一.全文搜索引擎 ElasticSearch 的介绍,以
及安装配置前的准备工作
介绍
ElasticSearch 是一个基于 Lucene 的 搜索服务器,它提供了一个 分布式多用户能力的 全文搜索引擎,基于 RESTful web 接口,Elasticsearch 是用 Java 开发的,并作为 Apache 许可条款下的开放源码发布,是当前流行的企业级搜索引擎,设计用于云计算中,能够达到 实时搜索, 稳定, 可靠, 快速,安装使用方便
官网地址: https://www.elastic.co/cn/
中文文档: https://www.elastic.co/guide/cn/index.html
github地址: https://github.com/elastic/elasticsearch
优点
支持分布式,高可用
底层就是Lucene, 隐藏了Lucene的复杂性
API更简单,更高级
支持PB级别的数据
完成了搜索的功能和分析功能
准备工作
电脑上面 必须安装 java jdk 以及 配置对应的环境变量
ElasticSearch与jdk版本匹配
elasticsearch支持JDK1.8的,仅仅是 7.17.3及其之前的版本,如果下的最新版本,最低JDK得17及其以上
二.在 Windows 下面下载并启动 ElasticSearch
ElasticSearch 下载
官方下载地址: https://www.elastic.co/downloads/elasticsearch
百度网盘链接: https://pan.baidu.com/s/1Xq7dFktRfpm2Ox8OK9Ud4w 提取码:qk60

运行 ElasticSearch
下载完成 ElasticSearch 包后,把 ElasticSearch 包放在一个固定 目录,然后从 命令窗口 cd 到ElasticSearch 包对应的目录, 运行位于 bin 文件夹中的 ElasticSearch.bat,这将会启动ElasticSearch 在控制台的前台运行,这意味着可在控制台中看到运行信息或一些错误信息,并可以使用 ctrl + c 停止或关闭它

bin 启动文件目录
config 配置文件目录
1og4j2 日志配置文件
jvm.options java虚拟机相关的配置(默认启动占1g内存,内容不够需要自己调整)
elasticsearch.ym1 elasticsearch的配置文件,默认9200端口!跨域
1ib
相关jar包
modules 功能模块目录
plugins 插件目录
ik分词器在启动过程中,ElasticSearch 的实例运行会占用大量的内存,所以在这一过程中,电脑会变得比较慢,需要耐心等待,启动加载完成后电脑就可以正常使用了。
如果没有安装 Java 运行时或没有正确配置,应该会输出一个消息说: JAVA_HOME 环境变量必须设置,要解决这个问题,首先下载并安装 Java JDK,并且确保已正确配置 JAVA_HOME 环境变量
有时候还会出现这样的提示:
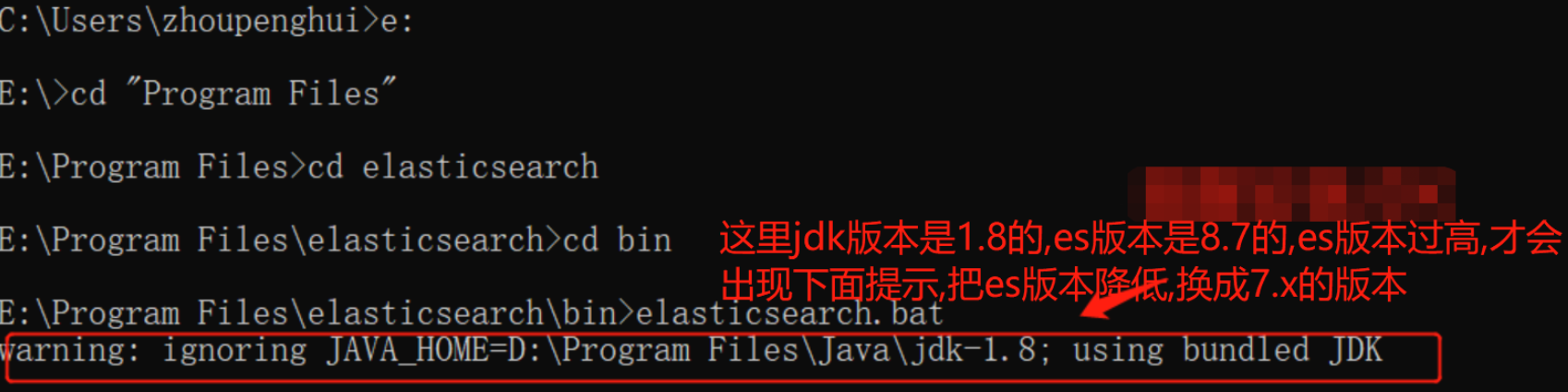
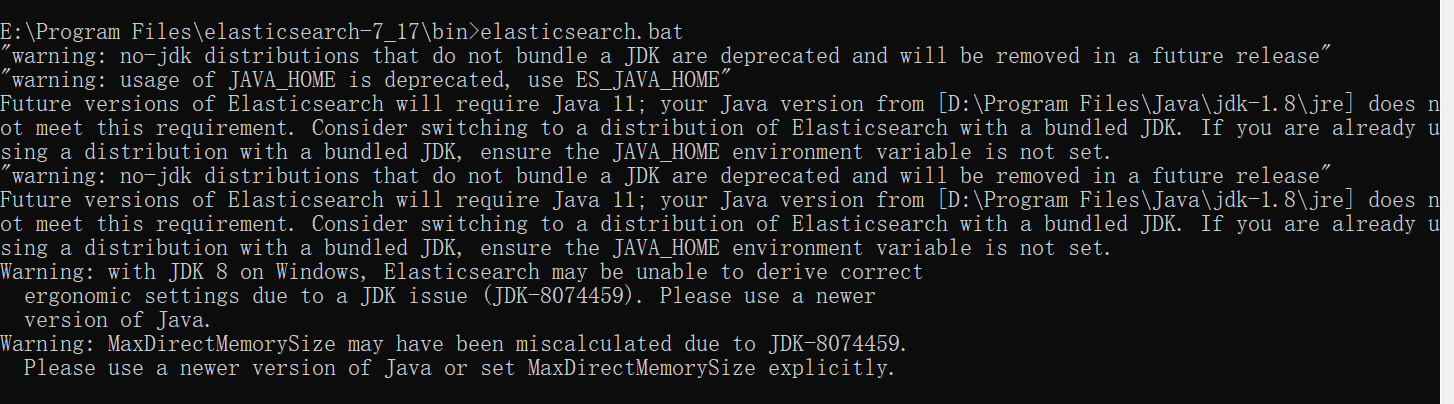
报错原因是因为JDK版本太低或者ElasticSearch版本太高,降低版本即可,低版本ElasticSearch下载地址: Past Releases of Elastic Stack Software | Elastic
启动成功图示:
访问 ElasticSearch Api
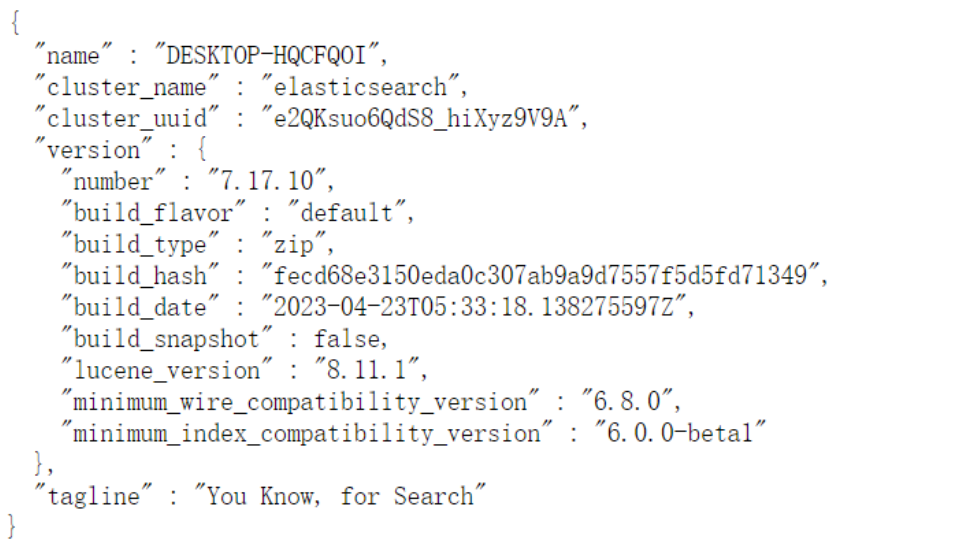
当 ElasticSearch 的实例并运行,可以使用 localhost:9200,基于 JSON 的 REST API 与
ElasticSearch 进行通信,如果输入 http://localhost:9200/ 出来如下界面,说明
ElasticSearch 配置并启动成功
安装配置中文分词工具
默认情况 ElasticSearch 只适用于 英文分词 , 如果要做 中文分词的话 , 要安装
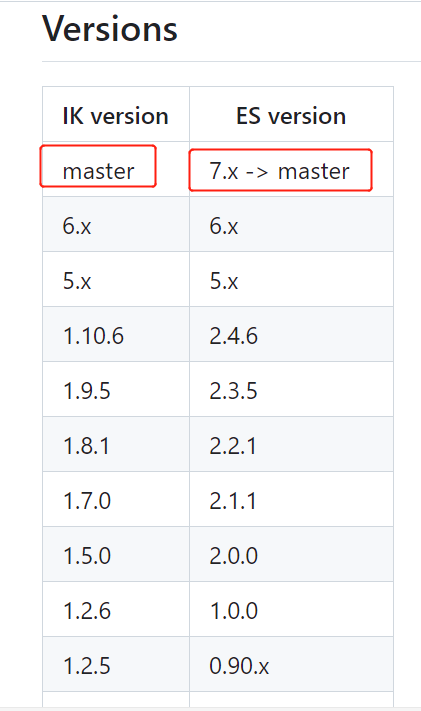
elasticsearch-analysis-ik插件,官方github地址: https://github.com/medcl/elasticsearch-analysis-ik;官方提供了 两种安装中文分词工具的 方法,由于第二种可能因为版本问题会安装失败,所以接下来用 第一种方式安装
在这里,下载工具的时候要注意: 下载对应ES版本的分词工具
百度网盘下载链接:链接: https://pan.baidu.com/s/1XeUjJO_qYYebUxNIBfSSSA 提取码:wefk
步骤:
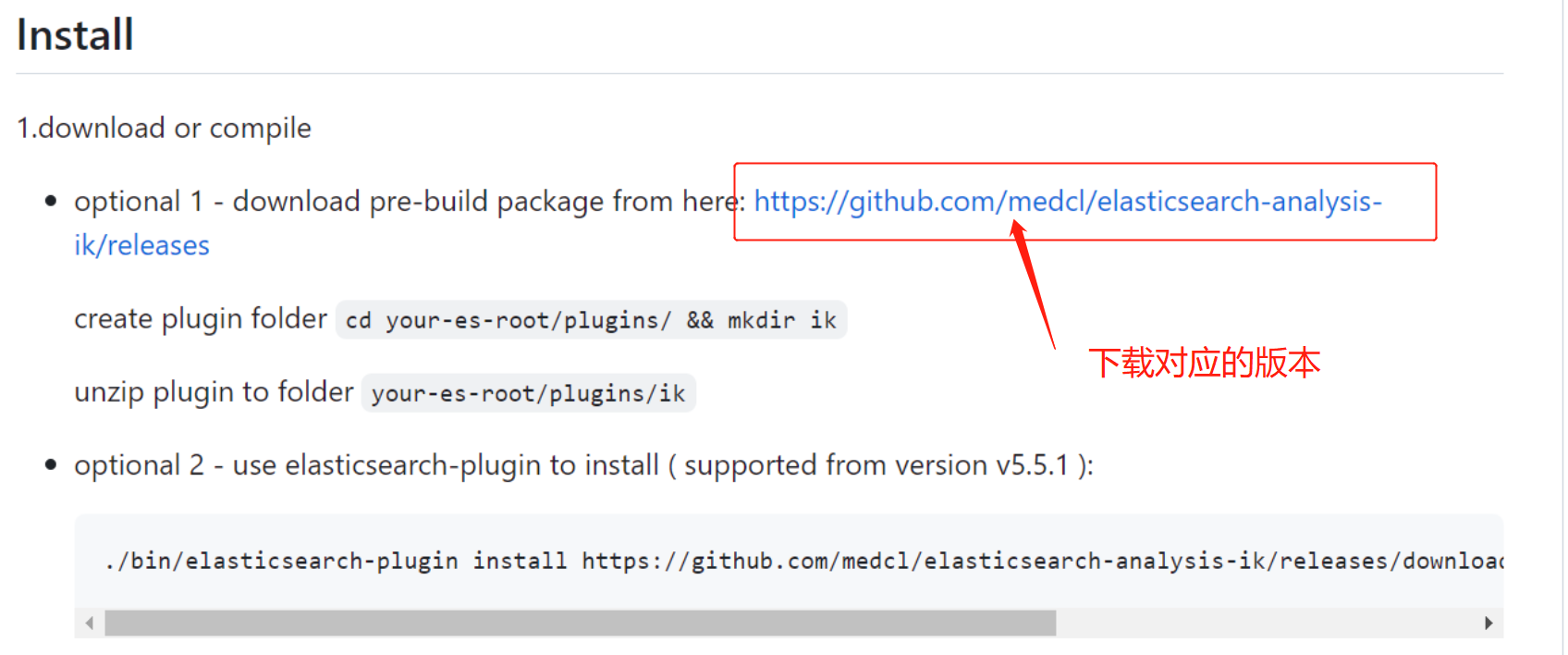
(1).按照上诉下载对应的分词工具
(2).在分词工具根目录创建 plugins/ik 文件
(3).把分词工具包的内容复制到 plugins/ik 文件里面
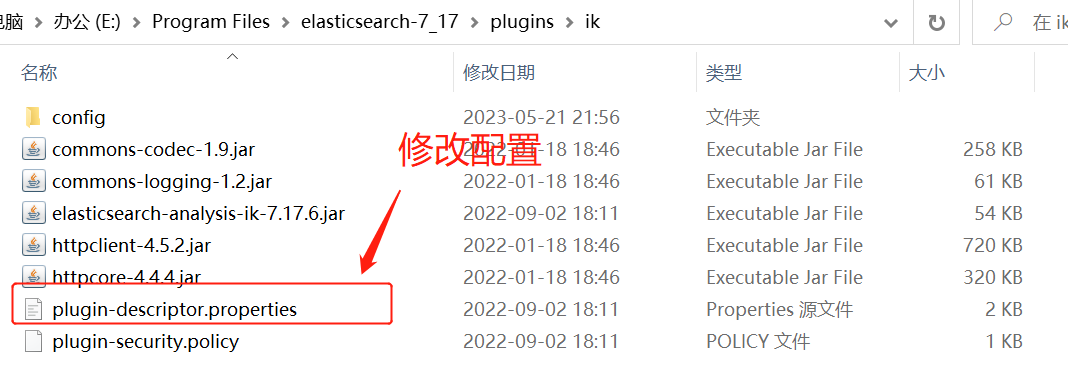
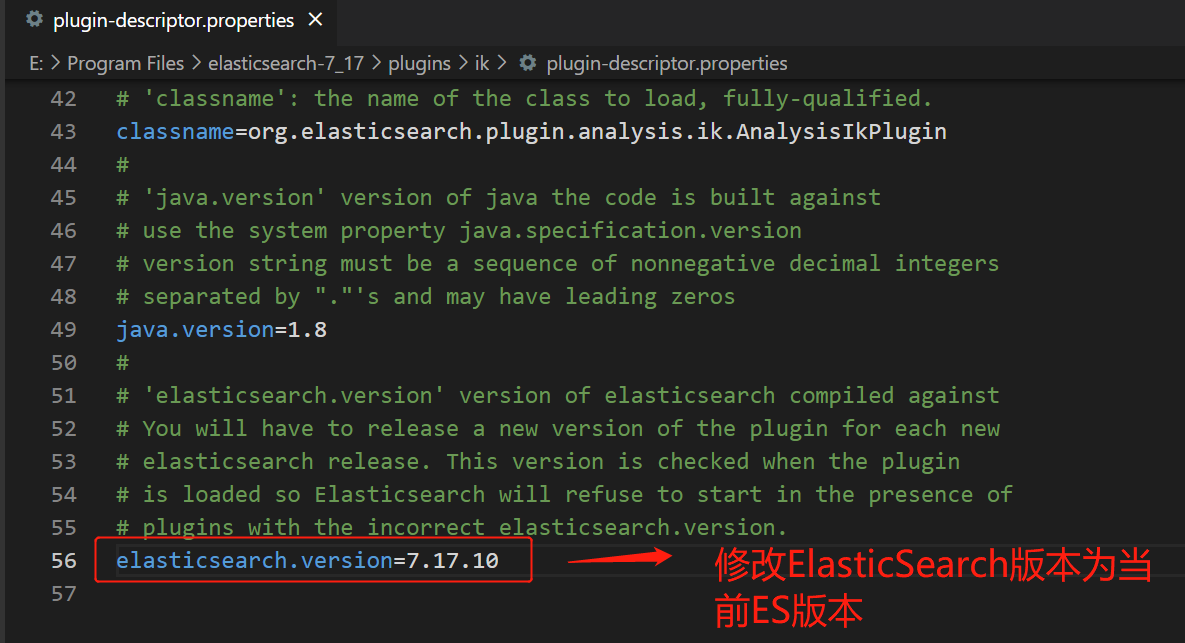
(4).修改配置文件的版本(如下图)
注意:一般修改配置的时候先备份配置
安装完成中文分词插件后,重新启动 ElasticSearch即可
三.在linux下面下载并启动 ElasticSearch
ElasticSearch下载
同 windows下载地址一样,下载完上传到Linux服务器直接解压
配置
ES的默认端口是 9200,提前在服务器端安全组端开放
vim编辑conf/elasticsearch.yml文件
# 取消注释,默认只能本地访问,修改为0.0.0.0,外网也能访问
network.host: 0.0.0.0 创建专用用户启动ES
root用户不能直接启动ES,会报如下错误
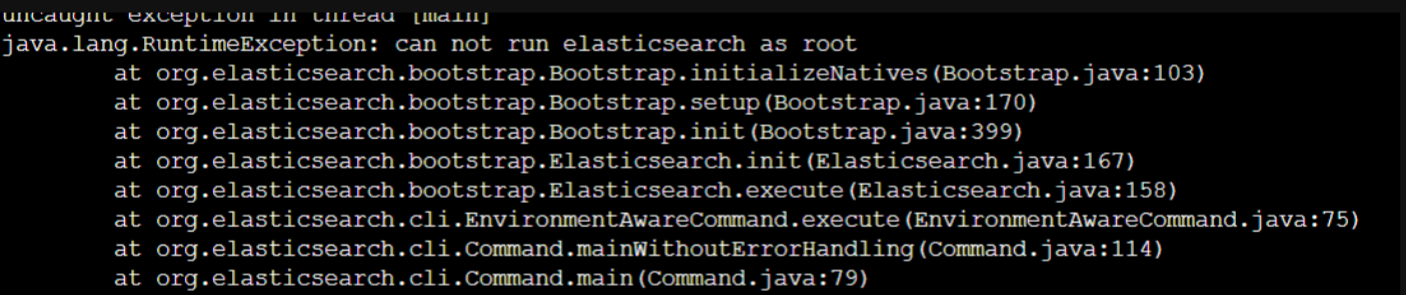
进入bin目录
cd /www/server/elasticsearch/elasticsearch-7.15.2/bin创建用户useres
useradd useres授权到es目录
chown useres:useres -R elasticsearch-7.15.2切换到useres用户
su useres启动ES
./elasticsearch测试访问
http://服务器ip地址:9200/

安装配置中文分词工具
和 windows一样,下载解压到plugins/ik,修改配置并重启es即可, 注意:解压完后要把压缩包删掉,否则会报错
启动时可能会报错
报错1:
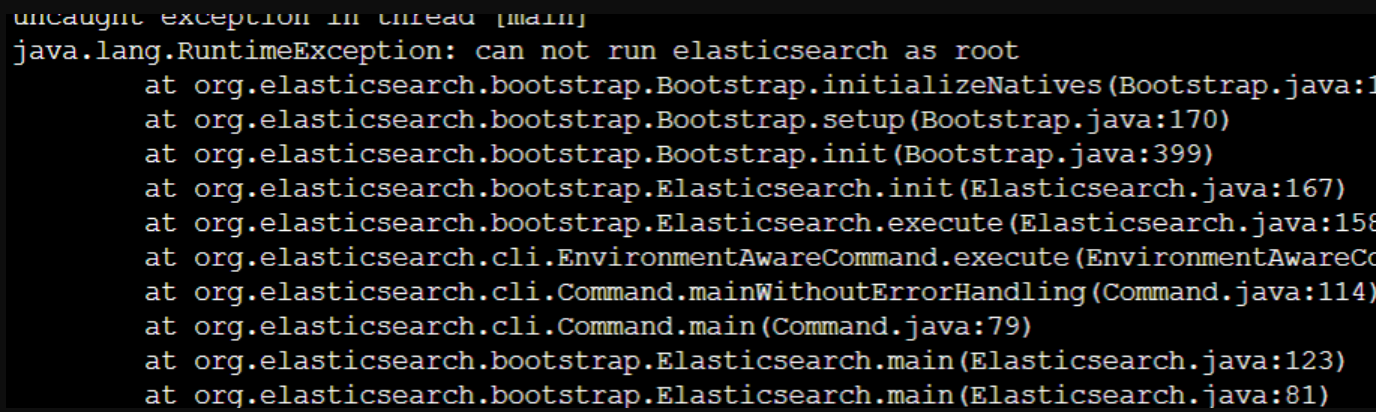
原因: ES用户拥有的 内存权限太小,至少需要262144
解决办法: 切换到root用户,修改 /etc/sysctl.conf文件
su rootvim 修改/etc/sysctl.conf文件
#添加如下内容
vm.max_map_count=262144
#保存退出后,刷新配置文件
sysctl -p切换useres用户后,再次启动ES
报错2:
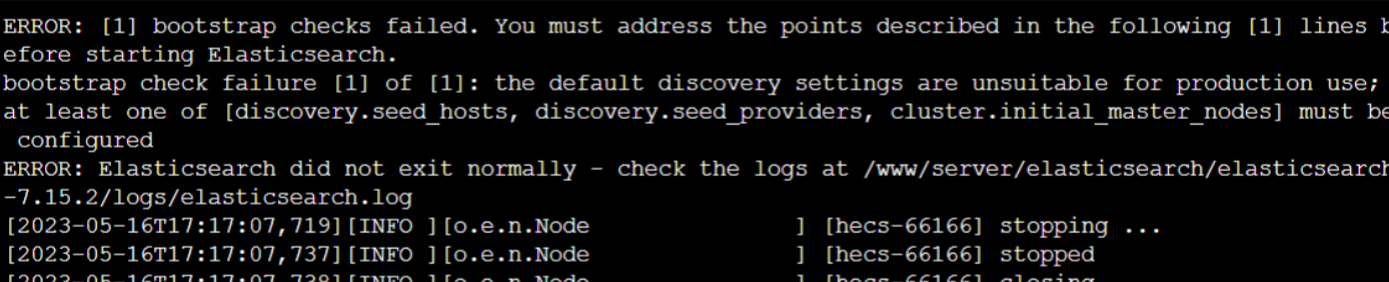
vim编辑 conf/elasticsearch.yml文件, 取消注释,删掉, “node-2”
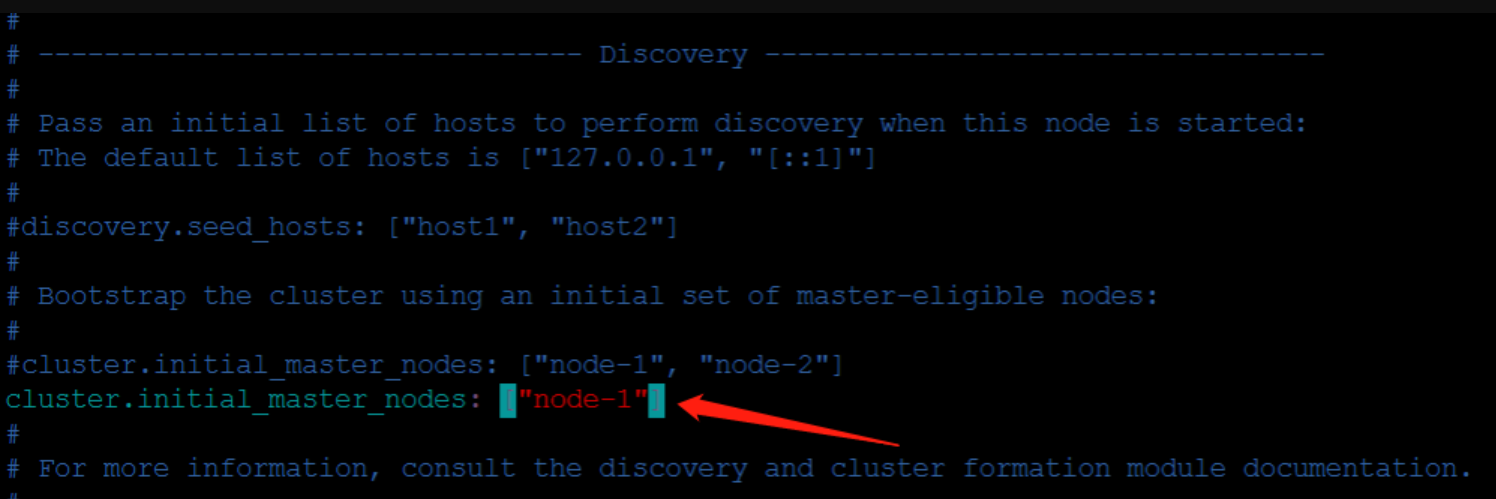
再次启动ES
四.Elasticsearch 中的一些概念概念
相关网址: https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
集群(cluster)
代表一个集群,集群中有多个节点(node),其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es 的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看 es 集群,在逻辑上是个整体,你与任何一个节点的通信和与整个 es 集群通信是等价的
索引(index)
ElasticSearch 将它的数据存储在一个或多个索引(index)中,用 SQL 领域的术语来类比,索引就像数据库,可以向索引写入文档或者从索引中读取文档,并通过ElasticSearch 内部使用 Lucene 将数据写入索引或从索引中检索数据
文档(document)
文档(document)是 ElasticSearch 中的主要实体,对所有使用 ElasticSearch的案例来说,他们最终都可以归结为对文档的搜索,文档由字段构成
映射(mapping)
所有文档写进索引之前都会先进行分析,如何将输入的文本分割为词条、哪些词条又会被过滤,这种行为叫做映射(mapping),一般由用户自己定义规则
类型(type)
每个文档都有与之对应的类型(type)定义,这允许用户在一个索引中存储多种文档类型,并为不同文档提供类型提供不同的映射
分片(shards)
代表索引分片,es 可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上,构成分布式搜索,分片的数量只能在索引创建前指定,并且索引创建后不能更改,5.X 默认不能通过配置文件定义分片
副本(replicas)
代表索引副本(备份),es 可以设置多个索引的副本,副本的作用一是提高系统的容错性,当个某个节点某个分片损坏或丢失时可以从副本中恢复,二是提高 es 的查询效率,es 会自动对搜索请求进行负载均衡
数据恢复(recovery)
代表数据恢复或叫数据重新分布,es 在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复
GET /_cat/health?v #可以看到集群状态
数据源(River)
代表 es 的一个数据源,也是其它存储方式(如:数据库)同步数据到 es 的一个方
法,它是以插件方式存在的一个 es 服务,通过读取 river 中的数据并把它索引到 es
中,官方的 river 有 couchDB 的,RabbitMQ 的,Twitter 的,Wikipedia 的
网关(gateway)
代表 es 索引的持久化存储方式,es 默认是先把索引存放到内存中,当内存满了时再持久化到硬盘,当这个 es 集群关闭再重新启动时就会从 gateway 中读取索引数据,es 支持多种类型的 gateway,有本地文件系统(默认),分布式文件系统,Hadoop的 HDFS 和 amazon 的 s3 云存储服务
自动发现(discovery.zen)
代表 es 的自动发现节点机制,es 是一个基于 p2p 的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互
5.X 关闭广播,需要自定义
通信(Transport)
代表 es 内部节点或集群与客户端的交互方式,默认内部是使用 tcp 协议进行交互,同时它支持 http 协议(json 格式)、thrift、servlet、memcached、zeroMQ 等的传输协议(通过插件方式集成)
节点间通信端口默认: 9300-9400
分片和复制(shards and replicas)
(1).分片
一个索引可以存储超出单个结点硬件限制的大量数据,比如,一个具有 10 亿文档的索引占据 1TB 的磁盘空间,而任一节点可能没有这样大的磁盘空间来存储或者单个节点处理搜索请求,响应会太慢。为了解决这个问题,Elasticsearch 提供了将索引划分成多片的能力,这些片叫做分片。当创建一个索引的时候,可以指定想要的分片的数量,每个分片本身也是一个功能完善并且独立的“索引”,这个“索引” 可以被放置到集群中的任何节点上
分片之所以重要,主要有两方面的原因:
允许水平分割/扩展内容容量
允许在分片(位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由 Elasticsearch 管理的
(2).复制
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点因为某些原因处于离线状态或者消失的情况下,故障转移机制是非常有用且强烈推荐的,为此, Elasticsearch 允许创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制
复制之所以重要,有几个主要原因:
在分片/节点失败的情况下,复制提供了高可用性,复制分片不与原/主要分片置于同一节点上是非常重要的。因为搜索可以在所有的复制上并行运行,复制可以扩展你的搜索量/吞吐量
总之,每个索引可以被分成多个分片。一个索引也可以被复制 0 次(即没有复制)或多次,一旦复制了,每个索引就有了主分片(作为复制源的分片)和复制分片(主分片的拷贝)
分片和复制的数量可以在索引创建的时候指定,在索引创建之后,可以在任何时候动态地改变复制的数量,但是不能再改变分片的数量
5.X 默认 5:1 5 个主分片,1 个复制分片
默认情况下,Elasticsearch 中的每个索引分配 5 个主分片和 1 个复制,这意味着,如果集群中至少有两个节点,索引将会有 5 个主分片和另外 5 个复制分片(1 个完全拷贝),这样每个索引总共就有 10 个分片
五.使用 RESTAPI 来操作 ElasticSearch
简介
当 ElasticSearch 的实例并运行,可以使用 localhost:9200,基于 JSON 的 REST API ElasticSearch 进行通信,在 ElasticSearch 自己的文档中,所有示例都使用 curl, 但是,当使用 API 时也可使用图客户端(如 Fiddler 或 RESTClient),这样操作起更方便直观一些
浏览器也提供了操作 ElasticSearch 的插件, 比如: Chrome 插件 Sense, Sense 提供了一个专门用于使用 ElasticSearch 的 REST API 的简单用户界面, 它还具有许多方便的功能,由于网络问题的原因,也可以使用 火狐浏览器里面提供的 ElasticSearch-Head,比如:火狐浏览器的 ElasticSearch-Head
安装火狐 ElasticSearch-Head步骤
上述请求将执行最简单的 搜索查询, 匹配服务器上 所有索引中的 所有文档,针对ElasticSearch 运行,Sense 提供的最简单的查询,在响应结果的数据中并没有查询到任何数据,因为没有任何索引,如下所示 :
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 0,
"successful": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": 0,
"hits": []
}
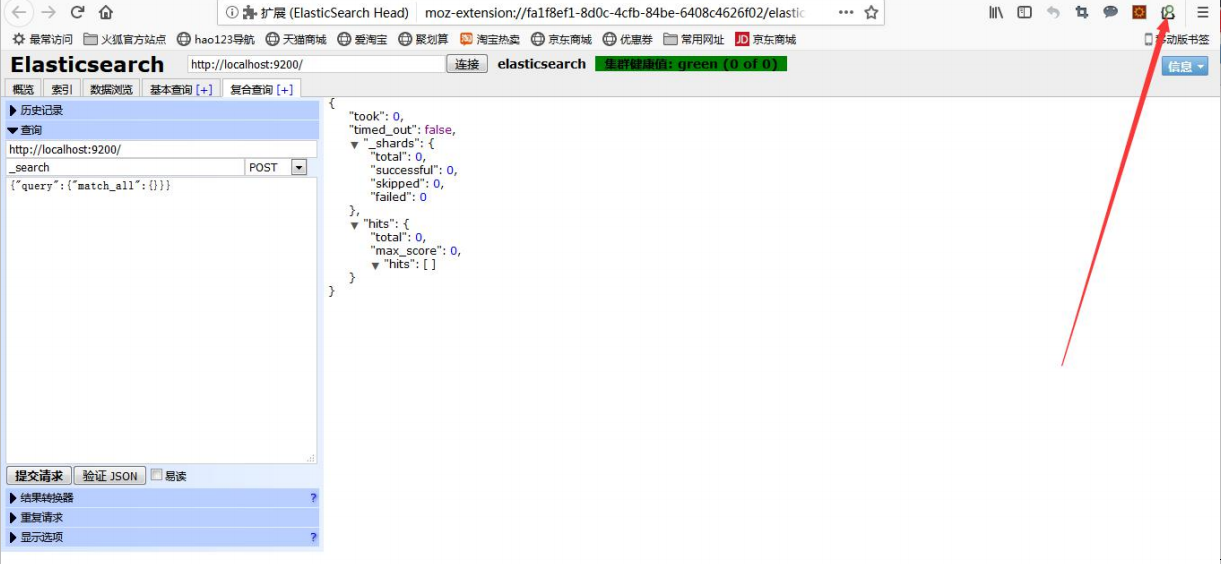
}使用ElasticSearch-Head
先看看几个重要概念

type:类型,可以是 text、long、short、date、integer、object 等
index:是否索引,默认为 true
store:是否存储,默认为 false
analyzer:分词器,这里的 ik_max_word 即使用 ik 分词器
具体代码参考ik官方github: https://github.com/medcl/elasticsearch-analysis-ik
(1).创建索引
curl -XPUT http://localhost:9200/goods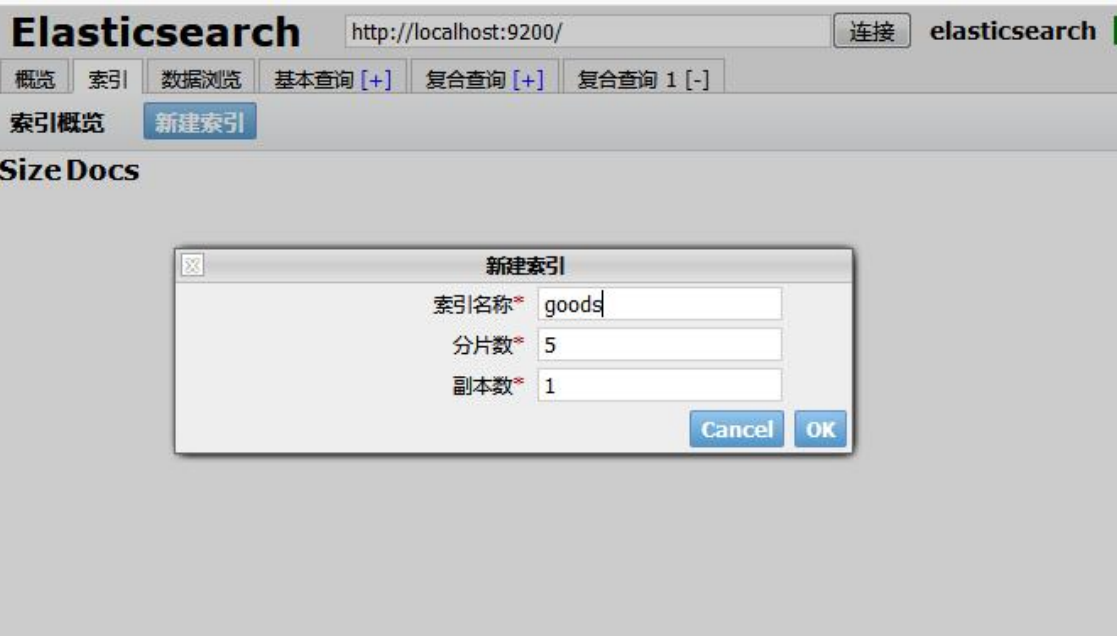
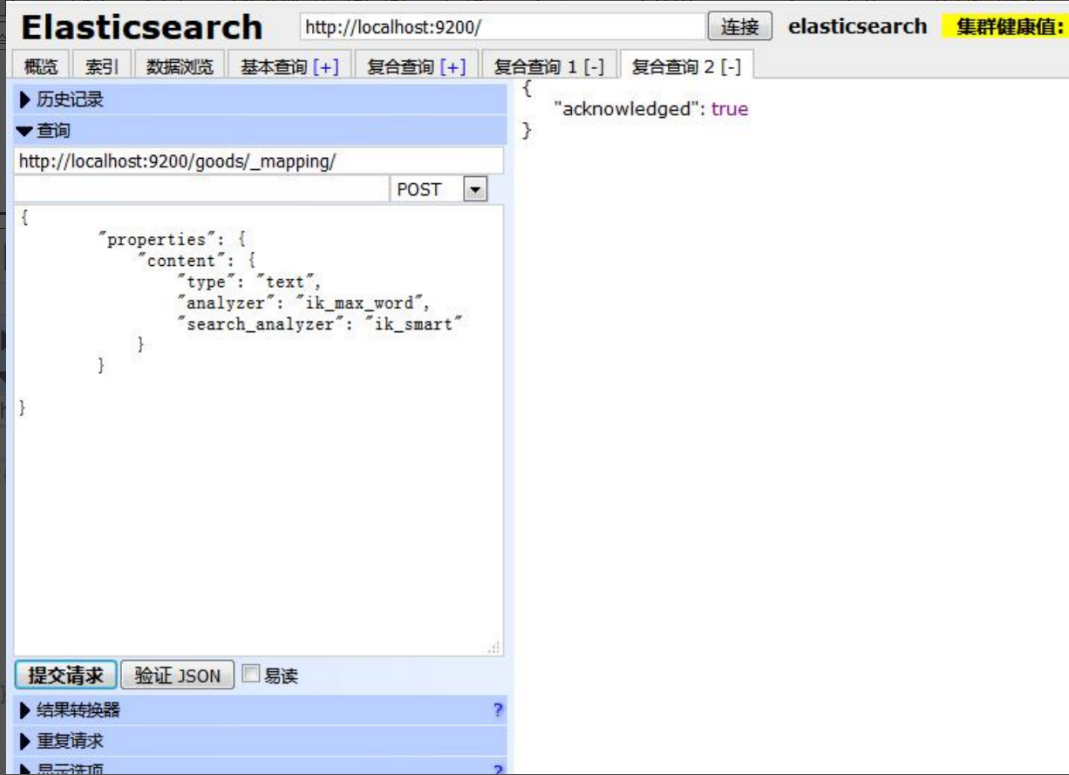
(2).创建类型以及配置映射
_mapping:映射标识
#配置映射url
curl -XPOST http://localhost:9200/goods/_mapping创建配置映射以及类型
{
"properties": { #属性
"content": { #映射名
"type": "text", #类型
"analyzer": "ik_max_word", #检索粒度
"search_analyzer": "ik_smart" #检索粒度
}
}
}
(3).查看映射
GET /goods/_mapping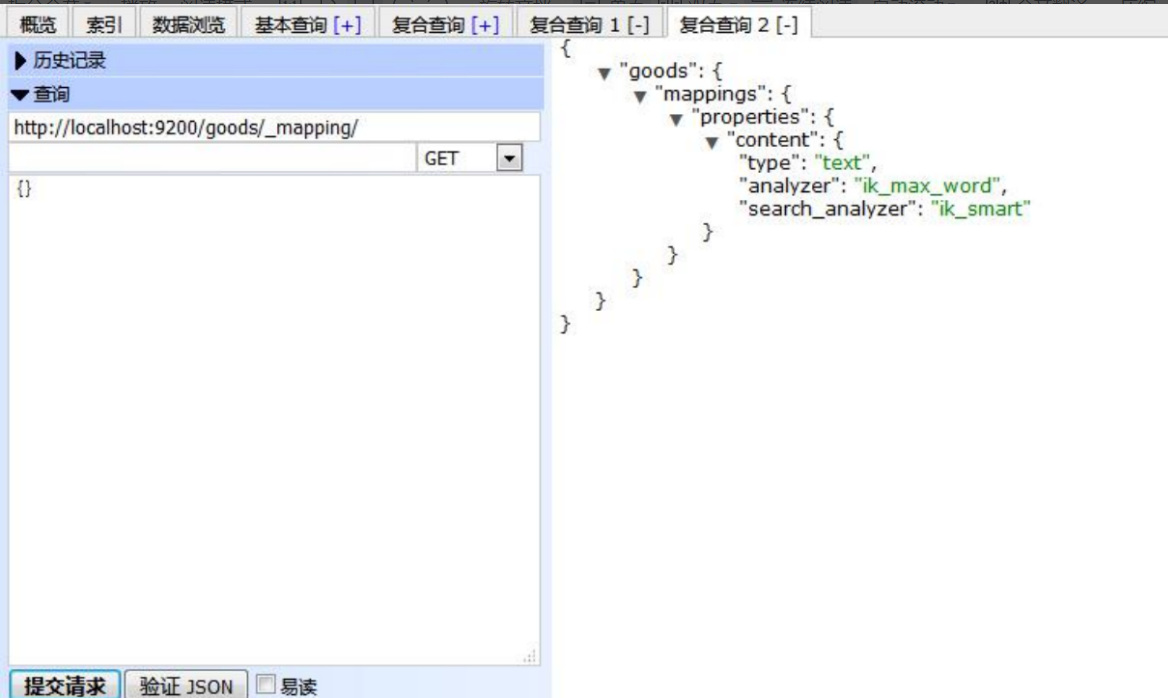
(4).增加数据
_doc为默认值,以后官方可能会取消
POST /goods/_doc{"content":"渔警调查:平均每天扣 1 艘渔船"}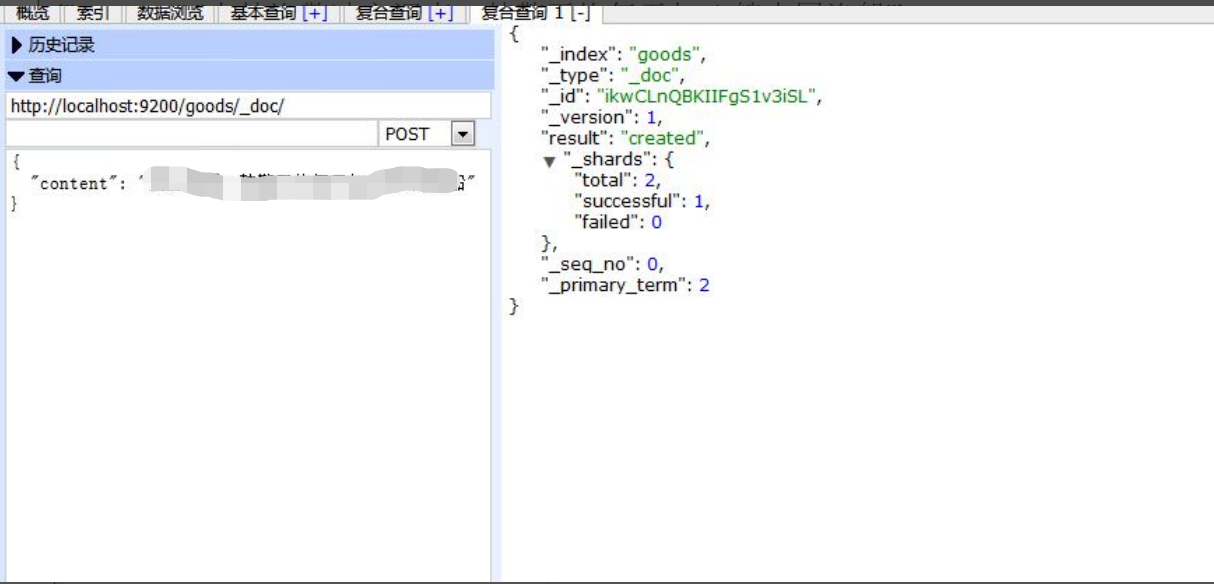
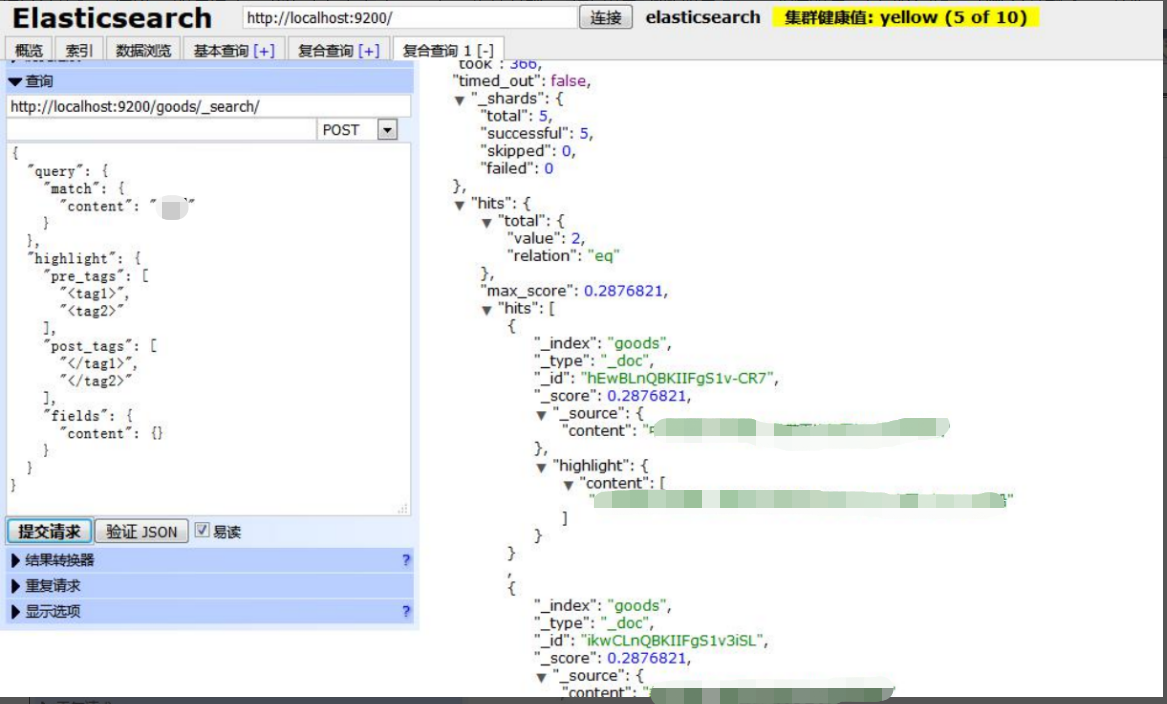
(5).查询数据
_search:查询标识
POST /goods/_search查询格式:
{
"query" : {
"match" : {
"content" : "渔船"
}
},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : { "content" : {}
}
}
}
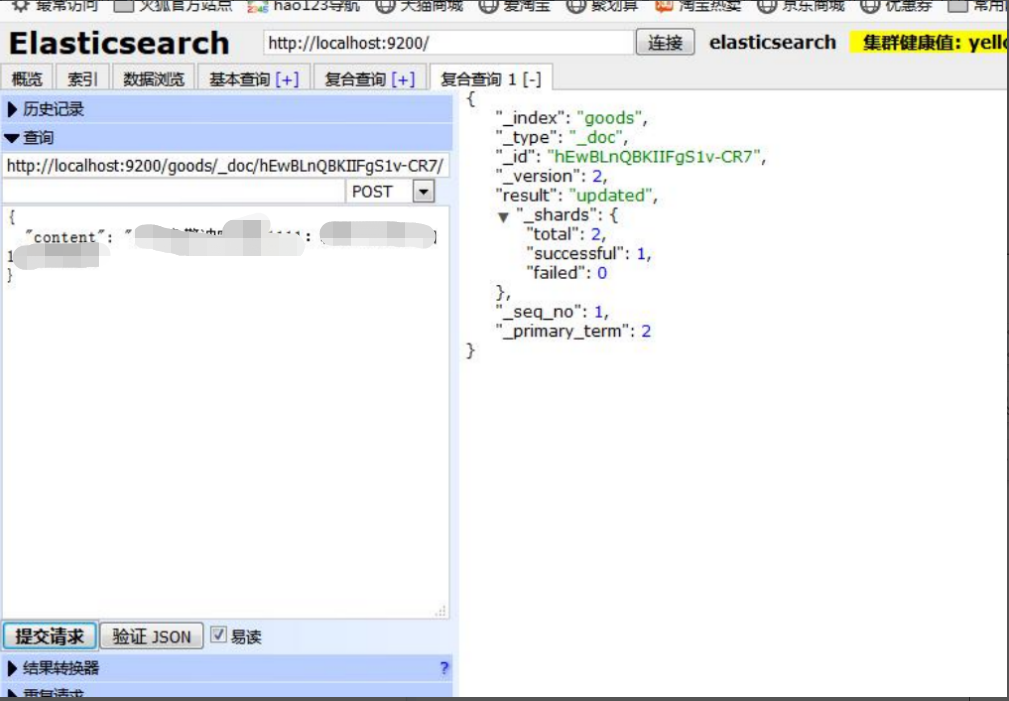
(5).修改数据
9lkEDmkBLW9aMdEIICBc:数据唯一编号,相当于mysql中的主键
PUT /news/_doc/9lkEDmkBLW9aMdEIICBc{
"content": "渔警冲突调查:平均每天扣 1 艘渔船xxx"
}
(6).删除数据
DELETE /news/_doc/9lkEDmkBLW9aMdEIICBc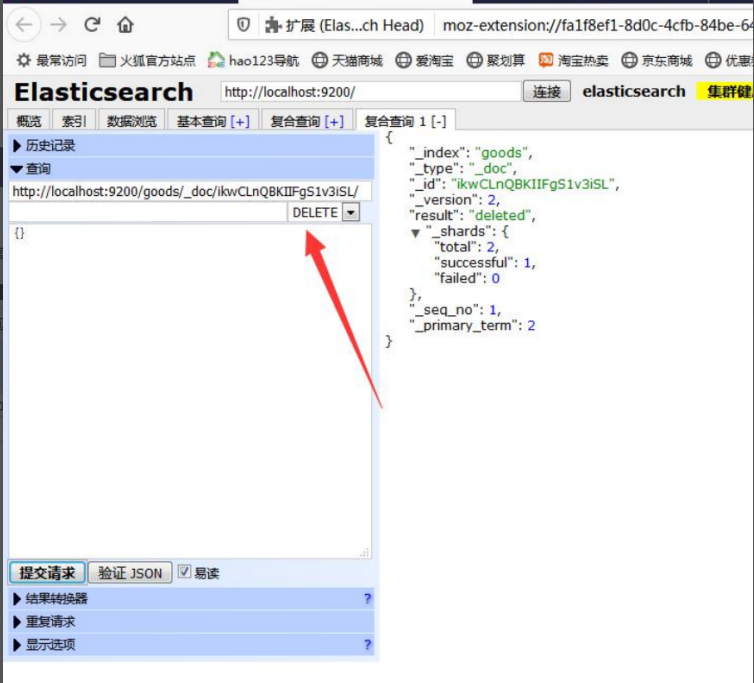
六.ElasticSearch 安装可视化工具 Kibana的使用
官方文档: https://www.elastic.co/guide/cn/kibana/current/install.html
百度网盘下载链接: https://pan.baidu.com/s/169GyGwxHLSYwGJ7Wmo-z8Q 提取码:yzbl
在这里介绍windows安装方式
下载Kibana

运行


warning警告不用管
访问
Kibana 是一个 web 应用,可以通过5601端口访问。只需要在浏览器中指定 Kibana 运行的机器,然后指定端口号即可。例如, localhost:5601 或者 http://YOURDOMAIN.com:5601 。当访问 Kibana 时, Discover 页默认会加载默认的索引模式。时间过滤器设置的时间为过去15分钟,查询设置为匹配所有 (\*) 。如果看不到任何文档,试着把时间过滤器的范围调大。如果还是看不到任何结果,很可能是根本就 没有 任何文档
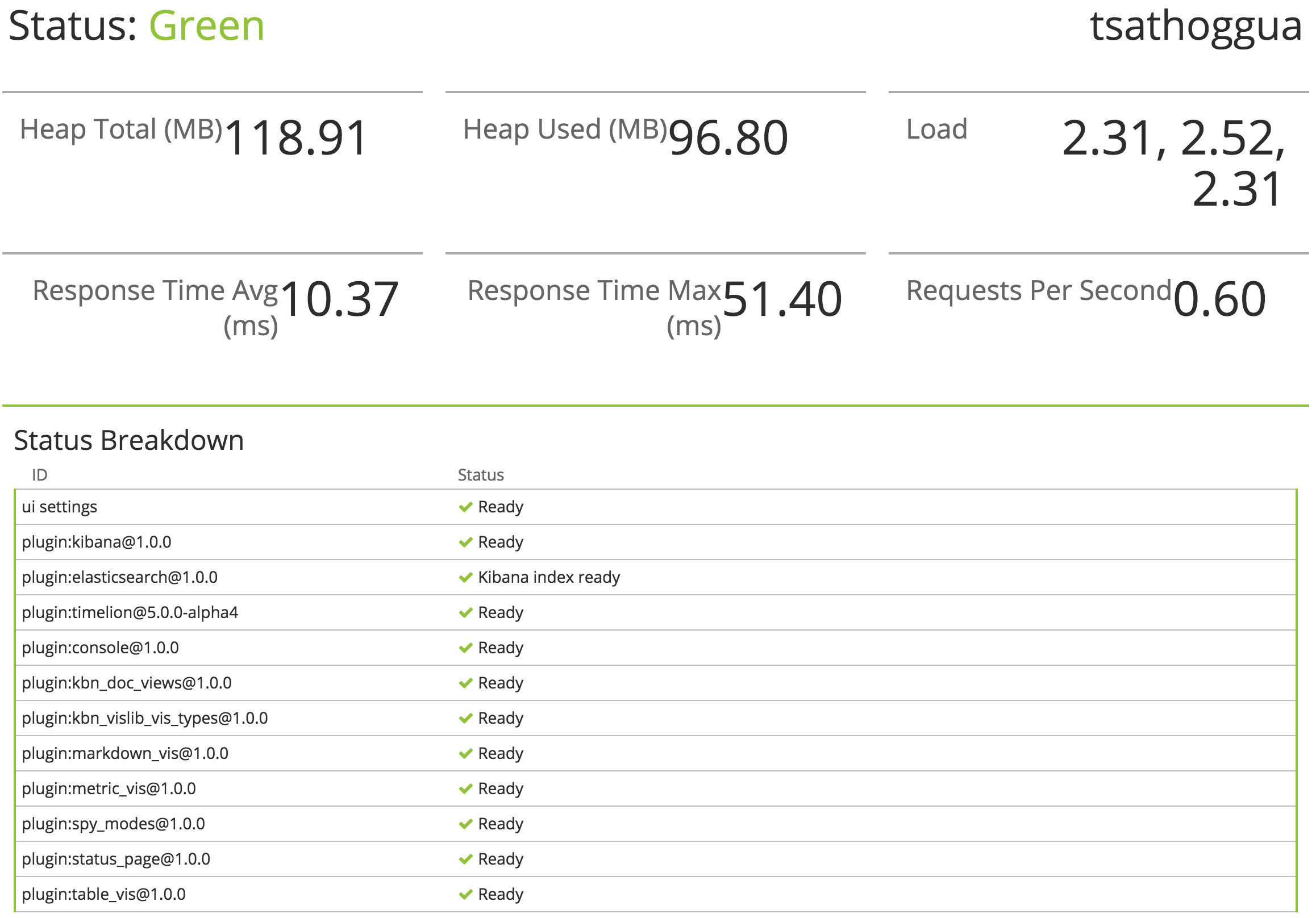
检查 Kibana 状态
您可以通过 localhost:5601/status 来访问 Kibana 的服务器状态页,状态页展示了服务器资源使用情况和已安装插件列表。
使用Kibaba操作
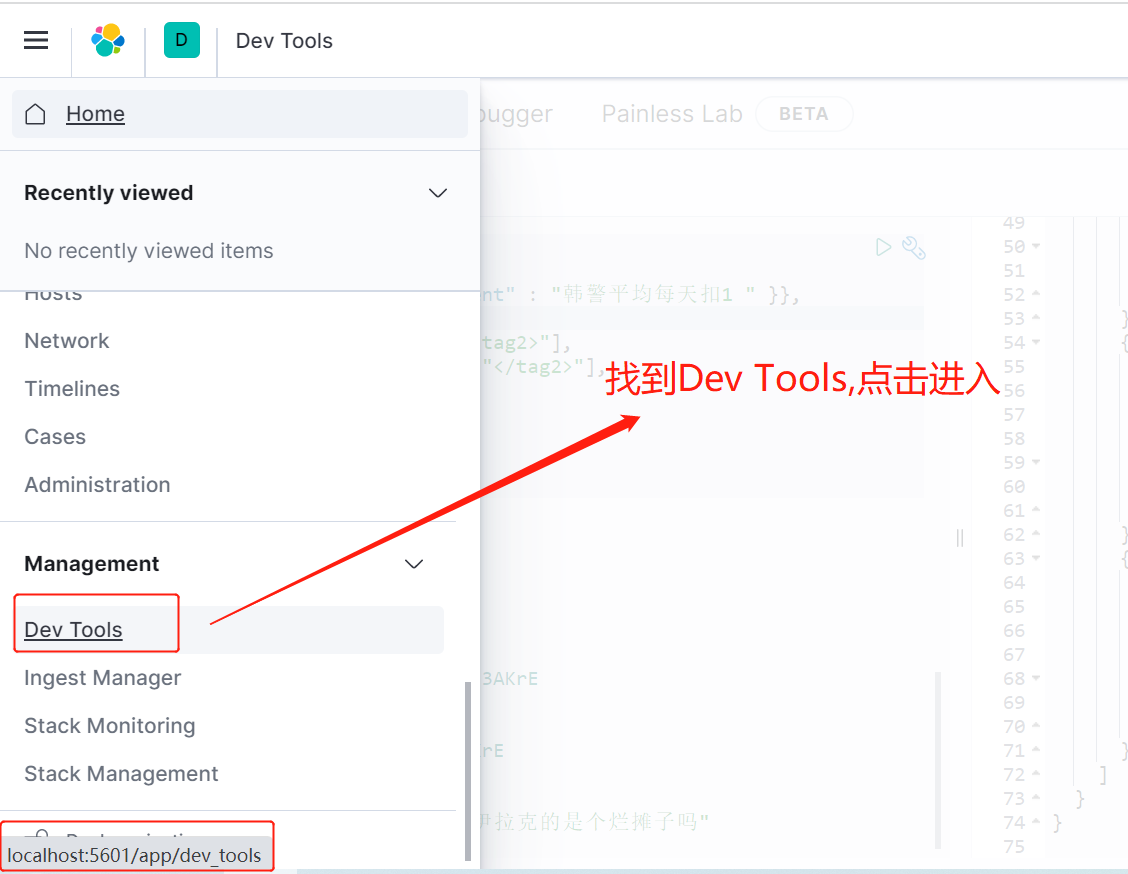
相关基础功能代码如下:
#删除索引
DELETE goods
#创建索引
PUT /goods
#修改映射
PUT /goods/_mapping
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
#修改映射
PUT /goods/_mapping
{
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
#查询映射
GET /goods/_mapping
#增加数据
POST /goods/_doc/
{
"title":"我",
"content":"美国留给伊拉克的是个烂摊子吗"
}
#增加数据
POST /goods/_doc/
{"content":"美国留给伊拉克的是个烂摊子吗"}
#增加数据
POST /goods/_doc/
{"content":"公安部:各地校车将享最高路权66666666"}
#增加数据
POST /goods/_doc/
{"content":"php公安部:各地校车将享最高路权"}
#增加数据
POST /goods/_doc/
{"content":"java公安部:各地校车将享最高路权"}
#增加数据
POST /goods/_doc/
{"content":"冲突调查:均每天扣1艘渔船"}
#增加数据
POST /goods/_doc/
{"content":"男子"}
#查询全部
GET /goods/_search
{
"query": {
"match_all": {}
}
}
#查询全部
GET /goods/_doc/_search
{
}
#根据关键词查询数据
POST /goods/_doc/_search
{
"query" : { "match" : { "content" : "平均每天" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
#修改数据:CqcgS4gBnl0dU5J3AKrE是文档唯一标识
PUT /goods/_doc/CqcgS4gBnl0dU5J3AKrE
{
"title": "我xxxxx",
"content": "111美国留给伊拉克的是个烂摊子吗"
}
#删除数据
DELETE /goods/_doc/CqcgS4gBnl0dU5J3AKrE更多操作方法见:
Kibana官方文档:https://www.elastic.co/guide/cn/kibana/current/introduction.html
elasticsearch-analysis-ik:https://github.com/medcl/elasticsearch-analysis-ik
[上一节]https://blog.csdn.net/zhoupenghui168/article/details/130715687[golang gin框架] 36.Gin 商城项目-RESTful API 设计指南,允许Cros跨域 ,提供api接口实现前后端分离,以及JWT的使用




![[CF复盘] Codeforces Round 874 (Div. 3) 20230520】](https://img-blog.csdnimg.cn/a1023d0502f64d65877a22a7d9611454.png)