文章目录
- 一、阻塞式队列
- 二、生产者消费者模型
- 1.发送方和接受方之间的 “解耦合”
- 2. “削峰填谷”保证系统稳定性
- 3、代码实现阻塞式队列
一、阻塞式队列
阻塞式队列,顾名思义也是一个队列,这个队列遵循的是先进先出的原则。
这里简单提一个特殊的队列,这个队列是 PriorityQueue 优先级队列,这个队列不遵守先进先出的原则
阻塞队列,也是一个比较特殊的队列,虽然是先进先出的,但是带有特殊的功能,如下:
- 如果队列为空,执行出队列操作,就会阻塞。阻塞到另一个线程往队列里添加元素 (队列不空) 为止。
- 如果队列满了,执行入队操作,也会阻塞。阻塞到另一个线程从队列取走元素为止 (队列不满)。
根据上面阻塞式队列的这些特性,从而衍生出了一个非常典型的应用场景“生产者消费者模型”。这是一种非常典型的开发模型。
二、生产者消费者模型
在这里,我们先举出一个简单的例子,就是每次过年时一家人坐在一起包饺子。
在日常包饺子我们会有下面两个经典的包法:
- 每个人都进行擀饺子皮,包饺子这两个操作。(此时,大家会竞争擀面杖,就会产生阻塞等待,影响效率)
- 由一个人专门负责擀饺子皮,另外几人负责包饺子。(这样就不存在竞争的问题,包的效率就和擀的效率有很大关系)
不难发现,第 2 种情况更加符合实际,这种形式就是生产者消费者模型。负责擀饺子皮的就是生产者,负责包饺子的就是消费者。
在这里,擀饺子皮的速度慢了,包的就得等,擀饺子皮的太快了,擀饺子皮的就等。
对于生产者消费者模型,可以带给我们非常重要的两个好处!!
1.发送方和接受方之间的 “解耦合”
所谓 “解耦合” ,就是降低程序和程序之间的关联性。
典型场景:服务器之间的相互调用。
如图:
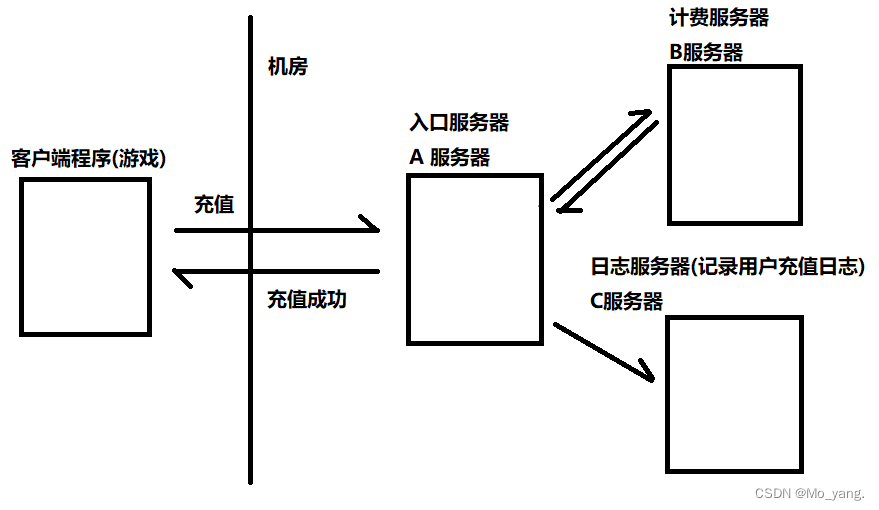
- 首先用户发出充值操作,由 A 服务器接受
- 之后 A 服务器将请求传递给 B 服务器处理,之后将处理结果返回给 A 服务器,此时,可以视为 A 调用了 B
在上面的场景中,A 和 B 之间的耦合度是比较高的,A 要调用 B,A 就必须要知道 B 的存在,如果此时 B 出现问题,就很容易引起 A 的 bug!
此外,如果在 A 服务器和 B 服务器之间根据需要在加入 C 服务器。这就需要对 A 服务器进行修改更新,重新测试,重新发布,重新部署。 这样就麻烦很多了。。
针对上面的场景,使用生产者消费者模型,就可以很好的降低 耦合度。
如图:
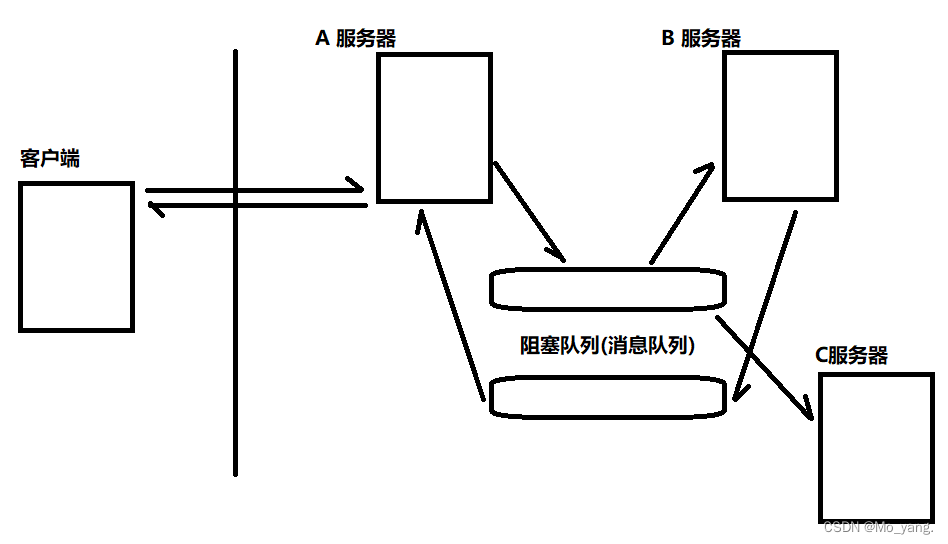
此时,A 服务器和 B 服务器之间的耦合度就降低很多了。
- 用户发出操作传递到服务器 A,当 A服务器接收后就存放到阻塞队列中,不与 B 服务器直接接触。
- B 服务器处理完相应操作后,也不直接反馈到 A 服务器,同样的存入到对应的阻塞队列中。
在修改后服务器与服务器之间的联系形式发生很大的改变。
- A 不知道 B 的存在。A 只知道阻塞队列。(A 的代码中没有任何代码与 B 相关)
- B 也不知道 A 的存在。B 也只知道阻塞队列。(B 的代码中也没有任何与 A 相关的代码)
- 如果 B 出现故障,对 A 没有任何影响。因为阻塞队列任然存在,A 任然可以给队列中插入元素,如果队列满,就先进行阻塞。
- 如果 A 出现故障,对于 B 也没有任何影响。同样因为阻塞队列存在,B 仍然也可以从队列中获取元素。若队列空,也就先进行阻塞。
总的来说,A 和 B 任何一方出现问题都不会对对方产生影响。
此时在要新增一个 C 作为消费者也是没有问题的。
2. “削峰填谷”保证系统稳定性
在日常生活中,我们一定知道水坝这个东西。
我们在上面介绍的阻塞队列就和水坝的作用十分相似。
对水坝而言:
- 上游水量增加——关闸蓄水。
- 上游水量减少——开闸放水。
对应到阻塞队列中:
- 上游——用户端发送的请求
- 下游——对应执行具体操作的服务器
所以上游用户的请求申请量的大小会随时冲击下游的各个服务器,阻塞队列在此就是起到水坝缓冲的作用。
3、代码实现阻塞式队列
我们知道,阻塞是队列仍然是队列的一种,所以,要自己实现一个阻塞队列就需要先设计出一个普通的队列。
队列基于两类,一种是基于数组,一种是基于链表,链表的实际是相对比较简单的,在这里,我来以循环数组的形式来给大家实现这个队列。
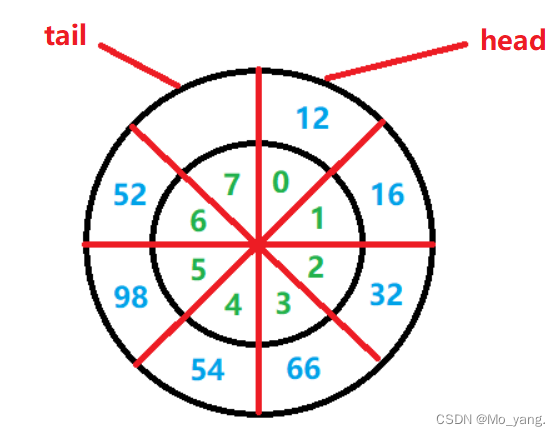
循环数组大致分为两类:
- 留出一个空间用于判断数组是否已满,如图
- 不浪费这个空间,引入一个 size 元素来进行记录个数。
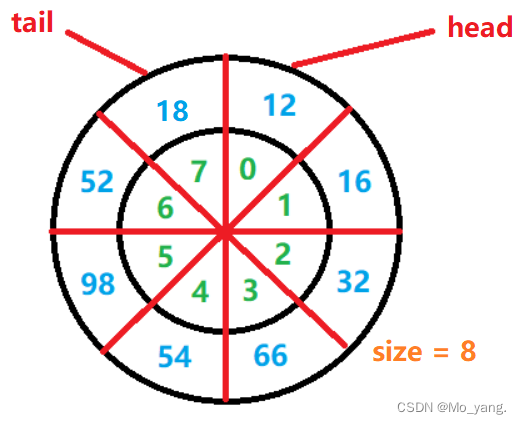
在这里我依照第二种情况的循环数组来实现队列。
到此,设计一个什么样的队列已经确定了,下面我们就需要确定阻塞队列都含有哪些方法。
对于阻塞队列主要方法有两个:1. 入队列 (put) 2. 出队列 (take) 这两个方法都是是带有阻塞功能的,知道上面的这些条件后,接下来就是通过代码来实现相关的操作了。
普通队列的实现
- 实现方法前准备
//不考虑泛型,直接使用 int 元素表示类型
class MyBlockingQueue {
//设定数组长度
private int[] item = new int[1000];
//设定头指针
private int head = 0;
//设定尾指针
private int tail = 0;
//记录数组长度
private int size = 0;
}
- 实现 put 存放方法
//实现 put 存入方法
public void put(int value){
//判断数组是否已经存满
if (size == item.length){
//队列满了,无法插入
return;
}
item[tail] = value;
tail++;
//针对 tail 的情况
//这里 tail 在上面已经 +1 所以式子中无需加 1.
//(1) tail = tail % item.length;
//(2)
if(tail >= item.length){
tail = 0;
}
size++;
}
在上面代码中针对 tail 的情况,本人更推荐第二种,因为第二种更加易于理解,直接将 tail 从队列末尾跳转到数组队列头部,不易出错。
- 实现 take 获取方法
//实现 take 拿取方法
public Integer take(){
//记录获取的数据
int result = 0;
//判断不能出队列的情况
if(size == 0){
//空队列
return null;
}
result = item[head];
head++;
//判断当 head 超出数组的情况
if(head >= item.length){
head = 0;
}
size--;
return result;
}
到此,一个普通的循环队列实现完毕,现在只要在这个基础上添加阻塞条件,就形成了一个阻塞队列。
我们知道,阻塞功能就意味着要在多线程下使用,存在多线程就必然会有线程安全问题,所以就需要使用 synchronized 对可能被修改的变量进行加锁。
//实现 put 存入方法
public void put(int value) throws InterruptedException {
//为了防止在多线程中产生不必要的修改,对元素进行加锁
synchronized (this){
//判断数组是否已经存满
//使用 while 循环 反复判断是否满足条件
while(size == item.length){
//队列满了,无法插入
//需要判断进行阻塞等到
//return;
this.wait();
}
item[tail] = value;
tail++;
//针对 tail 的情况
//(1) tail = tail % item.length;
//(2)
if(tail >= item.length){
tail = 0;
}
size++;
//这里的 notify 是用来唤醒 take 中的 wait
this.notify();
}
}
//实现 take 拿取方法
public Integer take() throws InterruptedException {
int result = 0;
synchronized (this){
//判断不能出队列的情况
while(size == 0){
//空队列
//当空队列时也需要等待
//return null;
this.wait();
}
result = item[head];
head++;
//判断当 head 超出数组的情况
if(head >= item.length){
head = 0;
}
size--;
//当出队列后进行 唤醒
this.notify();
}
return result;
}
}
加锁操作保证了代码中的各个变量不会出现被篡改的情况,关于 wait 和 notify 关键字就是实现阻塞等待操作。
这里再详细说明一下,wait 和 notify 是如何相互进行制约的,如图所示:

除此之外,代码中还有一点有变化,如图所示:
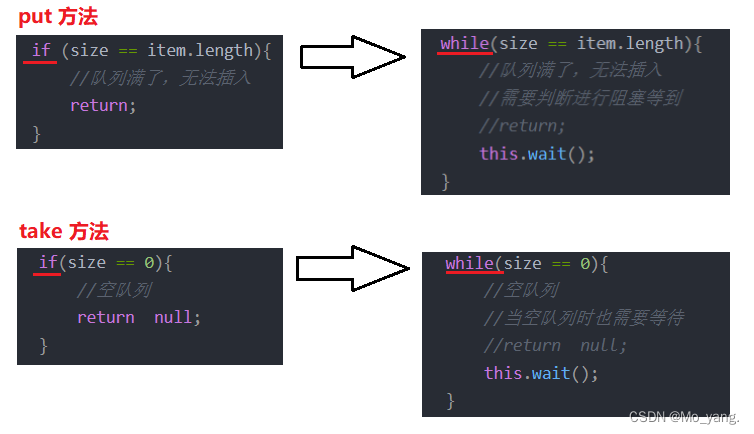
这里要提出一个问题,当 wait 被唤醒的时候,if 语句中的条件就一定不成立了吗? 以 put 为例,具体来讲,就是当 wait 被唤醒的时候 队列一定是不满的吗?
虽然说这样的可能性比较小,但是不能排除会有这样的可能,所以解决办法就是让其循环多次判断,观察是否满足条件!
这样,我们就自主实现了一个阻塞队列,下面通过代码进行验证一下。
public class ThreadDemo {
public static void main(String[] args) throws InterruptedException {
MyBlockingQueue queue = new MyBlockingQueue();
Thread t1 = new Thread(()->{
//消费者线程
while(true){
int result = 0;
try {
Thread.sleep(500);
result = queue.take();
System.out.println("消费:"+ result);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
Thread t2 = new Thread(()->{
//生产者线程
int count = 0;
while(true){
try {
System.out.println("生产:"+ count);
count++;
queue.put(count);
//Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t2.start();
}
}
在这里设定了两个线程分别为 生产者 和 消费者,我们在其中设定 sleep 可以很清楚地观察到阻塞队列的运行情况,如图:
设定生产者生产较慢
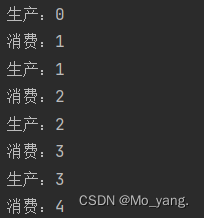
我们会发现,生产和消费几乎是同步进行的,但是结果有个问题,元素还没有生产出来,为什么就出现消费了?
其实这也不难解释,因为我们没有在打印操作上设定优先顺序,所以,其实元素已经生产出来,但是由于抢占式执行,所以会有些不对应。
设定消费者消费较慢
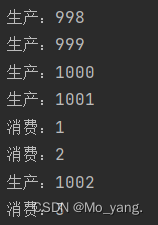
我们会发现,在一瞬间就产生了很多元素,最后消费者才缓慢消费,最终达到一个平衡。