目录
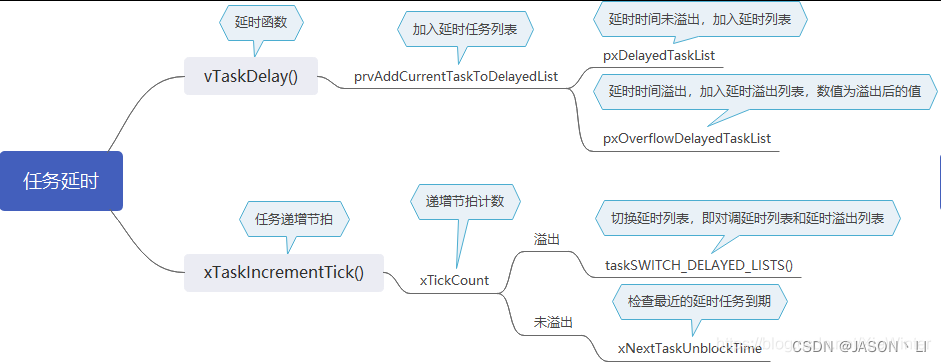
1 tensorflow运行机制
1.1 搭建计算图模型
计算图的概念
计算图的使用
新建计算图
1.2 在会话中执行计算图
会话的启动方式
1.3 指定计算图的运行设备
2 tensorflow数据模型
2.1 认识张量及属性
张量的类型
张量的阶
2.2 张量类型转换和形状变换
张量类型转换
张量形状变换
3 变量的定义与使用
3.1 定义与使用变量
变量定义
初始化变量
3.2 参数初始化变量
使用常量初始化
初始化为常量
初始化为正态分布
4 变量管理与模型数据喂入
4.1 变量管理
tf.get_variable获取变量
tf.variable_scope指定作用域
tf.name_scope命名空间管理
4.2喂入数据模型
占位符创建变量
模型喂入数据
1 tensorflow运行机制
1.1 搭建计算图模型
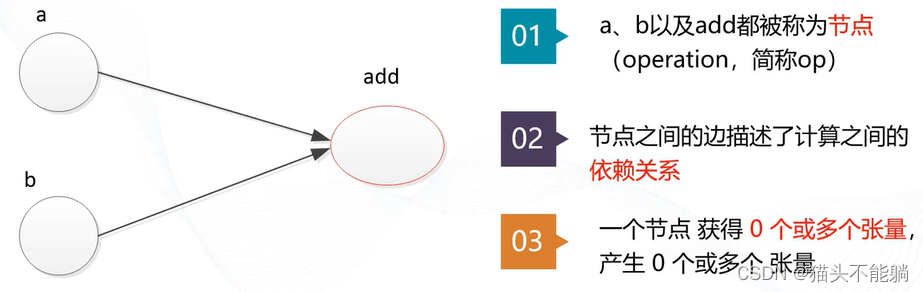
计算图的概念
tensor表示张量,其实质是某种类型的多维数组,flow表示张量在不同节点之间流动转换。
例如实现两个张量的相加:
计算图的使用
tensorflow程序通常被组织成计算图的构建阶段和执行阶段。
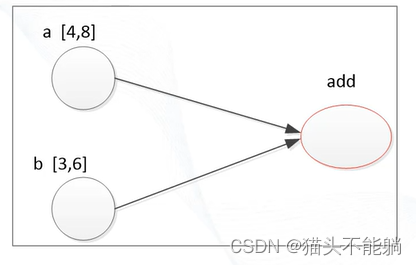
import tensorflow as tf
a = tf.constant([4,8],dtype=tf.int32)
b = tf.constant([3,6],dtype=tf.int32)
result=tf.add(a,b)
print(result)新建计算图
可以使用默认计算图
tf.get_default_graph()也可以通过tf.Graph生成新的计算图
import tensorflow as tf
# 新建计算图g1
g1 = tf.Graph()
# 新建计算图g2
g2 = tf.Graph()
with g1.as_default():
# 在g1图中新建张量v
v = tf.constant([1.0,2.0], name="v", dtype=tf.float32)
with g2.as_default():
# 在g2中新建装量v
v = tf.constant([3.0,4.0], name="v", dtype=tf.float32)
tensor1 = g1.get_operation_by_name("v")
tensor2 = g2.get_operation_by_name("v")
# 打印张量
print("g1:",tensor1)
print("g2:",tensor2)1.2 在会话中执行计算图
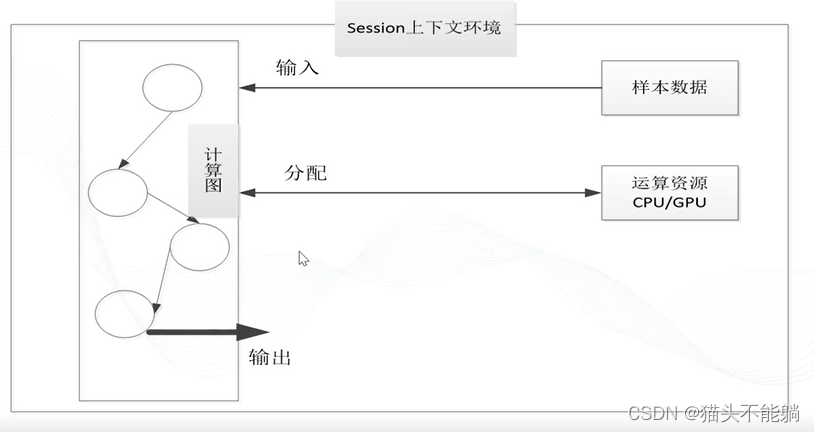
1.1中的例子并没有执行计算,是因为计算图只有在会话提供的上下文环境中才能启动。
会话的启动方式

# 导入tensorflow类库
import tensorflow as tf
# 定义张量m
m = tf.constant([[4,8,3],[12,16,5]],dtype=tf.int32)
# 定义张量b
n = tf.constant([[5,10,4],[8,14,6]],dtype=tf.int32)
# 实现两个张量的加法运算
result = m + n
print(result)
with tf.Session() as sess:
print(sess.run(result))Tensor("add:0", shape=(2, 3), dtype=int32)
[[ 9 18 7]
[20 30 11]]
计算图与会话的关系:
1.3 指定计算图的运行设备
如果没有指定的话,tensorflow会自动检测并找到cpu执行操作,如果电脑中有多块cpu的话,还可以用with...device语句用来指派指定的CPU操作:

import tensorflow as tf
import os
# 指定使用第1块GPU
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
v1 = tf.constant([1.0, 2.0, 3.0], shape=[3], name='v1')
v2 = tf.constant([1.0, 2.0, 3.0], shape=[3], name='v2')
sum = v1 + v2
with tf.Session() as sess:
print(sess.run(sum))2 tensorflow数据模型
2.1 认识张量及属性
tensor(张量)用来表示tensorflow程序中的所有数据。可以把tensor看成一个n维数组或列表。
每个张量有三个属性:
类型:数据类型
阶:张量维数的数量描述
形状:张量有几行几列
张量的类型

张量的阶

简单方法:看往一个方向的中括号数,有几个就是几阶。
2.2 张量类型转换和形状变换
张量类型转换

张量形状变换

import tensorflow as tf
c1=tf.constant([1,2,3,4,5,6,7,8,9,10,11,12],dtype=tf.float32,name="c1")
c2=tf.reshape(c1,(3,4))
c3=tf.reshape(c1,(2,-1,3))
with tf.Session() as sess:
print(sess.run(c1))
print(sess.run(c2))
print(sess.run(c3))[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12.]
[[ 1. 2. 3. 4.]
[ 5. 6. 7. 8.]
[ 9. 10. 11. 12.]]
[[[ 1. 2. 3.]
[ 4. 5. 6.]]
[[ 7. 8. 9.]
[10. 11. 12.]]]3 变量的定义与使用
3.1 定义与使用变量
变量定义
变量也是一种张量,但是变量存在于会话调用的上下文之外,主要用于保存和更新模型的参数。


初始化变量
在tensorflow中,在运行模型中其他操作之前,必须先对所有的变量进行初始化,常用的方法是调用tf.global_variables_initializer()函数进行全局初始化。
import tensorflow as tf
a=tf.Variable(tf.constant(0.0),dtype=tf.float32)
b=tf.assign(a,10)
c=b
init_op=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
print(a.eval())
print(b.eval())
print(c.eval())0.0
10.0
10.0实现一个计数器:
import tensorflow as tf
# 创建一个Op变量my_state,并初始化为0
my_state = tf.Variable(0, name ="counter")
# 创建一个Op常量赋值为1
one = tf.constant(1)
# 通过tf.add将my_state的值加1
new_value = tf.add(my_state, one)
# 通过tf.assign更新my_state的值
update = tf.compat.v1.assign(my_state, new_value)
# tf.global_variables_initializer()会返回一个操作,初始化计算图中所有Variable对象
init_Op = tf.compat.v1.global_variables_initializer()
with tf.compat.v1.Session() as sess:
# 在session中,调用sess.run(init_op)初始化所有的变量
sess.run(init_Op)
for i in range(3):
# 更新update状态值
sess.run(update)
# 输出mysate的值
print(sess.run(my_state))
1
2
33.2 参数初始化变量
使用常量初始化

import tensorflow as tf
value=[0,1,2,3,4,5,6,7]
init=tf.constant_initializer(value)
x=tf.get_variable('x',shape=[2,4],initializer=init)
with tf.Session() as sess:
sess.run(x.initializer)
print(x.eval())[[0. 1. 2. 3.]
[4. 5. 6. 7.]]
初始化为常量
当需要初始化的常量的维数很多时,一个一个指定每个值很不方便,tensorflow提供了初始化全为0和全为1的张量对象:

import tensorflow as tf
# 使用0初始化
init_zeros = tf.zeros_initializer()
# 使用1初始化
init_ones = tf.ones_initializer()
x = tf.get_variable('x', shape=[2, 3], initializer=init_zeros)
y = tf.get_variable('y', shape=[2, 8], initializer=init_ones)
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
print(x.eval())
print(y.eval())[[0. 0. 0.]
[0. 0. 0.]]
[[1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1.]]
初始化为正态分布



# 导入tensorflow类库
import tensorflow as tf
# 声明2行3列张量
w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2 = tf.Variable(tf.truncated_normal(shape=[2, 3], stddev=1, mean=0))
w3 = tf.Variable(tf.random_uniform((2, 3), minval=1.0, maxval=2.0, dtype=tf.float32))
init_op = tf.global_variables_initializer()
# 在会话中运行计算图
with tf.Session()as sess:
sess.run(init_op)
print("w1:", sess.run(w1))
print("w2:", sess.run(w2))
print("w3:", sess.run(w3))w1: [[-0.8113182 1.4845989 0.06532937]
[-2.4427042 0.09924842 0.5912243 ]]
w2: [[-0.6599848 -0.4042017 0.4803355 ]
[ 0.9102025 -0.12323765 -1.4945283 ]]
w3: [[1.1368059 1.4242172 1.3239204]
[1.3977511 1.0472989 1.9397585]]
4 变量管理与模型数据喂入
4.1 变量管理
tf.get_variable获取变量

tf.get_variable拥有变量检查机制,如果已经存在的变量如果设置为共享变量,那么tensorflow运行到第二个拥有相同名字的变量时就会报错。例如:
# 导入tensorflow类库
import tensorflow as tf
# 声明一个变量
a1 = tf.get_variable(name='a', initializer=2)
# 获取变量
a2 = tf.get_variable(name='a', initializer=2)
init_op = tf.global_variables_initializer()
with tf.Session()as sess:
sess.run(init_op)
print(sess.run(a1))
print(sess.run(a2))ValueError: Variable a already exists, disallowed. Did you mean to set reuse=True or reuse=tf.AUTO_REUSE in VarScope? Originally defined at:tf.variable_scope指定作用域
可以让不同作用域内的变量有相同的命名,包括tf.get_variable得到的变量,以及tf.Variable创建的变量。即使名称相同,由于作用域不同,不会产生冲突。
import tensorflow as tf
# 定义命名空间V1
with tf.variable_scope('V1'):
a1 = tf.get_variable(name='a1', shape=[1])
# 定义命名空间V2
with tf.variable_scope('V2'):
a2 = tf.get_variable(name='a1', shape=[1])
init_op=tf.global_variables_initializer()
with tf.compat.v1.Session() as sess:
sess.run(init_op)
print(a1)
print(a2)
<tf.Variable 'V1/a1:0' shape=(1,) dtype=float32_ref>
<tf.Variable 'V2/a1:0' shape=(1,) dtype=float32_ref>tf.variable_scope还有一个resuse=True的属性,表示使用已经定义过的变量,这时tf.get_variable都不会创建新的变量,而是直接获取已经创建的变量。
import tensorflow as tf
# 定义命名空间V1
with tf.variable_scope('V1'):
a1 = tf.get_variable(name='a1', shape=[1], initializer=tf.constant_initializer(1))
# 定义命名空间V2
with tf.compat.v1.variable_scope('V2'):
a2 = tf.get_variable(name='a1', shape=[1], initializer=tf.constant_initializer(1))
# 重新使用V2命名空间
with tf.variable_scope('V2', reuse=True):
a3 = tf.get_variable(name='a1', shape=[1])
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(a1)
print(a2)
print(a3)
<tf.Variable 'V1/a1:0' shape=(1,) dtype=float32_ref>
<tf.Variable 'V2/a1:0' shape=(1,) dtype=float32_ref>
<tf.Variable 'V2/a1:0' shape=(1,) dtype=float32_ref>tf.name_scope命名空间管理

import tensorflow as tf
with tf.name_scope('foo'):
a = tf.Variable([1.0, 2.0], name='weights')
with tf.name_scope('bar'):
b = tf.Variable([4.0, 2.0], name='weights')
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(a.name)
print(b.name)foo/weights:0
bar/weights:0
4.2喂入数据模型
占位符创建变量
占位符实质上也是一种张量, tf.placeholder创建,但是占位符并没有初始值,只会分配必要的内存,其值是在会话中由用户调用run方法传递的。

模型喂入数据
import tensorflow as tf
a = tf.placeholder(dtype=tf.int16)
b = tf.placeholder(dtype=tf.int16)
add = tf.add(a, b)
mul = tf.multiply(a, b)
with tf.Session() as sess:
print("相加: %i" % sess.run(add, feed_dict={a: 3, b: 4}))
print("相乘: %i" % sess.run(mul, feed_dict={a: 3, b: 4}))相加: 7
相乘: 12