介绍几篇使用diffusion来实现医学图像分割的论文:DARL(ICLR2023),MedSegDiff(MIDL2023)& MedSegDiff-V2(arXiv2023),ImgX-DiffSeg(arXiv2023)
基础概念:
-
一文弄懂 Diffusion Model (qq.com)。
-
表示学习(representation learning)初印象 - 知乎 (zhihu.com)。
-
10分钟快速入门PyTorch (10) - 知乎 (zhihu.com)。
Diffusion Adversarial Representation Learning for Self-supervised Vessel Segmentation, ICLR2023
解读:ICLR 2023:基于 diffusion adversarial representation learning 的血管分割 (qq.com)
论文:https://arxiv.org/abs/2209.14566
代码:https://github.com/boahK/DARL
目前对于血管分割任务,有两个问题:第一是数据量;第二是血管图像背景复杂。传统的监督方法需要大量的标签,无监督方法则因为血管图像一般背景复杂、低对比度、运动伪影和有许多微小的分支,分割结果达不到期望的准确率。本文引入一种名为扩散对抗表示学习(DARL)的新架构。自监督的学习的“标注”通常来自于数据本身,其常规操作是通过玩各种各样的“auxiliary task”来提高学习表征(representation)的质量,从而提高下游任务的质量。对于自监督的血管分割任务,DARL 使用 diffusion module 学习背景信号,利于生成模块有效地提供血管表达信息。此外,该模型使用基于可切换的空间自适应去规范化 (spatially adaptive denormalization, SPADE) 的对抗学习来合成假的血管图像和血管分割图,用来捕获与血管相关的语义信息。
DARL架构:
DARL 模型将 DDPM 和对抗学习应用于血管分割。即使用 diffusion module 学习背景信号,进行自监督的血管分割,这使生成模块能够有效地提供血管表达信息。此外,该模型基于可切换的 SPADE,通过对抗学习来合成假血管图像和血管分割图,进一步使该模型捕获了与血管相关的语义信息。
DARL 模型由扩散模块和生成模块组成,生成模块通过对抗学习来学习血管的语义信息。扩散模块估计添加到受干扰的输入数据中的噪声,对抗学习模型为扩散模块输出的噪声向量生成图像。扩散模型与对抗模型相连,使该模型能够实时生成图像,并对血管进行分割。
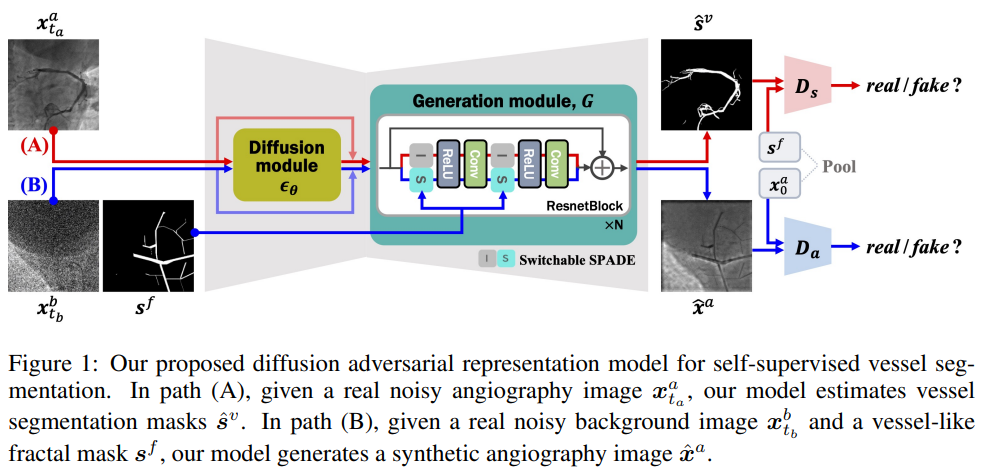
生成模块中使用了空间自适应去规范化 (SPADE) 层的可切换版本来同时估计血管分割图和基于掩膜的假血管造影。该模型输入未配对的背景图像和血管造影图像,这些图像是在注射造影剂之前和之后拍摄的。向拟议模型提供输入的途径有两种:(A)当给出真实的血管造影图像时,使用没有 SPADE 的模型估计血管分割图;(B)当给出背景图像时,带有 SPADE 的模型会生成合成血管造影,将类似血管的掩码(伪掩码)与输入背景混合在一起。(B)路径中的每个伪掩码都可以视为生成的血管造影图像的伪标签。通过将合成血管造影再次输入(A)路径,即应用分割图和伪掩码标签之间的周期一致性来捕获血管的语义信息。
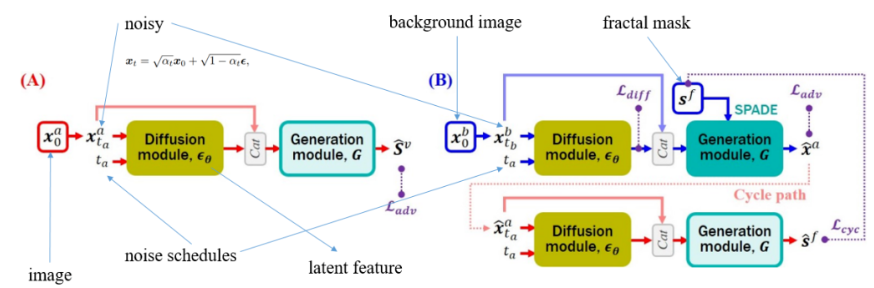
逻辑:首先输入是原图(没有标签),背景图像(来源于数据集)和随机的伪掩码(来源于数据集)三个,原图输入(A)路径,背景图像输入(B)路径,伪掩码输入生成模块的 SPADE,SPADE 会判断有没有伪掩码从而做不同的标准化动作。两条路径分别产生两种不同的输出,分别为原图的预测结果和合成的假血管造影图。上图的右侧,有两个判别器,分别为:原图的预测结果和伪掩码对抗;合成的假血管造影图和原图对抗。最后,生成的假血管造影图和伪掩码可以用来再次迭代训练该网络,整个是一个自监督的过程。
DDPM:

switchable SPADE:

训练和推理:


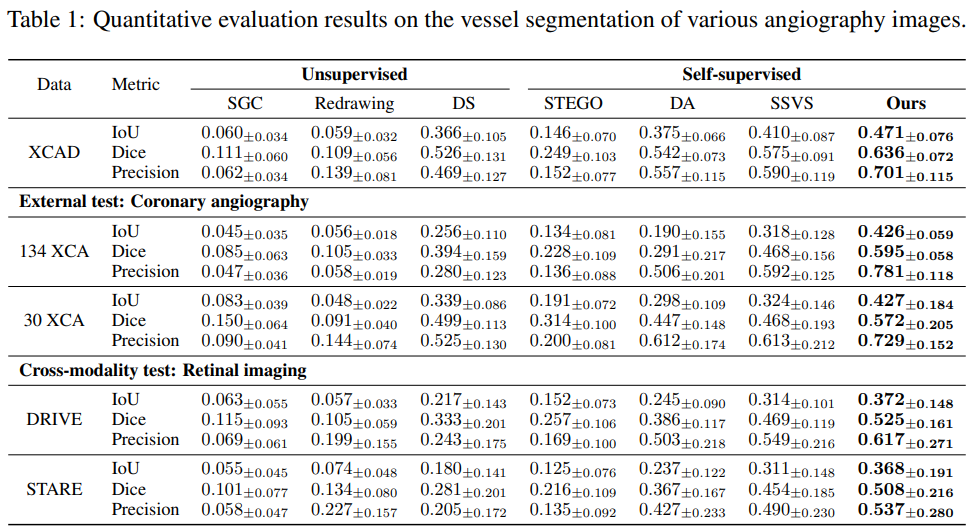
实验:
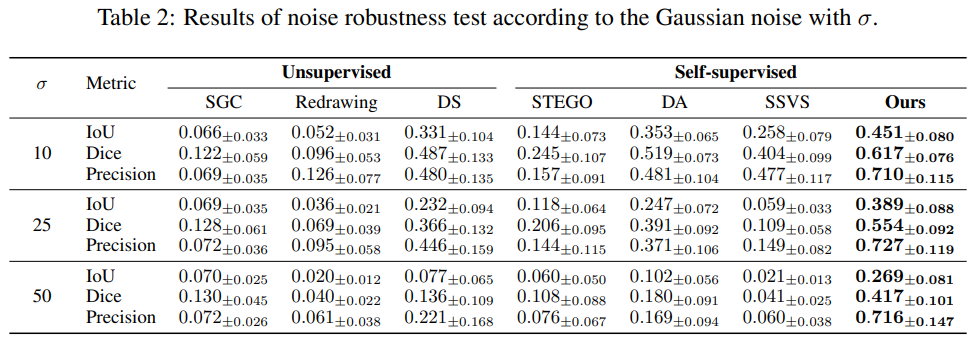
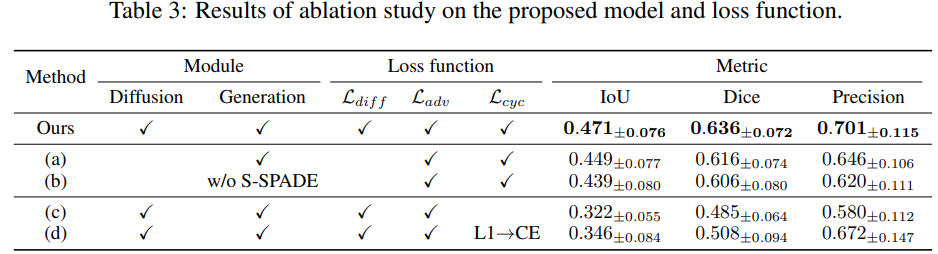 细节:
细节: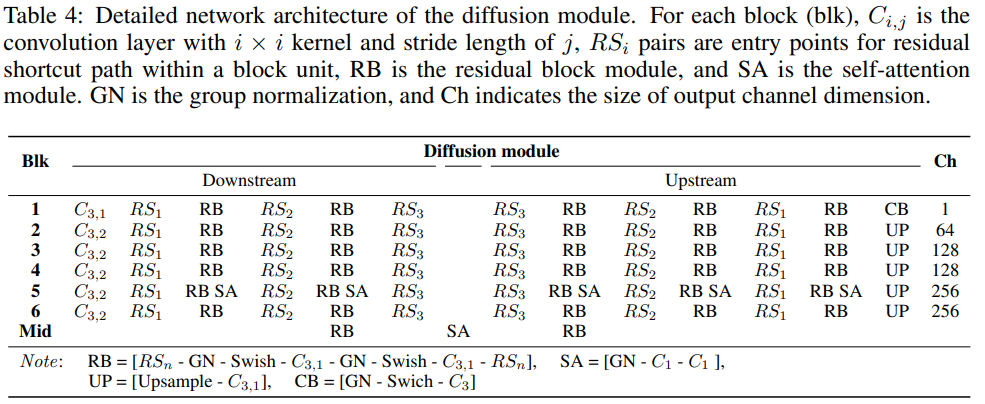
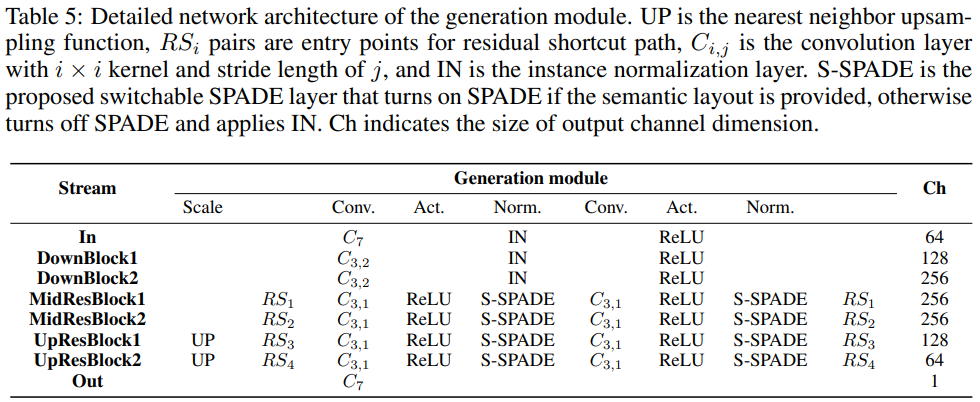
可视化结果: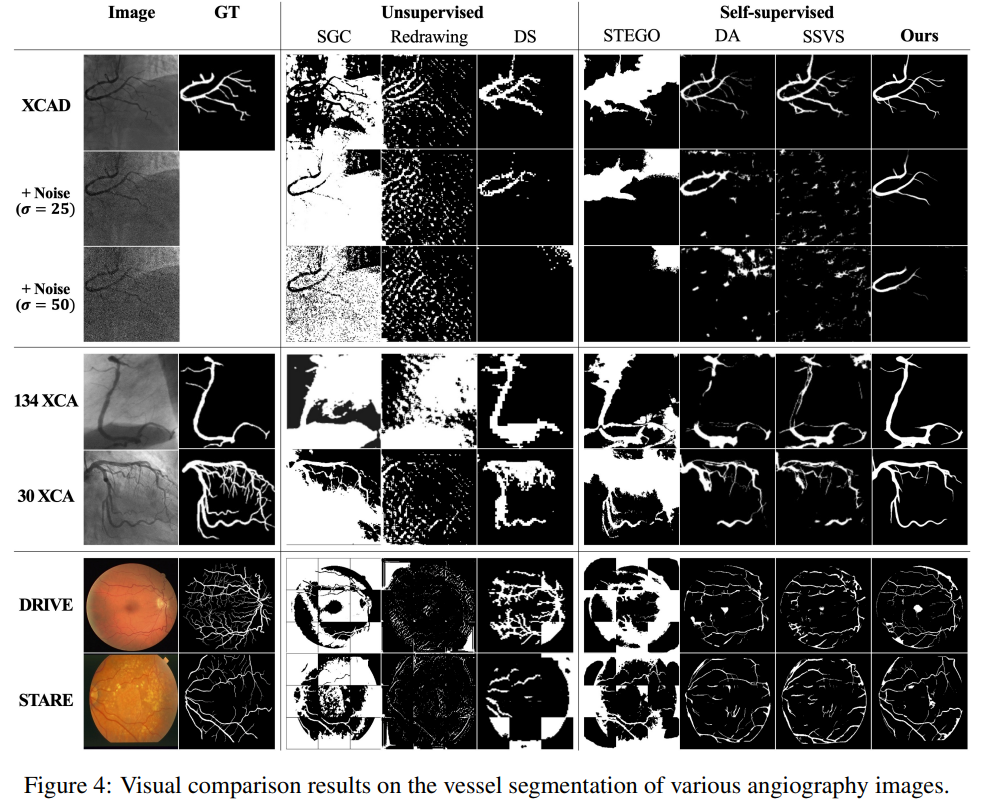
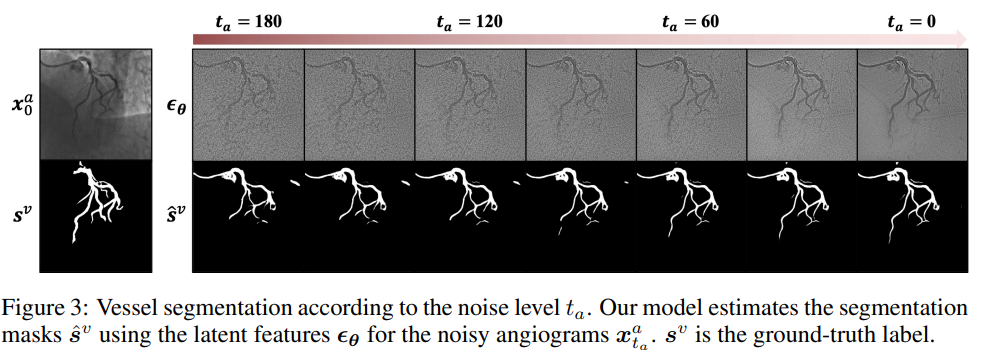
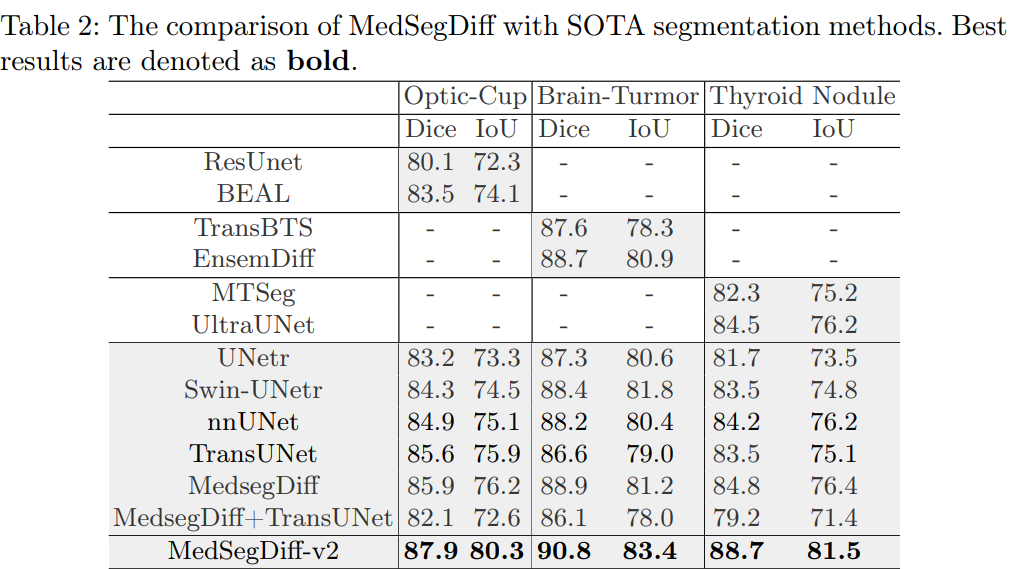
MedSegDiff & MedSegDiff-V2, 2023
MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model, MIDL2023
MedSegDiff-V2: Diffusion based Medical Image Segmentation with Transformer, arXiv2023
解读:MedSegDiff:基于 Diffusion Probabilistic Model 的医学图像分割 - GiantPandaCV
论文:https://arxiv.org/abs/2211.00611
https://arxiv.org/abs/2301.11798
代码:https://github.com/WuJunde/MedSegDiff
MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model, MIDL2023
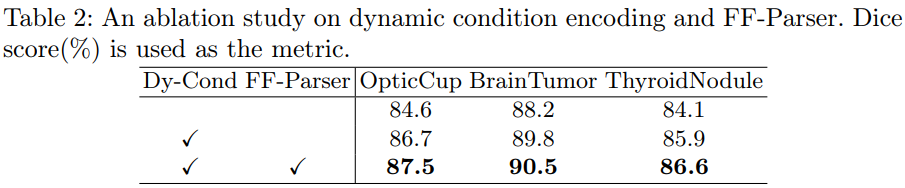
扩散概率模型(DPM)是近年来计算机视觉研究的热点之一。受DPM成功的启发,论文提出了第一个用于一般医学图像分割任务的基于DPM的模型,MedSegDiff。为了增强DPM对医学图像分割的分步区域关注,论文提出了动态条件编码,为每个采样步骤建立状态自适应条件。并进一步提出了特征频率分析器(FF Parser),以消除高频噪声分量在这一过程中的负面影响。
MedSegDiff框架:
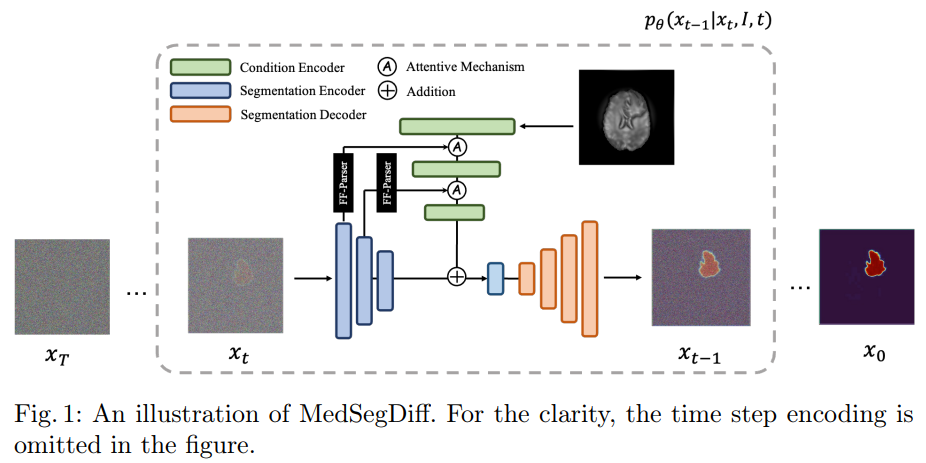
MedSegDiff 在原版 DPM 的基础上引入了动态条件编码,增强 DPM 在医学图像分割上的分步注意力能力。特征频率解析器(FF-Parser)可以消除分割过程中损坏的给定掩码中的高频噪声。
DPM 是一种生成模型,由两个阶段组成,正向扩散阶段和反向扩散阶段。在正向过程中,通过一系列步骤 T,将高斯噪声逐渐添加到分割标签 x0 中。在反向过程中,训练神经网络通过反向噪声过程来恢复原始数据:![]() , 其中 theta 是反向过程参数。从高斯噪声开始,
, 其中 theta 是反向过程参数。从高斯噪声开始, 表示原始图像,反向过程将潜在变量分布
转换为数据分布
。反向过程逐步恢复噪声图像,以获得最终的清晰分割。该模型使用 U-Net 作为学习网络,步长估计函数由原始图像先验条件确定:
![]() 其中
其中 是条件特征嵌入,即原始图像嵌入,
是当前步骤的分割映射特征嵌入。这两个组件被添加并发送到 U-Net 的解码器进行重建。步长索引 t 与新增的嵌入和解码器功能集成在一起,使用共享的 look-up table 进行嵌入。
动态条件编码 :
对于 MRI 或超声之类的低对比度图像,很难将感兴趣的对象与背景分开。使用动态条件编码方法来解决这个问题。原始图像包含准确的目标分割信息,但很难与背景区分开,而当前步骤的 grand truth 包含增强的目标区域,但不准确。
为了整合这两个信息来源,使用类似注意力的机制将条件特征图的每个尺度与当前步骤的编码特征融合。这种融合是首先对两个特征图分别应用层归一化,然后将它们相乘以获得 affine map 来实现的,再将 affine map 与条件编码特征相乘以增强注意力区域。但是,集成当前条件编码功能可能会产生额外的高频噪声。于是,使用 FF-Parser 来限制特征中的高频分量。
FF-Parser:
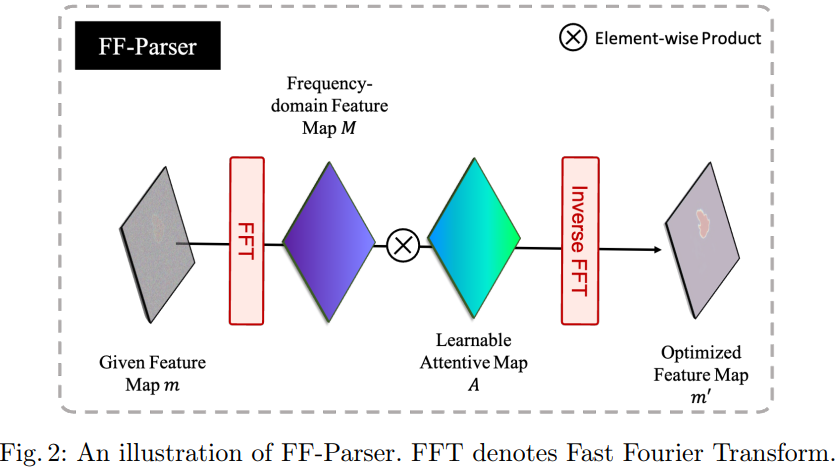 FF-Parser 是频率滤波器的可学习版本,它可以全局调整特定频率的分量,以限制高频分量进行自适应集成。首先使用二维 FFT(快速傅立叶变换)沿空间维度对解码器特征图 m 进行变换,生成频谱 M。然后,将参数化的注意力地图 A 与 M 相乘以调整频谱,得出 M'。最后,使用逆向 FFT 将 M' 反向回空间域,以获得修改后的特征图 m'。使用 FF-Parser 可以学习适用于傅里叶空间特征的权重图,该权重图可用于全局调整特定频率的分量。这种技术不同于空间注意力,后者调整特定空间位置的组成部分。
FF-Parser 是频率滤波器的可学习版本,它可以全局调整特定频率的分量,以限制高频分量进行自适应集成。首先使用二维 FFT(快速傅立叶变换)沿空间维度对解码器特征图 m 进行变换,生成频谱 M。然后,将参数化的注意力地图 A 与 M 相乘以调整频谱,得出 M'。最后,使用逆向 FFT 将 M' 反向回空间域,以获得修改后的特征图 m'。使用 FF-Parser 可以学习适用于傅里叶空间特征的权重图,该权重图可用于全局调整特定频率的分量。这种技术不同于空间注意力,后者调整特定空间位置的组成部分。
实验:
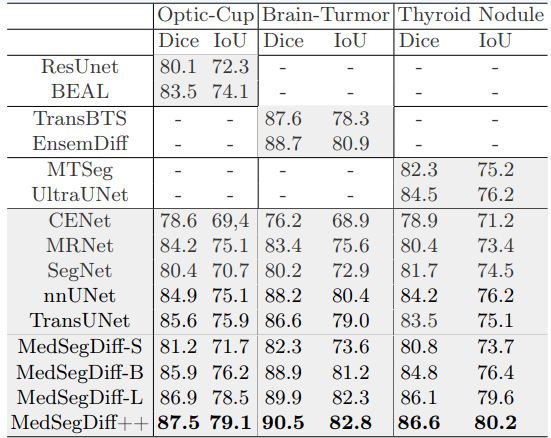
MedSegDiff-V2: Diffusion based Medical Image Segmentation with Transformer, arXiv2023
本文提出了一种新的基于变换器的条件UNet框架 MedsegDiff-v2,以及一种新型的频谱空间变换器(SS Former)来对噪声和语义特征之间的相互作用进行建模。Medsegdiff-v2 显著提高了 MedsegDiff-v1 的性能,采用了新的基于 Transformer 的条件 U-Net 框架和两种不同的条件方式,以提高扩散模型的性能。
MedSegDiff-V2架构:
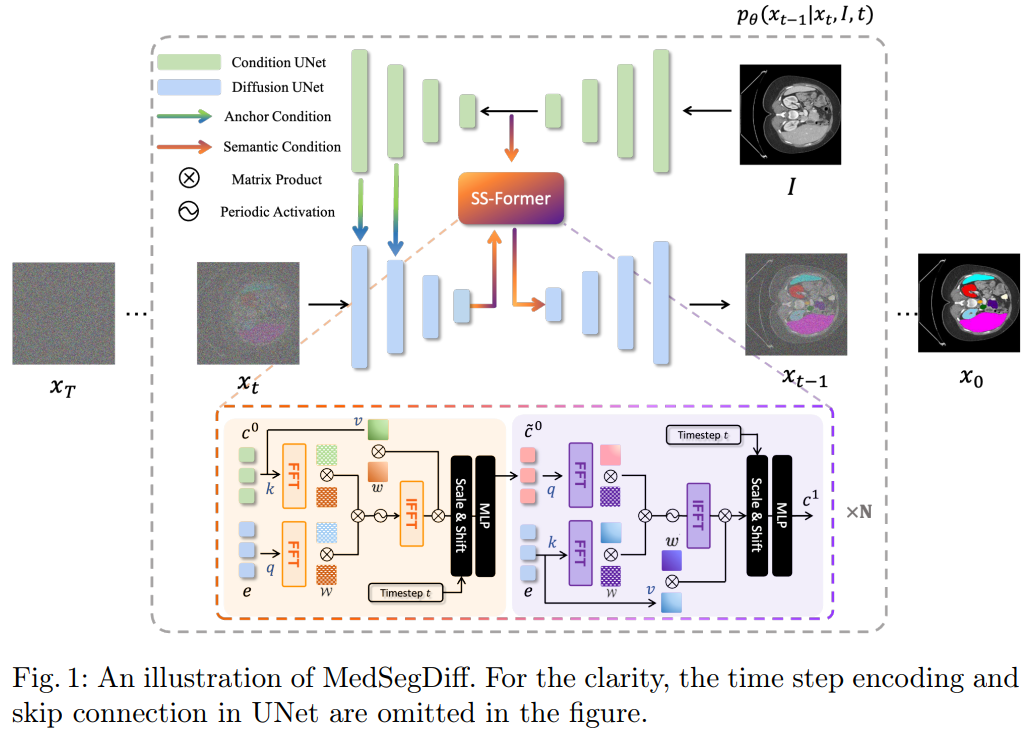
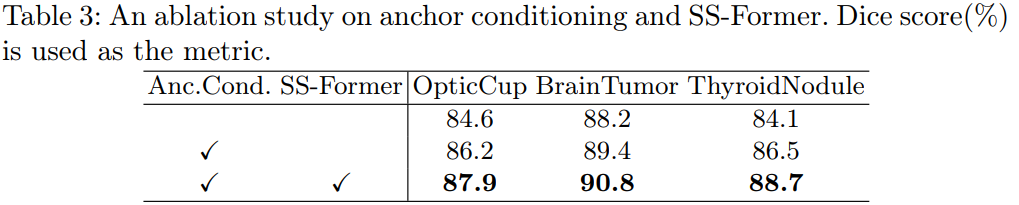
MedsegDiff-v2 结合了锚点条件和语义条件两种不同的条件方式,以提高扩散模型的性能。锚点条件将锚分割特征(条件模型的解码分割特征)集成到扩散模型的编码特征中。即允许使用粗略但静态的参照来初始化扩散模型,有助于减少扩散方差。
然后将语义条件强加于扩散模型的 embedding,理解为将条件模型的语义 embedding 集成到扩散模型的 embedding 中。这种条件集成由 SS-former 实现,它弥合了噪声和语义嵌入之间的鸿沟,并利用 Transformer 的全局和动态特性抽象出更强的特征表达形式。
Medsegiff-v2 是使用 DPM 的标准噪声预测损失 Lnoise 和锚损失 Lanchor 进行训练的。Lanchor 是 Dice loss 和 CE loss 的组合。总损失函数表示为: ![]() 其中 t ≡ 0 (mod α) 通过超参数 α 控制监督条件模型的时间,β 是另一个用于加权交叉熵损失的经验超参数。
其中 t ≡ 0 (mod α) 通过超参数 α 控制监督条件模型的时间,β 是另一个用于加权交叉熵损失的经验超参数。
Anchor Condition with Gaussian Spatial Attention:
与卷积层相比,Transformer 具有更强的表示性,但对输入方差更敏感。为了克服这种负面影响,使用锚条件运算,该运算将条件模型的解码分割特征(锚点)集成到扩散模型的编码器特征中。此外,还使用了高斯空间注意力来表示条件模型中给定分割特征的不确定性(概率)。


第一个公式中,表示在锚点特征上应用高斯核以进行平滑激活,因为锚点可能不完全准确,且高斯核的均值和方差是可以学习的。选择平滑 ground truth 和原始图之间的最大值以保留最相关的信息,从而生成平滑的锚特征。第二个公式中,将平滑锚点特征集成到扩散模型中以获得增强特征。首先应用 1x1 卷积将锚特征中的通道数减少到 1(经常作用于解码器的最后一层)。最后,在锚点特征上使用 sigmoid 激活函数,将其添加到扩散模型的每个通道中,类似于空间注意力的实现。
Semantic Condition with SS-Former:
频谱空间变换器(SS former),是一种将条件模型分割 embedding 集成到扩散模型 embedding 中的新架构,其使用频谱空间注意力机制来解决扩散和分割 embedding 之间的域差距。SS Former由几个共享相同架构的块组成。每个区块由两个类似交叉注意力的模块组成。第一个模块将扩散噪声嵌入编码为条件语义嵌入,下一个模块将噪声混合语义嵌入编码为扩散噪声嵌入。这使得模型能够学习噪声和语义特征之间的交互,并实现更强的再现。此外,注意力机制在傅里叶空间中合并语义和噪声信息,和 MedSegDiff-v1 类似。
实验:
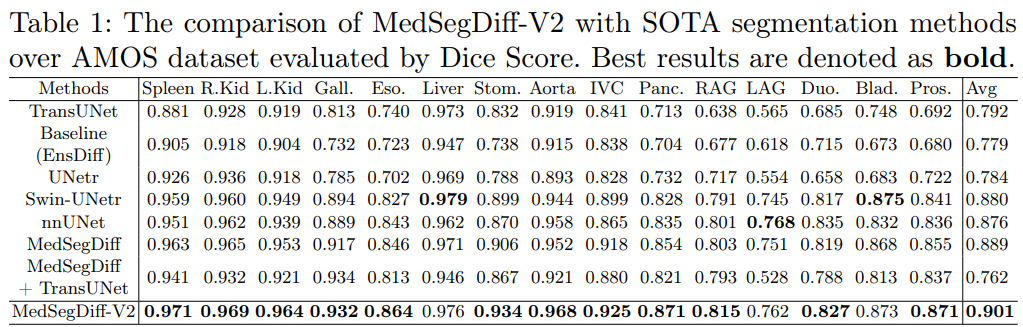
Importance of Aligning Training Strategy with Evaluation for Diffusion Models in 3D Multiclass Segmentation, arXiv2023
解读:ImgX-DiffSeg 基于 DDPMs 的 3D 医学图像分割 - GiantPandaCV
论文:https://arxiv.org/abs/2303.06040
代码:https://github.com/mathpluscode/ImgX-DiffSeg
最近,去噪扩散概率模型(DDPM)已通过生成以图像为条件的分割掩码应用于图像分割,而应用主要局限于2D网络,而没有利用3D公式的潜在优势。本文不是一种新的 diffusion 应用,而是对训练和推理策略进行优化,并适应 3D 的医学图像分割任务。
发现的问题:
- 目前带有 diffusion模型的架构训练和推理耗时。
- 一些分割任务难以确定diffusion模型预测噪声推断分割图和直接预测分割图何者更好。
- 模型过度依赖先前时间步中的信息。
优化之处:
- 该模型预测分割掩模而不是采样噪声,并直接通过Dice损失进行优化。即可以直接预测分割图。
- 回收先前时间步骤中预测的掩码,以生成噪声破坏的掩码,从而减少信息泄漏。可以减少对先前时间步信息的依赖。
- 训练期间的扩散过程减少到五个步骤,与推理相同。可以有效减少时间,提高效率。
ImgX-DiffSeg 架构:
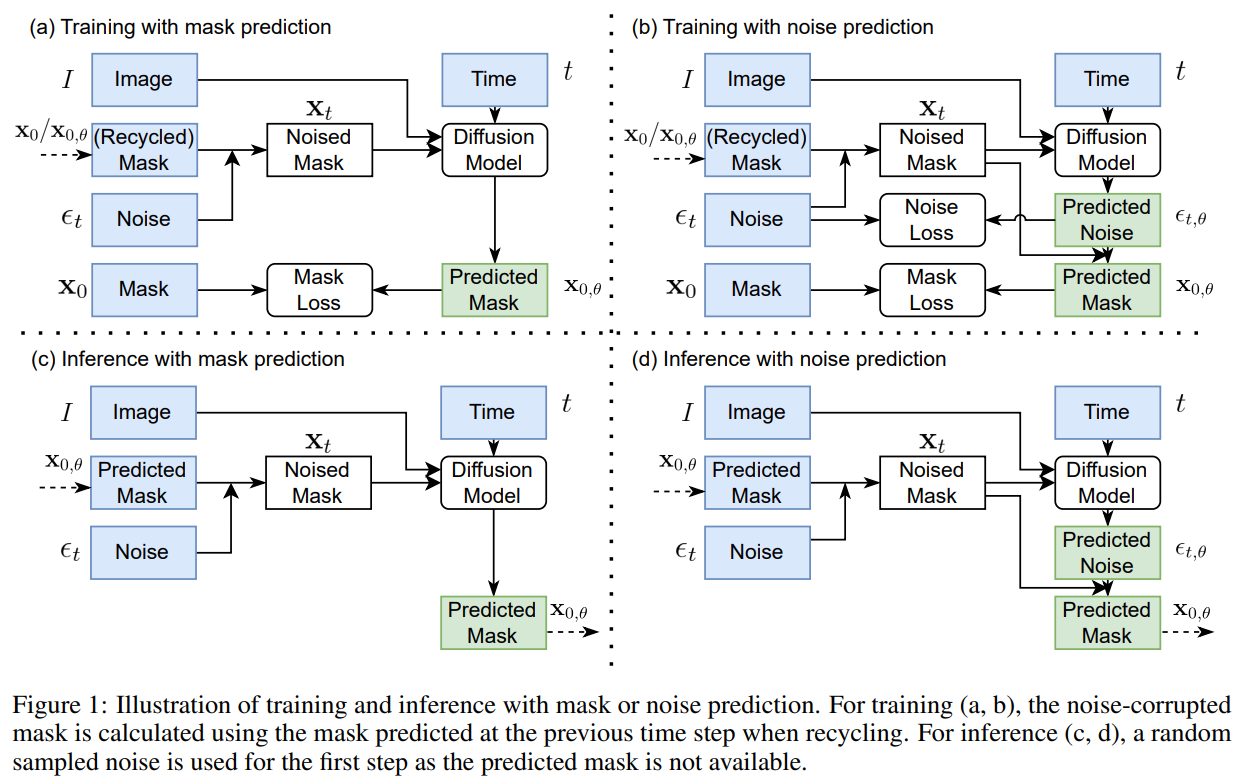
DDPM 是一种生成模型,可用于图像去噪和分割。工作原理是模拟干净图像的概率分布,然后在图像中添加噪点以生成噪声版本。相反的,模型尝试通过移除添加的噪点来对图像进行降噪。在图像分割的情况下,模型会生成分割掩码,可以根据输入图像的特征将图像分成不同的区域。
ImgX-DiffSeg。首先,该架构预测的是分割掩码而不是采样噪声,并直接通过 Dice Loss 进行优化。这意味着 ImgX-DiffSeg 可以直接预测图像的分割图,而不是生成噪点并用它来推断分割。其次,回收上一个时间步中预测的掩码,生成(noise-corrupted mask)噪音损坏的掩码。这有助于减少信息泄露,当模型过度依赖先前时间步中的信息时,就会发生这种情况。最后,将训练的扩散过程减少到五个步骤,与推理过程相同。扩散过程是一种平滑图像中噪点的方法,减少步骤数有助于提高效率。
DDPM with Variance Schedule Resampling:

Diffusion Model for Segmentation:

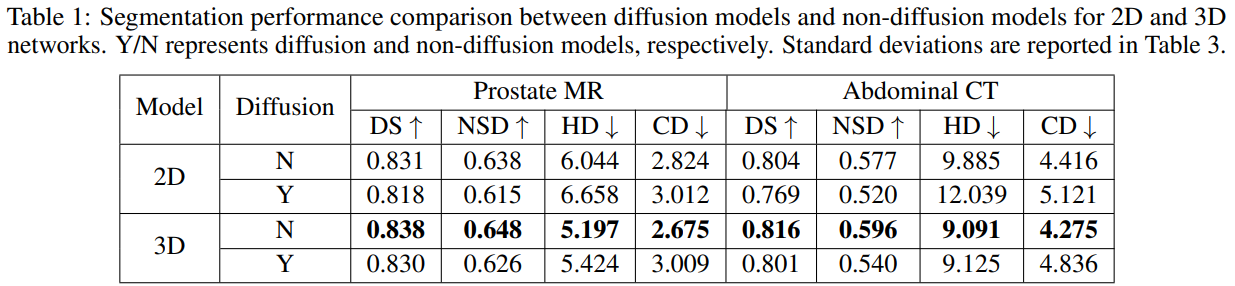
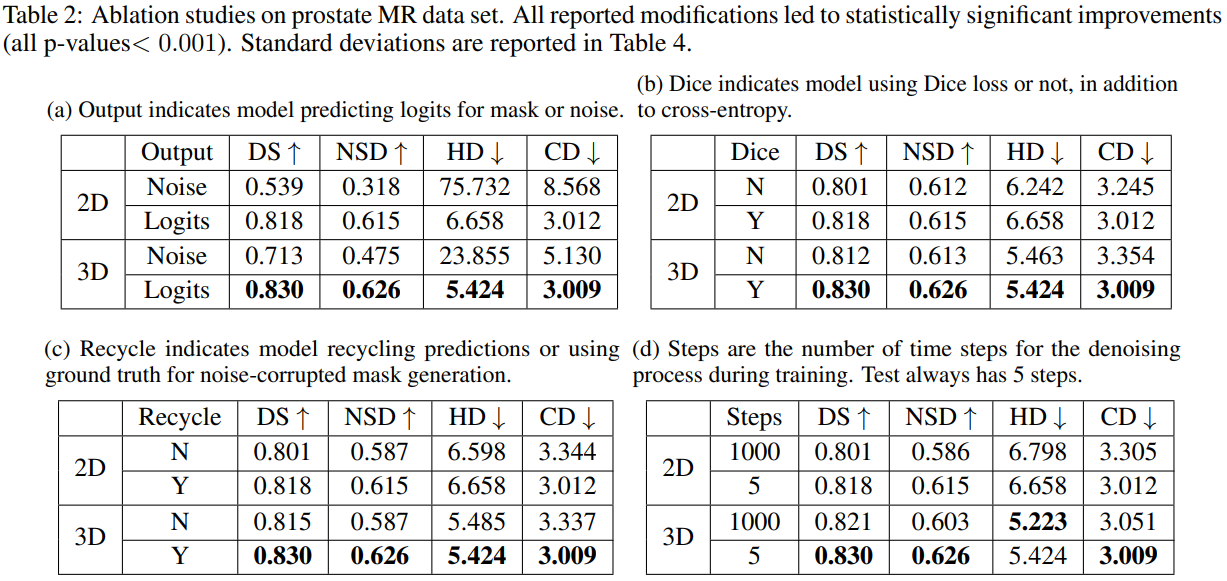
实验: