文章目录
- 1:简介
- 1.1:CH是什么?
- 1.2:CH优势
- 1.3:架构设计
- 2:CH接口
- 3:CH引擎
- 1:数据库引擎
- 3.1.1:mysql引擎
- 2:表引擎
- 3.2.1:MergeTree
- 3.2.2:集成引擎
- 1:mysql引擎
- 2:Hive
- 2:kafka
- 4:数据类型
- 5:性能优化
ClickHouse官网
CH存储原理
1:简介
clickhouse以下简称CH
1.1:CH是什么?
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
常见的行式数据库系统有:MySQL、Postgres和MS SQL Server
常见的行式数据库系统有:ClickHouse、hbase
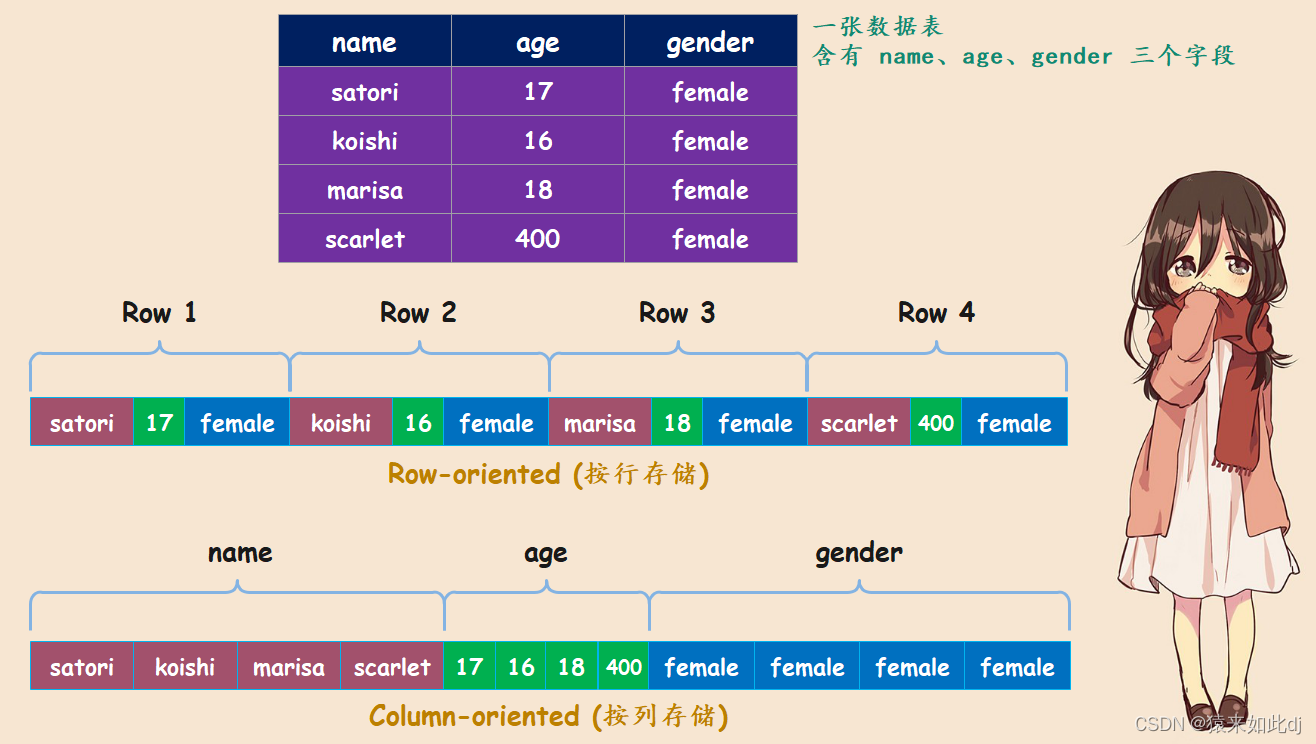
存储方式:行式数据库中同行数据被同一个物理存储,列式数据库是不同的列被不同物理存储。
适合场景:列式数据库适合OLAP;行式数据库更适合OLTP事务场景中
关于OLAP和OLTP可以看
1.2:CH优势
1:真正的列式数据库,更精确的数据类型如(Int类型:Int8、 Int16、 Int32、 Int64、 Int128、 Int256)带来更高的存储空间利用和更高的解压缩速度,更好的cpu使用,更高的吞吐量
2:数据存储在磁盘上,低成本
3:分布式,更好的利用每台服务器和集群的性能。
4:索引
按照主键对数据进行排序,这将帮助ClickHouse在几十毫秒以内完成对数据特定值或范围的查找。
5:适合在线查询
在线查询意味着在没有对数据做任何预处理的情况下以极低的延迟处理查询并将结果加载到用户的页面中。
6:支持sql
7:向量化执行引擎SIMD(在cpu计算时即用单条指令操作多条数据, CPU 寄存器层面实现数据的并行计算)
1.3:架构设计
Hadoop生态系统技术都采用了Master-Slave主从架构,而ClickHouse则采用Multi-Master多主架构,集群中每个节点角色对等,客户端访问任意一个节点都能达到相同的效果。
ClickHouse的集群由分片 ( Shard ) 组成,而每个分片又通过副本 ( Replica ) 组成
分片: 依赖集群,每个集群由1个或多个分片组成,每个分片对应ClickHouse的1台服务器节点,分片的数量取决于节点数量。
副本(Replica) 为了在异常情况下保证数据的安全性和服务的高可用性,ClickHouse提供了副本机制,将单台服务器的数据冗余存储在2台或多台服务器上。
1、本地表(Local Table)和分布式表(Distribute Table)
- 一张本地表相当于一份数据分片
- 分布式表本身不存储数据,它是本地表的访问代理,借助分布式表,能够代理访问多个数据分片,从而实现分布式查询,分布式表只是将数据分散存放了,相当于进行了负载均衡和一定的容错
- 分布式缺点:存在单点问题,分片故障数据丢失
2、单机表和复制表
单机表:数据只会存储在当前服务器上,不会被复制到其他服务器,即只有一个副本。
复制表:ClickHouse依靠ReplicatedMergeTree引擎族与ZooKeeper实现了复制表机制,来实现CH的高可用,数据被复制到多个服务器上利用副本进行存储。
在创建表时可以通过指定引擎选择该表是否高可用,每张表的分片与副本都是互相独立的。生产上一般都是复制表。
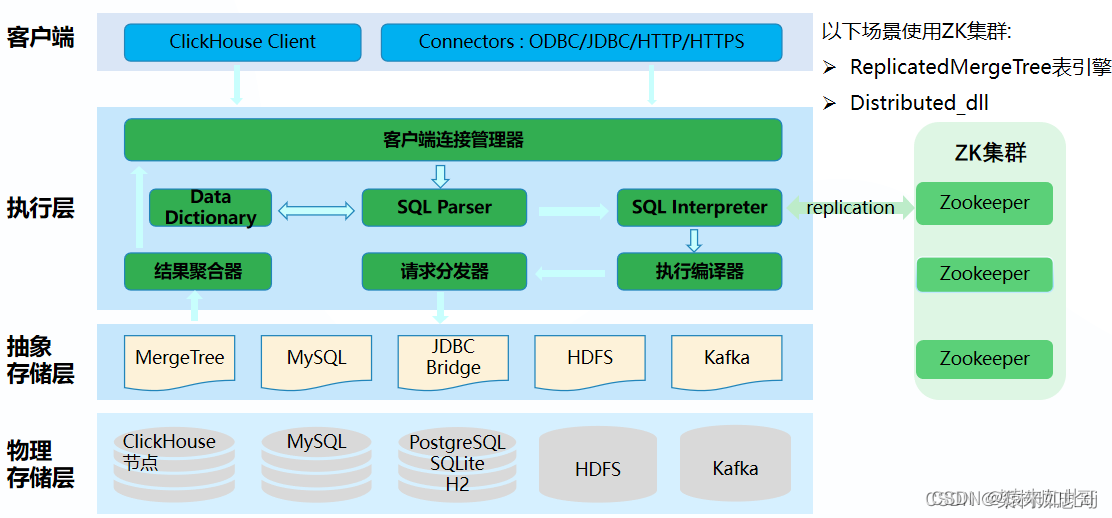
3、CH整体架构
2:CH接口
提供多种接口用来登录访问CH
3:CH引擎
1:数据库引擎
数据库引擎允许您处理数据表。
默认情况下,ClickHouse使用Atomic数据库引擎
CREATE DATABASE test[ ENGINE = Atomic];
3.1.1:mysql引擎
MySQL引擎用于将远程的MySQL服务器中的表映射到ClickHouse中(数据实际还在mysql中),并允许您对表进行INSERT和SELECT查询,以方便您在ClickHouse与MySQL之间进行数据交换
但您无法对其执行以下操作:
- RENAME
CREATE TABLE
ALTER
使用示例:创建数据库
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')
2:表引擎
表引擎(即表的类型)决定了:
- 1.数据的存储方式和位置,写到哪里以及从哪里读取数据
2.支持哪些查询以及如何支持。
3.并发数据访问。
4.索引的使用(如果存在)。
5.是否可以执行多线程请求。
6.数据复制参数,是否可以存储数据副本。
7.分布式引擎
引擎有MergeTree系列,log系列,集成引擎(kafka,mysql,jdbc等)
- 目前只有MergeTree、Merge和Distributed这三类表引擎支持 alter 操作。
- 目前只有MergeTree系列 的表引擎支持数据分区,只有 MergeTree 系列里的表可支持副本:
3.2.1:MergeTree
lickhouse 中最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree)中的其他引擎
主要特点:
1、存储的数据按主键排序。
2、这使得您能够创建一个小型的稀疏索引来加快数据检索。
3、如果指定了 分区键 的话,可以使用分区。
4、在相同数据集和相同结果集的情况下 ClickHouse 中某些带分区的操作会比普通操作更快。查询中指定了分区键时 ClickHouse 会自动截取分区数据。这也有效增加了查询性能。
5、支持数据副本。ReplicatedMergeTree 系列的表提供了数据副本功能。更多信息,请参阅 数据副本 一节。
6、支持数据采样。需要的话,您可以给表设置一个采样方法。
创建表示例
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
比如,toYYYYMM(EventDate) 是按月分区
ENGINE MergeTree() PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID) SETTINGS index_granularity=8192
存储结构
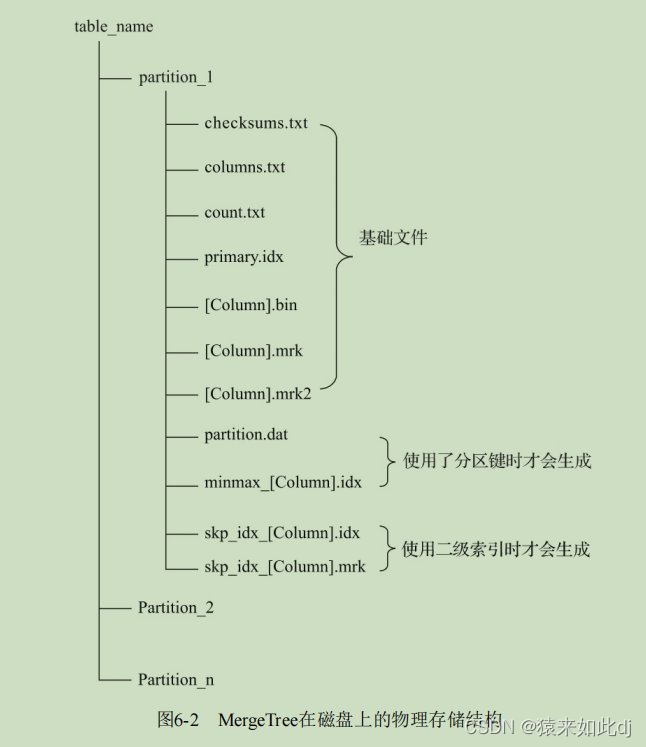
分区目录:partition
余下各类数据文件(primary.idx、 [Column].mrk、[Column].bin等)都是以分区目录的形式被组织存放的,属于相同分区的数据,最终会被合并到同一个分区目录,而不同分区的数据,永远不会被合并在一起。
校验文件:checksums.txt
使用二进制格式存储。它保存了余下各类文件(primary.idx、count.txt等)的size大小及size的哈希值,用于快速校验文件的完整性和正确性。
列信息文件:columns.txt
使用明文格式存储。用于保存此数据分区下的列字段信息。
3.2.2:集成引擎
集成引擎支持hive,hdfs,mysql,kkafka等多种数据管理引擎,此处仅列举几个
1:mysql引擎
MySQL 引擎可以对存储在远程 MySQL 服务器上的数据执行 SELECT 查询。
2:Hive
Hive引擎允许对HDFS Hive表执行 SELECT 查询
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [ALIAS expr1],
name2 [type2] [ALIAS expr2],
…
) ENGINE = Hive(‘thrift://host:port’, ‘database’, ‘table’);
PARTITION BY expr
2:kafka
CREATE TABLE queue (
timestamp UInt64,
level String,
message String
) ENGINE = Kafka(‘localhost:9092’, ‘topic’, ‘group1’, ‘JSONEachRow’);
4:数据类型
Int类型:Int8、 Int16、 Int32、 Int64、 Int128、 Int256
时间类型:Date32、DateTime64、Date
iP:IPv4、IPv6
小数:Float32、Float64、Decimal32、Decimal64、Decimal128
boolean:
字符串:String、FixedString、UUID
特殊类型:数组Array、枚举Enum8、Enum16、元组tuple(T)、嵌套Nested、位置坐标Point、Ring、Polygon、MultiPolygon
5:性能优化
从跳数索引,主键稀疏索引进行优化,也可以创联合索引。
跳数索引是建立在主键外的索引列,用于提升查询where后有该列时的查询性能。具体使用查看官网。
MergeTree 不是 LSM 树,因为它不包含»memtable«和»log«:插入的数据直接写入文件系统。这使得它仅适用于批量插入数据,而不适用于非常频繁地一行一行插入 - 大约每秒一次是没问题的,但是每秒一千次就会有问题