Prometheus : 入门
- Prometheus简介
- Prometheus 的主要特点
- Prometheus架构:
- 什么时候用它合适
- 什么时候用它不合适
- Prometheus VS InfluxDB
- 基本概念
- 数据模型
- metric types(指标类型)
- Prometheus 安装部署
- 二进制安装部署
- 1、将安装包prometheus-2.6.1.linux-amd64.tar放入opt目录下
- 2、在/usr/local/目录下新建prometheus
- 3、解压prometheus-2.6.1.linux-amd64.tar.gz 包
- 4、将解压prometheus-2.6.1.linux-amd64 移动到安装目录/usr/local/prometheus
- 5、进入目录/usr/local/prometheus
- 6、修改配置文件vim prometheus.yml 底部监控本机
- prometheus.yml中的配置文件含义
- 7、启动服务
- 启动选项了解:./prometheus --help
- 8、测试访问:http://localhost:9090
- 9、查看暴露指标:http://localhost:9090/metrics
- Grafana可视化大型测量数据 开源程序
- Grafana是什么?
- Grafana 与 Kibana 的区别
- grafana部署
- 1、下载安装
- 2、启动服务
- 3、访问页面http://localhost:3000 ,默认账号、密码admin/admin
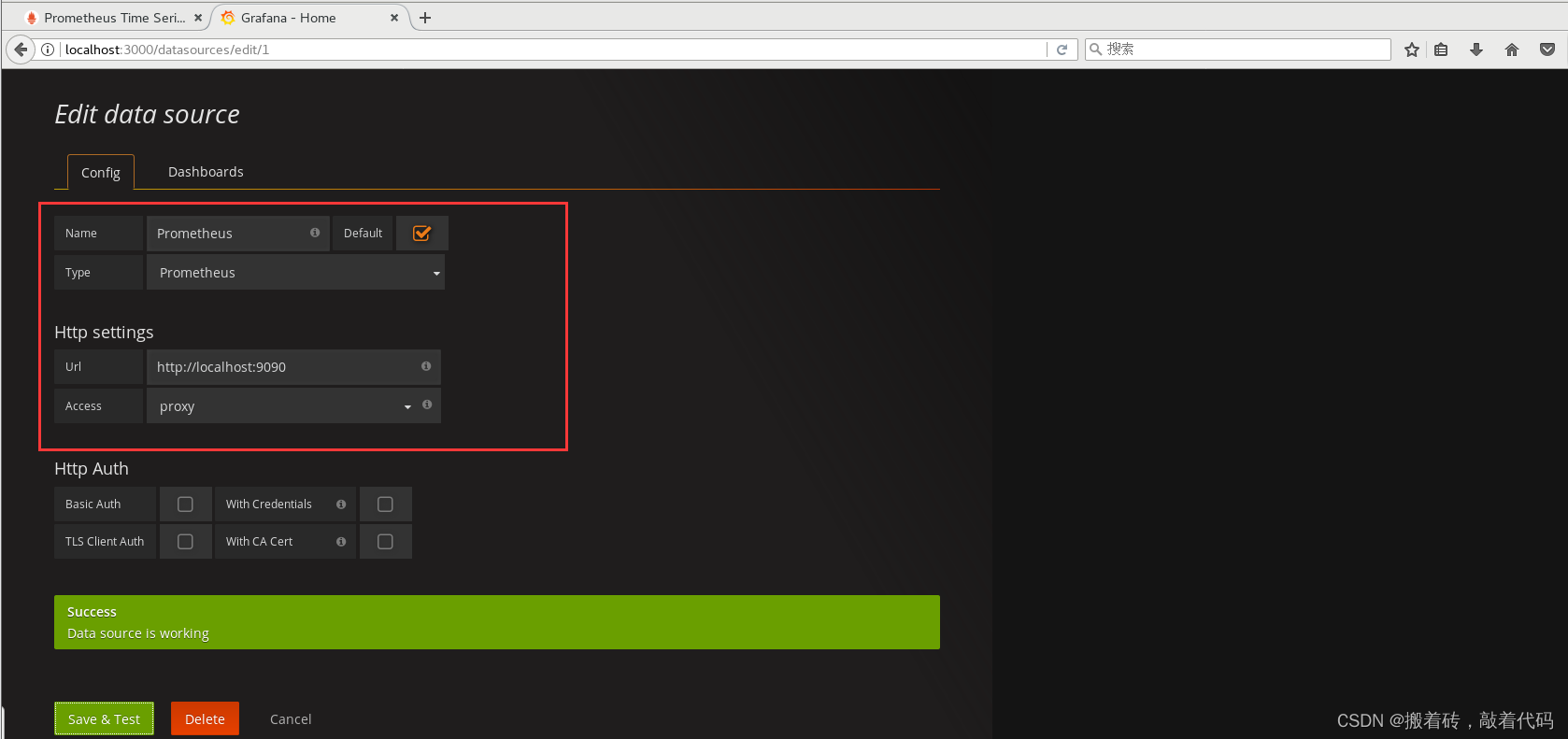
- 4、Prometheus 和 Grafana 的对接
实验所需安装包百度云盘自提
Prometheus简介
Prometheus 是一个开源的监控系统。支持灵活的查询语言(PromQL),采用 http 协议的 pull 模式拉取数据等特点使 Prometheus 即简单易懂又功能强大。
Prometheus 的主要特点
多维度数据模型
灵活的查询语言
不依赖分布式存储,单个服务器节点是自主的
通过 pull 方式采集时序数据
可以通过中间网关进行时序列数据推送
通过服务发现或者静态配置来发现目标服务对象
支持多种界面展示方案,比如 grafana 等
Prometheus 由 server, client, push gateway, exporter, alertmanager 等核心组件构成。Prometheus server 主要用于抓取和存储数据。Client libraries 可以用来连接 server 并进行查询等操作。Push gateway 用于批量,短期的监控数据的汇总节点,主要用于业务数据汇报等。不同的 exporter 用于不同场景下的数据收集,如收集主机信息的 node_exporter,收集 MongoDB 信息的 MongoDB exporter 等等。
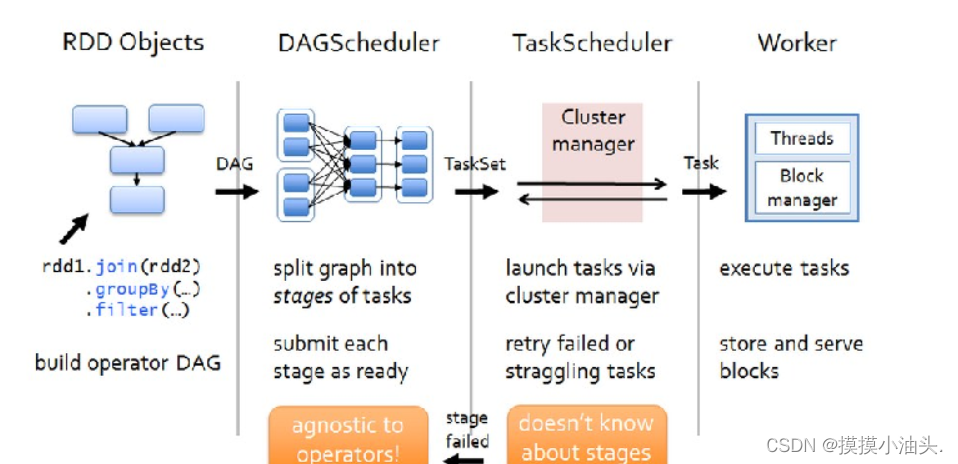
Prometheus架构:
这张图展示了架构及其生态系统的一些组成部分:

Prometheus从工具化的作业中获取指标,要么直接获取,要么通过中介推送网关获取短期作业。它在本地存储所有抓取的样本,并对这些数据应用规则将这些数据进行聚合,并记录新的时间序列,或者生成警报。可以用Grafana或其他API来可视化收集的数据。
什么时候用它合适
Prometheus可以很好地记录任何纯数字时间序列。它既适合以机器为中心的监视,也适合高度动态的面向服务的体系结构的监视。在微服务的世界中,它对多维数据收集和查询的支持是一个特别的优势。
Prometheus是为可靠性而设计的,在你的服务宕机的时候,你可以快速诊断问题。每台Prometheus服务器都是独立的,不依赖于网络存储或其他远程服务。
什么时候用它不合适
Prometheus的值的可靠性。你总是可以查看有关系统的统计信息,即使在出现故障的情况下也是如此。如果你需要100%的准确性,例如按请求计费,Prometheus不是一个好的选择,因为收集的数据可能不够详细和完整。在这种情况下,最好使用其他系统来收集和分析用于计费的数据,并使用Prometheus来完成剩下的监视工作。
Prometheus VS InfluxDB
InfluxDB是一个开源的时间序列数据库,具有扩展和集群的商业选项。InfluxDB项目是在Prometheus开发开始将近一年后发布的,所以当时无法考虑将其作为替代方案。尽管如此,Prometheus和fluxdb之间仍然存在显著的差异。二者有许多相似之处。两者都有标签(在InfluxDB中称为tags)来有效地支持多维度度量。它们基本上使用相同的数据压缩算法。两者都具有广泛的集成,包括彼此之间的集成。两者都有挂钩,允许进一步扩展它们,例如在统计工具中分析数据或执行自动化操作。
下列情况,用InfluxDB更好:
如果你正在进行事件日志记录
商业选项为InfluxDB提供集群,这对于长期数据存储也更好
最终实现副本之间数据的一致性
下列情况,用Prometheus更好:
如果你主要做的是度量
如果你需要更强大的查询语言、警报和通知功能
更高的可用性和正常运行时间,用于绘图和报警
InfluxDB由一家遵循开放核心模型的商业公司维护,提供高级特性,如闭源集群、托管和支持。
Prometheus是一个完全开源和独立的项目,由许多公司和个人维护,其中一些还提供商业服务和支持。
基本概念
数据模型
Prometheus基本上将所有数据存储为时间序列:属于同一指标和同一组标记维度的时间戳值流。除了存储时间序列外,Prometheus还可以根据查询结果生成临时派生的时间序列。
(PS:这里对时间序列的解释是这样的,time series: streams of timestamped values belonging to the same metric and the same set of labeled dimensions)
(1) Metric names and labels
Every time series is uniquely identified by its metric name and optional key-value pairs called labels.
(每个时间序列都由其指标名称和称为标签的可选键值对唯一标识)
指标名称指定要度量的系统的一般特性(例如,http_requests_total表示接收的HTTP请求的总数)。它可能包含ASCII字母和数字,以及下划线和冒号。它必须匹配正则表达式[a-zA-Z_:][a-zA-Z0-9_:]*
标签名称可以包含ASCII字母、数字和下划线。它们必须匹配正则表达式[a-zA-Z_][a-zA-Z0-9_]*。以__开头的标签名称保留内部使用。
标签值可以包含任何Unicode字符。
(2) Sample-样本
样本构成实际的时间序列数据。每个样本包括:
- a float64 value
- a millisecond-precision timestamp
(3) notation-记法
给定一个度量名称和一组标签,时间序列通常使用以下符号标识:
<metric name>{<label name>=<label value>,...}
例如,有这样一个时间序列,指标名称是api_http_requests_total,有两个标签method=“POST"和handler=”/messages",那么这个时间序列可以这样写:
api_http_requests_total{method="POST", handler="/messages"}
metric types(指标类型)
(1)Counter-计数器
计数器是一个累积指标,它表示一个单调递增的计数器,其值只能在重启时递增或重置为零。例如,可以使用计数器来表示已服务的请求数、已完成的任务数或错误数。不要使用计数器来反映一个可能会减小的值。例如,不要使用计数器表示当前正在运行的进程的数量,这种情况下,你应该用gauge。
(2)Gauge-计量器
计量器表示一个可以任意上下移动的数值。
计量器通常用于测量温度或当前内存使用量等,也用于“计数”,比如并发请求的数量。
(3)Histogram直方图、柱状图
直方图对观察结果(通常是请求持续时间或响应大小之类的东西)进行采样,并在可配置的桶中计数。它还提供了所有观测值的和。
直方图用一个基本的指标名暴露在一个抓取期间的多个时间序列:
- 观察桶的累积计数器,格式为_bucket{le=“”}
- 所有观测值的总和,格式为_sum
- 已观察到的事件的计数,格式为_count
(4)Summary-摘要
与柱状图类似,摘要样例观察结果(通常是请求持续时间和响应大小之类的内容)。虽然它还提供了观测值的总数和所有观测值的总和,但它计算了一个滑动时间窗口上的可配置分位数。
Prometheus 安装部署
二进制安装部署
1、将安装包prometheus-2.6.1.linux-amd64.tar放入opt目录下
[root@localhost ~]# cd /opt/
[root@localhost opt]# rz -E
rz waiting to receive.
[root@localhost opt]# ls
prometheus-2.6.1.linux-amd64.tar.gz rh

2、在/usr/local/目录下新建prometheus
[root@localhost opt]# mkdir /usr/local/prometheus

3、解压prometheus-2.6.1.linux-amd64.tar.gz 包
[root@localhost opt]# ls
prometheus-2.6.1.linux-amd64.tar.gz rh
[root@localhost opt]# tar xvzf prometheus-2.6.1.linux-amd64.tar.gz

4、将解压prometheus-2.6.1.linux-amd64 移动到安装目录/usr/local/prometheus
[root@localhost opt]# ls
prometheus-2.6.1.linux-amd64 prometheus-2.6.1.linux-amd64.tar.gz rh
[root@localhost opt]# mv prometheus-2.6.1.linux-amd64 /usr/local/prometheus

5、进入目录/usr/local/prometheus
[root@localhost opt]# cd /usr/local/prometheus
[root@localhost prometheus]# ls
prometheus-2.6.1.linux-amd64

6、修改配置文件vim prometheus.yml 底部监控本机
[root@localhost prometheus-2.6.1.linux-amd64]# ls
console_libraries consoles LICENSE NOTICE prometheus prometheus.yml promtool
[root@localhost prometheus-2.6.1.linux-amd64]# vim prometheus.yml
scrape_configs:
- job_name: 'prometheus'
static_configs:
# 监控本地及端口
- targets: ['localhost:9090']

注:Prometheus从目标机上通过http方式拉取采样点数据, 它也可以拉取自身服务数据并监控自身的健康状况。
注:当然Prometheus服务拉取自身服务采样数据,并没有多大的用处,但是它是一个好的DEMO。
prometheus.yml中的配置文件含义
global:
# 默认情况下,每15s拉取一次目标采样点数据。
scrape_interval: 15s
# 我们可以附加一些指定标签到采样点度量标签列表中, 用于和第三方系统进行通信, 包括:federation, remote storage, Alertmanager
external_labels:
# 下面就是拉取自身服务采样点数据配置
monitor: 'codelab-monitor'
scrape_configs:
# job名称会增加到拉取到的所有采样点上,同时还有一个instance目标服务的host:port标签也会增加到采样点上
- job_name: 'prometheus'
# 覆盖global的采样点,拉取时间间隔5s
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
7、启动服务
[root@localhost prometheus-2.6.1.linux-amd64]# ./prometheus --config.file=prometheus.yml

启动选项了解:./prometheus --help
global:
# 默认情况下,每15s拉取一次目标采样点数据。
scrape_interval: 15s
# 我们可以附加一些指定标签到采样点度量标签列表中, 用于和第三方系统进行通信, 包括:federation, remote storage, Alertmanager
external_labels:
# 下面就是拉取自身服务采样点数据配置
monitor: 'codelab-monitor'
scrape_configs:
# job名称会增加到拉取到的所有采样点上,同时还有一个instance目标服务的host:port标签也会增加到采样点上
- job_name: 'prometheus'
# 覆盖global的采样点,拉取时间间隔5s
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
8、测试访问:http://localhost:9090

9、查看暴露指标:http://localhost:9090/metrics

Grafana可视化大型测量数据 开源程序
Grafana是什么?
grafana是用于可视化大型测量数据的开源程序,他提供了强大和优雅的方式去创建、共享、浏览数据。dashboard中显示了你不同metric数据源中的数据。
Grafana 官方还对 Grafana 的适用场景以及基本特征作了介绍:
grafana最常用于因特网基础设施和应用分析,但在其他领域也有机会用到,比如:工业传感器、家庭自动化、过程控制等等。
grafana有热插拔控制面板和可扩展的数据源,目前已经支持Graphite、InfluxDB、OpenTSDB、Elasticsearch。
这里需要留意的是,上面官方列举的数据源都是时序型数据库。这也透露出 Grafana 的另一大适用性:Grafana 一般是配合时序数据库做数据展示的。
Grafana 与 Kibana 的区别
Kibana 是运维圈耳熟能详的后端数据实时展示工具。日常工作中,大家都用 Kibana 结合Logstash、ElasticSearch 等组件一起使用做日志展示、索引、分析的。但Kibana也可以接入其他数据源的,只不过最常见的用法还是展示日志。
Grafana 最早其实应该是 Kibana3 的一个分支。不同的是,Grafana 拥有自己的权限管理和用户管理系统,而 Kibana 没有权限管理系统。Kibana 和 ES 结合紧密,支持强大的ES语法,比较适合做一些多维度的分析和查询,而Grafana更适合用于展示,图形比Kibana美观很多。
grafana部署
1、下载安装
[root@localhost ~]# cd /opt/
[root@localhost opt]# wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-4.2.0-1.x86_64.rpm
[root@localhost opt]# ls
grafana-4.2.0-1.x86_64.rpm prometheus-2.6.1.linux-amd64.tar.gz rh

[root@localhost opt]# sudo yum install initscripts fontconfig -y

[root@localhost opt]# sudo rpm -Uvh grafana-4.2.0-1.x86_64.rpm
警告:grafana-4.2.0-1.x86_64.rpm: 头V4 RSA/SHA1 Signature, 密钥 ID 24098cb6: NOKEY
准备中... ################################# [100%]
正在升级/安装...
1:grafana-4.2.0-1 ################################# [100%]
### NOT starting on installation, please execute the following statements to configure grafana to start automatically using systemd
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable grafana-server.service
### You can start grafana-server by executing
sudo /bin/systemctl start grafana-server.service
POSTTRANS: Running script

2、启动服务
[root@localhost opt]# service grafana-server start
Starting grafana-server (via systemctl): [ 确定 ]

3、访问页面http://localhost:3000 ,默认账号、密码admin/admin


4、Prometheus 和 Grafana 的对接
官网操作手册文档:https://prometheus.io/docs/visualization/grafana/
点击“添加数据源”