文章目录
- GQN网络介绍
- Amortized Inference
- NeRF-VAE
GQN网络介绍
论文标题:Neural scene representation and rendering
作者:S. M. Ali Eslami, Danilo Jimenez Rezende, et al.
期刊:Science
发表时间:2018/06/15
该文章提出了生成查询网络(Generative Query Network,GQN)。要解决的问题是从不同角度输入一个场景的图像,构建出内在表征,并使用这种表征预测场景中未观察到的部分。
该网络的结构非常简单,包含两个部分:表示网络(representation network)和生成网络(generation network)。表示网络将当前场景中某些view images(比如两个)作为输入,构造一个描述基础场景的表示 z(向量)。然后,生成网络以其他视角作为query,做出一个view image的预测,然后拿该query视角下的真实图像作为GT来监督。所以说,GQN本质上是有监督学习。


这个视频讲解了GQN的训练流程:https://www.youtube.com/watch?v=XHuzjGps-yA

表示网络不知道生成网络被要求预测哪些视点,所以它必须找到一种有效的方式来尽可能准确地描述场景的真实布局。表示网络因此以简洁高效的方式生成了描述基础场景的向量,也就是以高度压缩、抽象的方式描述场景,只学到了场景中最关键的元素(如对象位置、颜色和房间布局),丢失了一些细节。
然后在训练过程中,生成网络用来学习环境中的典型对象、特征、关系和规则,填充细节。生成网络部分也可以看作是一种从数据中学习的近似渲染器(approximate renderer)。
总的来说,GQN(Generative Query Network)通过学习一个场景函数的分布来对视觉场景进行建模和生成。具体来说,GQN可以将一个场景表示成从视野中几个观测角度看到的一系列图像,然后通过学习这些图像的分布来推断出一个场景函数的分布(就是上图中的scene representation)。这个场景函数的分布可以用于生成新的图像,也可以用于其他任务,比如视觉问答。因此,GQN可以看作是一种生成式模型,它可以用于对场景进行建模和生成。
Amortized Inference
VAE的网络分为两个部分,推断网络和生成网络。因为直接预测样本X的分布比较困难,所以我们想通过一个隐变量z作为桥梁,先预测z的分布,再以z为基础生成X的分布。隐变量z可以看作是包含了随机变量X的核心特征,它表示数据的“潜在结构”,描述了随机变量X的内部结构,它可以看作GQN中表征网络生成的场景表征。
推断网络的作用是根据训练数据推断出z的后验分布 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x), 其中ϕ是推断网络的参数。生成网络将潜在变量z 映射到数据空间中,生成输出数据的分布 p θ ( x ^ ∣ z ) p_\theta(\hat{x}|z) pθ(x^∣z), 其中θ是推断网络的参数。
在vanilla VAE中,对于每个输入样本,都需要使用一个独立的推断网络对其进行推断,而在amortized inference中,推断网络被用于变分自编码器中的所有样本,将推断过程转化为参数学习问题。这大大减少了计算成本,加快了训练速度,提高了推断的准确性。
直白点说,Amortized Inference(摊销推理)就是对所有样本使用一个共享编码器进行推断,这样可以减小参数量,并增强推断网络的泛化性和鲁棒性。
NeRF-VAE
Paper: 《NeRF-VAE: A Geometry Aware 3D Scene Generative Model》【DeepMind】
在这篇文章出现之前,以往的工作嵌入的几何先验不够。
与GQN一样,NeRF-VAE定义了一个在场景函数上的分布。一旦采样,场景函数允许渲染底层场景的任意视图。
但是,GQN依赖于没有三维几何知识的卷积神经网络(CNNs),导致几何不一致,而NeRF-VAE通过利用NeRF的隐式表示和体积渲染来实现一致性。
这篇文章认为,用隐变量来充当当前场景的核心信息,这点是没问题的。然后用NeRF的场景函数存储共享的信息(例如,可用的纹理和形状、公共元素的属性、天空)被存储在场景功能的参数中,但是,共享信息这种说法合理么?细节信息或许更合适。
NeRF-VAE就是结合了GQN的思想进入NeRF,以VAE的方式实现,编码器还是VAE的编码器,解码器用conditional NeRF来实现。方法的pipeline如下,使用推断网络(ResNet)生成隐变量的后验分布,然后从先验分布p(z)(与VAE一样是标准正态分布)中采样生成z,再输入至scene function中生成密度σ和颜色rgb。注意,输入encoder时,相机参数也同时输入。
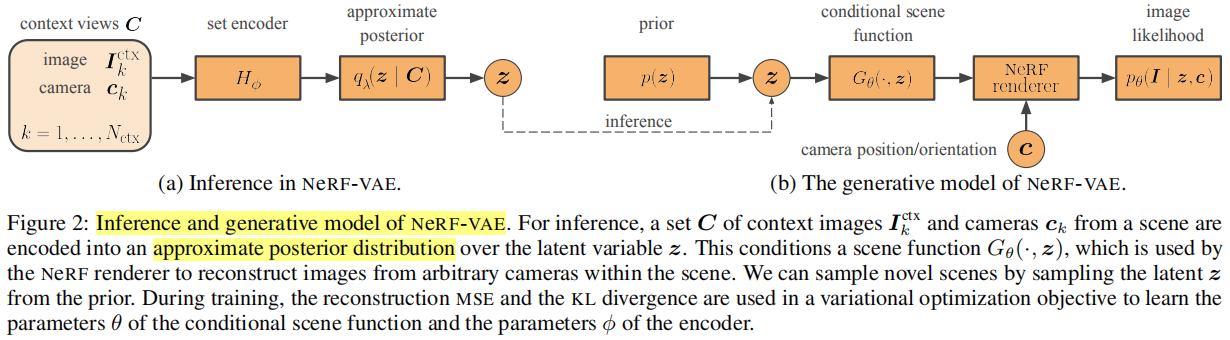
在训练时,使用了Iterative Amortized Inference,即对待不同的scene使用同一个网络训练,这其实与基于Condition的GeNeRF的做法相同,所以NeRF-VAE也能够实现泛化性。
此外,该文还提出了一种attention-based scene function。在NeRF中,生成密度和颜色在不同的层次上是有考虑的,这是为了多视角一致性,生成体积密度σ只取决于位置,而颜色则取决于位置和射线方向。所以在scene function的设计中也考虑了这一点。结构如下所示: