索引覆盖
什么是索引覆盖
select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖。
如何实现索引覆盖?
最常见的方法就是:将被查询的字段,建立到联合索引(如果只有一个字段,普通索引也可以)里去。
例如建立如下表:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`surname` varchar(2) NOT NULL DEFAULT '' COMMENT '姓',
`name` varchar(10) NOT NULL DEFAULT '' COMMENT '名',
`full_name` varchar(12) GENERATED ALWAYS AS (concat(`surname`,`name`)) STORED COMMENT '全名',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`sex` varchar(2) DEFAULT NULL COMMENT '性别',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_age_sex` (`age`,`sex`)
) ENGINE=InnoDB AUTO_INCREMENT=1144780 DEFAULT CHARSET=utf8mb4
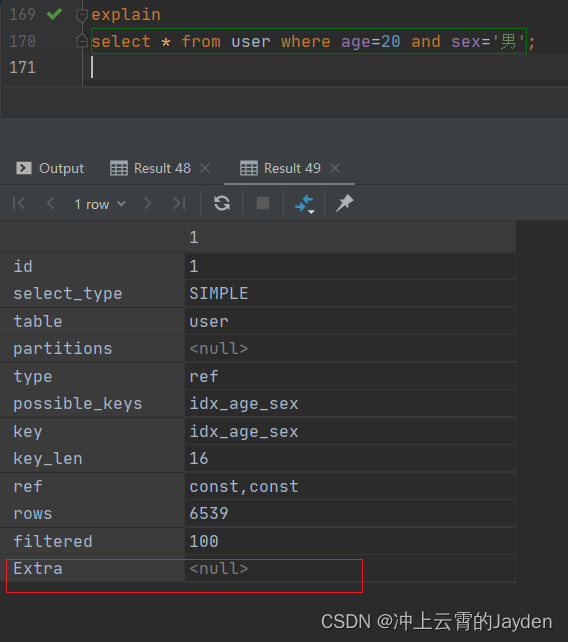
当查询所有字段时,需要使用了索引,但是还需要回表获取所有的行数据。
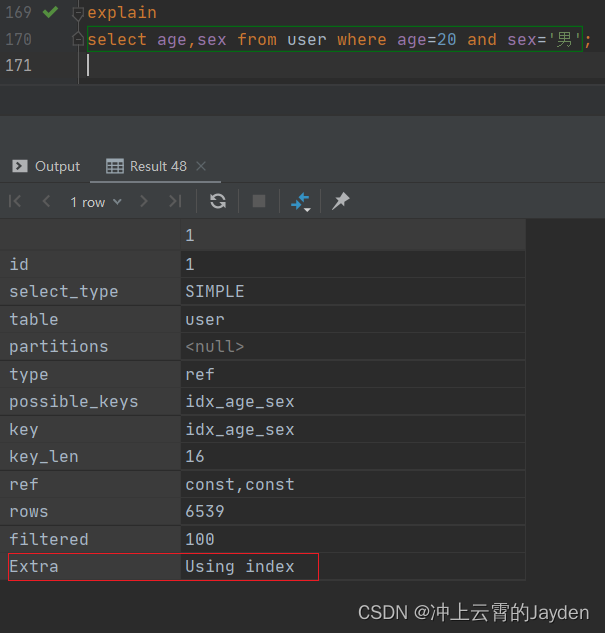
当查询只有age、sex时,explain 的Extra为Using index表示使用了索引覆盖。
索引下推
什么是所有下推?
索引下推(Index Condition Pushdown,简称ICP),是MySQL5.6版本的新特性,它能减少回表查询次数,提高查询效率。
索引下推有哪些作用?
主要作用有两个:
- 减少回表查询的次数
- 减少存储引擎和MySQL Server层的数据传输量
索引下推配置
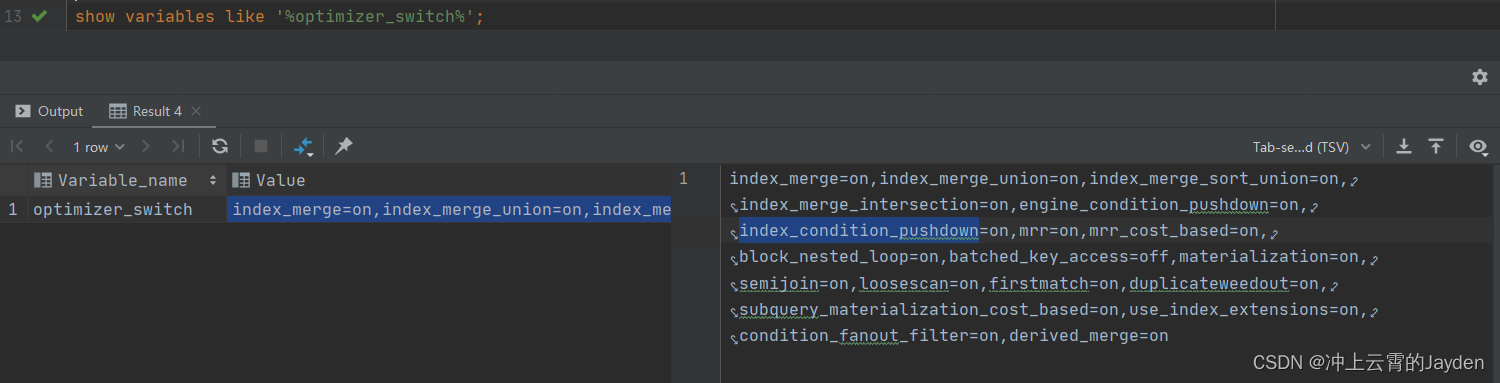
查看索引下推的配置:
show variables like '%optimizer_switch%';
如果输出结果中,显示 index_condition_pushdown=on,表示开启了索引下推。
开启索引下推
开启索引下推:
set optimizer_switch="index_condition_pushdown=on";
关闭索引下推
关闭索引下推:
set optimizer_switch="index_condition_pushdown=off";
索引下推原理
创建实战数据表:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`surname` varchar(2) NOT NULL DEFAULT '' COMMENT '姓',
`name` varchar(10) NOT NULL DEFAULT '' COMMENT '名',
`full_name` varchar(12) GENERATED ALWAYS AS (concat(`surname`,`name`)) STORED COMMENT '全名',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`sex` varchar(2) DEFAULT NULL COMMENT '性别',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_age_sex` (`age`,`sex`)
) ENGINE=InnoDB AUTO_INCREMENT=36 DEFAULT CHARSET=utf8mb4
在age、sex列上建立联合索引。
在没有使用索引下推的情况,查询过程是这样的:
- 存储引擎根据where条件中age索引字段,找到符合条件行主键ID
- 然后二次回表查询,根据主键ID去主键索引上找到整行记录
- 把数据返回给MySQL Server层,再根据where中sex条件,筛选出符合要求的一行记录
- 返回给客户端
在使用索引下推的情况,查询过程是这样的:
- 存储引擎根据where条件中age索引字段,找到符合条件的行记录,再用sex条件筛选出符合条件主键ID
- 然后二次回表查询,根据主键ID去主键索引上找到该整行记录
- 把数据返回给MySQL Server层
- 返回给客户端
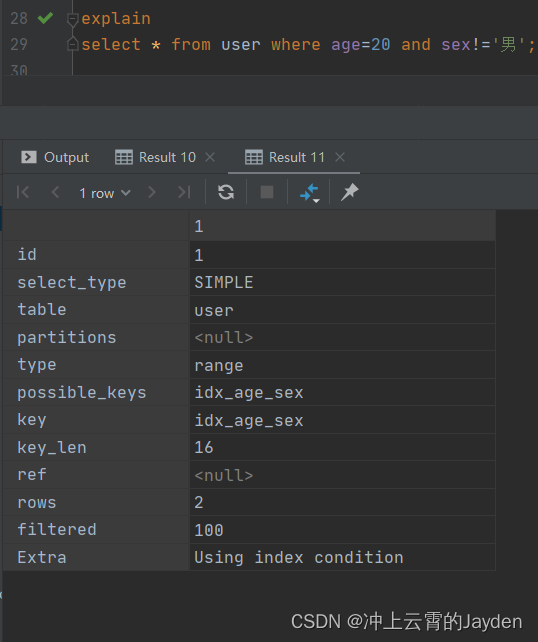
执行计划中的Extra列显示了Using index condition,表示用到了索引下推的优化逻辑。
索引下推应用范围
- 适用于InnoDB 引擎和 MyISAM 引擎的查询
- 适用于执行计划是
range,ref,eq_ref,ref_or_null的范围查询 - 对于InnoDB表,仅用于非聚簇索引。索引下推的目标是减少全行读取次数,从而减少 I/O 操作。对于 InnoDB聚集索引,完整的记录已经读入InnoDB 缓冲区。在这种情况下使用索引下推 不会减少 I/O。
- 子查询不能使用索引下推
- 存储过程不能使用索引下推
索引潜水
什么是索引潜水?
先看下实际操作。
创建表:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`surname` varchar(2) NOT NULL DEFAULT '' COMMENT '姓',
`name` varchar(10) NOT NULL DEFAULT '' COMMENT '名',
`full_name` varchar(12) GENERATED ALWAYS AS (concat(`surname`,`name`)) STORED COMMENT '全名',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`sex` varchar(2) DEFAULT NULL COMMENT '性别',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_age_sex` (`age`,`sex`)
) ENGINE=InnoDB AUTO_INCREMENT=151 DEFAULT CHARSET=utf8mb4
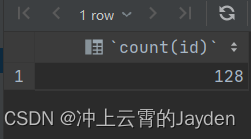
往里面写入128行数据:
select count(id) from user;
执行in操作:
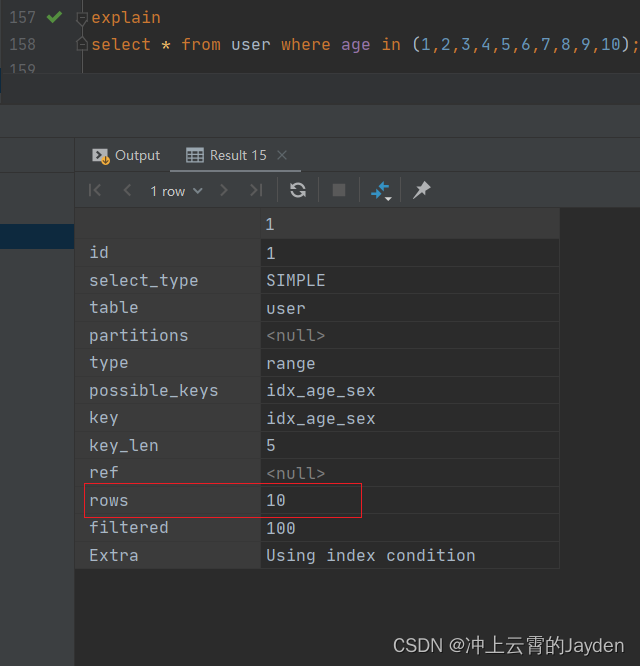
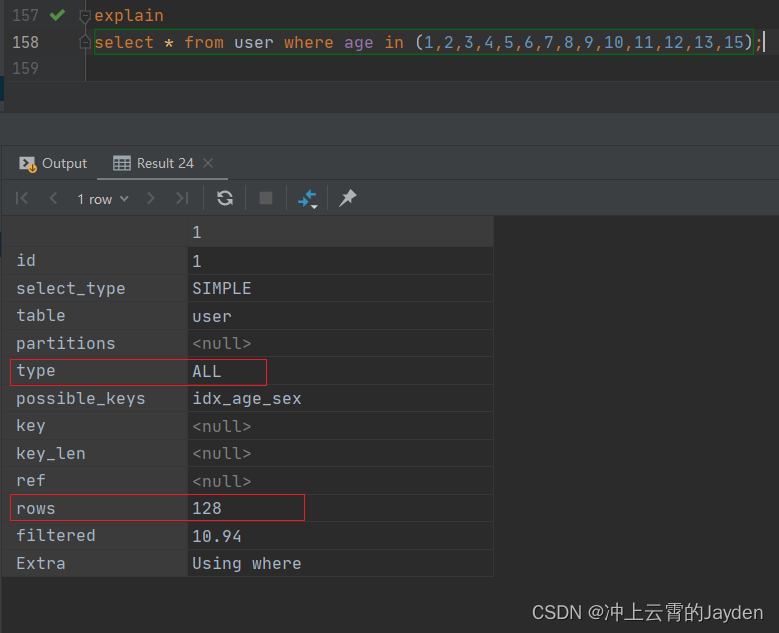
同样是in的查询,参数数量不一样时,rows和type都不一样。
in参数数量决定了走索引潜水还是索引统计的方式。
索引潜水有哪些作用?
都用索引潜水(Index dive)的方式预估扫描行数,不好吗?
其实这是基于成本的考虑,索引潜水估算成本较高,适合小数据量。索引统计估算成本较低,适合大数据量。
一般情况下,我们的where语句的in条件的参数不会太多,适合使用索引潜水预估扫描行数。
建议还在使用MySQL5.7.3之前版本的同学们,手动修改一下索引潜水的配置参数,改成合适的数值。
索引潜水配置
查询配置:
show variables like '%eq_range_index_dive_limit%';
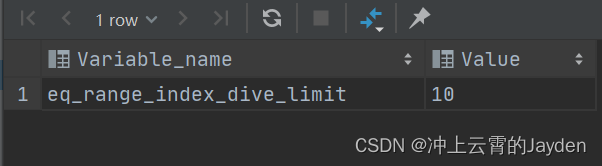
eq_range_index_dive_limit 配置的作用就是:
当where语句in条件中参数个数小于这个值的时候,MySQL就采用索引潜水(Index dive)的方式预估扫描行数,非常准确。
当where语句in条件中参数个数大于等于这个值的时候,MySQL就采用另一种方式索引统计(Index statistics)预估扫描行数,误差较大。
修改配置:
set eq_range_index_dive_limit=200;
索引合并
什么是索引合并?
当单表存在多个索引,一个SQL语句的where中又含有多个索引字段,在执行SQL语句时每个索引都可能返回一个结果集,MySQL会将其求交集或者并集,或者是交集和并集的组合。也就是说一次查询中可以使用多个索引。
我们创建一个表:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`surname` varchar(2) NOT NULL DEFAULT '' COMMENT '姓',
`name` varchar(10) NOT NULL DEFAULT '' COMMENT '名',
`full_name` varchar(12) GENERATED ALWAYS AS (concat(`surname`,`name`)) STORED COMMENT '全名',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`sex` varchar(2) DEFAULT NULL COMMENT '性别',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_age_sex` (`age`,`sex`)
) ENGINE=InnoDB AUTO_INCREMENT=151 DEFAULT CHARSET=utf8mb4
在age、sex列建立联合索引,在name建立索引。
执行查询时:
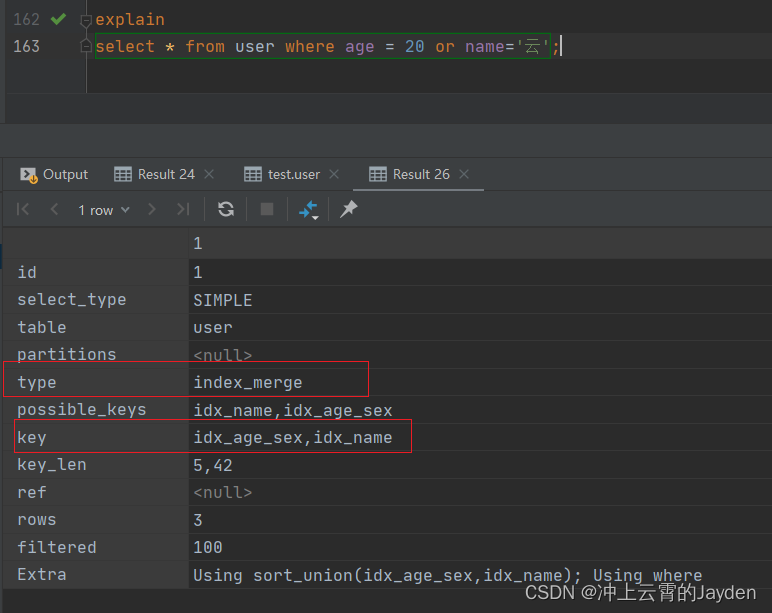
在使用explain 时,在type那一列会显示index_merge,key那一列是所有使用到的索引。
索引合并又包含三个算法,在explain中显示:
-
using intersect
index merge intersection access algorithm(索引合并交集访问算法)。
对于每一个使用到的索引进行查询,查询主键值集合,然后进行合并,求交集,也就是AND运算。 -
using union
index merge union access algorithm(索引合并并集访问算法)
容易看出,与上述的算法类似,不过是使用了or连接条件,求并集。
执行流程与index merge intersect 类似,依旧是查询了有序的主键集合,然后进行求并集。 -
using sort_union
index merge sort sort-union access algorithm (索引合并排序并集访问算法)
根据索引查询得到主键集合,对于每个主键集合进行排序,然后求并集。
索引合并有哪些作用?
索引合并能使用多个索引,提高查询的速度。