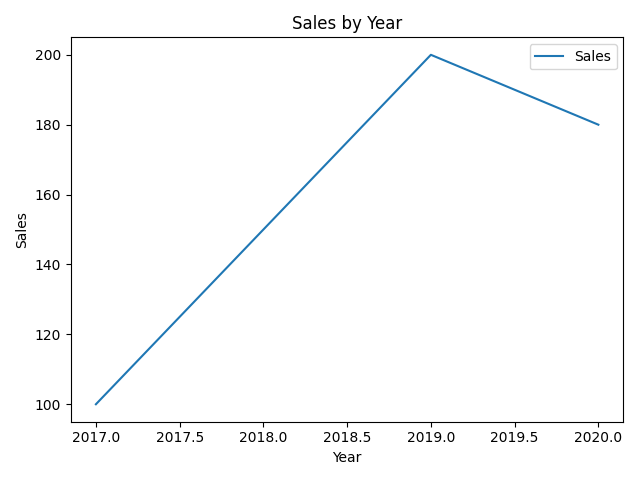
# 绘制折线图
df.plot(x='Year', y='Sales', kind='line')
plt.xlabel('Year')
plt.ylabel('Sales')
plt.title('Sales by Year')
plt.show()输出结果:
hist():Pandas中用于绘制直方图的函数。直方图是一种可视化工具,用于显示数据的分布情况,特别适用于连续变量的数据。
函数功能展示:
import pandas as pd
import matplotlib.pyplot as plt
# 创建DataFrame
data = {'Scores': [70, 85, 90, 75, 80, 95, 85, 90, 80, 85]}
df = pd.DataFrame(data)
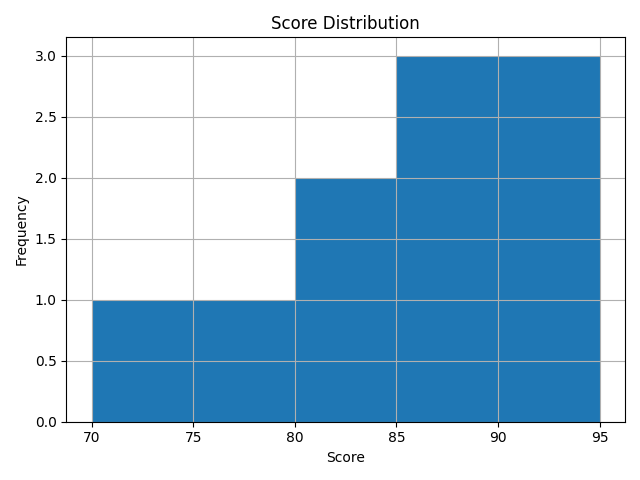
# 绘制直方图
df.hist(column='Scores', bins=5)
plt.xlabel('Score')
plt.ylabel('Frequency')
plt.title('Score Distribution')
plt.show()通过指定column='Scores'选择要绘制直方图的数据列,bins=5指定直方图的分组数量。这样,直方图将数据分成了5个组,横轴是分数,纵轴是频数(数据在每个组中出现的次数)。
结果输出:
boxplot():Pandas中用于绘制箱线图的函数。箱线图是一种可视化工具,用于展示数据的分布情况和离群值。
函数功能展示:
import pandas as pd
import matplotlib.pyplot as plt
# 创建DataFrame
data = {'Group': ['A', 'A', 'B', 'B', 'C', 'C'],
'Values': [10, 15, 20, 25, 30, 35]}
df = pd.DataFrame(data)
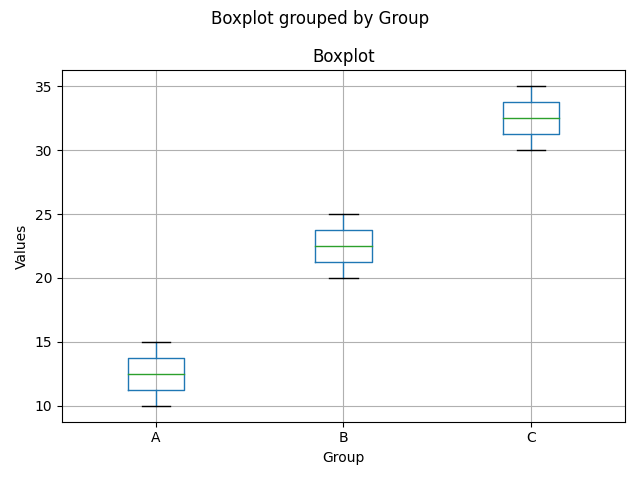
# 绘制箱线图
df.boxplot(column='Values', by='Group')
plt.xlabel('Group')
plt.ylabel('Values')
plt.title('Boxplot')
plt.show()通过指定column='Values'选择要绘制箱线图的数据列,by='Group'指定了分组的列。这样,箱线图将数据按照不同的组进行分组,横轴是组别,纵轴是数值。
在绘制箱线图之前,需要先导入pandas和matplotlib.pyplot库。然后,使用boxplot()函数绘制箱线图,并使用xlabel()、ylabel()和title()函数设置坐标轴标签和图表标题。
箱线图展示了数据的五个统计量:最小值(lower whisker)、第一四分位数(Q1)、中位数(Q2)、第三四分位数(Q3)、最大值(upper whisker)。箱体表示了Q1到Q3之间的数据范围,中间的线表示中位数。离群值(outliers)通常以圆圈或叉形表示。
需要注意的是,boxplot()函数也可以接受其他参数来定制箱线图的样式,如设置颜色、填充颜色、须的长度等。根据需求,可以选择合适的参数进行设置。另外,boxplot()函数也支持同时绘制多个箱线图,比如按照不同的列进行分组。
结果输出:
数据处理和优化
groupby() 和 agg() 函数结合使用,可以对同一列或同一行进行聚合操作,减少内存占用。
Pandas 的 lr=True 参数可以自动学习数据重分配策略,减少内存占用。
Pandas 提供了一些优化技巧,例如使用 rolling() 函数计算滚动窗口中的平均值等。
了上述指令外,Pandas 还有许多其他常见的指令,如:
describe():用于查看数据的统计信息,例如均值、方差、标准差等。
groupby() 和 agg() 函数配合使用,可以对数据按照某个字段进行分组,并对每组数据进行聚合操作。
rolling() 函数可以计算滚动窗口中的平均值,减少内存占用。
drop_duplicates() 函数可以删除重复的行,并返回唯一的数据。
tail() 函数可以获取数据末尾的一部分数据,方便进行数据分析。
使用 Pandas 进行数据处理时,还需要注意以下几点:
注意处理缺失值:Pandas 可以通过缺失值处理函数(如 fillna())来处理缺失值,但是在进行聚合操作时,缺失值可能会对结果产生影响。因此,需要根据具体情况选择合适的处理方法。
注意数据类型:Pandas 支持多种数据类型,包括 int、float、str、Series、DataFrame 等。在进行数据处理时,需要根据数据类型选择合适的函数和指令。
注意索引:Pandas 对于多维数据集(如矩阵)非常有用,但是索引也会影响数据处理效率。因此,需要合理地设置索引,并注意索引的类型和数量。
注意异常值:Pandas 对于异常值非常敏感,如果数据中存在异常值,可能会导致程序崩溃或产生不正确的结果。因此,需要注意异常值的处理和输出。
注意性能:在进行大规模数据处理时,需要注意 Pandas 的性能问题。可以通过调整参数(如缓冲区大小、分区方式等)来提高程序的性能。
总之,使用 Pandas 进行数据处理需要熟悉其指令和技巧,并注意处理数据中的各种问题,才能得到准确、高效的结果。
除了数据处理外,Pandas 还可以用于数据挖掘、机器学习等领域。以下是一些 Pandas 在数据挖掘和机器学习中的应用:
分类和回归:Pandas 可以用于多分类和回归问题,可以方便地处理复杂的数据集。
聚类:Pandas 可以用于层次聚类和k均值聚类等聚类算法,可以对数据进行快速聚类。
特征工程:Pandas 可以用于特征提取和降维,可以将高维数据转换为低维数据,并保留重要特征。
机器学习模型训练:Pandas 可以用于加载和预处理机器学习模型的输出,可以方便地处理大型数据集。
数据可视化:Pandas 可以用于绘制热力图、散点图、箱线图等图表,可以方便地对数据进行可视化分析。
总之,Pandas 是一个功能强大的 Python 库,可以用于数据清洗、转换、分析和可视化等多个领域。在进行数据处理和机器学习时,Pandas 可以提供很大的帮助。