文章目录
- 节点设置
- 二叉树的深度优先遍历
- 前序遍历
- 中序遍历
- 后序遍历
- 二叉树的广度优先遍历
- 层序遍历
- 节点的个数
- 叶子节点的个数
- 第K层节点的个数
- 值为X的节点
- 树的最大深度
- 翻转二叉树
- 判断两颗二叉树是否相同
- 判断二叉树是否是完全二叉树
- 判断二叉树是否是单值二叉树
- 判断二叉树是否是平衡二叉树
- 判断二叉树是否是对称二叉树
- 判断一棵二叉树是否是另一棵二叉树的子树
- 二叉树的销毁
- 二叉树的深度遍历(接口型题目)
- 前序遍历
- 中序遍历
- 后序遍历
- 二叉树的构建及遍历
本文是对二叉树这种数据结构基本操作与部分练习题的总结,内容庞大、详细、易懂,是你学习路上不容错过的优质博客!
节点设置
既然是链式二叉树,那必须得有自己的结点类型,以下是链式二叉树结点类型的定义,为了避免过多重复的代码,下面的问题都统一使用该结点类型。
代码示例:
typedef char BTDataType;//结点中存储的元素类型(以char为例)
typedef struct BTNode
{
BTDataType data;//结点中存储的元素类型
struct BTNode* left;//左指针域(指向左孩子)
struct BTNode* right;//右指针域(指向右孩子)
}BTNode;
二叉树的深度优先遍历
图片示例:
前序遍历
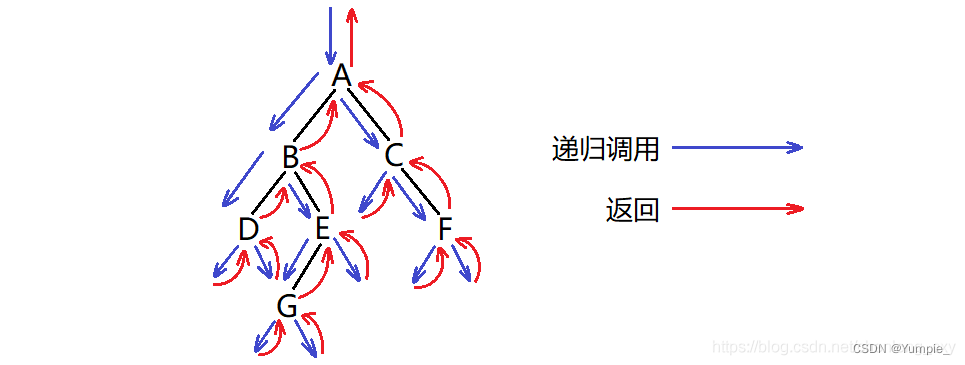
前序遍历,又叫先根遍历。
遍历顺序:根 -> 左子树 -> 右子树
图片示例:

代码示例:
//前序遍历
void BinaryPrevOrder(BTNode* root)
{
if (root == NULL)
{
return;
}
//根->左子树->右子树
printf("%c ", root->data);
BinaryPrevOrder(root->left);
BinaryPrevOrder(root->right);
}
中序遍历
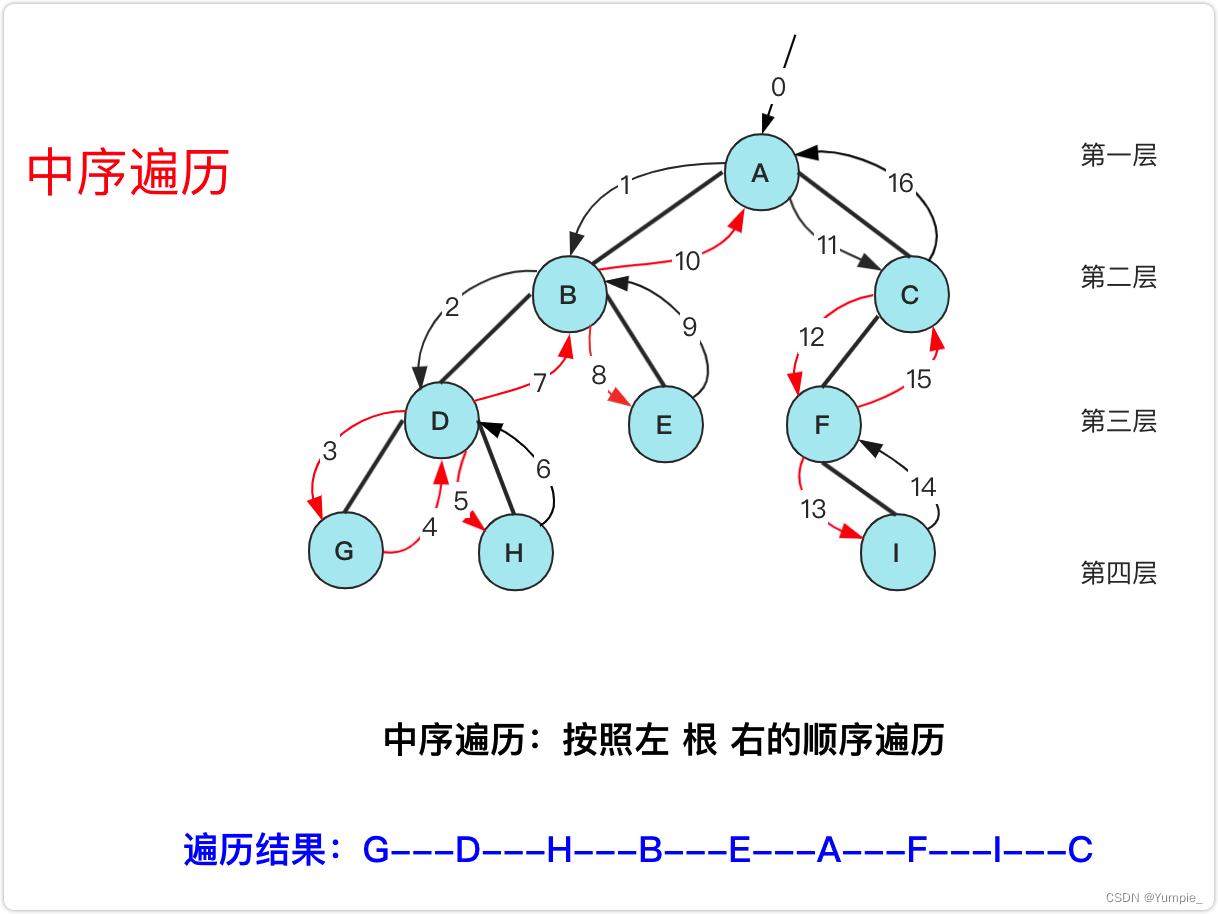
中序遍历,又叫中根遍历。
遍历顺序:左子树 -> 根 -> 右子树
图片示例:
代码示例:
void BinaryInOrder(BTNode* root)
{
if (root == NULL)
{
return;
}
//左子树->根->右子树
BinaryInOrder(root->left);
printf("%c ", root->data);
BinaryInOrder(root->right);
}
后序遍历
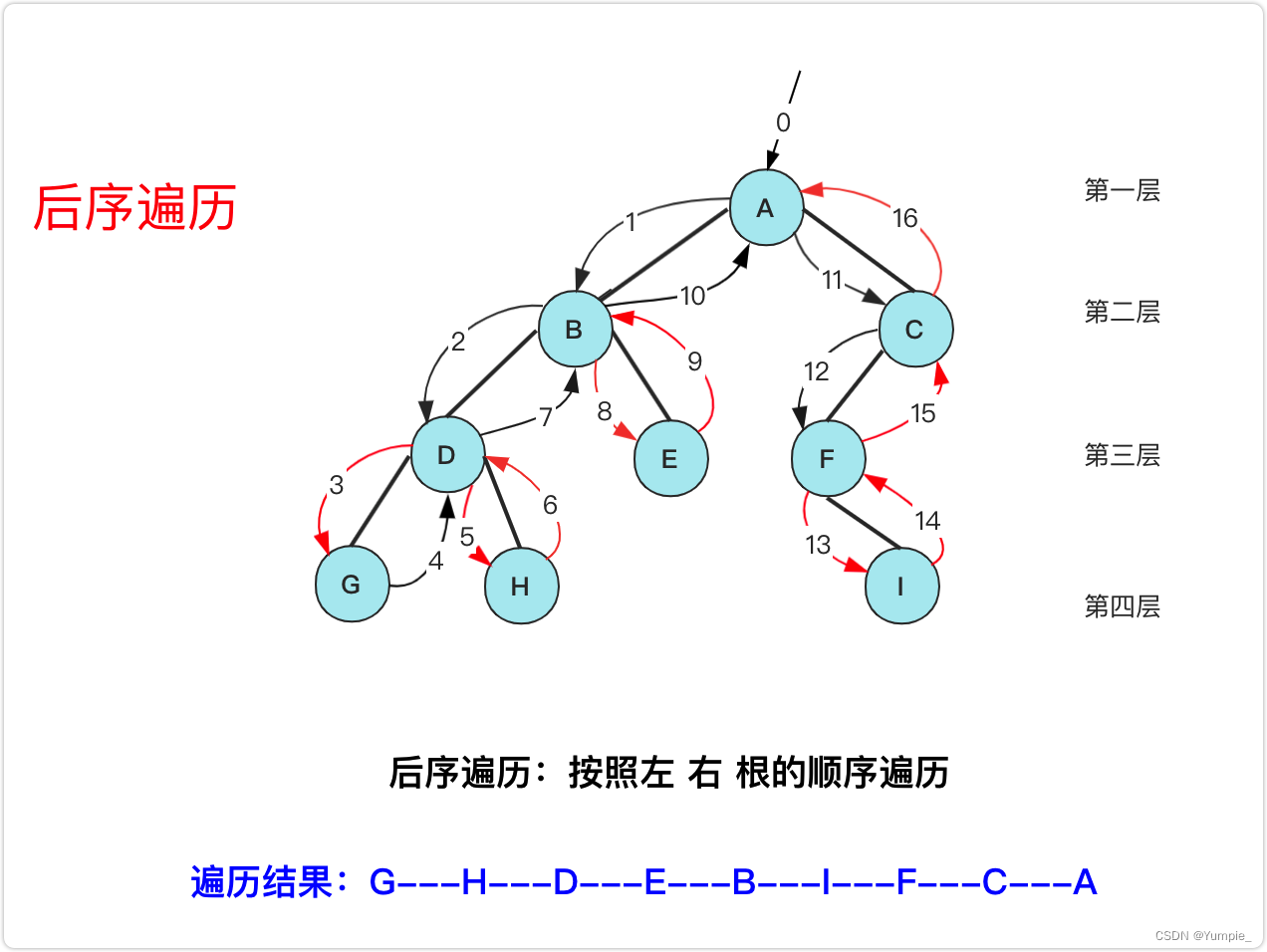
后序遍历,又叫后根遍历。
遍历顺序:左子树 -> 右子树 -> 根
图片示例:
代码示例:
//后序遍历
void BinaryPostOrder(BTNode* root)
{
if (root == NULL)
{
return;
}
//左子树->右子树->根
BinaryPostOrder(root->left);
BinaryPostOrder(root->right);
printf("%c ", root->data);
}
二叉树的广度优先遍历
层序遍历
层序遍历,自上而下,从左往右逐层访问树的结点的过程就是层序遍历。
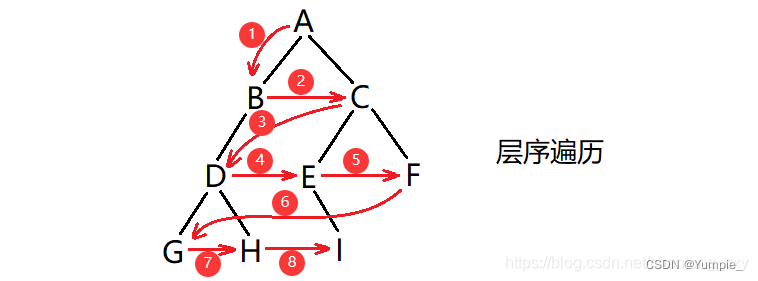
思路(借助一个队列):
1.先把根入队列,然后开始从队头出数据。
2.出队头的数据,把它的左孩子和右孩子依次从队尾入队列(NULL不入队列)。
3.重复进行步骤2,直到队列为空为止。
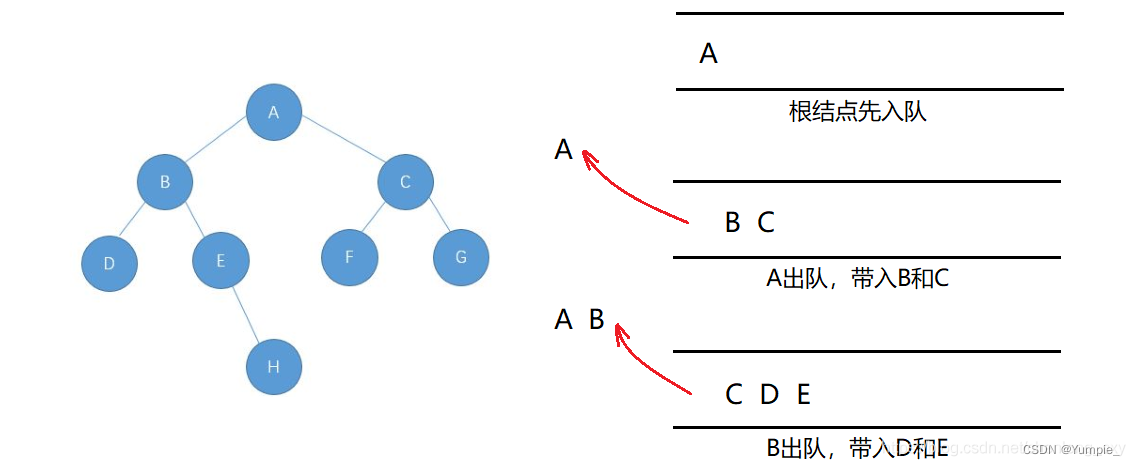
特点:借助队列先进先出的性质,上一层数据出队列的时候带入下一层数据。
代码示例:
//层序遍历
void BinaryLevelOrder(BTNode* root)
{
Queue q;
QueueInit(&q);//初始化队列
if (root != NULL)
QueuePush(&q, root);
while (!QueueEmpty(&q))//当队列不为空时,循环继续
{
BTNode* front = QueueFront(&q);//读取队头元素
QueuePop(&q);//删除队头元素
printf("%c ", front->data);//打印出队的元素
if (front->left)
{
QueuePush(&q, front->left);//出队元素的左孩子入队列
}
if (front->right)
{
QueuePush(&q, front->right);//出队元素的右孩子入队列
}
}
QueueDestroy(&q);//销毁队列
}
节点的个数
求解树的结点总数时,可以将问题拆解成子问题:
1.若为空,则结点个数为0。
2.若不为空,则结点个数 = 左子树结点个数 + 右子树结点个数 + 1(自己)。
代码示例:
//结点的个数
int BinaryTreeSize(BTNode* root)
{
//结点个数 = 左子树的结点个数 + 右子树的结点个数 + 自己
return root == NULL ? 0 : BinaryTreeSize(root->left) + BinaryTreeSize(root->right) + 1;
}
叶子节点的个数
子问题拆解:
1.若为空,则叶子结点个数为0。
2.若结点的左指针和右指针均为空,则叶子结点个数为1。
3.除上述两种情况外,说明该树存在子树,其叶子结点个数 = 左子树的叶子结点个数 + 右子树的叶子结点个数。
代码示例:
//叶子结点的个数
int BinaryTreeLeafSize(BTNode* root)
{
if (root == NULL)//空树无叶子结点
return 0;
if (root->left == NULL&&root->right == NULL)//是叶子结点
return 1;
//叶子结点的个数 = 左子树的叶子结点个数 + 右子树的叶子结点个数
return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);
}
第K层节点的个数
思路:
相对于根结点的第k层结点的个数 = 相对于以其左孩子为根的第k-1层结点的个数 + 相对于以其右孩子为根的第k-1层结点的个数。

代码示例:
//第k层结点的个数
int BinaryTreeKLevelSize(BTNode* root, int k)
{
if (k < 1 || root == NULL)//空树或输入k值不合法
return 0;
if (k == 1)//第一层结点个数
return 1;
//相对于父结点的第k层的结点个数 = 相对于两个孩子结点的第k-1层的结点个数之和
return BinaryTreeKLevelSize(root->left, k - 1) + BinaryTreeKLevelSize(root->right, k - 1);
}
值为X的节点
子问题:
1.先判断根结点是否是目标结点。
2.再去左子树中寻找。
3.最后去右子树中寻找。
代码示例:
//查找值为x的结点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{
if (root == NULL)//空树
return NULL;
if (root->data == x)//先判断根结点
return root;
BTNode* lret = BinaryTreeFind(root->left, x);//在左子树中找
if (lret)
return lret;
BTNode* rret = BinaryTreeFind(root->right, x);//在右子树中找
if (rret)
return rret;
return NULL;//根结点和左右子树中均没有找到
}
树的最大深度
子问题:
1.若为空,则深度为0。
2.若不为空,则树的最大深度 = 左右子树中深度较大的值 + 1。
代码示例:
//求较大值
int Max(int a, int b)
{
return a > b ? a : b;
}
//树的最大深度
int BinaryTreeMaxDepth(BTNode* root)
{
if (root == NULL)//空树,深度为0
return 0;
//树的最大深度 = 左右子树中深度较大的值 + 1
return Max(BinaryTreeMaxDepth(root->left), BinaryTreeMaxDepth(root->right)) + 1;
}
翻转二叉树
如何翻转一棵二叉树呢?我们可以先观察一棵二叉树在翻转前后的变化:
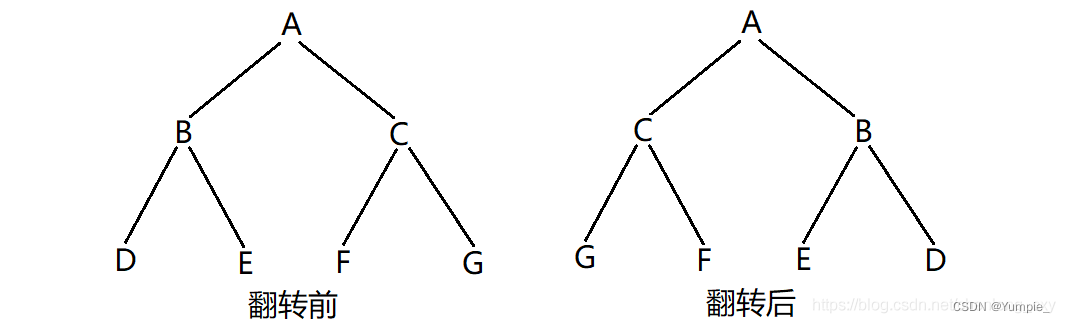
通过观察,可以发现:翻转后,根的左右子树的位置交换了;根的孩子的左右子树的位置也交换了;根的孩子的孩子的左右子树的位置也交换了…
思路:
1.翻转左子树。
2.翻转右子树。
3.交换左右子树的位置。
代码示例:
//翻转二叉树
BTNode* invertTree(BTNode* root)
{
if (root == NULL)//根为空,直接返回
return NULL;
BTNode* left = invertTree(root->left);//翻转左子树
BTNode* right = invertTree(root->right);//翻转右子树
//左右子树位置交换
root->left = right;
root->right = left;
return root;
}
判断两颗二叉树是否相同
判断两棵二叉树是否相同,也可以将其分解为子问题:
1.比较两棵树的根是否相同。
2.比较两根的左子树是否相同。
3.比较两根的右子树是否相同。
代码示例:
//判断两棵二叉树是否相同
bool isSameTree(BTNode* p, BTNode* q)
{
if (p == NULL&&q == NULL)//两棵树均为空,则相同
return true;
if (p == NULL || q == NULL)//两棵树中只有一棵树为空,则不相同
return false;
if (p->data != q->data)//两棵树根的值不同,则不相同
return false;
return isSameTree(p->left, q->left) && isSameTree(p->right, q->right);//两棵树的左子树相同并且右子树相同,则这两棵树相同
}
判断二叉树是否是完全二叉树
判断二叉树是否是完全二叉树的方法与二叉树的层序遍历类似,但又有一些不同。
思路(借助一个队列):
1.先把根入队列,然后开始从队头出数据。
2.出队头的数据,把它的左孩子和右孩子依次从队尾入队列(NULL也入队列)。
3.重复进行步骤2,直到读取到的队头数据为NULL时停止入队列。
4.检查队列中剩余数据,若全为NULL,则是完全二叉树;若其中有一个非空的数据,则不是完全二叉树。
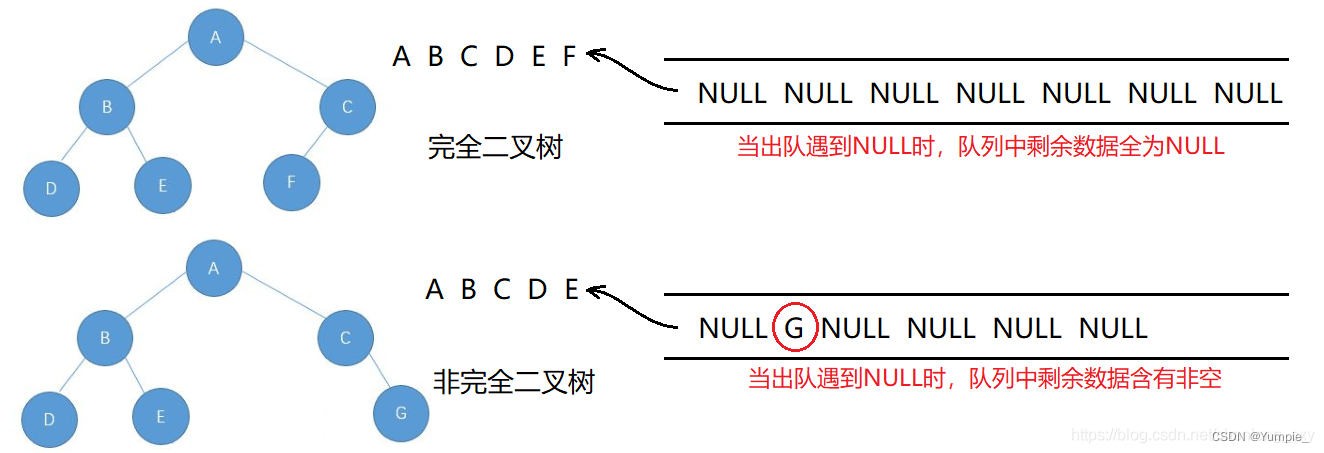
代码示例:
//判断二叉树是否是完全二叉树
bool isCompleteTree(BTNode* root)
{
Queue q;
QueueInit(&q);//初始化队列
if (root != NULL)
QueuePush(&q, root);
while (!QueueEmpty(&q))//当队列不为空时,循环继续
{
BTNode* front = QueueFront(&q);//读取队头元素
QueuePop(&q);//删除队头元素
if (front == NULL)//当读取到空指针时,停止入队操作
break;
QueuePush(&q, front->left);//出队元素的左孩子入队列
QueuePush(&q, front->right);//出队元素的右孩子入队列
}
while (!QueueEmpty(&q))//读取队列中剩余的数据
{
BTNode* front = QueueFront(&q);
QueuePop(&q);
if (front != NULL)//若队列中存在非空指针,则不是完全二叉树
{
QueueDestroy(&q);//销毁队列
return false;
}
}
QueueDestroy(&q);//销毁队列
return true;//若队列中全是空指针,则是完全二叉树
}
判断二叉树是否是单值二叉树
单值二叉树,所有结点的值都相同的二叉树即为单值二叉树,判断某一棵二叉树是否是单值二叉树的一般步骤如下:
1.判断根的左孩子的值与根结点是否相同。
2.判断根的右孩子的值与根结点是否相同。
3.判断以根的左孩子为根的二叉树是否是单值二叉树。
4.判断以根的右孩子为根的二叉树是否是单值二叉树。
若满足以上情况,则是单值二叉树。
注:空树也是单值二叉树。
代码示例:
//判断二叉树是否是单值二叉树
bool isUnivalTree(BTNode* root)
{
if (root == NULL)//根为空,是单值二叉树
return true;
if (root->left && root->left->data != root->data)//左孩子存在,但左孩子的值不等于根的值
return false;
if (root->right && root->right->data != root->data)//右孩子存在,但右孩子的值不等于根的值
return false;
return isUnivalTree(root->left) && isUnivalTree(root->right);//左子树是单值二叉树并且右子树是单值二叉树
}
判断二叉树是否是平衡二叉树
若一棵二叉树的每个结点的左右两个子树的高度差的绝对值不超过1,则称该树为平衡二叉树。
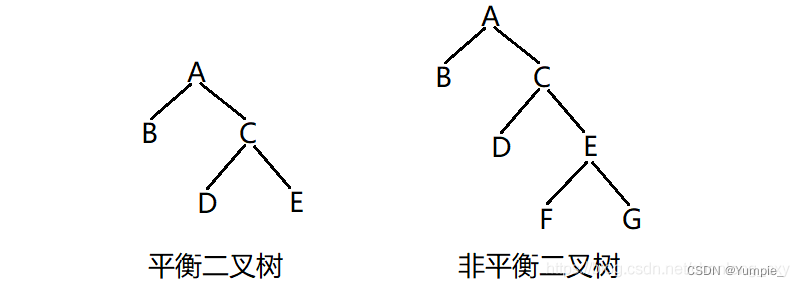
思路一:
子问题:
1.求出左子树的深度。
2.求出右子树的深度。
3.若左子树与右子树的深度差的绝对值不超过1,并且左右子树也是平衡二叉树,则该树是平衡二叉树。
代码示例:
//判断二叉树是否是平衡二叉树
bool isBalanced(BTNode* root)
{
if (root == NULL)//空树是平衡二叉树
return true;
int leftDepth = BinaryTreeMaxDepth(root->left);//求左子树的深度
int rightDepth = BinaryTreeMaxDepth(root->right);//求右子树的深度
//左右子树高度差的绝对值不超过1 && 其左子树是平衡二叉树 && 其右子树是平衡二叉树
return abs(leftDepth - rightDepth) < 2 && isBalanced(root->left) && isBalanced(root->right);
}
时间复杂度:O(N^2)
思路二:
采用后序遍历:
1.从叶子结点处开始计算每课子树的高度。(每棵子树的高度 = 左右子树中高度的较大值 + 1)
2.先判断左子树是否是平衡二叉树。
3.再判断右子树是否是平衡二叉树。
4.若左右子树均为平衡二叉树,则返回当前子树的高度给上一层,继续判断上一层的子树是否是平衡二叉树,直到判断到根为止。(若判断过程中,某一棵子树不是平衡二叉树,则该树也就不是平衡二叉树了)
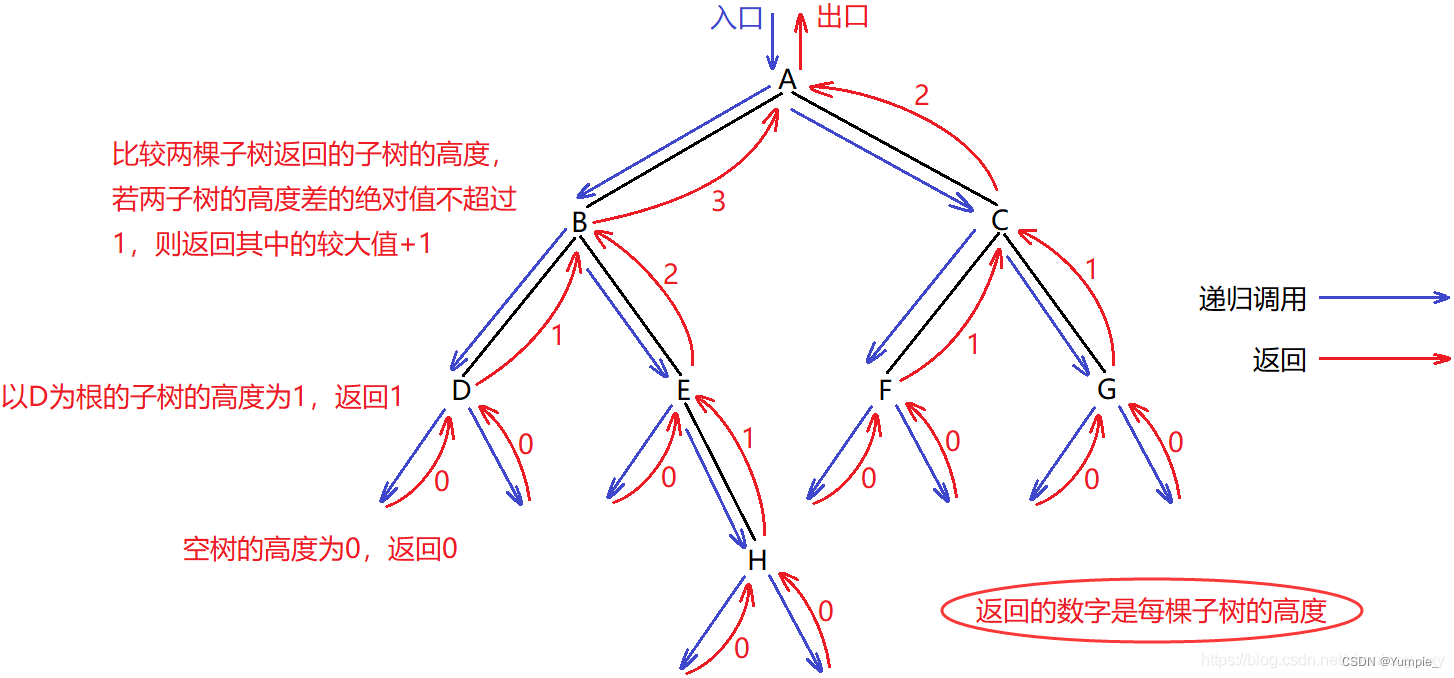
代码示例:
bool _isBalanced(BTNode* root, int* ph)
{
if (root == NULL)//空树是平衡二叉树
{
*ph = 0;//空树返回高度为0
return true;
}
//先判断左子树
int leftHight = 0;
if (_isBalanced(root->left, &leftHight) == false)
return false;
//再判断右子树
int rightHight = 0;
if (_isBalanced(root->right, &rightHight) == false)
return false;
//把左右子树的高度中的较大值+1作为当前树的高度返回给上一层
*ph = Max(leftHight, rightHight) + 1;
return abs(leftHight - rightHight) < 2;//平衡二叉树的条件
}
//判断二叉树是否是平衡二叉树
bool isBalanced(BTNode* root)
{
int hight = 0;
return _isBalanced(root, &hight);
}
时间复杂度:O(N)
判断二叉树是否是对称二叉树
对称二叉树,这里所说的对称是指镜像对称:

要判断某二叉树是否是对称二叉树,则判断其根结点的左子树和右子树是否是镜像对称即可。因为是镜像对称,所以左子树的遍历方式和右子树的遍历方式是不同的,准确来说,左子树和右子树的遍历是反方向进行的。
如下图:
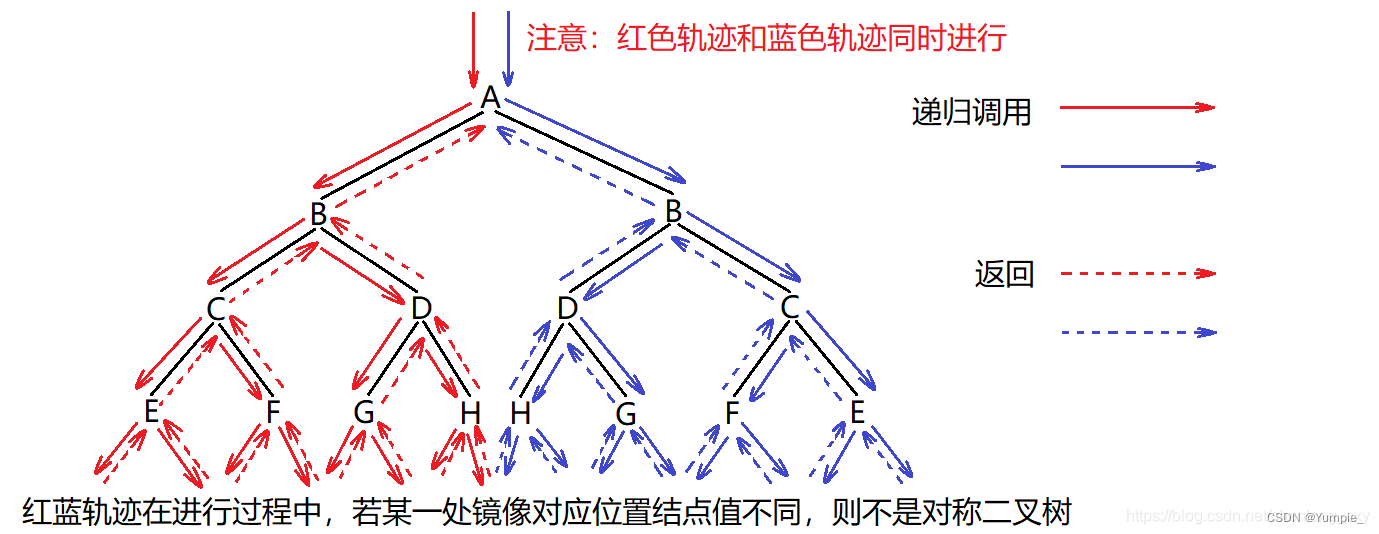
图中红蓝轨迹同时进行,同时结束。若在遍历过程中发现镜像对称的某两个结点值不同,则无需继续遍历,此时已经可以判断该树不是对称二叉树,只有当红蓝轨迹成功遍历完毕后,才能断定该树是对称二叉树。
代码示例:
//判断镜像位置是否相等
bool travel(BTNode* left, BTNode* right)
{
if (left == NULL&&right == NULL)//红蓝轨迹同时遍历到NULL,函数返回
return true;
if (left == NULL || right == NULL)//红蓝指针中,一个为NULL,另一个不为NULL,即镜像不相等
return false;
if (left->data != right->data)//红蓝指针指向的结点值不同,即镜像不相等
return false;
//子问题:左子树遍历顺序:先左后右,右子树遍历顺序:先右后左。若两次遍历均成功,则是对称二叉树
return travel(left->left, right->right) && travel(left->right, right->left);
}
//对称二叉树
bool isSymmetric(BTNode* root)
{
if (root == NULL)//空树是对称二叉树
return true;
return travel(root->left, root->right);//判断镜像位置是否相等
}
判断一棵二叉树是否是另一棵二叉树的子树
判断 subRoot 是否是二叉树 root 的子树,即检验 root 中是否包含和 subRoot 具有相同结构和结点值的子树,其中 root 和 subRoot 均为非空二叉树。
如下图中,subRoot就是root的一棵子树:
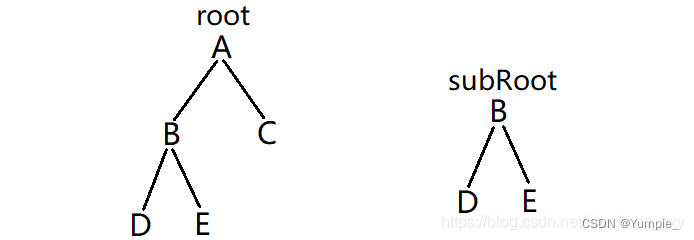
思路:
依次判断以 root 中某一个结点为根的子树是否与subRoot相同。
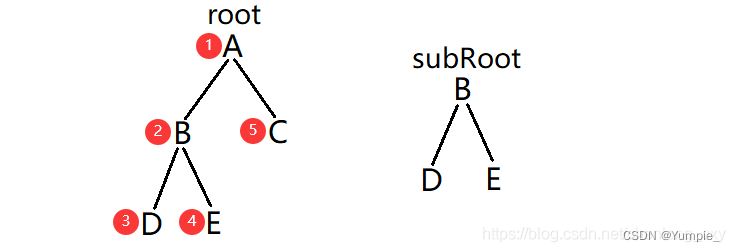
实际上,当发现 root 中的某一个子树与 subRoot 相匹配时,便不再继续比较其他子树,所以图中只会比较到序号2就结束比较了。
代码示例:
//比较以root和subRoot为根结点的两棵树是否相等
bool Compare(BTNode* root, BTNode* subRoot)
{
if (root == NULL&&subRoot == NULL)//均为空树,相等
return true;
if (root == NULL || subRoot == NULL)//一个为空另一个不为空,不相等
return false;
if (root->data != subRoot->data)//结点的值不同,不相等
return false;
//比较两棵树的子结点
return Compare(root->left, subRoot->left) && Compare(root->right, subRoot->right);
}
//另一个树的子树
bool isSubtree(BTNode* root, BTNode* subRoot)
{
if (root == NULL)//空树,不可能是与subRoot相同(subRoot非空)
return false;
if (Compare(root, subRoot))//以root和subRoot为根,开始比较两棵树是否相同
return true;
//判断root的左孩子和右孩子中是否有某一棵子树与subRoot相同
return isSubtree(root->left, subRoot) || isSubtree(root->right,subRoot);
}
二叉树的销毁
二叉树的销毁,与其他数据结构的销毁类似,都是一边遍历一边销毁。但是二叉树需要注意销毁结点的顺序,遍历时我们应该选用后序遍历,也就是说,销毁顺序应该为:左子树->右子树->根。
我们必须先将左右子树销毁,最后再销毁根结点,若先销毁根结点,那么其左右子树就无法找到,也就无法销毁了。
代码示例:
//二叉树销毁
void BinaryTreeDestroy(BTNode* root)
{
if (root == NULL)
return;
BinaryTreeDestroy(root->left);//销毁左子树
BinaryTreeDestroy(root->right);//销毁右子树
free(root);//释放根结点
}
二叉树的深度遍历(接口型题目)
注意,接下来所要说的深度遍历与前面有所不同,前面说到的深度遍历是将一棵二叉树遍历,并将遍历结果打印屏幕上(较简单)。而下面说到的深度遍历是将一棵二叉树进行遍历,并将遍历结果存储到一个动态开辟的数组中,将数组作为函数返回值进行返回。
思路:
1.首先计算二叉树中结点的个数,便于确定动态开辟的数组的大小。
2.遍历二叉树,将遍历结果存储到数组中。
3.返回数组。
前序遍历
代码示例:
//求树的结点个数
int TreeSize(BTNode* root)
{
return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;
}
//将树中结点的值放入数组
void preorder(BTNode* root, int* arr, int* pi)
{
if (root == NULL)//根结点为空,直接返回
return;
arr[(*pi)++] = root->data;//先将根结点的值放入数组
preorder(root->left, arr, pi);//再将左子树中结点的值放入数组
preorder(root->right, arr, pi);//最后将右子树中结点的值放入数组
}
//前序遍历
int* preorderTraversal(BTNode* root, int* returnSize)
{
*returnSize = TreeSize(root);//值的个数等于结点的个数
int* arr = (int*)malloc(sizeof(int)*(*returnSize));
int i = 0;
preorder(root, arr, &i);//将树中结点的值放入数组
return arr;
}
中序遍历
代码示例:
//求树的结点个数
int TreeSize(BTNode* root)
{
return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;
}
//将树中结点的值放入数组
void inorder(BTNode* root, int* arr, int* pi)
{
if (root == NULL)//根结点为空,直接返回
return;
inorder(root->left, arr, pi);//先将左子树中结点的值放入数组
arr[(*pi)++] = root->data;//再将根结点的值放入数组
inorder(root->right, arr, pi);//最后将右子树中结点的值放入数组
}
//中序遍历
int* inorderTraversal(BTNode* root, int* returnSize)
{
*returnSize = TreeSize(root);//值的个数等于结点的个数
int* arr = (int*)malloc(sizeof(int)*(*returnSize));
int i = 0;
preorder(root, arr, &i);//将树中结点的值放入数组
return arr;
}
后序遍历
代码示例:
//求树的结点个数
int TreeSize(BTNode* root)
{
return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;
}
//将树中结点的值放入数组
void postorder(BTNode* root, int* arr, int* pi)
{
if (root == NULL)//根结点为空,直接返回
return;
postorder(root->left, arr, pi);//先将左子树中结点的值放入数组
postorder(root->right, arr, pi);//再将右子树中结点的值放入数组
arr[(*pi)++] = root->data;//最后将根结点的值放入数组
}
//后序遍历
int* postorderTraversal(BTNode* root, int* returnSize)
{
*returnSize = TreeSize(root);//值的个数等于结点的个数
int* arr = (int*)malloc(sizeof(int)*(*returnSize));
int i = 0;
preorder(root, arr, &i);//将树中结点的值放入数组
return arr;
}
二叉树的构建及遍历
编一个程序,读入用户输入的一串先序遍历字符串,根据此字符串建立一个二叉树(以指针方式存储)。 例如如下的先序遍历字符串: ABC##DE#G##F### 其中“#”表示的是空格,空格字符代表空树。建立起此二叉树以后,再对二叉树进行中序遍历,输出遍历结果。
输入描述:
输入包括1行字符串,长度不超过100。
输出描述:
可能有多组测试数据,对于每组数据,输出将输入字符串建立二叉树后中序遍历的序列,每个字符后面都有一个空格。每个输出结果占一行。
思路:
根据前序遍历所得到的字符串,我们可以很容易地将其对应的二叉树画出来。
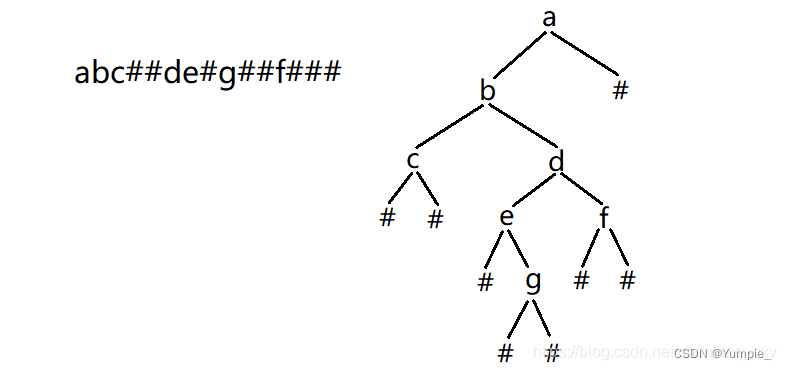
其实很容易发现其中的规律,我们可以依次从字符串读取字符:
1.若该字符不是#,则我们先构建该值的结点,然后递归构建其左子树和右子树。
2.若该字符是#,则说明该位置之下不能再构建结点了,返回即可。
构建完树后,使用中序遍历打印二叉树的数据即可。
代码示例:
#include <stdio.h>
#include <stdlib.h>
typedef struct TreeNode
{
struct TreeNode* left;
struct TreeNode* right;
char data;
}TreeNode;
//创建树
TreeNode* CreateTree(char* str, int* pi)
{
if(str[*pi] == '#')//
{
(*pi)++;
return NULL;
}
//不是NULL,构建结点
TreeNode* root = (TreeNode*)malloc(sizeof(TreeNode));
root->left = NULL;
root->right = NULL;
root->data = str[*pi];
(*pi)++;
//递归构建左子树
root->left = CreateTree(str, pi);
//递归构建右子树
root->right = CreateTree(str, pi);
return root;
}
//中序遍历
void Inorder(TreeNode* root)
{
if(root == NULL)
return;
Inorder(root->left);
printf("%c ", root->data);
Inorder(root->right);
}
int main()
{
char str[100];
scanf("%s", str);
int i = 0;
TreeNode* root = CreateTree(str, &i);
Inorder(root);
return 0;
}
如此明了清晰的详解过程,希望各位看官能够一键三连哦💕