多维时序 | MATLAB实现GA-BiLSTM遗传算法优化双向长短期记忆网络的多变量时间序列预测
目录
- 多维时序 | MATLAB实现GA-BiLSTM遗传算法优化双向长短期记忆网络的多变量时间序列预测
- 效果一览
- 基本介绍
- 程序设计
- 参考资料
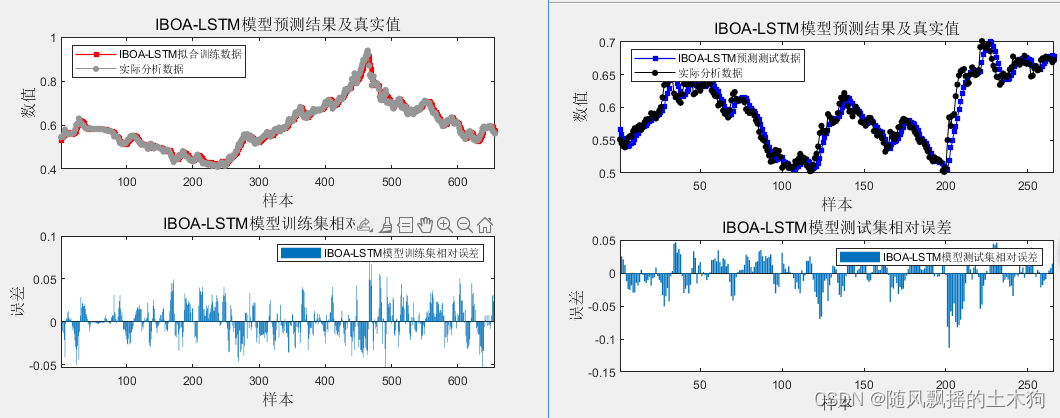
效果一览







基本介绍
MATLAB实现GA-BiLSTM遗传算法优化双向长短期记忆网络的多变量时间序列预测
1.Matlab实现GA-BiLSTM多变量时间序列预测,遗传算法优化双向长短期记忆神经网络;
遗传算法优化BiLSTM的学习率,隐藏层节点,正则化系数;
2.运行环境为Matlab2018b;
3.输入多个特征,输出单个变量,考虑历史特征的影响,多变量时间序列预测;
4.data为数据集,GA_BiLSTMNTS.m为主程序,运行即可,所有文件放在一个文件夹;
5.命令窗口输出R2、MSE、MAE、MAPE和MBE多指标评价。
程序设计
- 完整程序和数据下载方式1(订阅《智能学习》专栏,同时获取《智能学习》专栏收录程序3份,数据订阅后私信我获取):MATLAB实现GA-BiLSTM遗传算法优化双向长短期记忆网络的多变量时间序列预测
- 完整程序和数据下载方式2:私信博主。
%% 优化算法参数设置
SearchAgents_no = 5; % 种群数量
Max_iteration = 8; % 最大迭代次数
dim = 3; % 优化参数个数
lb = [1e-4, 10, 1e-4]; % 参数取值下界(学习率,隐藏层节点,正则化系数)
ub = [1e-2, 30, 1e-1]; % 参数取值上界(学习率,隐藏层节点,正则化系数)
fitness = @(x)fical(x,p_train,t_train,f_);
[Best_score,Best_pos,Convergence_curve]=GA(SearchAgents_no,Max_iteration,lb ,ub,dim,fitness)
%% 记录最佳参数
Best_pos(1, 2) = round(Best_pos(1, 2));
best_lr = Best_pos(1, 1);
best_hd = Best_pos(1, 2);
best_l2 = Best_pos(1, 3);
%% 建立模型
% ---------------------- 修改模型结构时需对应修改fical.m中的模型结构 --------------------------
layers = [
sequenceInputLayer(f_) % 输入层
bilstmLayer(best_hd) % BiLSTM层
reluLayer % Relu激活层
fullyConnectedLayer(outdim) % 输出回归层
regressionLayer];
%% 参数设置
% ---------------------- 修改模型参数时需对应修改fical.m中的模型参数 --------------------------
options = trainingOptions('adam', ... % Adam 梯度下降算法
'MaxEpochs', 500, ... % 最大训练次数 500
'InitialLearnRate', best_lr, ... % 初始学习率 best_lr
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.5, ... % 学习率下降因子 0.1
'LearnRateDropPeriod', 400, ... % 经过 400 次训练后 学习率为 best_lr * 0.5
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'ValidationPatience', Inf, ... % 关闭验证
'L2Regularization', best_l2, ... % 正则化参数
'Plots', 'training-progress', ... % 画出曲线
'Verbose', false);
%% 训练模型
net = trainNetwork(p_train, t_train, layers, options);
%% 仿真验证
t_sim1 = predict(net, p_train);
t_sim2 = predict(net, p_test );
%% 数据反归一化
T_sim1 = mapminmax('reverse', t_sim1, ps_output);
T_sim2 = mapminmax('reverse', t_sim2, ps_output);
T_sim1=double(T_sim1);
T_sim2=double(T_sim2);
%本函数完成交叉操作
% pcorss input : 交叉概率
% lenchrom input : 染色体的长度
% chrom input : 染色体群
% sizepop input : 种群规模
% ret output : 交叉后的染色体
for i=1:sizepop
% 随机选择两个染色体进行交叉
pick=rand(1,2);
while prod(pick)==0
pick=rand(1,2);
end
index=ceil(pick.*sizepop);
% 交叉概率决定是否进行交叉
pick=rand;
while pick==0
pick=rand;
end
if pick>pcross
continue;
end
% 随机选择交叉位置
pick=rand;
while pick==0
pick=rand;
end
pos=ceil(pick.*sum(lenchrom)); %随机选择进行交叉的位置,即选择第几个变量进行交叉,注意:两个染色体交叉的位置相同
pick=rand; %交叉开始
v1=chrom(index(1),pos);
v2=chrom(index(2),pos);
chrom(index(1),pos)=pick*v2+(1-pick)*v1;
chrom(index(2),pos)=pick*v1+(1-pick)*v2; %交叉结束
%检验染色体2的可行性
end
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/129215161
[2] https://blog.csdn.net/kjm13182345320/article/details/128105718