torch.nn中的nn全称为neural network,意思是神经网络,是torch中构建神经网络的模块。
文章目录
- 一、神经网络基本骨架
- 二、认识卷积操作
- 三、认识最大池化操作
- 四、非线性激活
- 五、线性层及其它层介绍
- 六、简单的神经网络搭建
- 七、简单的认识神经网络中的数值计算
- 八、损失函数与反向传播的应用
一、神经网络基本骨架
CNN卷积神经网络基本包含五个层
- ①输入层
- 主要做什么?数据的预处理
- 去均值
- 归一化
- PCA/SVD降维等
- 使用模块
- transforms
- 主要做什么?数据的预处理
- ②卷积层
一个图像占有很大的维数,但是图像的特征所在的维数远小于一个图像的维数
在训练时冗余的维数会拖慢训练进度,我们要使用卷积降低维数,又保留特征(人识别不出特征计算机可以) - ③激活(激励)层
- 主要做什么?
- 对卷积层得出的结果做一次非线性映射
- 主要使用函数
- sigmoid
- tanh
- relu
- leaky relu
- elu
- maxout
- 主要做什么?
- ④池化层(又称欠采样或下采样)
- 主要作用:
- 特征降维,压缩数据参数、数量,减小过拟合提高模型的容错性
- 主要模块
- 平均池化:MaxPooling
- 最大池化:Average Pooling
- 主要作用:
- ⑤全连接fc层
- 经过多次卷积、激励、池化后没有出现过拟合可以认为模型训练完毕
二、认识卷积操作
- 卷积相关概念
- 卷积核:一定大小的矩阵,利用该矩阵与目标矩阵进行运算
- 卷积操作:具体运算是对应项相乘再相加,计算结果放在新生成的位置
- 卷积操作常用函数
- conv1d(一维卷积)
- conv2d(二维卷积)
- conv3d(三维卷积)
- 卷积时传进去的参数意义
- input 需要进行操作的矩阵
- weight 矩阵的权重
- stride 每次卷积完下次卷积移动的步长
- padding 目标矩阵在进行卷积操作的时候,是否进行外边界的填充

下面代码模拟了一下卷积操作:
# 模拟一下卷积操作
# 目标矩阵
objA=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
# 卷积核
coCore=torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
input=torch.reshape(objA,(1,1,5,5))
coCore=torch.reshape(coCore,(1,1,3,3))
# 步长为1没有外边界填充
output1=F.conv2d(input,coCore,stride=1)
# 向外扩充一圈
output2=F.conv2d(input,coCore,stride=1,padding=1)
print(output1)
print(output2)
结果(可以自己计算测试一下):
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
Process finished with exit code 0
将数据传入神经网络,进行多层卷积会得到具有明显特征的图片
测试一下神经网络中的卷积:
import os
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
'''
将数据传入神经网络,进行多层卷积会得到具有明显特征的图片
'''
basepath=os.path.split(os.getcwd())[0]
# 获取需要使用的数据集
dataset=torchvision.datasets.CIFAR10(basepath+r"\数据集",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 加载数据集其中64个打包分成一块
dataloader=DataLoader(dataset,batch_size=64)
# 自定义一个神经网络类
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
# 初始化一层卷积
# channels 英文意思是频道
# in_channels 向神经网络输送的数据频道数量
# out_channels 神经网络输出的频道数量
# kernel_size 卷积核的大小,输出的时候会将卷积核根据其大小正方形化
# stride 每次卷积移动的步长,输出的时候也是一个元组,代表左右上下都是移动1
self.conv1=Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
x=self.conv1(x)
return x
# 创建日志文件,显示图像表示的效果
writer=SummaryWriter("logs_Conv")
# 生成神经网络模型
myModel=Model()
# print(myModel)
stept=0
# 迭代打包好的数据,将数据输送到神经网络进行卷积,最后得出卷积后的图片
for data in dataloader:
# 获取数据与标签
imgs,targets=data
# 将数据输送到神经网络
output=myModel(imgs)
print(imgs.shape)
print(output.shape)
# 输出的数据是3,6,30,30 30为尺寸
# tensorboard无法识别6维的图片,使用reshape修改图片形状
output=torch.reshape(output,(-1,3,30,30))
# 将图片加入到tensorBoard中
writer.add_images("input",imgs,stept)
writer.add_images("output",output,stept)
stept=stept+1
# 如果一个图片经过卷积尺寸没有改变并且维度变大,那么可能进行了卷积时的边界填充
三、认识最大池化操作
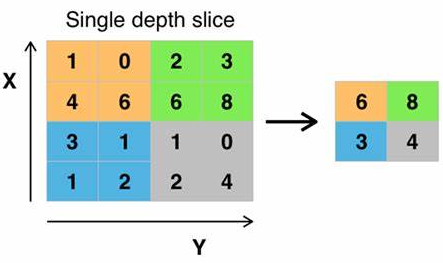
最大池化的作用:
通过卷积核大小将图片各个区域的最大值选出来
一般最大池化后会将数据的大小大大减小,以此提高训练速度
最大池化会将数据比较明显的特征提取出来
在日常神经网络训练过程中,通常将卷积,最大池化,激活函数交替使用
最大池化,Tensor变化,我记得还有平均池化之类的东西,感兴趣大家自己研究研究。
import os
import torch.nn as nn
import torch
import torchvision
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
basepath=os.path.split(os.getcwd())[0]
# 初始化数据集
writer=SummaryWriter(basepath+r"\logss\logs9_1")
dataset=torchvision.datasets.CIFAR10(basepath+r"\数据集",train=False,transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(dataset,64)
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.pool1=MaxPool2d(kernel_size=2,ceil_mode=True)
def forward(self,input):
output=self.pool1(input)
return output
# 创建神经网络模型
myModel=Model()
step=0
for data in dataloader:
imgs,targes=data
output=myModel(imgs)
writer.add_images("pool_test",output,step)
step=step+1
writer.close()
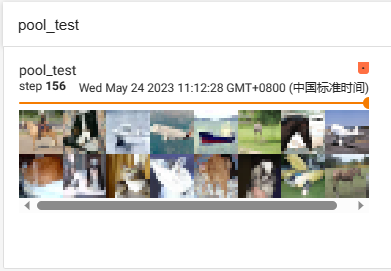
池化过后的图片:
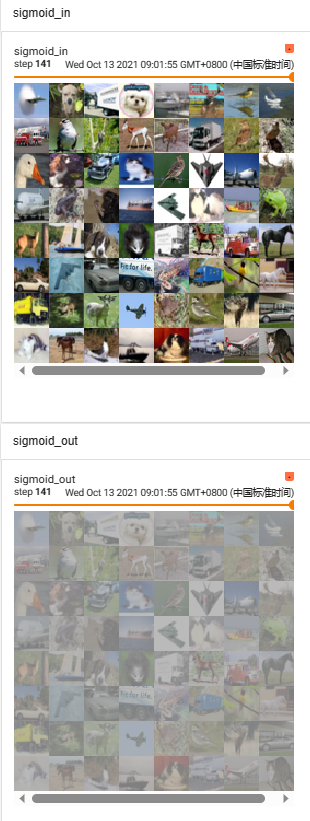
四、非线性激活
当数据混乱冗杂时,不带激活函数的单层感知机是一个线性分类器,线性函数无法对各个类别进行分类
激活函数是用来加入非线性因素的,提高神经网络对模型的表达能力,解决线性模型无法解决的问题
单层感知机是最基础的神经网络,感知机网络与卷积网络都属于前馈型网络
单层感知机网络是二分类的线性分类模型,输入是被感知数据集的特征向量,输出是数据集的类别
五、线性层及其它层介绍
-
Linear Layers线性层
-
Dropout Layers 随机将一些数据置为0
Dropout函数参数
第一个参数p是被置为0的概率,第二个参数inplace 是否在本次样本进行操作默认为false -
Normalization正则化层
-
Recurrent Layers
-
Transformer Layers
-
Sparse Layers 一般用于自然语言处理
import os
import torch.nn as nn
import torch
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
basepath=os.path.split(os.getcwd())[0]
# 预处理数据集
dataset=torchvision.datasets.CIFAR10(basepath+r"\数据集",train=False,transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(dataset,64)
writer=SummaryWriter(basepath+r"\logss\log_6")
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
'''
Linear()
第一个参数是输入的样本大小,第二个是输出的样本大小,第三个是是否偏执,默认为true
'''
self.line1=nn.Linear(196608,10)
def forward(self,input):
output=self.line1(input)
return output
myModel=Model()
step=0
for data in dataloader:
imgs,targets=data
print(imgs.shape)
# 该函数直接将多维数组直接转换成一维数组
output=torch.flatten(imgs)
print(output.shape)
output=myModel(output)
print(output.shape)
# writer.add_images("test",output,step)
step=step+1
六、简单的神经网络搭建
普通方式
import os
import torch
import torch.nn as nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
basepath=os.path.split(os.getcwd())[0]
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.con1=Conv2d(3, 32, 5, padding=2)
self.maxp1=MaxPool2d(2)
self.con2=Conv2d(32, 32, 5, padding=2)
self.maxp2=MaxPool2d(2)
self.con3=Conv2d(32, 64, 5, padding=2)
self.maxp3=MaxPool2d(2)
self.fla=Flatten()
self.lin1=Linear(1024, 64)
self.lin2=Linear(64, 10)
def forward(self,x):
x=self.con1(x)
x=self.maxp1(x)
x=self.con2(x)
x=self.maxp2(x)
x=self.con3(x)
x=self.maxp3(x)
x=self.fla(x)
x=self.lin1(x)
x=self.lin2(x)
return x
Sequential方式
构建神经网络的另一个方法,也可以说是快速构建方法,就是通过torch.nn.Sequential,直接完成对神经网络的建立。
import os
import torch
import torch.nn as nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
basepath=os.path.split(os.getcwd())[0]
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.model1 = Sequential(
# 卷积
Conv2d(3, 32, 5, padding=2),
# 池化
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
# 展开为一维数组
Flatten(),
# 线性映射
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
直接打印创建的对象可以看到网络结构,也可以通过之前介绍到的tensorboard查看网络结构:
myModel=Model()
writer=SummaryWriter(basepath+r"\logss\log_7")
print(myModel)
input=torch.ones((64,3,32,32))
output=myModel(input)
print(output.shape)
# 将搭建的神经网络结构绘制到tensorboard中
writer.add_graph(myModel,input)
writer.close()
输出结果如下:
Model(
(model1): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([64, 10])
Process finished with exit code 0

七、简单的认识神经网络中的数值计算
import torch
from torch.nn import L1Loss
import torch.nn as nn
input=torch.tensor([1,2,3],dtype=torch.float32)
target=torch.tensor([1,2,5])
input=torch.reshape(input,(1,1,1,3))
target=torch.reshape(target,(1,1,1,3))
# 获取损失函数计算器(计算差值)
# reduction可以进行修改
loss=L1Loss(reduction="sum")
result_loss=loss(input,target)
print(result_loss)
# 计算平方差
loss_mse=nn.MSELoss()
result_loss_mse=loss_mse(input,target)
print(result_loss_mse)
# 交叉熵
x=torch.tensor([0.1,0.2,0.3])
y=torch.tensor([1])
# 这里(1,3)代表有三个类别一个进行选择
x=torch.reshape(x,(1,3))
loss_cross=nn.CrossEntropyLoss()
result_loss=loss_cross(x,y)
print(result_loss)
八、损失函数与反向传播的应用
- 损失函数
损失函数用于检测最后的数据结果与最开始的数据存在的差值(默认计算的是平均损失值,可以对reduction参数进行修改,改为自己想进行的运算方式)计算实际得到的结果与预测结果的差值 - 反向传播
损失函数进行完损失值的计算,使用反向传播会给数据下一次进入神经网络提供一些参数进行参考,以减小损失值结合优化器一块使用,反向传播告诉神经网络,模型的好坏,哪里需要调整 - 优化器
损失函数进行误差估计,反向传播将数据参数给优化器,然后优化器根据梯度对训练方式进行优化
优化器没进行完一次优化,就需要将数据清理一次
import os
import torchvision.datasets
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
basepath=os.path.split(os.getcwd())[0]
dataset=torchvision.datasets.CIFAR10(basepath+r"\数据集",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,1)
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.model1 = Sequential(
# 卷积
Conv2d(3, 32, 5, padding=2),
# 池化
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
# 展开为一维数组
Flatten(),
# 线性映射
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
myModel=Model()
# 创建损失函数
loss=nn.CrossEntropyLoss()
# 获取优化器
optim=torch.optim.SGD(myModel.parameters(),lr=0.01)#lr指的是训练速率,这个速率不可以过高,也不可以太低,过高会使模型不稳定
for x in range(20):#过低训练速度太慢
runing_loss=0.0
for data in dataloader:
imgs,targets=data
output=myModel(imgs)
# print(output)
# print(targets)
result_loss=loss(output,targets)
optim.zero_grad()
result_loss.backward()
optim.step()
runing_loss=runing_loss+result_loss
print(runing_loss)