一、堆排序
堆排序是一种基于比较的排序算法,它的基本思想是将待排序的元素构建成一个堆,然后依次将堆顶元素取出,放到已排序的序列中,直到堆中所有元素都被取出,最终得到一个有序的序列。
堆是一种特殊的树形数据结构,它满足以下两个条件:
-
堆是一颗完全二叉树。
-
堆中每个节点的值都大于等于(或小于等于)其左右子节点的值,这种性质称为堆的性质。
堆排序的基本步骤如下:
-
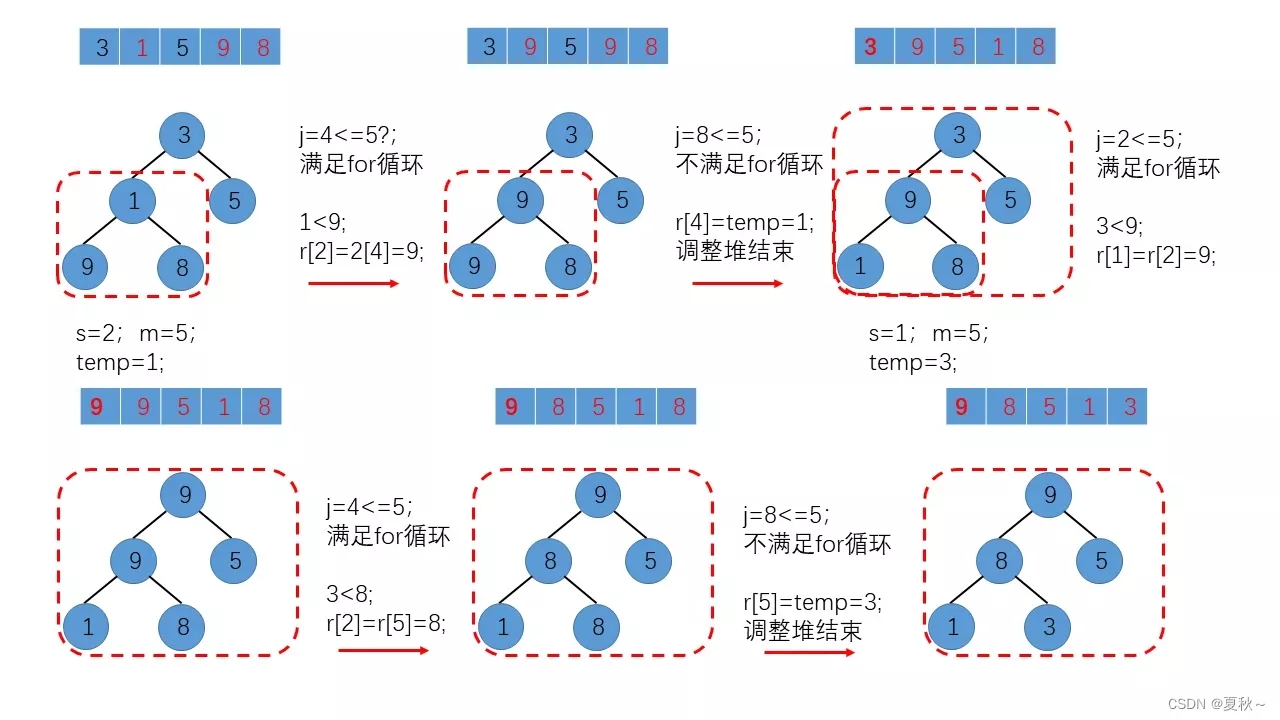
构建堆:将待排序的元素构建成一个堆,可以使用数组来表示堆,数组中下标为 i 的元素的左子节点下标为 2i+1,右子节点下标为 2i+2。
-
取出堆顶元素:将堆顶元素取出,放到已排序的序列中。
-
调整堆:将剩余的元素重新构建成一个堆,然后重复步骤 2 和步骤 3,直到堆中所有元素都被取出。
堆排序的优点是排序效率高,适用于大规模数据的排序。堆排序的缺点是不稳定,无法保证相等元素的相对位置不变。
二、堆排序的性质
堆排序的性质如下:
-
堆是一种完全二叉树:堆是一种特殊的树形数据结构,它满足完全二叉树的性质,即除了最后一层外,其他层的节点数都是满的,最后一层的节点都靠左排列。
-
堆分为大根堆和小根堆:大根堆中每个节点的值都大于等于其左右子节点的值,小根堆中每个节点的值都小于等于其左右子节点的值。
-
堆的性质:堆中每个节点的值都大于等于(或小于等于)其左右子节点的值,这种性质称为堆的性质。
-
堆的存储方式:堆可以使用数组来表示,数组中下标为 i 的元素的左子节点下标为 2i+1,右子节点下标为 2i+2。
-
堆排序的过程:堆排序的过程包括构建堆、取出堆顶元素、调整堆三个步骤。在构建堆的过程中,需要从下往上调整堆,确保堆中每个节点都满足堆的性质;在取出堆顶元素的过程中,需要将堆顶元素与堆中最后一个元素交换位置,然后将堆中剩余元素重新构建成一个堆,从而保证堆的性质;在调整堆的过程中,需要从上往下调整堆,确保堆中每个节点都满足堆的性质。
-
堆排序的时间复杂度:堆排序的时间复杂度为 O(nlogn),其中 n 表示待排序数组的长度。堆排序的时间复杂度比较稳定,不受数据分布的影响。
-
堆排序的空间复杂度:堆排序的空间复杂度为 O(1),因为堆排序是原地排序算法,不需要额外的空间来存储临时数组。
三、堆排序的变种
堆排序的变种有以下几种:
-
堆排序的升级版:堆排序的升级版是优先队列(Priority Queue),它是一种支持在 O(logn) 时间内插入和删除元素的数据结构,可以使用堆来实现。在 Java 中,PriorityQueue 就是使用堆来实现的。
-
大小根堆的切换:堆排序可以通过切换大小根堆来实现升序和降序排序。如果使用大根堆,则可以实现升序排序,因为大根堆的堆顶元素是最大的;如果使用小根堆,则可以实现降序排序,因为小根堆的堆顶元素是最小的。
-
堆排序的非递归实现:堆排序可以使用非递归的方式来实现,这样可以避免递归调用带来的额外开销。非递归的堆排序可以使用循环来实现,具体实现方法可以参考迭代版堆排序。
-
堆排序的并行实现:堆排序可以使用多线程来实现并行排序,这样可以加速排序的过程。具体实现方法可以参考并行堆排序。
-
堆排序的优化:堆排序的效率可以通过一些优化来提高,例如使用局部性原理来减少缓存的失效、使用指针来代替数组下标来提高访问效率等。
四、Java 实现
以下是 Java 实现堆排序的代码:
public class HeapSort {
public static void heapSort(int[] arr) {
if (arr == null || arr.length == 0) {
return;
}
int len = arr.length;
// 构建大根堆
for (int i = len / 2 - 1; i >= 0; i--) {
adjustHeap(arr, i, len);
}
// 取出堆顶元素,放到已排序的序列中
for (int i = len - 1; i >= 0; i--) {
swap(arr, 0, i);
adjustHeap(arr, 0, i);
}
}
private static void adjustHeap(int[] arr, int i, int len) {
int temp = arr[i];
for (int j = i * 2 + 1; j < len; j = j * 2 + 1) {
if (j + 1 < len && arr[j] < arr[j + 1]) {
j++;
}
if (arr[j] > temp) {
arr[i] = arr[j];
i = j;
} else {
break;
}
}
arr[i] = temp;
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
在上面的代码中,我们首先构建一个大根堆,然后依次取出堆顶元素,放到已排序的序列中,最终得到一个有序的序列。在构建大根堆和调整堆的过程中,我们使用 adjustHeap 方法来实现,该方法可以将一个无序的数组构建成一个大根堆,或者调整一个无序的堆,使其满足堆的性质。在 swap 方法中,我们使用了一个临时变量 temp 来交换数组中的两个元素。
五、堆排序的应用场景
堆排序的应用场景包括:
-
大规模数据的排序:堆排序的时间复杂度为 O(nlogn),比较适用于大规模数据的排序。在实际应用中,堆排序经常被用来对海量数据进行排序。
-
优先队列:堆排序可以用来实现优先队列(Priority Queue),即支持在 O(logn) 时间内插入和删除元素的数据结构。在 Java 中,PriorityQueue 就是使用堆来实现的。
-
求最大/最小值:堆排序可以用来求一个集合中的最大或最小值,因为堆的性质可以保证堆顶元素是最大或最小的。
-
数据流中的中位数:堆排序可以用来解决数据流中的中位数问题,即如何在不断流入数据的情况下,快速地求出中位数。具体实现方法可以参考数据流中的中位数。
堆排序是一种非常高效的排序算法,可以应用于各种场景中。
六、堆排序在spring 中的应用
Spring 框架中使用堆排序的场景主要是在实现任务调度(Task Scheduling)功能时。Spring 的任务调度模块(Spring Task Scheduling)可以让开发者方便地配置和管理任务调度,支持多种触发器(Trigger)和执行器(Executor),可以满足各种任务调度的需求。
在 Spring 的任务调度模块中,任务调度器(TaskScheduler)使用堆排序来维护任务队列。具体来说,任务调度器会将所有待执行的任务按照触发时间排序,然后按照顺序依次执行。当一个任务执行完毕后,任务调度器会从堆顶取出下一个任务执行,以此类推。
使用堆排序来维护任务队列的好处是可以保证任务按照触发时间的先后顺序执行,同时可以快速地找到下一个要执行的任务。由于堆排序的时间复杂度为 O(nlogn),所以任务调度器可以在高效地管理大量的任务。









![[极客大挑战 2019]HardSQL1](https://img-blog.csdnimg.cn/img_convert/371f807c75ee420b9af63daf209682b8.png)