在JAVA语言层面,怎么保证线程安全?
有序性:使用happens-before原则
可见性:可以使用 volatile 关键字来保证,不仅如此,volatile 还能起到禁止指令重排的作用;另外, synchronized 和 final 这俩关键字也能保证可见性。
原子性:可以使用锁 和 java.util.concurrent.atomic 包中的原子类来保证。
0、三大关键字:
1、CAS算法:
首先,大家应该已经知道,JMM 中不仅有主内存,每个线程还有各自的本地内存。每个线程会先更新自己的本地内存,然后再同步更新到主内存。
那如果多个线程都想要同步更新到主内存怎么办呢?
CAS 就是用来保证这种情况下的线程安全的。当多个线程尝试使用 CAS 同时更新主内存中的同一个变量时,只有一个线程可以成功更新变量的值,其他的线程都会失败,失败的线程并不会挂起,而是会自旋重试。
1.1 具体来说,CAS(Compare And Set):比较并替换,该算法中有重要的三个操作数:
- 需要读写的主内存位置(某个变量的值)
- 该变量原来应该有的值(检查值有没有发生变化)
- 线程想要把这个变量更新为哪个值
1.2 首先线程先读取需要读写的某个变量的值,然后比较当前该变量的值和该变量原来应该有的值:
- 如果当前该变量的值与原来应该有的值相匹配,那么这个线程就可以将该变量更新为新值
- 如果当前该变量的值与原来应该有的值不匹配,那就更新失败,开始自旋重试。
1.3 听起来好像有点拗口,其实总结一下就是三步走:
- 读取
- 比较
- 交换
1.4 CAS 存在的三大问题
看起来 CAS 好像很不错,高效地解决了并发问题,但事实上,CAS 仍然存在三大问题:
- ABA 问题
- 循环时间长开销大
- 只能保证一个共享变量的原子操作
2、AQS(队列同步器):
3、Lock接口:
Java 有两套锁实现,一个就是原生的 synchronized 关键字,另一个就是实现了 Lock 接口的类比如 ReentrantLock。那么既然有了前者,为什么还大费力气整出一套新的实现呢?
对于 synchronized 来说,它把锁的获取和释放操作完全隐藏起来了,进入同步块的时候自动尝试去获取锁,退出同步块时候的自动释放锁,也就是说获取锁操作一定是在释放锁操作之前的。
使用 Lock 那样手动获取和释放锁的方式了。
Lock 接口概览
Lock 其实也没啥神秘的,整个接口就 6 个方法:
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}
-
lock():尝试获取锁,获取锁成功后返回
-
lockInterruptibly():可中断的获取锁。所谓可中断的意思就是,在锁的获取过程中可以中断当前线程
-
tryLock():尝试非阻塞的获取锁。不同于 lock() 方法在锁获取成功后再返回,该方法被调用后就会立即返回。如果最终获取锁成功返回 true,否则返回 false
-
tryLock(long time, TimeUnit unit):超时的获取锁。如果在指定时间内未获取到锁,则返回 false
-
unlock():释放锁
-
newCondition():当前线程只有获得了锁,才能调用 Condition 接口的 await 方法。Condition 接口本文就先不做详细赘述了
4、并发集合:
与现代的数据结构类库的常见情况一样,Java 集合类也将接口与实现分离,这些接口和实现类都位于 java.util 包下。按照其存储结构集合可以分为两大类:
- 单列集合 Collection
- 双列集合 Map
Collection 接口
单列集合 java.util.Collection:元素是孤立存在的,向集合中存储元素采用一个个元素的方式存储。
1)List 的特点是元素有序、可重复。注意,这里所谓有序的意思,并不是指集合中按照元素值的大小进行有序排序,而是说,List 会按照元素添加的顺序来进行存储,保证插入的顺序和存储的顺序一致。
List 接口的常用实现类有:
- ArrayList:底层数据结构是数组,线程不安全
- LinkedList:底层数据结构是链表,线程不安全
2)Set 接口在方法签名上与 Collection 接口其实是完全一样的,只不过在方法的说明上有更严格的定义,最重要的特点是他拒绝添加重复元素,不能通过整数索引来访问,并且元素无序。同样的,所谓无序也就是指 Set 并不会按照元素添加的顺序来进行存储,插入的顺序和存储的顺序是不一致的。其常用实现类有:
- HashSet:底层基于 HashMap 实现,采用 HashMap 来保存元素
- LinkedHashSet:LinkedHashSet 是 HashSet 的子类,并且其底层是通过 LinkedHashMap 来实现的。
3)Queue 这个接口其实用的不多,可以把队列看作一种遵循 FIFO 原则的特殊线性表(事实上,LinkedList 也确实实现了 DeQueue 接口),Queue 接口是单向队列,而 DeQue 接口继承自 Queue,它是双向队列。
Map 接口
双列集合 java.util.Map:元素是成对存在的。每个元素由键(key)与值(value)两部分组成,通过键可以找对所对应的值。显然这个双列集合解决了数组无法存储映射关系的痛点。另外,需要注意的是,Map 不能包含重复的键,值可以重复;并且每个键只能对应一个值。
来看 Map 接口的继承体系图:

Map 有两个重要的实现类,HashMap 和 LinkedHashMap :
① HashMap:可以说 HashMap 不背到滚瓜烂熟不敢去面试,这里简单说下它的底层结构吧。JDK 1.8 之前 HashMap 底层由数组加链表实现,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法” 解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间(注意:将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)。
② LinkedHashMap:HashMap 的子类,可以保证元素的存取顺序一致(存进去时候的顺序是多少,取出来的顺序就是多少,不会因为 key 的大小而改变)。
LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构,即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
线程安全的集合总览
J.U.C 为每一类集合都提供了线程安全的实现,等会往下看各位就会发现很多线程安全的集合都是以 Concurrent 或者 CopyOnWrite 开头的。这里先给大家解释下:
以 Concurrent 开头的集合类通常采用某些比较复杂的算法(以 ConcurrentHashMap 为首,相信各位八股文都已经背恶心了)来保证永远不会锁住整个集合,因此在并发写入时有较好的性能。
而以 CopyOnWrite(COW)开头的集合类采用了 写时复制 的思想来支持并发读。
具体来说,就是我们往一个 COW 集合中添加元素的时候,底层并不是直接向当前的集合中添加,而是先将当前的集合 copy 出一个新的副本,然后在这个副本李添加元素,添加完元素之后,再将原集合的引用指向这个副本。这样做的好处是我们可以对 COW 集合进行并发的读,而不需要执行加锁操作。
所以,CopyOnWrite 集合其实是一种读写分离的集合。
下面我们来捋一下具体都有哪些线程安全的集合:
Collection 接口
先来一张

1)List:
- Vector(这个没啥好说的,它就是把 ArrayList 中所有的方法统统加上 synchronized )
- CopyOnWriteArrayList
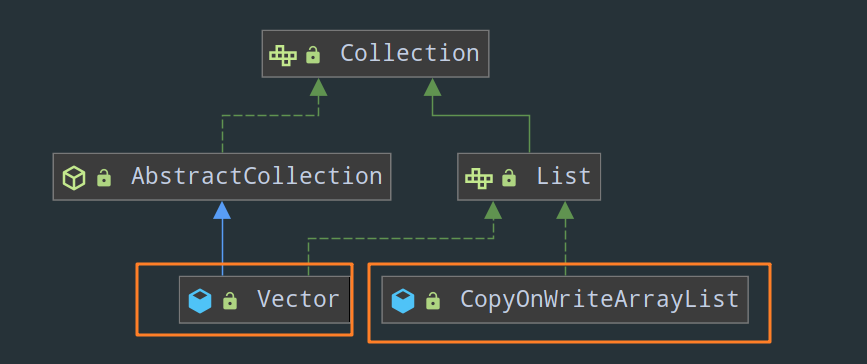
2)Set:
CopyOnWriteArraySetConcurrentSkipListSet
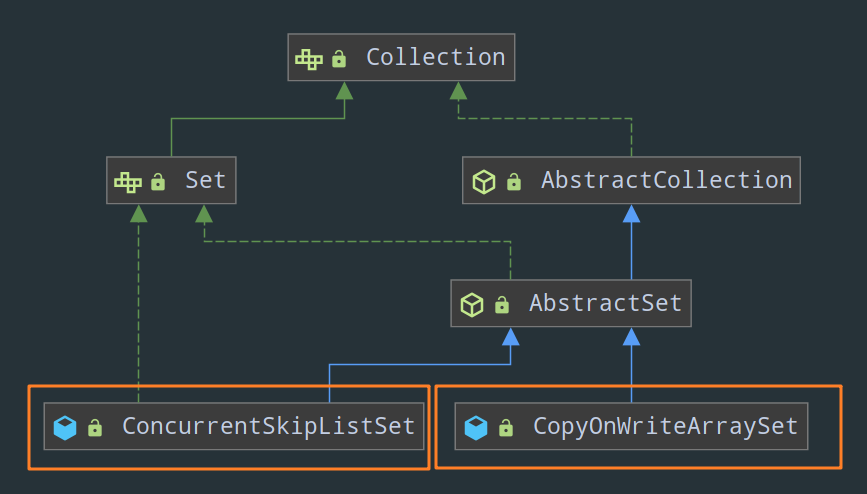
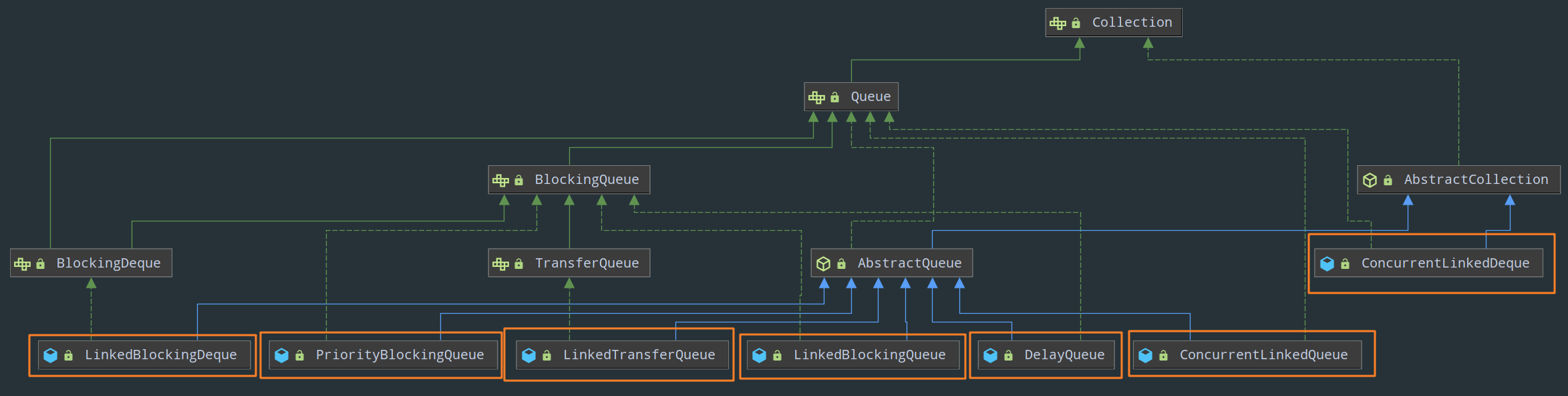
3)Queue:
- BlockingQueue 接口
LinkedBlockingQueue
DelayQueue
PriorityBlockingQueue
ConcurrentLinkedQueue
- TransferQueue 接口
LinkedTransferQueue
- BlockingDeque 接口
LinkedBlockingDeque
ConcurrentLinkedDeque
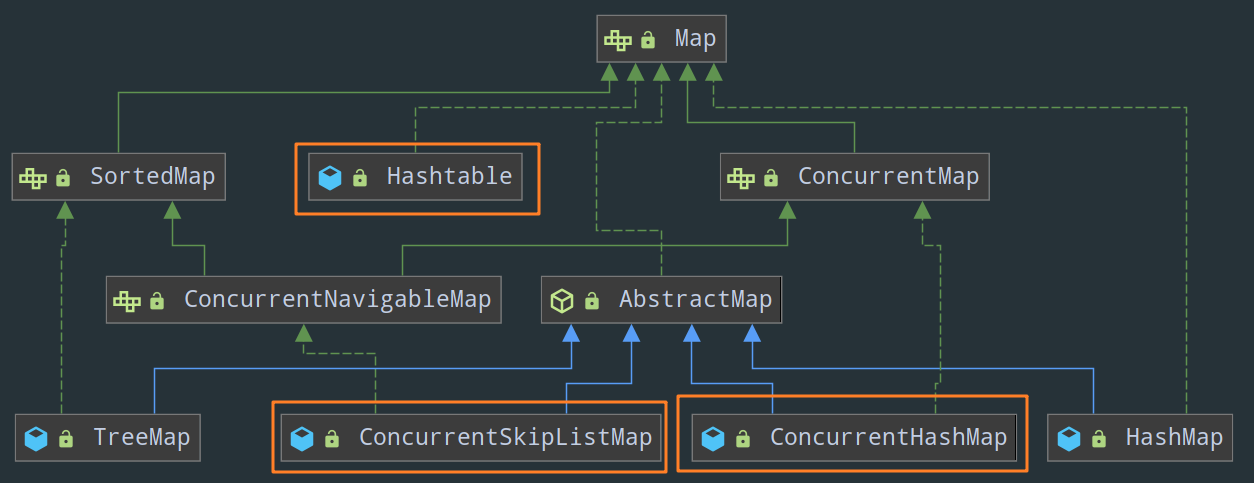
Map 接口
HashTable(这个有一些细节需要注意,可以看这里 Hashtable 渐渐被人们遗忘了,只有面试官还记得,不过在线程安全方面其实也没啥好说的,就是把 HashMap 中所有的方法统统加上 synchronized )ConcurrentMap 接口
ConcurrentHashMap
ConcurrentSkipListMap
ConcurrentHashMap
JDK1.7
第一句:ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成
第二句:Segment 继承自 ReentrantLock,是一种可重入锁;其中,HashEntry 是用于真正存储数据的地方
第三句:一个 ConcurrentHashMap 包含一个 Segment 数组,一个 Segment 里包含一个 HashEntry 数组,当对某个 HashEntry 数组中的元素进行修改时,必须首先获得该元素所属 HashEntry 数组对应的 Segment 锁
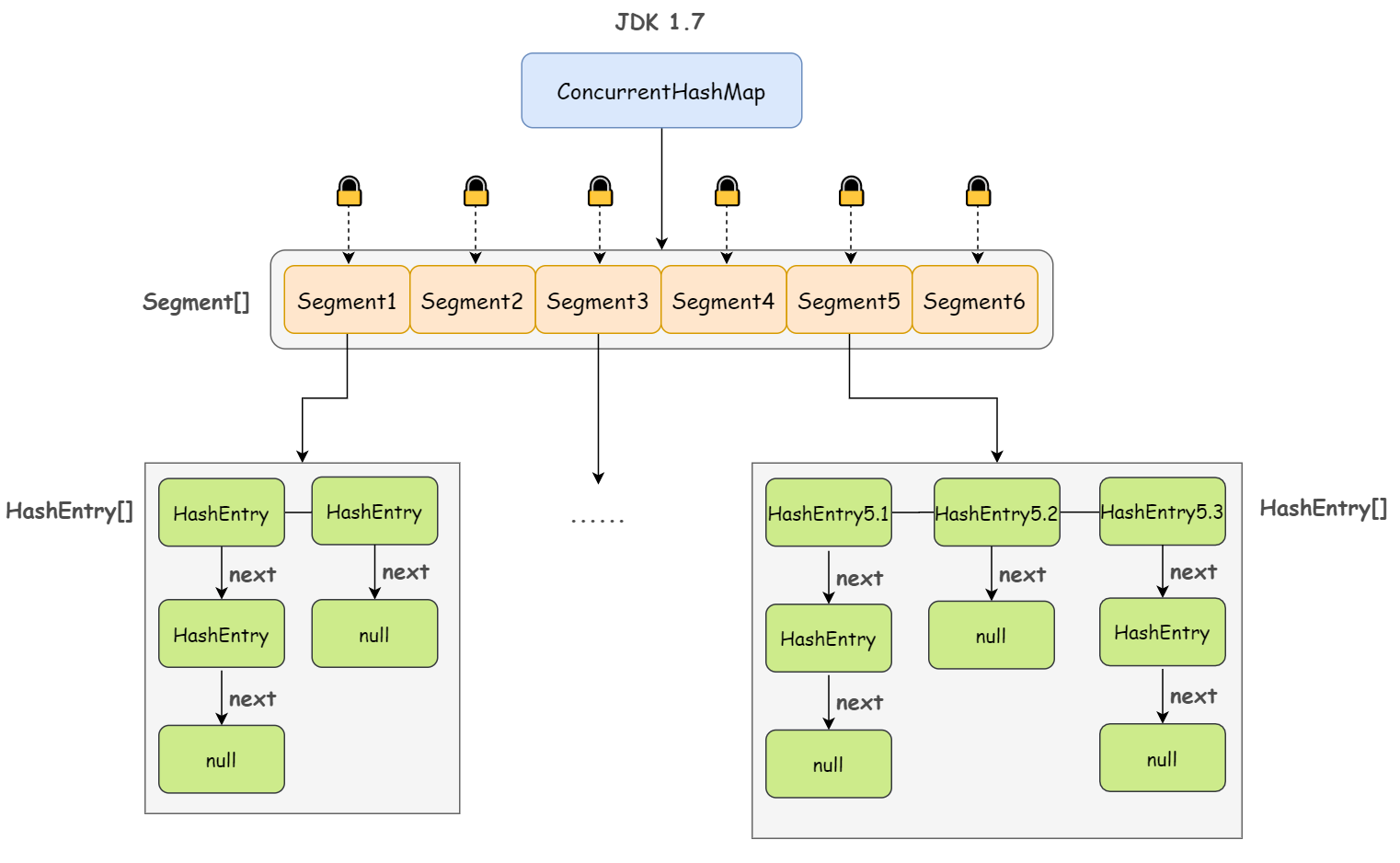
ConcurrentHashMap 采用分段锁(Segment 数组,一个 Segment 就是一个锁)技术,每当一个线程访问 HashEntry 中存储的数据从而占用一个 Segment 锁时,并不会影响到其他的 Segment,也就是说,如果 Segment 数组中有 10 个 元素,那理论上是可以允许 10 个线程同时执行的。
小结
总结下 JDK 1.7 版本下的 ConcurrentHashMap,其实就是数组(Segment 数组) + 链表(每个 HashEntry 是链表结构),存在的问题也很明显,和 HashMap 一样,那就是 get 的时候都需要遍历链表,效率实在太低。
So,JDK 1.8 做了一些结构上的小调整
JDK1.8
不同于 JDK 1.7 版本的 Segment 数组 + HashEntry 链表,JDK 1.8 版本中的 ConcurrentHashMap 直接抛弃了 Segment 锁,一个 ConcurrentHashMap 包含一个 Node 数组(和 HashEntry 实现差不多),每个 Node 是一个链表结构,并且在链表长度大于一定值时会转换为红黑树结构(TreeBin)。
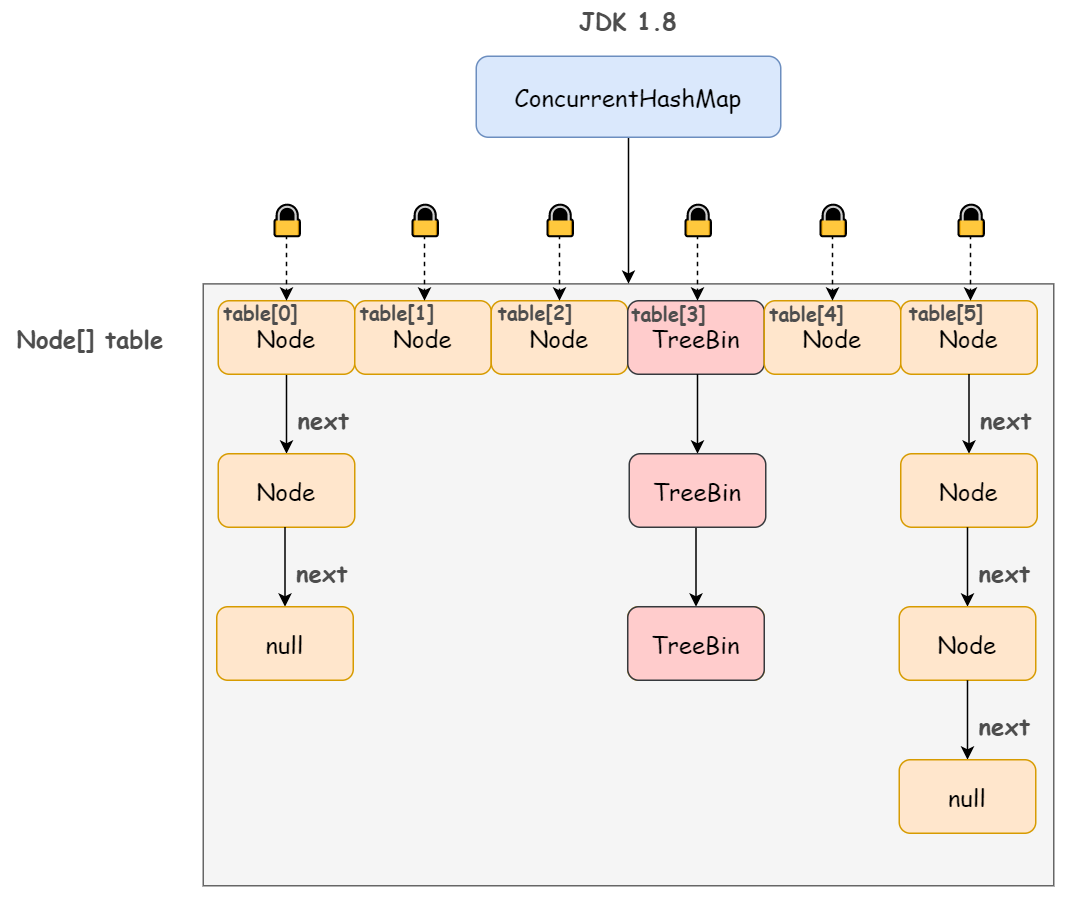
那既然没有使用分段锁,如何保证并发安全性的呢?
synchronized + CAS!
简单来说,Node 数组其实就是一个哈希桶数组,每个 Node 头节点及其所有的 next 节点组成的链表就是一个桶,只要锁住这个桶的头结点,就不会影响其他哈希桶数组元素的读写。桶级别的粒度显然比 1.7 版本的 Segment 段要细。
JDK 1.8 没有使用 ReentrantLock 而是改用 synchronized,足以说明新版 JDK 对 synchronized 的优化确有成效。
5、并发工具类:
6、线程池:
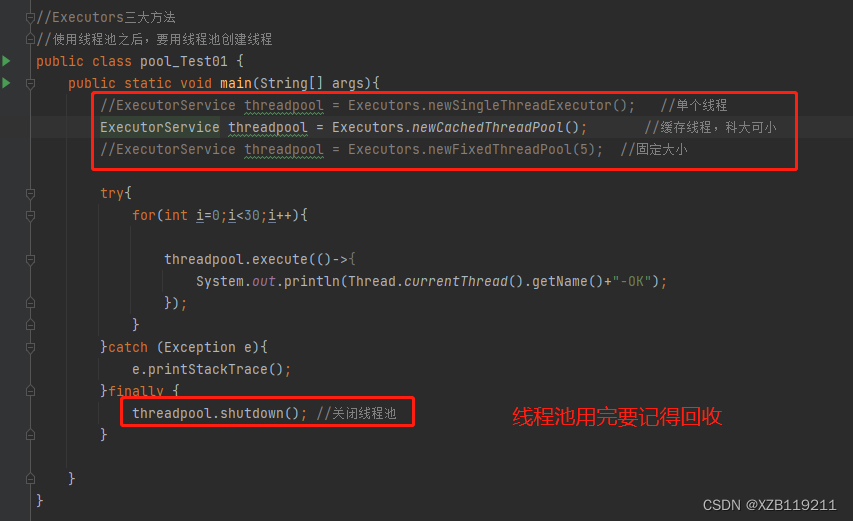
三大方法、7大参数、4种拒绝策略
三大方法:
七大参数
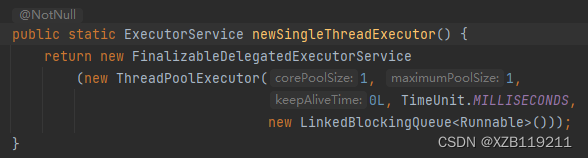
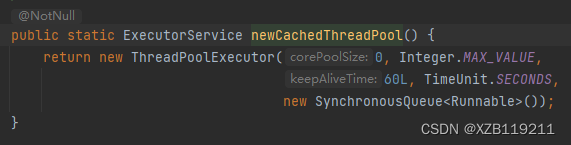

三大方法的源码都是用ThreadPoolExcutor来创建的
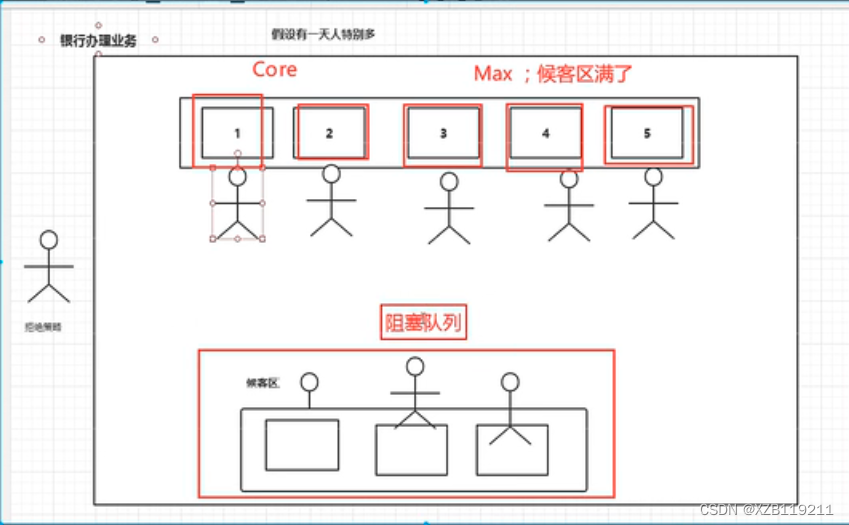
所以一般实际运用中药用源码的方式去自定义线程池
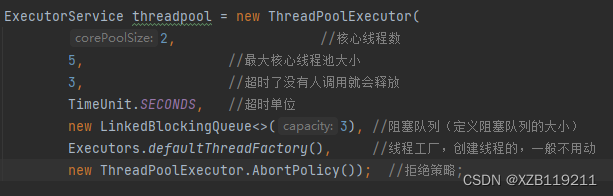
四种拒绝策略

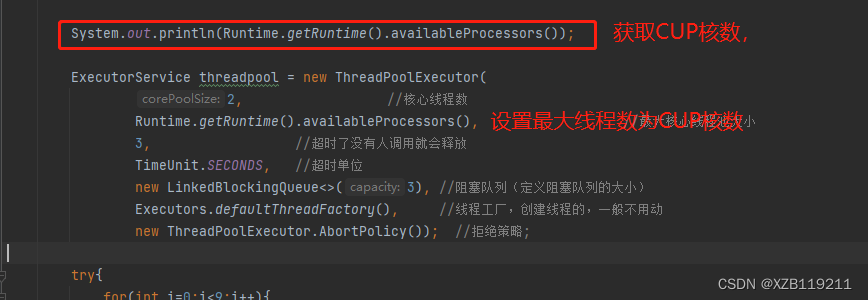
最大线程数如何设置?
分为CPU密集型和IO密集型
CPU密集型:设置CPU核数为最大线程数
IO密集型:程序有15个大型任务,IO特别占用资源,一般设置为大型任务数的二倍





![[CF复盘] Codeforces Round 874 (Div. 3) 20230520】](https://img-blog.csdnimg.cn/a1023d0502f64d65877a22a7d9611454.png)