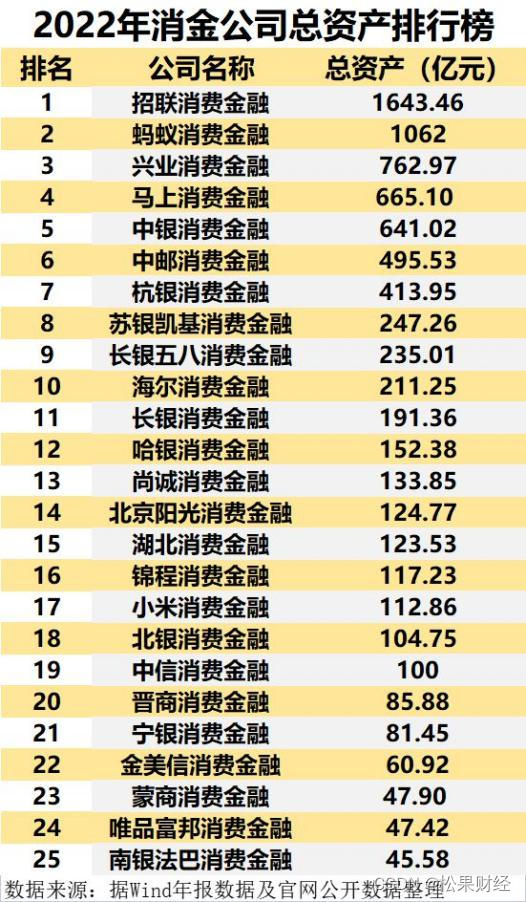
mprotect()函数
使用系统调用 mprotect()可以更改一个现有映射区的保护要求,其函数原型如下所示:
#include <sys/mman.h>
int mprotect(void *addr, size_t len, int prot);
参数 prot 的取值与 mmap()函数的 prot 参数的一样,mprotect()函数会将指定地址范围的保护要求更改为参数 prot 所指定的类型,参数 addr 指定该地址范围的起始地址,addr 的值必须是系统页大小的整数倍; 参数 len 指定该地址范围的大小。
mprotect()函数调用成功返回 0;失败将返回-1,并且会设置 errno 来只是错误原因。
msync()函数
前文提到过,read()和 write()系统调用在操作磁盘文件时不会直接发起磁盘访问(读写磁盘硬件), 而是仅仅在用户空间缓冲区和内核缓冲区之间复制数据,在后续的某个时刻,内核会将其缓冲区中的数据写入(刷新至)磁盘中,所以由此可知,调用 write()写入到磁盘文件中的数据并不会立马写入磁盘,而是会先缓存在内核缓冲区中,所以就会出现 write()操作与磁盘操作并不同步,也就是数据不同步。
对于存储 I/O 来说亦是如此,写入到文件映射区中的数据也不会立马刷新至磁盘设备中,而是会在我们将数据写入到映射区之后的某个时刻将映射区中的数据写入磁盘中。所以会导致映射区中的内容与磁盘文件中的内容不同步。我们可以调用 msync()函数将映射区中的数据刷写、更新至磁盘文件中(同步操作), 系统调用 msync()类似于 fsync()函数,不过 msync()作用于映射区。该函数原型如下所示:
#include <sys/mman.h>
int msync(void *addr, size_t length, int flags);参数 addr 和 length 指定了需同步的内存区域的起始地址和大小。对于参数 addr 来说,同样也要求必须 是系统页大小的整数倍,也就是与系统页大小对齐。譬如,调用 msync()时,将 addr 设置为 mmap()函数的返回值,将 length 设置为 mmap()函数的 length 参数,将对文件的整个映射区进行同步操作。
参数 flags 应指定为 MS_ASYNC 和 MS_SYNC 两个标志之一,除此之外,还可以根据需求选择是否指定 MS_INVALIDATE 标志,作为一个可选标志。
- MS_ASYNC:以异步方式进行同步操作。调用 msync()函数之后,并不会等待数据完全写入磁盘之后才返回。
- MS_SYNC:以同步方式进行同步操作。调用 msync()函数之后,需等待数据全部写入磁盘之后才返回。
- MS_INVALIDATE:是一个可选标志,请求使同一文件的其它映射无效(以便可以用刚写入的新值更新它们)。
msync()函数在调用成功情况下返回 0;失败将返回-1、并设置 errno。
munmap()函数并不影响被映射的文件,也就是说,当调用 munmap()解除映射时并不会将映射区中的内容写到磁盘文件中。如果 mmap()指定了 MAP_SHARED 标志,对于文件的更新,会在我们将数据写入到映射区之后的某个时刻将映射区中的数据更新到磁盘文件中,由内核根据虚拟存储算法自动进行。
如果 mmap()指定了 MAP_PRIVATE 标志,在解除映射后,进程对映射区的修改将会丢弃!
普通 I/O 与存储映射 I/O 比较
通过前面的介绍,相信大家对存储映射 I/O 之间有了一个新的认识,本小节我们再来对普通 I/O 方式和存储映射 I/O 做一个简单的总结。
普通 I/O 方式的缺点
普通 I/O 方式一般是通过调用 read()和 write()函数来实现对文件的读写,使用 read()和 write()读写文件时,函数经过层层的调用后,才能够最终操作到文件,中间涉及到很多的函数调用过程,数据需要在不同的缓存间倒腾,效率会比较低。同样使用标准 I/O(库函数 fread()、fwrite())也是如此,本身标准 I/O 就是对普通 I/O 的一种封装。
那既然效率较低,为啥还要使用这种方式呢?原因在于,只有当数据量比较大时,效率的影响才会比较明显,如果数据量比较小,影响并不大,使用普通的 I/O 方式还是非常方便的。
存储映射 I/O 的优点
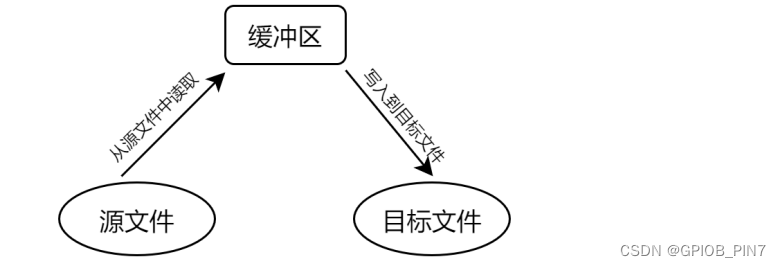
存储映射 I/O 的实质其实是共享,与 IPC 之内存共享很相似。譬如执行一个文件复制操作来说,对于普通 I/O 方式,首先需要将源文件中的数据读取出来存放在一个应用层缓冲区中,接着再将缓冲区中的数据写入到目标文件中,如下所示:
而对于存储映射 I/O 来说,由于源文件和目标文件都已映射到了应用层的内存区域中,所以直接操作映射区来实现文件复制,如下所示:
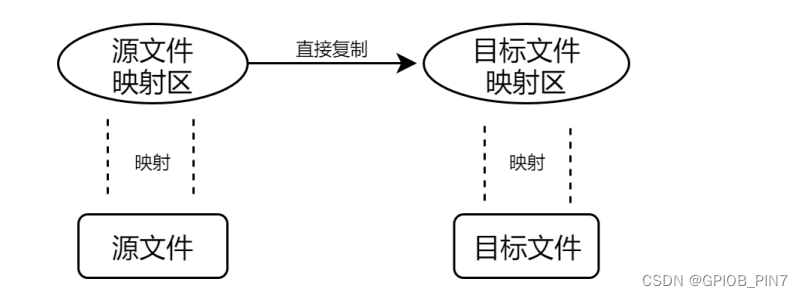
首先非常直观的一点就是,使用存储映射 I/O 减少了数据的复制操作,所以在效率上会比普通 I/O 要高,其次上面也讲了,普通 I/O 中间涉及到了很多的函数调用过程,这些都会导致普通 I/O 在效率上会比存储映射 I/O 要低。
前面提到存储映射 I/O 的实质其实是共享,如何理解共享呢?其实非常简单,我们知道,应用层与内核层是不能直接进行交互的,必须要通过操作系统提供的系统调用或库函数来与内核进行数据交互,包括操作硬件。通过存储映射 I/O 将文件直接映射到应用程序地址空间中的一块内存区域中,也就是映射区;直接将磁盘文件直接与映射区关联起来,不用调用 read()、write()系统调用,直接对映射区进行读写操作即可操作磁盘上的文件,而磁盘文件中的数据也可反应到映射区中,这就是一种共享,可以认为映射区就是应用层与内核层之间的共享内存。
存储映射 I/O 的不足
存储映射 I/O 方式并不是完美的,它所映射的文件只能是固定大小,因为文件所映射的区域已经在调用 mmap()函数时通过 length参数指定了。另外,文件映射的内存区域的大小必须是系统页大小的整数倍,譬如映射文件的大小为 96 字节,假定系统页大小为 4096 字节,那么剩余的 4000 字节全部填充为 0,虽然可以通过映射地址访问剩余的这些字节数据,但不能在映射文件中反应出来,由此可知,使用存储映射 I/O 在 进行大数据量操作时比较有效;对于少量数据,使用普通 I/O 方式更加方便! 存储映射 I/O 的应用场景由上面介绍可知,存储映射 I/O 在处理大量数据时效率高,对于少量数据处理不是很划算,所以通常来说,存储映射 I/O 会在视频图像处理方面用的比较多,例如 Framebuffer 编程,就会使用到存储映射 I/O。