(179条消息) Transformer模型入门详解及代码实现_transformer模型代码-CSDN博客
transformer的encoder和decoder的差别
1. decoder包含两个 Multi-Head Attention 层。
- decoder第一个 Multi-Head Attention 层采用了 Masked 操作。
为什么需要Mask处理
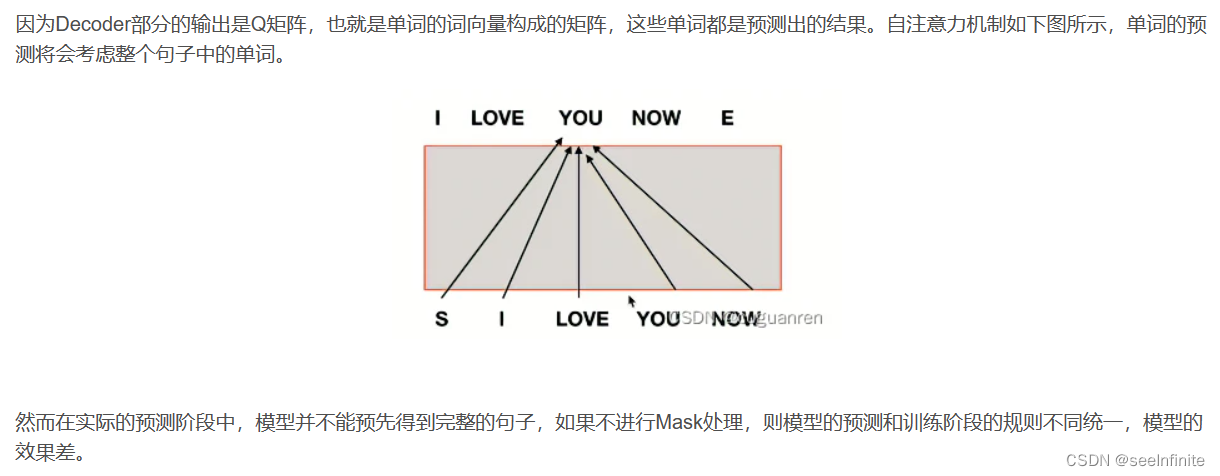
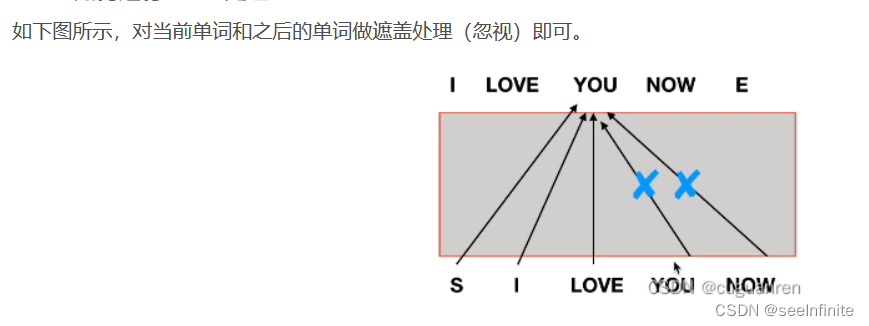
如何进行Mask处理
- decoder第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
相当于每个位置获得encoder所有输入信息和前面已经翻译部分的信息
2. decoder最后有一个 Softmax 层计算下一个翻译单词的概率。
四、Transformer的特点
4.1 并行处理
并行是相对而言的,对比rnn一次只能处理一个字符,transformer中的注意力机制enocder一次可以处理一整句话,不过decoder的时候还是一次处理一个字符。
decoder预测时一次一个字,训练的时候可以一次性计算从头到当前字符的向量。
4.2Encoder与Decoder的联系
注意encoder的输出并没直接作为decoder的直接输入。
encoder的输出包括隐向量以及K /Q /V。
decoders层中相较encoders层多了一个encoder-decoder attention模块,其计算跟多头自注意力计算也类似,只是它的Q是前一个decoder层的输出乘上新的参数矩阵进行转换得来的,K, V 则来自于与encoder的输出乘上新的参数矩阵进行转换得来的。
仔细想想其实可以发现,这里的交互模块就跟seq2seq with attention中的机制一样,目的就在于让Decoder端的单词(token)给予Encoder端对应的单词(token)“更多的关注(attention weight)”
4.3 Decoder的输入与输出

面试题
1.Self-Attention 的时间复杂度是怎么计算的?
Self-Attention时间复杂度:O(n^2,d) ,这里,n是序列的长度,d是embedding的维度。

2.Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
答:请求和键值初始为不同的权重是为了解决可能输入句长与输出句长不一致的问题。并且假如QK维度一致,如果不用Q,直接拿K和K点乘的话,你会发现attention score 矩阵是一个对称矩阵。因为是同样一个矩阵,都投影到了同样一个空间,所以泛化能力很差。
3.Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
答:K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。K和Q使用了不同的W_k, W_Q来计算,可以理解为是在不同空间上的投影。正因为 有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。
4.为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根)
当维度很大时,点积结果会很大,会导致softmax的梯度很小。
假设 Q 和 K 的均值为0,方差为1。它们的矩阵乘积将有均值为0,方差为dk,因此使用dk的平方根被用于缩放,因为,Q 和 K 的矩阵乘积的均值本应该为 0,方差本应该为1,这样可以获得更平缓的softmax。
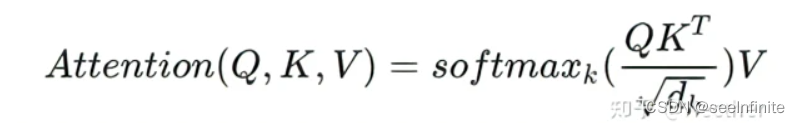
5. 在计算attention score的时候如何对padding做mask操作?
对需要mask的位置设为负无穷,再与attention score进行相加,softmax时负无穷的位置score为0
6. 为什么在进行多头注意力的时候需要对每个head进行降维?
将原有的高维空间转化为多个低维空间并再最后进行拼接,形成同样维度的输出,借此丰富特性信息,降低了计算量
7.大概讲一下Transformer的Encoder模块?
答:输入嵌入-加上位置编码-多个编码器层(每个编码器层包含全连接层,多头注意力层和点式前馈网络层(包含激活函数层))
8.为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?
embedding matrix的初始化方式是xavier init,这种方式的方差是1/embedding size,因此乘以embedding size的开方,使得embedding matrix的方差是1,在这个scale下可能更有利于embedding matrix的收敛。
Xavier init:
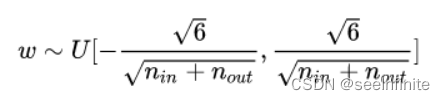
初始化为全0,当有隐藏层时,使用relu等激活函数,会导致梯度梯度为0,参数无法更新
理想的参数分布应该使得,输入输出的空间比较一致,输入稠密,输出稀疏,导致参数更新慢,输入稀疏,输出稠密,导致梯度爆炸,所以要使得输入输出方差尽可能相等
10.你还了解哪些关于位置编码的技术,各自的优缺点是什么?
1.在计算attention score和weighted value时各加入一个可训练的表示相对位置的参数。
2.在生成多头注意力时,把对key来说将绝对位置转换为相对query的位置
3.复数域函数,已知一个词在某个位置的词向量表示,可以计算出它在任何位置的词向量表示。前两个方法是词向量+位置编码,属于亡羊补牢,复数域是生成词向量的时候即生成对应的位置信息。
Transformer和Bert位置编码的区别
Transformer的位置编码是一个固定值,因此只能标记位置,但是不能标记这个位置有什么用。
BERT的位置编码是可学习的Embedding,因此不仅可以标记位置,还可以学习到这个位置有什么用。
BERT选择这么做的原因可能是,相比于Transformer,BERT训练所用的数据量充足,完全可以让模型自己学习。
11.简单讲一下Transformer中的残差结构以及意义。
答:encoder和decoder的self-attention层和ffn层都有残差连接。反向传播的时候缓解造成梯度消失。
12.为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
答:多头注意力层和激活函数层之间。nlp领域认为句子长度不一致,并且各个batch的信息没什么关系,因此只考虑句子内信息的归一化,也就是LN。
13.简答讲一下BatchNorm技术,以及它的优缺点。
答:批归一化是对每一批的数据在进入激活函数前/后进行归一化,可以提高收敛速度,防止过拟合,防止梯度消失,增加网络对数据的敏感度。
优点
1.把输入强行拉到均值0,方差1的标准正态分布区间,使得非线性变换函数的输入值落到输入比较敏感区域,缓解梯度消失问题(因为对于sigmoid和softmax这类激活函数,输入过大或者过小,都会导致梯度很小)
2. 随着网络训练,每层参数变化后,导致后一层的输入发生变化,使得网络在训练中需要不停拟合不同分布的数据,训练难度加大
缺点
batch非常小的情况不适用
不等句长输入不适用
什么时候用?
收敛速度很慢,梯度消失/爆炸无法训练时
也可以在平时用来加速网络训练
BN训练和测试时的参数是一样的嘛?
训练时:是对每一批的训练数据进行归一化,也即用每一批数据的均值和方差。
测试时:比如进行一个样本的预测,就并没有batch的概念,因此,这个时候用的均值和方差是全量训练数据的均值和方差,这个可以通过移动平均法求得。
对于BN,当一个模型训练完成之后,它的所有参数都确定了,包括均值和方差,gamma和bata。
BN训练时为什么不用全量训练集的均值和方差呢?
因为用全量训练集的均值和方差容易过拟合,对于BN,其实就是对每一批数据进行归一化到一个相同的分布,而每一批数据的均值和方差会有一定的差别,而不是用固定的值,这个差别实际上能够增加模型的鲁棒性,也会在一定程度上减少过拟合。
也正是因此,BN一般要求将训练集完全打乱,并用一个较大的batch值,否则,一个batch的数据无法较好得代表训练集的分布,会影响模型训练的效果。
BN的参数和公式
增加两个可训练参数,让本层输入和上一层解耦

14.简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
答:输入嵌入-加上位置编码-多个编码器层(每个编码器层包含全连接层,多头注意力层和点式前馈网络层(包含激活函数层))-多个解码器层(每个编码器层包含全连接层,多头注意力层和点式前馈网络层)-全连接层,使用了relu激活函数
15.Encoder端和Decoder端是如何进行交互的?
答:通过转置encoder_ouput的seq_len维与depth维,进行矩阵两次乘法,即q*kT*v输出即可得到target_len维度的输出
16.Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?
答:Decoder有两层多头注意力,encoder有一层多头注意力,
Decoder的第一层注意力是带mask的注意力,第二层多头注意力与encoder进行交互
17.Transformer的并行化提现在哪个地方?
答:Transformer的并行化主要体现在self-attention模块,在Encoder端Transformer可以并行处理整个序列,并得到整个输入序列经过Encoder端的输出,但是rnn只能从前到后的执行
18.Decoder端可以做并行化吗?
训练的时候可以,预测的时候不可以
19.简单描述一下wordpiece model 和 byte pair encoding,有实际应用过吗?
WordPiece子字级标记算法
而现在大火的bert框架就是使用的WordPiece算法。WordPiece( Schuster和Nakajima,2012年 )最初用于解决日文和韩文语音问题,目前因在BERT中使用而闻名;它在许多方面与BPE相似,不同之处在于它基于似然而不是下一个最高频率对形成一个新的子字,这个似然值表示来两个子字的相关性,WordPiece会合并相关性最高的两个子字;WordPiece底层算法和代码尚未公开,这里简单叙述以下实现步骤。
1. 获得足够大的语料库。
2. 定义所需的子词词汇量。
3. 将单词拆分为字符序列。
4. 用文本中的所有字符初始化词汇表。
5. 根据词汇建立语言模型。
6. 通过将当前词汇表中的两个单元组合以将词汇表增加一个来生成新的子词单元。 从所有可能性中选择新的子词单位,这会在添加到模型时最大程度地增加训练数据的可能性。
7. 重复第5步,直到达到子词词汇量(在第2步中定义),或者似然性增加降至某个阈值以下。
BPE(Basic Periodontal Examination)
由Sennrich等人介绍。 在2015年 ,它迭代地合并最频繁出现的字符或字符序列。 该算法大致是这样工作的:
1. 获得足够大的语料库。
2. 定义所需的子词词汇量。
3. 将单词拆分为字符序列,并附加一个特殊的标记,分别显示单词的开头或单词的结尾词缀/后缀。
4. 计算文本中的序列对及其频率。 例如,('t','h')具有频率X,('h','e')具有频率Y。
5. 根据最频繁出现的序列对生成一个新的子词。 例如,如果('t','h')在该对对中具有最高的频率,则新的子字单元将变为'th'。
6. 从第3步开始重复,直到达到子词词汇量(在第2步中定义)或下一个最高频率对为1。在示例中,语料库中的“ t”,“ h”将替换为“ th”,再次计算,最频繁的对再次获得,并再次合并。
BPE是一种贪婪的确定性算法,不能提供多个细分。 也就是说,对于给定的文本标记化文本始终是相同的。
两者主要区别:
BPE和WordPiece的区别在于如何选择两个子词进行合并。
BPE的词表创建过程:
- 首先初始化词表,词表中包含了训练数据中出现的所有字符。
- 然后两两拼接字符,统计字符对在训练数据中出现的频率。
- 选择出现频率最高的一组字符对加入词表中。
- 反复2和3,直到词表大小达到指定大小。
WordPiece是贪心的最长匹配搜索算法。基本流程:
- 首先初始化词表,词表包含了训练数据中出现的所有字符。
- 然后两两拼接字符,统计字符对加入词表后对语言模型的似然值的提升程度。
- 选择提升语言模型似然值最大的一组字符对加入词表中。
优点:
答“传统词表示方法无法很好的处理未知或罕见的词汇(OOV问题)
传统词tokenization方法不利于模型学习词缀之间的关系
BPE(字节对编码)或二元编码是一种简单的数据压缩形式,其中最常见的一对连续字节数据被替换为该数据中不存在的字节。后期使用时需要一个替换表来重建原始数据。
优点:可以有效地平衡词汇表大小和步数(编码句子所需的token次数)。
缺点:基于贪婪和确定的符号替换,不能提供带概率的多个分片结果。
源码实现
def tokenize(self, text):
"""Tokenizes a piece of text into its word pieces.
This uses a greedy longest-match-first algorithm to perform tokenization
using the given vocabulary.
For example:
input = "unaffable"
output = ["un", "##aff", "##able"]
Args:
text: A single token or whitespace separated tokens. This should have
already been passed through `BasicTokenizer`.
Returns:
A list of wordpiece tokens.
"""
def whitespace_tokenize(text):
"""Runs basic whitespace cleaning and splitting on a peice of text."""
text = text.strip()
if not text:
return []
tokens = text.split()
return tokens
output_tokens = []
for token in whitespace_tokenize(text):
chars = list(token)
if len(chars) > self.max_input_chars_per_word: #max_input_chars_per_word 默认为 100
output_tokens.append(self.unk_token) # 单词长度大于最大长度,用[UNK]表示单词
continue
is_bad = False
start = 0
sub_tokens = []
while start < len(chars):
end = len(chars)
cur_substr = None
while start < end: # 贪心的最长匹配搜索 end从最后一位往前遍历,每移动一位,判断start:end是否存在于词表中
substr = "".join(chars[start:end])
if start > 0: # 若子词不是从位置0开始,前面要加“##”
substr = "##" + substr
if substr in self.vocab:
cur_substr = substr
break
end -= 1
if cur_substr is None: #没有在词表中出现的子词,break
is_bad = True
break
sub_tokens.append(cur_substr)
start = end # 从上一子词的后一位开始下一轮遍历
if is_bad: #没有在词表中出现的子词(单词中的任何区域),用[unk]表示该词:比如“wordfi”,首先确定“word”为子词,后发现“fi”不存在在词表中,则最终用[UNK]表示“wordfi”
output_tokens.append(self.unk_token)
else:
output_tokens.extend(sub_tokens)
return output_tokens
20.Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
LN是为了解决梯度消失的问题,dropout是为了解决过拟合的问题。在embedding后面加LN有利于embedding matrix的收敛。
21.bert的mask为何不学习transformer在attention处进行屏蔽score的技巧?
答:BERT和transformer的目标不一致,bert是语言的预训练模型,需要充分考虑上下文的关系,而transformer主要考虑句子中第i个元素与前i-1个元素的关系。
如果使用 Transformer 对不同类别的数据进行训练,数据集有些类别的数据量很大
(例如有 10 亿条),而大多数类别的数据量特别小(例如可能只有 100 条),此时如何训练
出一个相对理想的 Transformer 模型来对处理不同类别的任务?
重新选择评价指标
准确度在类别均衡的分类任务中并不能有效地评价分类器模型,造成模型失效,甚至会误导业务,造成较大损失。
最典型的评价指标即混淆矩阵Confusion Matrix:使用一个表格对分类器所预测的类别与其真实的类别的样本统计,分别为:TP、FN、FP、TN。包括精确度Precision、召回率Recall、F1得分F1-Score等。
重采样数据集
使用采样sampling策略该减轻数据的不平衡程度。主要有两种方法
- 对小类的数据样本进行采样来增加小类的数据样本个数,即过采样
over-sampling - 对大类的数据样本进行采样来减少该类数据样本的个数,即欠采样
under-sampling
采样算法往往很容易实现,并且其运行速度快,并且效果也不错。在使用采样策略时,可以考虑:
- 对大类下的样本 (超过1万, 十万甚至更多) 进行欠采样,即删除部分样本
- 对小类下的样本 (不足1为甚至更少) 进行过采样,即添加部分样本的副本
- 尝试随机采样与非随机采样两种采样方法
- 对各类别尝试不同的采样比例
- 同时使用过采样与欠采样
BERT
BERT的三个Embedding直接相加会对语义有影响吗?
Embedding的数学本质,就是以one hot为输入的单层全连接,也就是说,世界上本没什么Embedding,有的只是one hot。我们将token,position,segment三者都用one hot表示,然后concat起来,然后才去过一个单层全连接,等价的效果就是三个Embedding相加。原文链接:词向量与Embedding究竟是怎么回事?
在这里想用一个例子再尝试解释一下:
假设 token Embedding 矩阵维度是 [4,768];position Embedding 矩阵维度是 [3,768];segment Embedding 矩阵维度是 [2,768]。假设它的 token one-hot 是[1,0,0,0];它的 position one-hot 是[1,0,0];它的 segment one-hot 是[1,0]。
那这个字最后的 word Embedding,就是上面三种 Embedding 的加和。如此得到的 word Embedding,和concat后的特征:[1,0,0,0,1,0,0,1,0],再过维度为 [4+3+2,768] = [9, 768] 的全连接层,得到的向量其实就是一样的。
再换一个角度理解:
直接将三个one-hot 特征 concat 起来得到的 [1,0,0,0,1,0,0,1,0] 不再是one-hot了,但可以把它映射到三个one-hot 组成的特征空间,空间维度是 432=24 ,那在新的特征空间,这个字的one-hot就是[1,0,0,0,0…] (23个0)。
此时,Embedding 矩阵维度就是 [24,768],最后得到的 word Embedding 依然是和上面的等效,但是三个小Embedding 矩阵的大小会远小于新特征空间对应的Embedding 矩阵大小。
当然,在相同初始化方法前提下,两种方式得到的 word Embedding 可能方差会有差别,但是,BERT还有Layer Norm,会把 Embedding 结果统一到相同的分布。
BERT的三个Embedding相加,本质可以看作一个特征的融合,强大如 BERT 应该可以学到融合后特征的语义信息的。