文章目录
- 1、人脸认证和人脸识别
- 2、One shot学习
- 3、siamese network
- 4、Triplet loss function
- 5、人脸识别和二分类问题
- THE END
1、人脸认证和人脸识别
\qquad
人脸认证表示输入一幅图片和一个name/ID,输出这个图片和ID是否是同一个人。
\qquad
人脸识别表示数据库中有K个人,输入一幅图片,输出这幅图片是否是数据库中的某一个人。
\qquad
人脸识别属于一对一(1:1)的任务,而人脸识别属于(1:K)的任务,对于误差率很小的人脸认证分类器,用在人脸识别上可能效果会很差。
2、One shot学习
\qquad
人脸识别任务中,有一个比较难解决的问题,就是数据库中的每个人只有一张图片,从而无法直接对数据库中的图片进行训练从而进行不同人脸的识别任务,这样训练出来的分类器也将会十分低效。同时若数据库中新加入了图片,则需要重新对分类器进行训练,从而使得这种思路显得不可行。
\qquad
为了解决上述问题,不是去针对每一幅图片训练,而是训练一个计算不同图片之间相似度的函数:
d
(
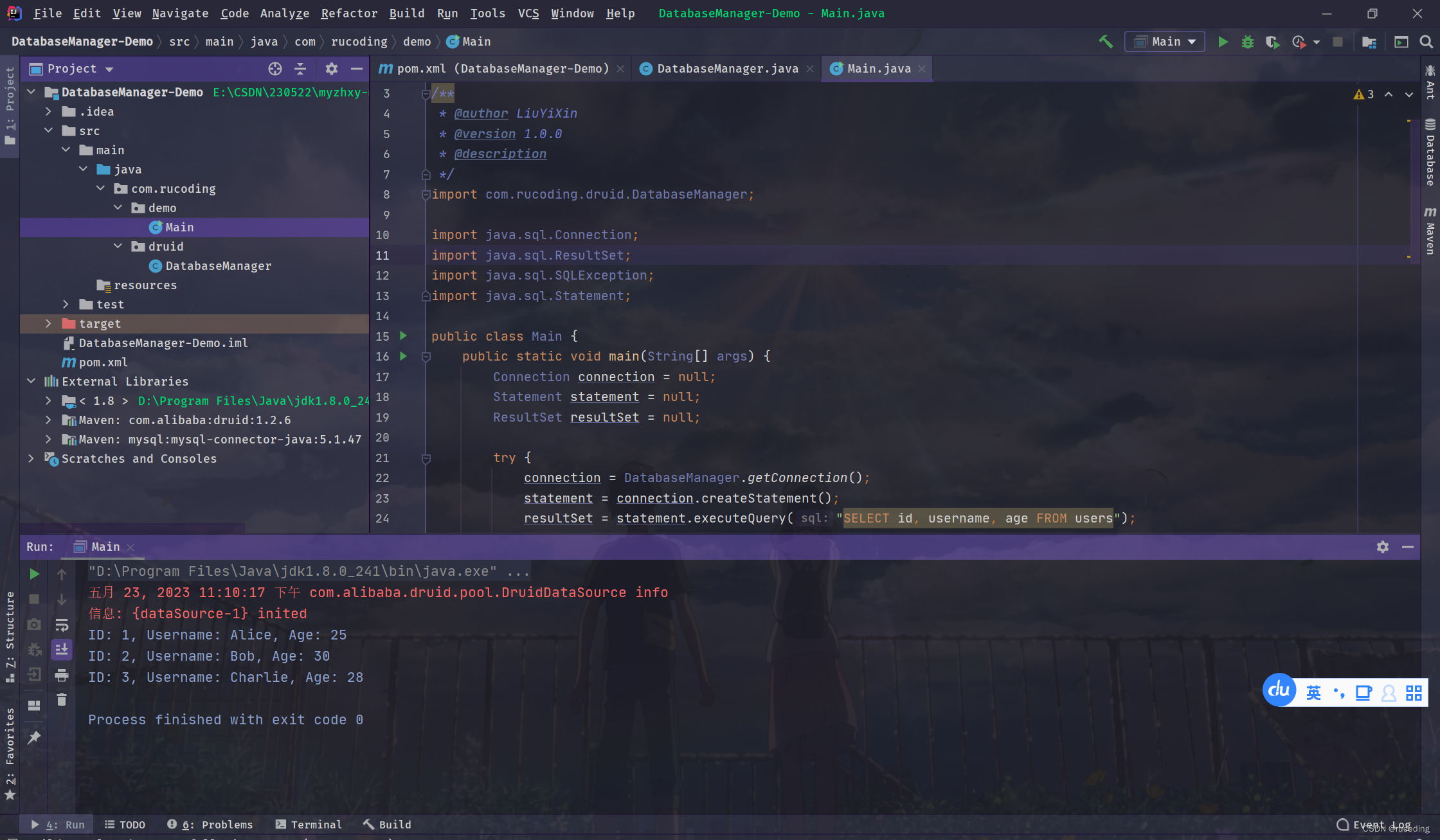
i
m
g
1
,
i
m
g
2
)
=
d
e
g
r
e
e
o
f
d
i
f
f
e
r
e
n
c
e
b
e
t
w
e
e
n
i
m
a
g
e
s
d(img1, img2)=degree of difference between images
d(img1,img2)=degreeofdifferencebetweenimages
\qquad
从而在获取到一幅新的图片时,直接将图片和数据库中的图片进行相似度的计算,设置一个阈值
τ
\tau
τ来决定是否接受这幅图片属于数据库中某个人;最终选择相似度最大的数据库中的图片对应的人作为这幅图片的从属人。
3、siamese network
\qquad
siamese network架构就是训练两个相同的卷积神经网络,这个卷积神经网络输入一幅图片,经过若干个卷积层,池化层和全连接层之后,输出这幅图片的编码;最终将不同图片之间的编码做二范数,若两幅图片属于同一个人,则训练二范数的值需要尽可能的小。

4、Triplet loss function
\qquad
上述siamese network同样使用误差反向传播来进行网络参数的训练,siamese network的目标可以通过下述方式进行设定:选定一幅图片作为anchor picture(A),之后选择一幅同人图片作为positive picture(A)和一幅非同人图片作为negative picture(N),分别计算anchor picture和positive picture,negative picture之间的相似度,同时设定一个margin
α
\alpha
α来进一步区分positive picture和negative picture,最终得到的目标如下所示:
∣
∣
f
(
A
)
−
f
(
P
)
∣
∣
2
+
α
≤
∣
∣
f
(
A
)
−
f
(
N
)
∣
∣
2
||f(A)-f(P)||^2+\alpha \leq ||f(A)-f(N)||^2
∣∣f(A)−f(P)∣∣2+α≤∣∣f(A)−f(N)∣∣2
\qquad
非定三幅图片A,P和N,Triplet loss function的定义如下所示:
L
(
A
,
P
,
N
)
=
m
a
x
(
∣
∣
f
(
A
)
−
f
(
P
)
∣
∣
2
+
α
≤
∣
∣
f
(
A
)
−
f
(
N
)
∣
∣
2
,
0
)
L(A,P,N)=max(||f(A)-f(P)||^2+\alpha \leq ||f(A)-f(N)||^2, 0)
L(A,P,N)=max(∣∣f(A)−f(P)∣∣2+α≤∣∣f(A)−f(N)∣∣2,0)
\qquad
从而可以得到神经网络的损失函数为:
J
=
∑
i
=
1
m
L
(
A
i
,
P
i
,
N
i
)
J=\sum_{i=1}^{m}L(A^i,P^i,N^i)
J=i=1∑mL(Ai,Pi,Ni)
\qquad
在训练时,训练集中需要包含同一个人的不同的图片,从而便于生成A,P,N三元组,e.g., 10K pictures of 1K persons.
5、人脸识别和二分类问题
\qquad
面部识别问题同样可以转化成一个二分类问题来进行处理,方法是将两幅图片输入siamese network,将输出的图像的encoding向量输入到一个神经元中,经过sigmoid函数处理之后输出0和1表示这两幅图片是否为同一个人,令encoding向量的维度为128,其中sigmoid函数输入的值可以如下进行设置:
y
^
=
σ
(
∑
k
=
1
128
ω
i
∣
f
(
x
(
i
)
)
k
−
f
(
x
(
j
)
)
k
∣
+
b
)
\hat{y} = \sigma (\sum_{k=1}^{128} \omega_i|f(x^{(i)})_k-f(x^{(j)})_k|+b)
y^=σ(k=1∑128ωi∣f(x(i))k−f(x(j))k∣+b)
\qquad
其中
ω
i
\omega_i
ωi和
b
b
b是需要训练的参数,也可以选择其他形式将encoding进行输入,如
χ
2
\chi^2
χ2形式:
(
f
(
x
(
i
)
)
k
−
f
(
x
(
j
)
)
k
)
2
f
(
x
(
i
)
)
k
+
f
(
x
(
j
)
)
k
\frac{(f(x^{(i)})_k-f(x^{(j)})_k)^2}{f(x^{(i)})_k+f(x^{(j)})_k}
f(x(i))k+f(x(j))k(f(x(i))k−f(x(j))k)2