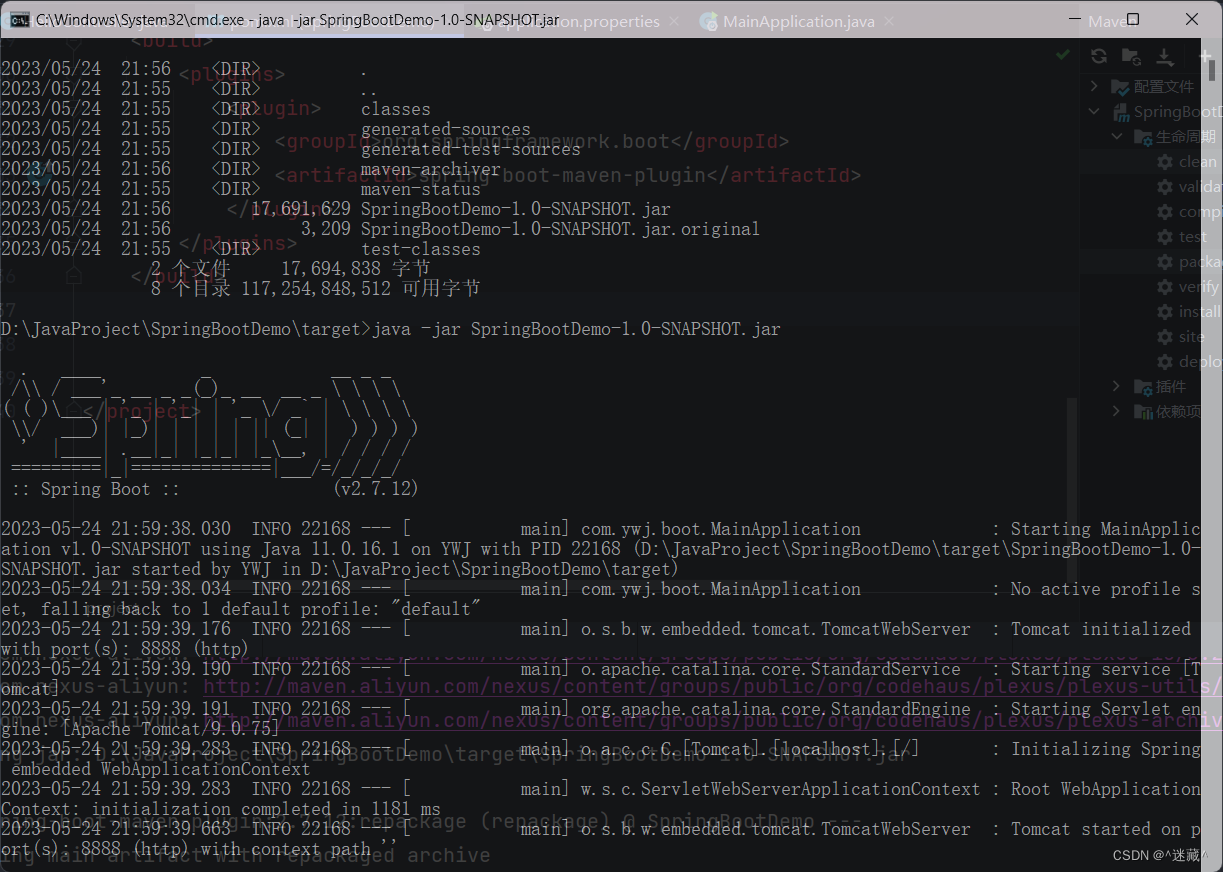
2022/11/13
HTML :讲完了
css:讲完了
作业:编写登陆界面、整理一下sql优化,对于mybatis不熟练的继续练习
关于MySQL优化的问题?
思路总结:主要考虑数据库优化与SQL语句优化。
1,数据库优化,包括存储引擎的优化,缓存的优化和内存的优化等。使用索引的优缺点 缺点:一张数据表,不建议过多创建 回表问题 优点 方便 数据结构
2,SQL优化。首先先判断什么样的SQL需要优化。
可以在MySQL中开启慢查询,设置成例如SQL执行时长超过5秒就可以定为慢SQL,并记录到日志中。
然后拿到慢SQL的执行记录和计划,通过explain关键字做分析。
分析思路有例如SQL存在索引,判断是否执行了索引或者索引失效原因,若索引未失效则要考虑索引创建是否合理,以及是否遵循最左匹配原则等。
索引失效的最常见的几个原因,
1.没有遵循最左匹配原则
2.like模糊查询时,%在最前面
3.where条件,后面使用<>,!= or可以替换为(union all)
4.where条件,后面使用表达式函数
5.where条件,多个条件 违反了索引最左匹配原则
6.where条件列,存储null值时,建议创建数据表的时候,所有列都就安逸设置成not null ,设置默认值
7.order by条件 索引失效场景和where类似 ----- 函数/表达式(尽量使用索引排序)
优化目标就是尽量不要进行全表扫描操作
2022/11/15
自我介绍
大家好,我叫刘陈晨,就读于江苏大学,我的专业是软件工程。我来自于江苏 南通。
我从小热爱体育运动,特长是乒乓球。
我乐于广交良友,周末聚聚餐,假期结伴出去旅游。
关于出生年月日:1999年2月10日
关于身高体重,我身高185cm,体重80kg
上大学后,当我接触到软件工程这个专业时,我就对它产生了浓厚的兴趣,觉得它非常神奇和有趣,于是从那时起我就下定决心要好好学习这门专业科目,学好一门 专业,就必须沉下心来,心无杂念,一心一意。
我的座右铭是:
请专心地自始至终地做好一件事!
自律是最好的武器!
我的生活状态只有:
- 专心认真地学习软件工程这门专业,为未来就业做准备。
- 2.每天抽出课余时间参加体育运动健身(身体是革命的本钱)
作业:HTML+CSS+JAVASCRIPT 登录注册-–用户输入数据的格式
前端两天的内容讲解完毕!!!
♥基本的sql语句:DQL DML
作业:
-
编写登陆注册页面,校验用户输入的格式:
用户名:数字,字母,区分大小写,#$!组成,不能使用数字开头,一共6位.
密码:数字,字母,区分大小写
-
CRUD增删改查 练习
动态sql
SSM,mybatis-plus,基础Vue,基础springboot
server.xml配置文件(修改端口) webapps 部署项目
中午演讲的题目:
- 手写单例设计模式
考虑并发问题
使用volatile关键字
2022/11/17
Servlet:
动态资源 : JavaEE动态规范之一 本质上其实就是一个servlet动态接口 (实现接口)
作用 :
接收用户请求
执行service方法:处理本次请求(调用mybatis/调用第三方的技术)
返回给我们的浏览器,响应处理结果数据
-
创建web项目
-
导入servlet依赖—注意:java servlet-api 一定要设置作用范围 provide
-
重写service方法
-
配置当前servlet访问路径 @webservlet(value=“/名称”)
-
启动项目,根据配置的名称访问
tomcat软件创建的servlet对象 tomcat软件创建的servlet对象,调用的方法 tomcat启动 会扫描所有的资源(动态资源和静态资源)1.扫描 注解 value=“” loads’tartup=“正数” tomcat软件 创建servlet,存储到一个动态资源的 浏览器发起请求 可访问动态资源
- tomcat检查当前动态资源是否已经实例化,直接调用service方法
- tomcat直接创建此动态资源servlet,并调用service方法
servlet生命周期:
实例化 loadstartup= 正数 初始化 服务 销毁
实现类:HttpServlet
request:请求 通用方式 getparam 获取请求参数对象 getparamValues获取多个请求参数对象
面试题目:
1.Volitail的底层原理—保证了什么性 内存屏障
JVM 底层是通过一个叫做“内存屏障”的东西来完成。内存屏障,也叫做内存栅栏,是一组处理器指令,用于实现对内存操作的顺序限制。
所以能禁止指令重排序,即volatile能在一定程度上保证有序性。
2.这十个线程都执行结束了 怎么知道结束了 用那几个方法可以
三种方法可以知道是否结束
1.设置退出标志,使线程正常退出,也就是当run()方法完成后线程终止
2.使用interrupt()方法中断线程
3.使用stop方法强行终止线程(不推荐使用,Thread.stop, Thread.suspend, Thread.resume 和Runtime.runFinalizersOnExit 这些终止线程运行的方法已经被废弃,使用它们是极端不安全的!)
前两种方法都可以实现线程的正常退出;第3种方法相当于电脑断电关机一样,是不安全的方法。
3.怎么创建线程池 核心线程 最大线程 和等待队列的关系 换个说法 非核心线程什么时候创建
//创建如下线程池 核心线程数2 最大活动线程数10 缓存队列2
private static ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 10, 1000L, TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(2), new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r,r.getClass().getSimpleName());
return thread;
}
});
创建核心线程 通过new ThreadPoolExecutor()创建 ()里面传入想要传入的参数
非核心线程:在每个线程运行都不结束的情况下,创建线程 创建1,2时 线程开始执行,然后开始使用核心线程,创建3,4线程的时候,因核心线程占用 3,4进入队列等待 然后紧接着创建5,6,7,8,9,10时,因核心线程被占用,等待队列已满,启用非核心线程,此时执行的线程为1,2,5,6,7,8,9,10,3,4等待中 创建11,12 此时并没有超过最大线程数限制 1,2,5,6,7,8,9,10,11,12刚好十个,所以11,12可以正常创建 创建13 超出最大线程数限制,报错
4.线程类ThreadLocal干嘛的 底层数据结构是啥
5.Mysql存储引擎为啥选Innodb
6.给一个表中的一个字段添加索引 什么语句导致索引失效
7.分库分表做过么 用什么组件做的
二、Volatile与Synchronized比较
Volatile是轻量级的synchronized,因为它不会引起上下文的切换和调度,所以Volatile性能更好。
Volatile只能修饰变量,synchronized可以修饰方法,静态方法,代码块。
Volatile对任意单个变量的读/写具有原子性,但是类似于i++这种复合操作不具有原子性。而锁的互斥执行的特性可以确保对整个临界区代码执行具有原子性。
多线程访问volatile不会发生阻塞,而synchronized会发生阻塞。
volatile是变量在多线程之间的可见性,synchronize是多线程之间访问资源的同步性。
HashMap:
hashmap是我们日常开发当中每天都需要用到的一个东西,他是一个集合,能够存储键值对,在jdk1.7到1.8之间,有两个比较重要的区别:jdk1.7版本之前时数组+链表 在jdk1.7版本的时候 使用的时分段锁 1.8版本的时候使用的是cas+cyn锁 而在jdk1.8版本之后 hashmap的结构则变为 数组+链表+红黑树 扩容因子为0.75 红黑树的引入是为了提高他的查询效率,因为我们链表的查询效率 查询时间的复杂度是0(n)而我们的红黑树的时间复杂度是o(log n) 还有一点比较重要的是 在jdk1,7之前 我们遇到哈希碰撞的时候,需要在链表上添加数据的时候采用的是头插法 但是在jdk1.8之后便 改用了尾插法 因为头插法在多线程的情况下会导致一些问题 比如他会形成循环链表 耗尽我们的cpu性能 为了解决这个问题 在jdk1.8之后改用了尾插法 jdk1.7到1.8 之间还进行了许多优化 我可能记不太清了 比如他的hash算法 接下来 我就用1.8来和你聊了 扩容 扩容因子:0.75 16* 0.75 = 12 当数组容量大于等于12 的时候 就会开始进行扩容操作 两倍扩容 树化:链表的结点大于等于8 当数组容量大于等于64 就会进行树化 链表长度小于6就会解除树化 当然扩容和树化都是比较消耗cpu性能的
- hashmap是我们几乎每天用到的集合类,它以键值对的形式存在。
2. 在jdk1.7中:底层是数组加链表,1.8中采用的是数组加链表加红黑树,红黑树的引入是为了提高查询效率
3. 1.7中hash碰撞采用头插法,头插法会形成循环链表,1.8尾插法
4. hash算法1.8进行了简化
5. 最好传入一个二的次幂的初始化容量, put时,会初始化数组,容量为大于等于初始化容量的最近的二次幂,比如初始化容量为6,他初始化就是8。
6. key的hash值 与 上容量-1,计算出所在位置
7. 扩容的问题:加载因子0.75,达到 容量 *0.75后就会扩容,两倍扩容
8. 树化,数组容量达到64,链表长度大于等于8,后才会进行树化,链表长度小于6就会解除树化
2022//11/19
算法:
- 冒泡排序
* 冒泡排序:原理解析
* 相邻两个元素 进行比较 大小
* 如果左边元素>右边元素
* 发生交换 (左边元素,右边元素)
- 二分查找
二分搜索法
* 1.先去定义一下 左边 跟 右边
* 2.因为不知道要查找几次就使用while循环
* 3.确定中间值 即为 左边加上右边除以2
* 4.进行判断 三种情况
* 1.中间值小于查找值 左边的值 等于 中间 +1
* 2.中间值大于查找值 右边的值 等于 中间 -1
* 3.中间值等于查找值 返回中间值
* 4.不然返回的是-1
- 快速排序
* 快速排序
*每一轮排序 采用一个基准点pivot进行分区
* 让小于基准点的元素进入一个分区 让大于基准点的元素进入一个分区
* 当分区完后之后,基准点元素的位置就是其最终位置
Lunix常用的几个命令:
netstat -aon | findstr 端口号
taskkill /f /PID 端口号
tasklist | findstr 端口号
jsp的缺点:遇到的概率非常低 本质上就是一个servlet
- 书写麻烦:特别是复杂的页面
- 阅读麻烦
- 复杂度高:运行需要依赖于各种环境,JRE,JSP容器,JavaEE…
- 占内存和磁盘:JSP会自动生成.java和.class文件占磁盘,运行的是.class文件占内存
- 调试困难:出错后,需要找到自动生成的.java文件进行调试
- 不利于团队协作:前端人员不会java,后端人员不精HTML
- … … …
2022/11/20
HTML(Ajax)—>servlet(推荐的模式)
| IT这行需要很扎实的计算机基础知识,包括离散数学、计算机原理、数据结构和算法、计算机网络等等,你必须有十分扎实的基础,不然是走不远的,所以这对老师的教学质量就至关重要 |
…
环境准备:
- 创建web工程:brandProject
- 导入依赖
项目经历:
- 自己在学校做过哪些项目
- 真实,自己做过哪些项目经历
- 切记不要流水账!
- 我做了什么项目
- 我在项目中负责哪一个部分
- 在项目开发中遇到哪些难题
- 我是怎么处理和解决的!
垃圾分类管理系统,我在项目中负责后端数据处理。在项目开发中,我遇到了许多问题,我是这么处理的?
2022/11/26
什么是IoC和AOP,什么又是JavaBean呢 ?
IoC理论:就是所有的实现类对象 对象与对象之间的关系全部交给程序来动态决定
单列模式和原型模式的区别?
当Bean的作用域为单例模式,那么它会在一开始就被创建,而处于原型模式下,只有在获取时才会被创建,也就是说,单例模式下,Bean会被IoC容器存储,只要容器没有被销毁,那么此对象将一直存在,而原型模式才是相当于直接new了一个对象,并不会被保存。
我们还可以通过配置文件,告诉创建一个对象需要执行初始化方法,以及销毁一个对象的销毁方法
我们还可以手动指定Bean的加载顺序,若某个Bean需要保证一定在另一个Bean加载之前加载,那么就可以使用depend-on属性。
spring容器适合管理的对象:如果可以复用 servlet service dao mapper的话 就直接交给spring单例模式。如果具有状态的对象,不适合交给spring 容器单例模式管理
2022/11/27
1.如何去注册和使用一个Bean?如何去给一个Bean去赋值?
可以通过property标签去实现,但是必须去设置一个set() 否则无法赋值
无参构造是无法给它去赋值的 IoC依赖注入 使用技巧 依赖注入DI
2.管理系统的增删改查后端以及前端 过两天考试
3.IoC容器、依赖注入DI: 创建并且去注册一个JavaBean , 使用xml文件配置去操作Bean对象
4.面向切面AOP:在运行时,动态的将代码切入到类的指定方法,指定位置上的编程思想就是面向切面的编程。也就是说,我们可以使用AOP来帮助我们在方法执行前或执行后,做一些额外的操作,实际上,就是代理。
5.CGLIB动态代理
2022/11/28
1.请求参数 如何去获取参数?
k-v格式的参数 拿取 req.getParameter
前端请求参数:post ,请求体 {} req.getReader().readline() JSON.parseObject(jsonStr,java对象.class)
2.响应处理结果1/0
resp.getWriter().writer(1/0)
3.返回结果是:Java对象 Java集合/数组对象 javaMap对象
返回结果数据:将Java对象转换成为json字符串 通过网络传送给前端 将json字符串,响应给ajax前端 resp.getWriter().writer(1/0)
业务层:
处理请求参数 调用多次的持久层 调用持久层
持久层:
编写持久层接口的Mapper接口方法:
1.参数个数 如何传递多个参数 散列,在补全占位符,区别不同的请求参数 地址定义k 使用@param
2.返回类型:
编写持久层接口Mapper接口方法 1.参数个数 2.返回类型 3.编写sql语句 insert添加 trim update更新 set delete删除 for each select查询 where if
前端: Vue + elementUI
内容回顾
1.数据库技术
MySQL:
基本的CRUD的SQL语句:
insert into 表名称(列名称列表) values(值的列表)
update 表名称 set 列名称1=值 ,列名称2=值 where 条件
delete from 表名称 where 条件
select 列列表 from 表名称 where 条件
order by 排序字段 asc | desc
groud by 分组字段
having 分组过滤条件
limit 起始位置,条数
Mybatis:
编写持久层接口Mapper接口方法
编写SQL语句 ---- Mabatis-Plus
Maven工具:
构建Java项目的工具 依赖管理 构建过程中的功能插件
2.前端技术
HTML-绘制页面,标签
CSS-美化页面。标签设置样式/属性
JavaScript-给页面添加交互行为,对标签进行Dom操作/添加事件
Vue/ElementUI-Vue,简化了js的DOM操作,MVVN思想实现 View和Model的双向绑定
ElementUI,提供了一套自带css/js的标签库-拷贝复制使用
3.后台技术
HTTP:按下F12,查看请求行/请求头/请求体中,方便定位问题- 问题的定位:前端还是后台 前端的请求参数是否发送成功 查看响应结果数据是否接收成功
Tomcat:Web项目部署到Web服务器上,用户通过浏览器访问 使用插件来运行 springBoot 内嵌服务器
Servlet:动态资源,作用:接收请求/处理业务/返回处理结果—接收请求参数—响应处理结果
JSP:(了解即可)
会话技术:cookie session 单层架构 session的底层是基于cookie
Filter/Lisenter/Ajax/JSON :
Filter:编写用户身份校验的过滤器 编写字符集设置的过滤器 过滤器的执行流程
Lisenter:(了解)
Ajax:使用axios发送ajax,接收处理结果,配置Vue
JSON:了解数据格式 掌握在Java后台实现Java对象和JSON字符串的转换
4.综合案例
Brand案例:写三遍
前端:HTML+Ajax 发送Ajax 接收处理结果
后端:三层结构 表现层 业务层 持久层
代理模式
基本的代理模式:设计模式的一种
静态代理是在编译期间就需要完成的,相当于每个类都要创建一个代理类,这样的代码冗余量很大。JDK提供的动态代理要求类实现invokationHandler接口,然后在运行时才去创建代理类,解决了静态代理代码冗余的问题。cglib是对JDK方法的一种补充或者说是一种强化,它对于没有实现接口的类也可以生成代理类,实现方式和JDK的实现方式差不多。
如果bean实现了接口,默认是JDK代理模式,如果bean没有实现接口会切换成CGLIB实现,也可以通过设置强制Spring使用CGLIB实现![[吃瓜]](https://img-blog.csdnimg.cn/img_convert/aabccf8e7d884e3475360c961ad02cda.png)
动态代理:
动态代理原理:
Mybatis:Mybatis:动态代理设计模式(封装了具体的实现,简化了JDBC的操作)(jdk cglib) 工厂设计模式(通过工厂创建一个会话对象)
Spring:
常被问到的面试题:
spring概述
Bean的生命周期
1.实例化 反射调用 无参构造
2.设置属性 反射调用set方法
3.初始化操作:配置init-method
4.销毁操作:配置destory-method
ioc是什么?
DI是什么?
2022/11/29
使用注解开发
通过注解的方式开发只能以实体类的形式进行配置
在配置的类上添加@ Configuration 注解 配置Bean的时候 只需要编写一个方法,并返回我们要创建的Bean对象,并在其上方添加@Bean注解 我们还可以继续使用@scope注解来指定作用域 可以使用原型模式 Bean的默认名称实际上就是手写字母的小写,我们也可以手动指定 此外、还有一种创建Bean的方法 就是直接在类上添加@Component注解来将一个类进行注册,不过还需要添加一个自动扫描,就是在配置类上添加一个@ComponentScan(“全路径的包名”)注解即可,如果套添加多个包进行扫描,可以使用@ComponentScans,与@Component同样效果的还有@Controller、@Service、@Repository,这几个现在暂时不提,后面SpringMVC再学习。
两种注册Bean的方式!!!!
1.xml配置文件方式,第三方的Bean的IOC和DI操作
2.spring容器的体系结构
3.(重点)注解开发
扫描注解
注解开发
注解开发的Bean的作用范围与生命周期管理
@PostConst
@DisPosableBean
2022/12/1
spring基础
IoC核心容器: 纯注解:创建对象 设置属性
整合:
1.单元测试 spring整合了单月测试之后,测试spring容器中的所有的Bean
2.整合MyBatis 持久层的步骤:
1.导入整合依赖 spring-jdbc mybatis-spring 版本需要保持一致 5.2.10.RELEASE 1.3.0 第三方 具体的整合的代码是mybatis自己写的 spring只是向外暴露了整合的一个接口
2.将sqlsessionFactory 对象交给容器管理
下午:
AOP切面思想:
连接点:所有的方法
切入点:增强的
通知:是一个方法 around通知方法 pointcut 切入点 被增强的方法 类里面放了一个通知
切面(aspect)
oop和aop的区别?
oop:封装继承 多态
aop:无入侵的动态增强
aop入门
导入坐标: spring aop aspectj
1.先写通知Adivice方法2.@Pointcut再写切入点表达式:定位需要增强的方法3.将切入点表达式和通知方法进行把一个绑定 4.@Component @Aspect 5.@EnableAspectJAutoProxy//开启aop功能----代理设计模式
mybatis编码流程
深入MyBatis框架
2022/12/2
作业:
1.自定义注解:kunkun
在业务层方法上添加自定义的注解kunkun
编写aop,实现对添加自定义注解@kunkun的方法进行增强
打印一下执行当前的方法的时间
事务
spring事务实现流程?
- 在业务层接口上添加Spring事务管理
- 设置事务管理器(将事务管理器添加到IOC容器中)
- 开启注解式事务驱动
- 运行测试类,查看结果
面试:
自定义aop
spring提供的申明式事务 遇到过一些异常失效的场景,当前你控制的方法,里面抛了一个编译期异常(IOException) 使用rollbackFor = {}
事务失效的场景:
1.业务方法中抛出了编译器异常,rollbackfor=编译器异常.class
2.业务方法没有被当前事务管控
3.当前事务方法的bean没有被spring
幻读和虚读的区别?
虚读是某个数据前后读取不一致,幻读是整个表的记录数量前后读取不一致
开启事务
首先在配置类中 编写一个TransactionManager方法、参数是@autowired datasource
2022/12/4
spring-MVC
简化web表现层的开发 底层任然是servlet开发
数据传送格式:
一:kv格式
二:json对象格式 @EnableMvc 在 springconfig 配置文件中 开启 @RequestBody jackson-databind 2.9.0 依赖
@requestParam用于接收url地址传参 请求行 请求体中的kv格式 专门 用来处理 kv格式
添加注册修改 使用json
删除详情 k-v
converter 数据类型转换 springMVC自动提供的
自定义时间格式参数 @datatime
前端最需要的是json字符串 json对象 json数组对象 转换成js对象
品牌项目
2022/12/5
2022/12/9
1.如何获取配置文件的属性?
方式一:@value(“${key}”) string key;
方式二:@Autowied
方式三:自定义一个Bean
2.springBooot 多套环境的配置?
第二种方式 新式的一种方式 yml
3.springboot项目中的拦截器的配置
和springMVC项目中一样 编写web配置类
2022/12/10
GIT:
作用:代码回溯 版本切换 多人协作 远程备份
git概述 代码托管服务 常用命令 在idea里面使用git
git下载安装 commit提交 push推送 pull 拉取 commit提交
2022/12/11
mybatis-plus继续学习
DML DQL
UUID 雪花算法
kv格式/json格式 各是什么样子
springBoot简化ssm项目开发 ssm:crud config spring boot+mp:crud
两年经验 手写git命令
2022/12/12
git 全局命令 :
设置用户信息
git config --global user.name “itcast”
git config --global user.email “hello@itcast.cn”
查看配置信息
git config --list
回溯版本
git reset --hard 版本号
怎么去将本地仓库跟远程仓库建立连接???
git remote add origin 远程仓库 (先关联在push)
git merage
聚合工程 和 父工程 才使用 pom打包
创建git add添加 输入一个url 远程仓库里面不允许有东西 建议是一个空的
DML 写操作
DQL 读操作
2022/12/15
业务流程分析:
登录、过滤器、业务流程:
1.登录:业务流程
1.查询用户名是否存在:表现层直接调用业务层。mp提供了业务层方法 适用于简单的业务,直接写在表现层。两种方法都可以的。
2.判断:用户名存在:判断密码是否存在—(需要md5加密)—后台管理员会看到密码
3.判断员工状态是否未禁用
4.登陆成功:返回当前用户信息(前端ajax接收到用户信息,存储到前端的本地缓存)
5.将用户信息存储到session中
前端代码(了解):
request.js
请求拦截器:
响应拦截器:
api—login.js:登录界面发起的所有ajax请求所在的脚本文件
api—member.js:员工页面发送的所有ajax请求所在的脚本文件
api—category.js—分类页面发送的所有ajax请求所在的脚本文件
api—food.js:菜品页面发送的所有ajax请求所在的脚本文件
api—combo.js:套餐页面发送的所有ajax请求所在的脚本文件
2.退出
业务流程:清楚session中存储的用户信息
3.登录过滤器
业务流程:
1.放行直接需要放行的
2.用户已经登录,直接放行
3.封装跳转登录页面的响应信息给ajax code ==0 msg == NOLOGIN
4.分页加条件查询员工:
动态sql: 使用mp提供的三参数api:动态拼接SQL语句 select(是否拼接此条件,列名称,数值)
5.添加员工:
8.统一异常处理:
统一的处理了约束异常
1.编写全局异常处理器
@ResrtControllerAdvice
2.编写处理此异常的处理方法
@ExceptionHandler(异常类型)
6.修改员工状态
7.编辑员工信息
查询指定员工信息
更新员工信息
问题;查询和更新无法获取到员工信息?
原因:js接收到的长整型数据回存在数据精度丢失
解决:
-
1.长整型设置字符串类型
-
2.自定义json数据的转换器
-
long—string
9.自定义jackson转换器:
复制转换器:JacksonObjectMapper 将Java对象中的long/bigint属性转换成字符串放置在json字符串中
配置转换器:Java—json数据之间的转换
实现的功能
拓展—自动填充功能—使用填充注解@TableFiled(fill = FiledFill.INSERT)生成器策略部分也可以配置
自定义实现类MyMetaObjectHandler
发现一个问题:
用户id写死了
1.分页查询
2.删除分类
3.更新分类
4.添加分类
2022/12/16
短信服务的代码实现
采用的是阿里云短信服务:
应用的场景有:
- 验证码
- 短信通知
- 推广短信
2022/12/17
这两天将菜品和菜单的功能写完就可以了
2022/12/18
回显功能 一对多 list setmeal_dish 创建一个setmealDto 换了两张表而已
批量删除 批量添加 为什么要先删除在添加?
点击添加菜品—数据会回显list?catergory99999 接口
先添加套餐 拿到套餐id 在将数据添加到套餐里面
套餐管理:
2022/12/23
登录
地址
购物车
订单
从dish开始需要封装DTO对象
2022/12/24
安装使用redis 开源的 基于c语言的 kv格式非关系型数据库 思维导图
2022/12/25
1.观看07录课视频1 √
用户登录模块任务:
接口一:手机验证码
接口二:登录
接口三:退出
2.观看07录课视频2
2022/12/30 项目二 实战
入职第一天
一.入职准备工作
-
安装基本的电脑环境
- 安装jdk
- 安装idea
- 安装git
- 安装maven
-
拉代码(一般使用gitlab)
----拉不下来,没有权限 not authorized (问领导加权限)
----依赖报错,依赖下不下来(私服,没有权限,问领导加权限)
如何拉取代码?(两种方式)
- git clone === 远程仓库拉取到本地
- 先创建本地仓库 === 远程的仓库地址和本地的仓库地址 创建关联
-
了解该项目
----做什么的?
----看下产品的需求文档
----看下代码的模块
----看下表结构
后端:
导入数据库
修改用户名密码
前端:
安装node.js工具
备注:先安装v14版本 如果不行 就卸载掉 重新安装v12 如果不行 官网下载v16
node -v npm -v 出现版本号
打开huike-crm-web npm run dev 直接启动
备注:启动可能会失败===中文路径(去掉)
密码admin123
postman 测试代码的工具的熟练使用
2022/12/31 项目二 第二天
统一返回结果集 huike—common AjaxResult.java 静态的方法 类可以直接调用
一.登录验证码 验证码后台生成的 1.验证码 2.用户名 3.密码 captchaImage链接=访问后台的验证码 对业务不熟悉的时候=从页面找相关的请求F12=业务逻辑=公司代码又长又乱
一、登陆验证码业务流程讲解?
生成uuid
使用谷歌的第三方工具 google.code.kaptcha 创建 一个字符串 “7*1=?@7”
截取 字符串 @得出7 这个结果答案,将结果7放入到redis中(key是uuid,并设置失效时间)
将7*1=?前半部分字符串 使用第三方工具 kaptcha生成字符串图片
最终将uuid和图片输出到前端页面
二.登陆的完整流程—jwt+token+springsecurity
1.问题:什么是token?
答:token的意思就是令牌,是服务器生成的一串字符串,作为客户端进行请求的一个标识。当用户第一次登录后,服务器生成一个token,并将此token返回给客户端,以后客户端只需带上这个token前来请求数据即可,无需再次带上用户名和密码。简单的token的组成:uid(用户唯一的身份标识)time(当前时间的时间戳) sign(签名:将请求URL、时间戳、uid进行一定的算法加密)
2.问题:jwt 和传统 session 有何优势?
优点:
-
与session相比,可以跨服务器
-
避免cookie存储遭受CSRF(跨站请求伪造的攻击)以及cookie跨域限制问题
问题:token ,jwt 和 session 的区别?
JWT区别:
JWT:Json Web Token
有自己的一套规则
是无状态的,不用将token存储在内存或者db中
也不用自己另外去存储过期时间
3.问题:Springsecurity 是安全权限框架?
2023/1/1
Security登录校验流程是什么?
前端:1.携带用户名密码访问登录接口====》
服务器:2.去和数据库的用户名和密码进行校验3.如果正确,使用用户名/用户id,生成一个jwt(类似于加密)4.把jwt响应给前端
前端:登录后访问其他请求需要在请求头中携带token===》
服务器:获取请求头中的token进行解析,获取userID,根据用户id获取用户相关的信息,如果有权限则允许访问相关资源,访问目标资源,响应给前端
前端:接收响应信息
思路分析
登录:
①自定义登录接口
调用ProviderManger的方法进行认证 如果认证通过生成jwt
把用户信息存入redis中
②自定义UserDetailsService
在这个实现列中去查询数据库
校验:
①定义Jwt认证过滤器
获取token
解析token获取其中的userid
从redis中获取用户信息
存入SecurityContextHolder
2023/1/2
问题:你写项目时,有没有遇到什么难点?
日志问题,异步线程池的方式去解决日志记录,创建一个类,饥饿加载(提前创建内存提高新跟那个效率),并创建了一个延迟任务的线程池(延迟10毫秒),执行延迟任务(任务就是将相关的数据信息记录到 数据库表中—采用TimeTask异步执行任务,即使插入报错也不会影响主线程执行)
今天的任务???
接口和接口之间是继承关系
mybatisplus能不能正常去使用?测试一下
1.实体类的类名和数据库的表名不一致的时候去使用@tablename(“----表名—”)去指定一下,在对应的主键上也加上一个注解@tableid就可以了
2.组件扫描:在启动类上加上@mapperscan(“------com.sangeng.mapper–”)去指定一下就可以了
修改密码变成明文输出?
在密码前面加上(noop)即可
Bean的生命周期?
对象的创建—属性的赋值—对象的初始化—销毁
init-method destory-method applicationContext.xml—不用
@PostContructor
2023/1/4
作业:
- bug的修复 5 over
- 优化代码
- bug的修改 修改权限 去看懂hasPermi这个方法即可
Redis(属于NoSQL非关系型数据库)
1.NOSQL相比传统的SQL关系型数据库的区别?
- 不保证关系数据的ACID特性
- 并不遵循SQL标准
- 消除数据之间关联性
2.NOSQL与MySQL相比有何优势?
- 远超传统关系型数据库的性能
- 非常易于拓展
- 数据模型更加灵活
- 高可用
- 高并发海量数据的解决方案
策略模式
开胃菜2
2023/1/6
作业
day03—文档下发—上午—11-1按接口开发
任务:
①今日简报—今日新增线索
②待办事项—待跟进线索—待跟进商机
③统计分析—客户统计和线索统计
数据权限 接口权限 并不一样 token数据共享 放入本地线程
线索+商机+分配表
- 查询分配表 time = 今日now() type = 0 当前的用户userid or name = id and lateast = 1(最新分配人)
controller持久层 用户界面表示层
service业务层 业务逻辑层
dao mapper 数据层 数据访问层
2023/1/7
SpringSecurity框架教程P13 12.数据库校验用户核心代码实现
Redis 缓存技术 已完结(2021版本)P2 基本操作
Java获取时间段内的每一天
格林威治时间 国际标准时间
public static List<String> findDaysStr(String cntDateBeg, String cntDateEnd) {
List<String> list = new ArrayList<>();
//拆分成数组
String[] dateBegs = cntDateBeg.split("-");
String[] dateEnds = cntDateEnd.split("-");
//开始时间转换成时间戳
Calendar start = Calendar.getInstance();
start.set(Integer.valueOf(dateBegs[0]), Integer.valueOf(dateBegs[1]) - 1, Integer.valueOf(dateBegs[2]));
Long startTIme = start.getTimeInMillis();
//结束时间转换成时间戳
Calendar end = Calendar.getInstance();
end.set(Integer.valueOf(dateEnds[0]), Integer.valueOf(dateEnds[1]) - 1, Integer.valueOf(dateEnds[2]));
Long endTime = end.getTimeInMillis();
//定义一个一天的时间戳时长
Long oneDay = 1000 * 60 * 60 * 24L;
Long time = startTIme;
//循环得出
while (time <= endTime) {
list.add(new SimpleDateFormat("yyyy-MM-dd").format(new Date(time)));
time += oneDay;
}
return list;
}
实例:
public static void main(String[] args) throws Exception {
System.out.println(findDaysStr("2021-09-01", "2021-09-08"));
}
结果:
[2021-09-01, 2021-09-02, 2021-09-03, 2021-09-04, 2021-09-05, 2021-09-06, 2021-09-07, 2021-09-08]
面试题背诵
作业
- 漏斗图
- 商机转龙虎榜
- 线索转龙虎榜
异步并发线程
sql越多 导致 速度和效率慢
CompletableFuture 专门用于异步执行 可以看成是一个线程池 .supplyAsync
join的作用:等待所有的sql 一起执行完
需要返回值—供给型
并发执行 等所有的sql一起执行完
get 获取结果result
任务:改造代码
实体类封装的规范化
前端浏览器 发请求 controller service dao
post 提交表单 vo对象(OrderVo) dto 对象(OrderDto) po对象(Order)
id 用来封装前端发送的所有数据信息 username 就是在controller中提炼 真正和数据库表
username phone 传入的数据 字段一致的对象
phone sex 数据
qq orderid
wechat price
sex status
address
orderid
price
status
第四天的任务
day04 任务下发 设计表 15理解新需求 实现4个功能
大致原因:dao接口无法创建bean,导致service层依赖无法注入,导致controller层依赖无法注入
归根结底:一个bean创建失败
- controller层service层dao层注解是否都使用正确?
- 接口有没有写实现类,实现类实现的接口是否正确?
- xml映射文件里路径大小写类型是否正确?
- 有重复命名的xxxMapper.xml文件吗?
- 接口名字是否重复?
在xml中大于号使用>; 小于号使用<;
第三天的需求:漏斗图完成√
2023/1/9
- 线索跟进
- zhangsan – 伪线索 – 伪线索不需要下次的跟进时间 要多设置一次时间 为null
- 商机–
aop oop的区别
- aop读取代码 是从上往下 缺点:非常累 少丢
在不改变源代码的基础上,对代码功能进行增强(增加代码或者减少代码)
-
aop 切面 切入点 为了补充oop大量的对源代码的增加和减少
-
aop重要的概念:
-
切入点:切的某个方法(多个方法)
-
@pointCut(“execution(“com.itheima.clue.clueservice.findById()”)”) 多个方法的切入 @pointCut(“execution(“com.*.*.insert*(..)”)”) -
通知:(五种通知类型)—》再切的方法前,后,环绕 去增强代码
-
切面:表示切入点和通知的关系—》把他两拉在一起
-
连接点:
-
Joinpoint---》获取原方法的 参数,原方法的名称,原方法的对象
-
使用aop 面向切面编程 + 异步进行操作的日志记录
流程: 在框架里面
- 自定义一个log注解 切入点 切面 通知类型 + 异步日志(看上面)
- aop面试必问
第五天: 学习两个新的知识 EasyExcel Minio
线索跟进完成
商机跟进完成 作业完成
poi apache easyExcel 阿里巴巴
常用场景:
- 大量的用户信息导出为excel表格(导出数据)
- 将Excel表中的信息录入到网站数据库(习题上传) 大大减轻网站录入量
操作Excel目前最流行的就是Apache POI 和阿里巴巴的 easyExcel 开源的
理解:POI比较复杂,所以我们去使用easyExcel–Java解析Excel的工具
区别:
性能:内存问题:POI=100w 先加载到内存OOM。。(一次性全部返回)再写入文件 es = 1 通过磁盘 一行一行的去返回
注意对象的一个区别,文件后缀!
2023/1/10
office办公软件的都可以使用poi读写
使用excel比较多的话 就可以使用easyexcel
demoDao
监听器注入DemoDAO 为啥不用@autowire?
因为listener不归spring管理
依赖注入的前提是bean对象都在spring容器当中
监听器的jar包是阿里巴巴的 不是spring
构造函数 构造器 把代码注入 进来
mysql 慢 的 原因?
执行一次加载一遍
1.加载驱动
2.连接数据库地址
3.connext statement
4.创建sql
5.关闭连接
提高效率的操作?
100条数据 加载一次
/**
* 最简单的读
* <p>
* 1. 创建excel对应的实体对象 参照{@link DemoData}
* <p>
* 2. 由于默认一行行的读取excel,所以需要创建excel一行一行的回调监听器,参照{@link DemoDataListener}
* <p>
* 3. 直接读即可
*/
@Test
public void simpleRead() {
// 写法1:JDK8+ ,不用额外写一个DemoDataListener
// since: 3.0.0-beta1
String fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭
// 这里每次会读取3000条数据 然后返回过来 直接调用使用数据就行
EasyExcel.read(fileName, DemoData.class, new PageReadListener<DemoData>(dataList -> {
for (DemoData demoData : dataList) {
log.info("读取到一条数据{}", JSON.toJSONString(demoData));
}
})).sheet().doRead();
// 写法2:
// 匿名内部类 不用额外写一个DemoDataListener
fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭
EasyExcel.read(fileName, DemoData.class, new ReadListener<DemoData>() {
/**
* 单次缓存的数据量
*/
public static final int BATCH_COUNT = 100;
/**
*临时存储
*/
private List<DemoData> cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
@Override
public void invoke(DemoData data, AnalysisContext context) {
cachedDataList.add(data);
if (cachedDataList.size() >= BATCH_COUNT) {
saveData();
// 存储完成清理 list
cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
saveData();
}
/**
* 加上存储数据库
*/
private void saveData() {
log.info("{}条数据,开始存储数据库!", cachedDataList.size());
log.info("存储数据库成功!");
}
}).sheet().doRead();
// 有个很重要的点 DemoDataListener 不能被spring管理,要每次读取excel都要new,然后里面用到spring可以构造方法传进去
// 写法3:
fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭
EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();
// 写法4: 使用 try-with-resources @since 3.1.0
fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 一个文件一个reader
try (ExcelReader excelReader = EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).build()) {
// 构建一个sheet 这里可以指定名字或者no
ReadSheet readSheet = EasyExcel.readSheet(0).build();
// 读取一个sheet
excelReader.read(readSheet);
}
// 写法5: 不使用 try-with-resources
fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 一个文件一个reader
ExcelReader excelReader = null;
try {
excelReader = EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).build();
// 构建一个sheet 这里可以指定名字或者no
ReadSheet readSheet = EasyExcel.readSheet(0).build();
// 读取一个sheet
excelReader.read(readSheet);
} finally {
if (excelReader != null) {
// 这里千万别忘记关闭,读的时候会创建临时文件,到时磁盘会崩的
excelReader.close();
}
}
}
invoke 每一条数据都会走这个
方法2 缺点 匿名内部类写的太长了
方法3 用的最多 将方法2 单独抽取出来
注解 @ExcelProperty(1 2)
字型不匹配
1.index 下标
2.中文 string ”日期标题“
/**
* 文件上传
* <p>1. 创建excel对应的实体对象 参照{@link UploadData}
* <p>2. 由于默认一行行的读取excel,所以需要创建excel一行一行的回调监听器,参照{@link UploadDataListener}
* <p>3. 直接读即可
*/
@PostMapping("upload")
@ResponseBody
public String upload(MultipartFile file) throws IOException {
EasyExcel.read(file.getInputStream(), UploadData.class, new UploadDataListener(uploadDAO)).sheet().doRead();
return "success";
}
Integer 默认值是null 空指针异常
作业,importResultDTO 成功数量 失败数量
解决 :
1.改成int 类型 默认值是0
2.将 变量 初始值 变为 0 private Integer successNum = 0
MinIO download windows 上午 技术调研 minio 启动命令
.\minio.exe server ./data
2023/1/11
SpringCloud学习
2023/1/12
题目讲解
3.@postmapping(/{a}/{b})
add(@pathvairable a ,。。。,@pathparam name,。。。)
**4.**restcontroller = testbody + controller
5.只是为了标准
6.#{} 占位符 = 防止sql注入 ${} 传值 不安全 有注入的风险
10.验证码的流程:
通过开源工具生成验证码的公式和结果,截取结果部分@,使用uuid为key,验证码的结果为value存入到redis中,并设置超时时间为2分钟,将uuid返回给前端,将内存中验证码的图片使用base64转码后返回给前端
springcloud微服务架构-黑马视频
- 微服务架构演变
单体架构:简单,部署成本低 但是耦合度高
分布式架构:服务 耦合度低、利于服务升级拓展 跨域远程调用
拆分粒度 集群地址 远程调用 服务健康状态
微服务=分布式架构最佳的实践 唯一的业务能力,单一职责,避免重复业务开发
-
单一职责
-
面向服务 对外暴露业务接口
-
自治 符合敏捷开发的思维
-
隔离性强
- SpringCloud
zookeeper 集群管理
vue 是前端的额框架 Javascript的框架 body是属于视图 视图是属于静态的
在
js代码 怎么去赋值 首先先去获得这个对象 然后在进行赋值 getElementById().value = 赋值;
如果不赋值 就会直接去获得这个值
编码是否存储静态的代码去获得 两部分 渐进式的javaScript框架
vue 动态的框架 优先级 vue框架代码>div代码块
要记得引入vue的参数文件 位置在官网上面
elementui 分页效果 一边是柱状图 一边是饼图
2023/1/20
SpringCloud 学习
晴空霞光视频:P1
2023/1/29
第一节课
10天左右的课程 高级框架 黑马头条项目 简历面试 在做一个项目 3.18号 整体结束
部署步骤:打包——使用命令:Java-jar进行部署
自动化部署:Jenkins
注意:重点关注流程
小公司不会使用分布式架构 因为烧钱
单体架构:
将一个整体项目打成一个包,并且部署在一个服务器中
缺点:耦合度高
优点:结构简单,成本低
分布式架构:
将一个单体架构项目按业务功能进行拆分,拆成多个单体服务,分别进行部署
缺点:结构复杂,存在模块间互相调用的问题
优点:耦合度低
微服务架构:
拥有良好设计的分布式架构
1.单一:拆分更细
2.面向服务:各个服务间的调用只依赖http请求的url
3.自治:有自己的数据库,各个服务可以独立运行
4.隔离性:每个拆分的服务互相隔离
微服务架构他是一个概念:
看得见摸不着;
Springcloud 微服务框架:他是一个集合体——包含了各个组件(注册中心,配置中心,网关等等)
Springcloud+Springboot最佳搭档
问题:整理一下
1.微服务是什么?
微服务架构是一种架构模式或者说是一种架构风格,它提倡将单一应用程序划分为一组小的服务,每个服务运行在其独立的自己的进程中,服务之间相互协调、互相配合,为用户提供 终价值。服务之间采用轻量级的通信机制互相沟通(通常是基于HTTP的RESTful API),每个服务都围绕着具体的业务进行构建,并且能够被独立的构建在生产环境、类生产环境等。另外,应避免统一的、集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建,可以有一个非常轻量级的集中式管理来协调这些服务,可以使用不同的语言来编写服务,也可以使用不同的数据存储。
2.spring cloud 和 Spring Boot 有什么区别?
优点:拆分更细 互相调用 独立运行 每个服务之间可以互相隔离 主流框架是springcloud 并不是唯一的
一般spring cloud结合springboot使用 spring boot里面有大量的自动配置 起步依赖 不需要写大量的配置依赖
区别:spring cloud 是框架 微服务框架 一个spring框架 两者没有任何的关联 springboot概念 快速启动spring框架的技术 两者没有任何的关系
SpringBoot专注于快速方便的开发单个个体微服务
SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务整合并管理起来,
为各个微服务之间提供,配置管理、服务发现、断路器、路由、微代理、事件总线、全局锁、决策竞选、分布式会话等等集成服务
SpringBoot可以离开SpringCloud独立使用开发项目, 但是SpringCloud离不开SpringBoot ,属于依赖的关系.
SpringBoot专注于快速、方便的开发单个微服务个体,SpringCloud关注全局的服务治理框架。
微服务的远程调用:
RestTemplate模板对象(springmvc的东西)发送http的请求的
负载均衡:
轮询:从头开始挑一个
eureka注册中心创建步骤:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
//表明它是一个注册中心的服务端
@EnableEurekaServer
@SpringBootApplication
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class, args);
}
}
server:
port: 10086
spring:
application:
name: eureka-server #服务名也很重要
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka/ #eureka也是一个微服务,也需要注册到自己注册中心
2023/1/30
Ribbon负载均衡
通过eureka上面的注册的服务名来访问ribbon负载均衡
如果单独的将eureka上面注册的服务名使用—估计是打不开的—不能访问的local host:8080 = 服务名 一定是通过注册中心的来调用的 如果单独使用是无效的
发送请求取得时候 是通过注册中心的来发送的 单独发起是无效的
Ribbon体现:@loadBalanced 从eureka上面匹配 没有 异常 有 拉取 轮询 随机 权重 默认的是轮询机制
nacos eureka 的区别
搭建一个
nacos的配置管理
2023/1/31
一、@value spring框架容器里面 @refreshScope 实现热更新
二、映射 @configurationproperties(prefix= “ 一级 目录”)
fegin
- 远程调用
- 引入fegin的依赖
- 开启fegin的注解
- 创建fegin调用的远程接口
- 满足要素:请求方式、服务名称、路径、参数
2023/2/1
自习:
- nacos配置管理
- Feign远程调用
- Gateway服务网关
- Gateway服务网关
- 断言工厂
- 过滤器工厂
- 跨域问题
Docker 容器
Docker就是为了解决组件过多的问题 解决依赖兼容的问题
依赖解决的方法:打包成镜像(应用,函数库,依赖项,配置)
隔离机制:采用的是沙箱机制,运行在容器中,相互隔离
仅仅只需要依赖linux内核即可
2023/2/2
今天学习的内容给是docker
复习
流程 :
Docker
- 安装
- 命令
- 镜像
- 容器
作业
- nginx 镜像 容器 挂载 登哥最帅
2023/2/4
微服务保护
2023/2/6
分布式事务 seata
复习:feign同步调用的情况下 使用sentinel 对这个微服务进行保护
- 流量控制
jar包 骑起来 整合 每个微服务 点 默认展示controller
- 熔断降级 直接 关联 链路
- 流控效果 直接失败 直接给他一个失败 缓冲 队列
- 降级逻辑
- 熔断 三种状态 close open
- 异常比例 异常数 慢调用
事务:跨域调用事务 spring事务 适合单机 不能控制别的服务的spring事务
分布式事务:事务的ACID原则
spring @translation 控制多个事务
第三方 来控制服务
cap理论:
AP 和 CP
BASE理论:
对CAP理论的一种补充和解决方案
2023/2/7
MQ:高并发量
-
作用和优势
-
不需要时效性太强 数据存在MQ中 对数据进行保护 并发量:每秒发送的qbs 平时正常没有并发量 节假日并发量上来 大概是几十 一两百 华为大概一两千 数据量: 下订单 查询 一天大概几千 -
什么场景下业务 使用这种MQ?
微服务保护:
先说概念 采用sentinel这样的技术场景,当时有很多的技术方案,也不是我写的。当时是经过我们几个人讨论,采用什么样的产品对我们的微服务进行保护,sentinel比较好用,就绝对采用这个。
讲产品:就是一个springboot工程,阿里开发的,有一个客户端,整合微服务,依赖配上地址,微服务方法 端点 加入到里面进行相关的操作,1从源头上进行控制qbs2.熔断控制 直接限流 关联限流 链路模式
如果业务已经失败 自己写一个降级逻辑,当服务失败的时候,返回一个null或空字符串,实现一个fallback接口。
断路器的作用:在客户端进行规则,异常比例 异常数。断路器打开之后,调用降级逻辑,达到他的熔断时长,然后就会继续,如果成功,就关闭。反之
seata:
怎么控制的?
两个理论:cap base 两个模式 cp ap 最终一致性 强一致性
seata的结构:三种角色 TC 判断 TM 区分 RM 提交 子事务
三种模式: XA AT TCC 默认AT 性能比较好 最总一致 ap 模式
第一阶段:各个子事务分别执行和提交事务,将提交的数据记录在undo_log
第二阶段:TC 判断结果,成功删除数据快照表,失败根据快照表的xid 数据恢复,删除快照表
与nacos进行整合
细节方面:
data-source-proxy-mode: AT
@GlobalTransactional // 控制全局事务
分布式redis
redis持久化
RDB 数据备份文件 数据快照 把记录保存在磁盘 加载到内存 关掉之后,把数据保存到磁盘中
RDB:全量打包文件----将内存中数据整体打包成rdb文件
save指令---同步,会阻塞所有指令
bgsave指令---异步,开启另一个进程执行指令
redis停机时就会执行一次RDB操作bgsave打包
AOF 追加文件 命令日志文件
开启AOF appendonly yes
-
redis的主从
搭建: 1.复制三份redis 2.修改端口号和目录 3.起三台redis服务 4.从机salveof<master ip><master port>数据同步原理:
全量同步:
- 主从第一次同步:
增量同步:
-
redis的哨兵
作用: 1.监控:心跳机制 -
redis的集群
2023/2/8
复习MQ:
同步调用
同步通讯:feign 存在问题:耦合度高,每次加入新的需求,需要修改原来的代码 性能下降 需要等待响应 如果调用链过长则响应时间等于每次调用的时间之和 资源浪费 每个调用链在等待的过程中,不能释放请求中占用的资源,高并发场景下会记得浪费系统资源 级联失败 如果服务提供者出现问题 则会出发多米诺骨牌效应 迅速导致整个微服务群故障
同步调用优点:时效性比较强,可以立即得到结果
缺点:耦合度高 性能下降 资源浪费 级联失败
异步调用
流程:
publisher事件的发布者---broker中间人---consumer事件的订阅者
好处:
-耦合度低,每个服务可以灵活插拔,可替换
-吞吐量提升
-故障隔离,不存在级联失败
-不会造成资源阻塞,占用,不会浪费资源
-流量削峰,不管发布的事件的流量的波动多大,都由broker接收,订阅者可以按照自己的速度去处理事件
缺点:
-构架复杂
-需要依赖broker
目前mq就是一种比较成熟的broker技术
1.简单模型
2.工作模型:多个消费者绑定一个队列,同一个消息只会被一个消费者处理。通过设置prefech来控制消费者预取的消息数量
3.发布订阅模型:多了一个exchange角色 exchange有三种类型:fanout广播 Direct定向 topic通配符
fanout:将消息交给所有绑定到交换机的队列
Direct定向:把消息交给符合指定routingkey的队列
topic通配符:把消息交给符合routingpattern(路由模式)的队列
2023/2/9
明天的需求:算工资的需求
MQ高级
至少要消费一次,可靠性。-----消息可靠性
延迟消息问题。--------死信交换机
消息堆积问题。----------惰性队列
高可用问题。--------MQ集群
消息可靠性
三种丢失消息的方式
2023/2/10
若依模板学习
2023/2/12
分布式服务:注册中心nacos 、springcloud 、MQ 、ES
初识ES:数据库 解决mysql海量数据模糊查询性能不高的问题
- 搜索引擎,数据库,搜索,海量数据
- kibana客户端类似于navicat
- ELK logstash kibana beats elastisearch
- Lucene Java的jar包 第三方的jar包 核心api
概念:分布式搜索数据库,查询海量数据
ELK:elasticsearch(服务器),kibana(客户端),logstash(分析日志)
倒排索引:分词 文档id 信息存储
将文档数据(指定某个列)进行分词,形成一个个词条。条件查询
2022/5/24
springmvc的Bean的加载和控制的学习:
springmvc的相关Bean是由springmvc加载的(表现层的Bean)
spring加载的业务层的Bean和数据层的Bean(service和 datasource还有dao的)
提问:因为功能的不同,怎么去避免Spring错误的加载到SpringMvc的Bean?
SpringMvc的Bean:在加载Spring控制的Bean的时候排除掉SpringMvc控制的Bean。
SpringMvc加载的Bean对应的包均在com.heima.controller包内
Spring相关的Bean的控制:
方式一:设置spring扫描范围为精准范围
//在springconfig类中的这个注解里面写上具体扫描到哪个包下
//@ComponentScan注解扫描多个包可以使用数组的方式,即使用大括号的方式书写多个包名即可
//不扫描dao包的话:通用性就会差一些
//通用性差一些:不管使用什么数据层技术,我们现在使用的是mybatis数据层技术,如果不扫描dao包的话,数据层的Bean就会无法加载出来,简单来说,写上扫描dao包没毛病。
@ComponentScan({"com.itheima.service","com.itheima.dao","com.itheima.xxx"})
方式二:设置扫描范围大一点,设置扫描范围为com.itheima,排除掉controller包内的Bean
//在springconfig类中直接扫描整个大的的范围的包
//在@ComponentScan注解中:设定包含的过滤器:includeFilters 设定排除的过滤器: excludeFilters
//我要去扫描com.itheima里面的所有的东西,但是我要排除掉一些东西,我按照注解排除,如果发现注解是controller的话,就直接排除掉
@ComponentScan(value="com.itheima",excludeFilters = @componentScan.Filter(type = FilterType.ANNOTATION , classes = Controller.class))//excludeFilters:排除扫描路径中加载的bean,需要指定类别(type)与具体项(classes)
//在使用排除controller的Bean的同时,要注意将springconfig里面的@ComponentScan注解去除,因为spring会将@ComponentScan上面的类加载到spring容器当中,就相当于排除了之后又给重新加进去了。
方式三:不区分spring与springmvc的环境,加载到同一个环境中
使用AbstractAnnotationConfigDispatcherServletInitializer来代替AbstractConfigDispatcherServletInitializer
ServletContationersInitConfig也是 extends AbstractAnnotationConfigDispatcherServletInitializer然后继承父类的三个方法:比较方便 直接在方法后面写上{配置文件.class}即可
postman软件的学习
功能:用于接口测试的软件 异步请求
get请求
post请求 发个表单
ajax请求 不光发个表单 还得写个js代码 一点提交 发送异步请求
响应 主要是异步调用,所以主要集中在json这块
团队多人开发,每个人设置不同的请求路径,冲突问题如何解决?
设置模块名作为请求路径前缀
如何传递参数?
后端:直接使用行参的形式即可,两个参数就往后继续写即可
前端:postman里面Get请求使用的是 ?name = xxx & age = xxx
乱码处理方式?
//乱码处理@Overrideprotected Filter[] getServletFilters() { CharacterEncodingFilter filter = new CharacterEncodingFilter(); filter.setEncoding("UTF-8"); return new Filter[]{filter};}








![[极客大挑战 2019]HardSQL1](https://img-blog.csdnimg.cn/img_convert/371f807c75ee420b9af63daf209682b8.png)