文章目录
- 1. 数据库连接池的好处
- 1.1 提高性能
- 1.2 连接的重用
- 1.3 连接管理和监控
- 2. 代码演示
- 2.1 新建maven项目
- 2.2 配置maven地址
- 2.3 配置 Druid 数据源
- 2.4 编写测试代码
- 2.4.1 创建一个 Druid 数据源连接池和获取连接
- 2.4.2 编写测试类
- 2.4.3 新建数据库表
- 2.4.4 运行截图
- 3. 完整代码下载
数据库连接池(database connection pool)是在 Java 中用于管理数据库连接的一种技术。它的主要目的是提高数据库连接的重用性和性能。在传统的数据库连接方式中,每次与数据库建立连接时都需要进行一系列的网络通信和身份验证操作,这样的开销较大并且会影响应用程序的性能。而连接池则通过预先创建一定数量的数据库连接,并将这些连接保存在一个池中,供应用程序随时使用和归还。
1. 数据库连接池的好处
1.1 提高性能
连接池可以避免频繁地创建和销毁数据库连接,从而节省了宝贵的资源和时间。通过重复使用现有的连接,可以大大减少连接建立和认证的开销,提高数据库操作的响应速度和整体性能。
1.2 连接的重用
连接池能够重复利用已经创建的连接,避免了每次操作都需要重新建立连接的开销。这样可以减少系统负载,提高并发处理能力,同时也减轻了数据库服务器的压力。
1.3 连接管理和监控
连接池可以提供连接的管理和监控功能,包括连接的分配和回收、连接的空闲超时处理、连接的健康检查等。这样可以确保连接的有效性和可靠性,避免无效或失效的连接被分配给应用程序使用。
2. 代码演示
2.1 新建maven项目
点击File,选择New - Project
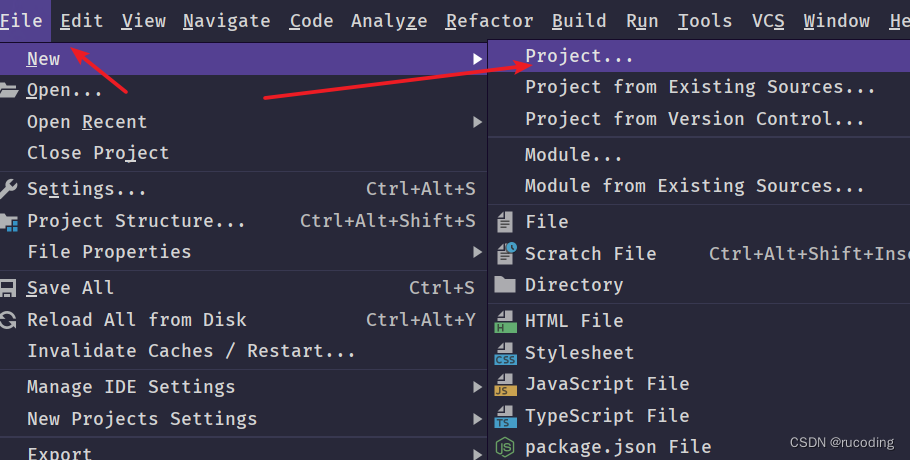
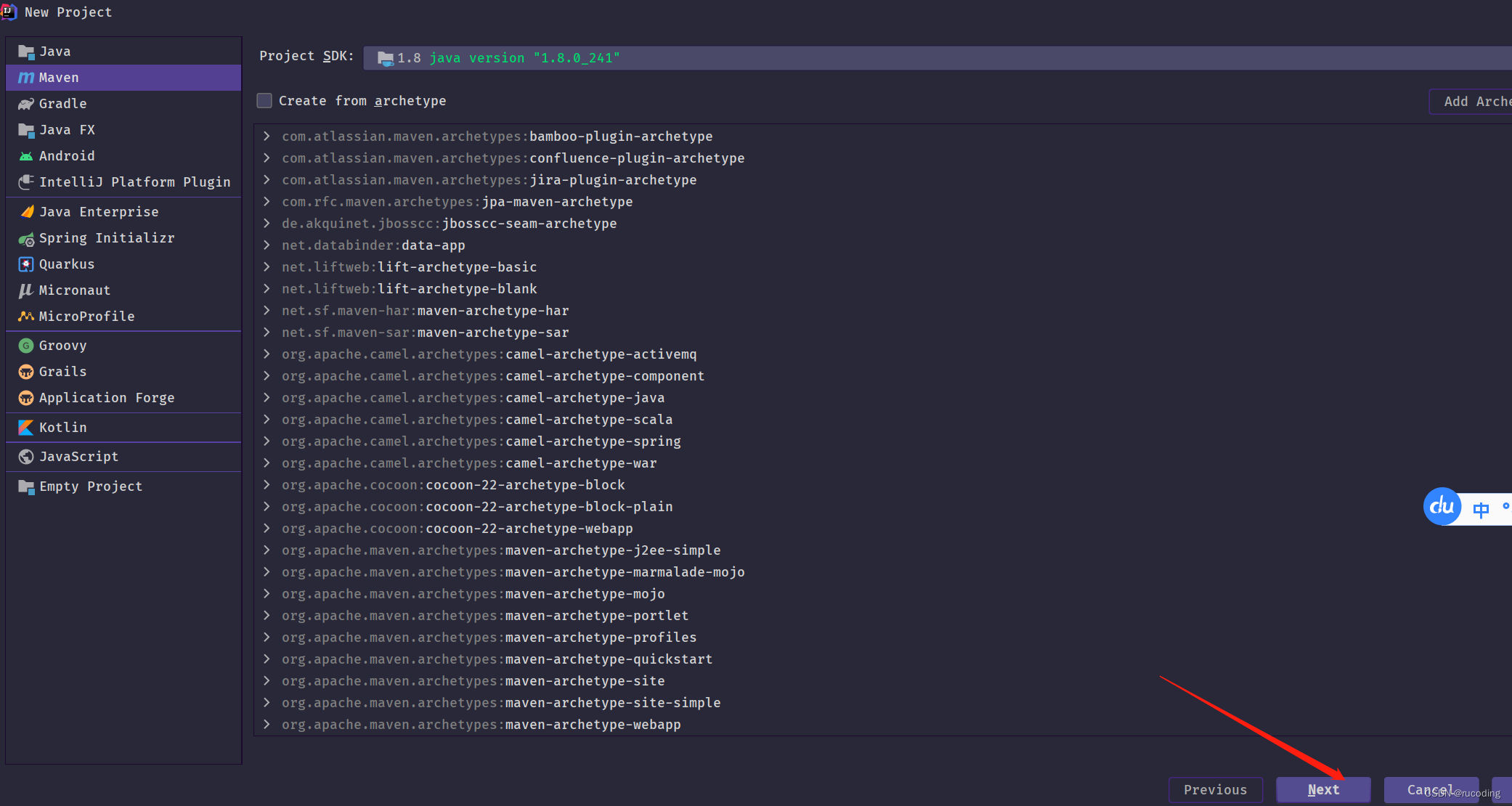
选择Maven,点击Next
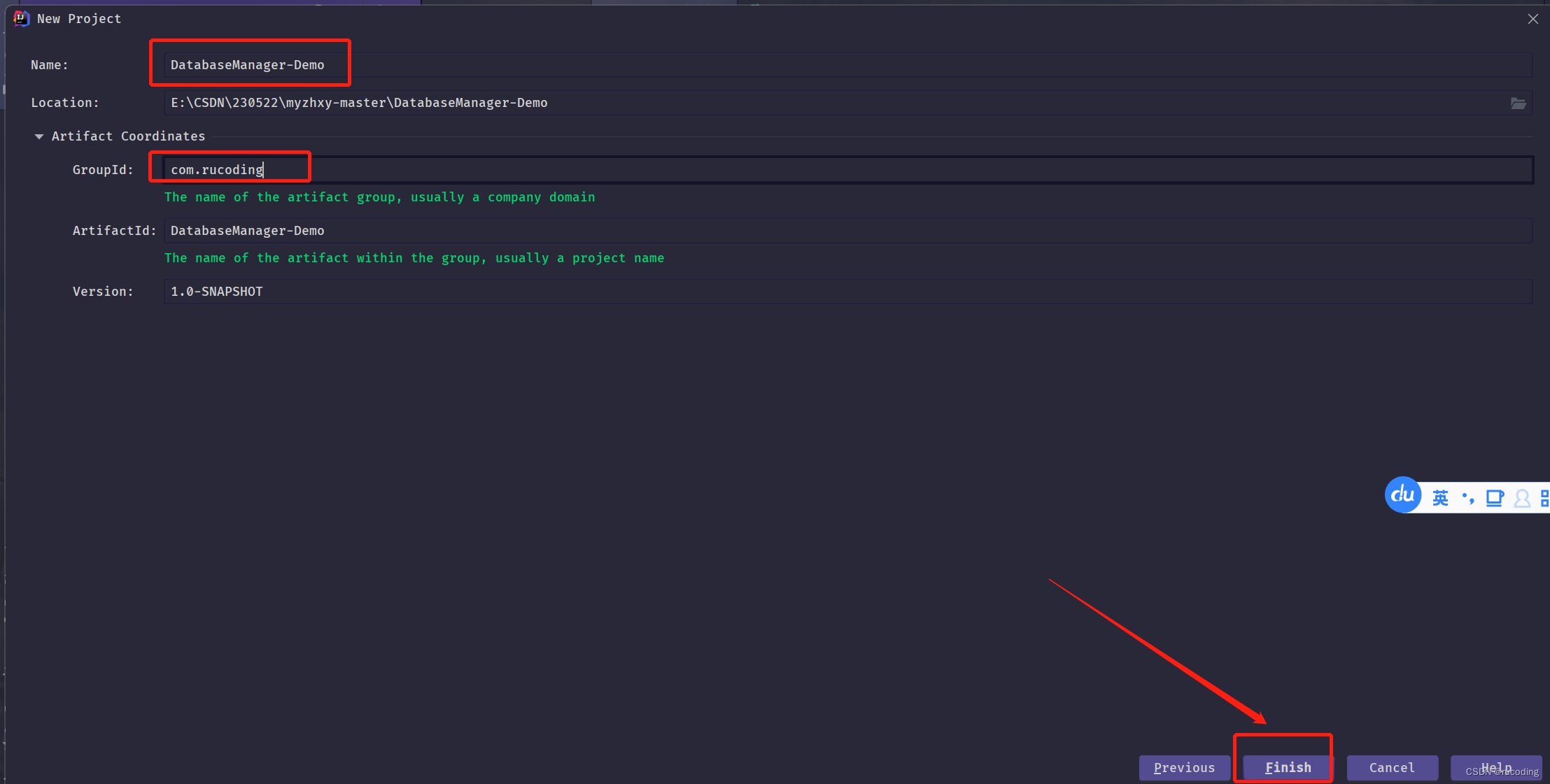
填写项目名称信息,点击Finish
2.2 配置maven地址
点击File,Settings设置
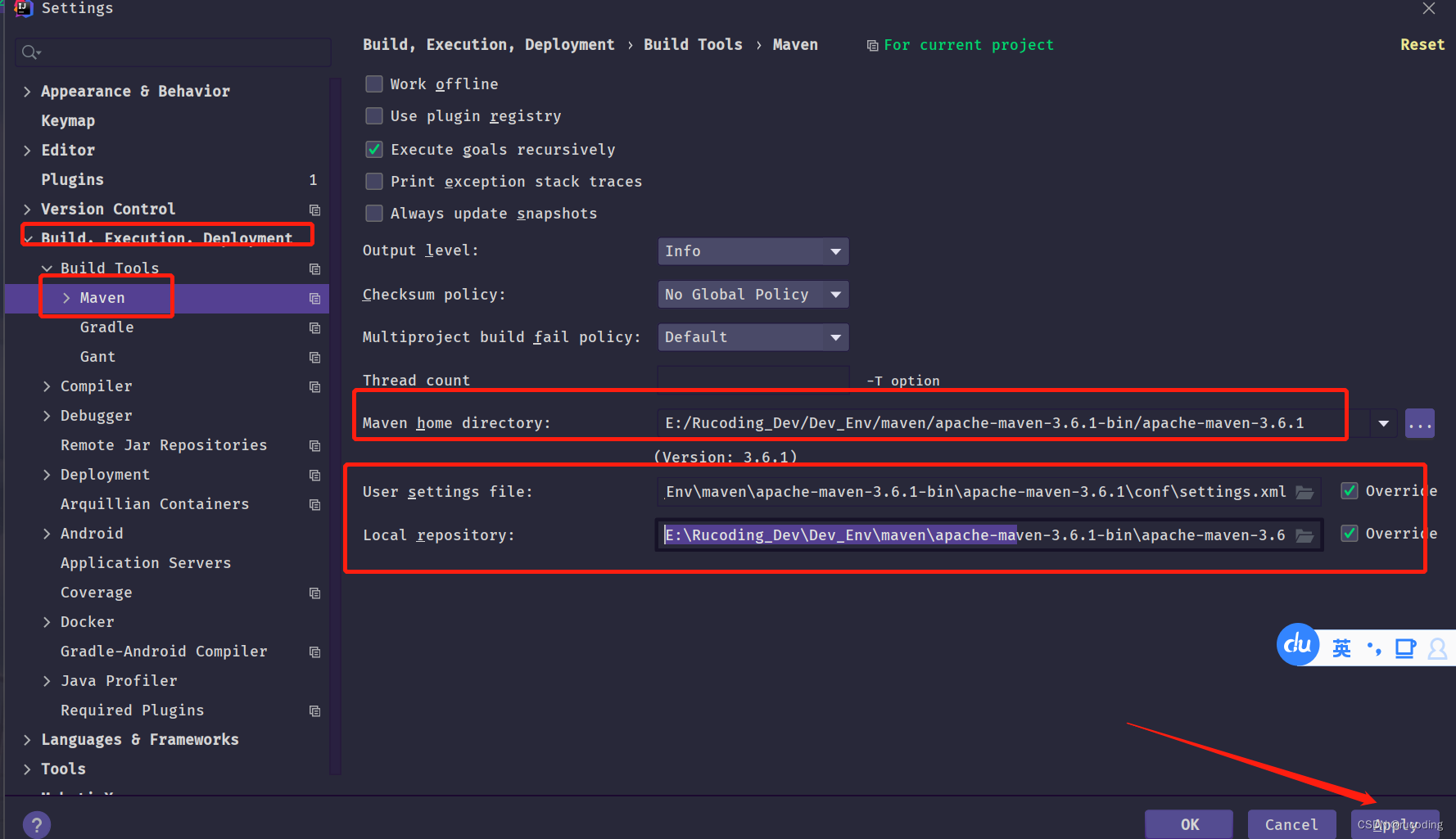
检索maven,配置为本地对应maven安装目录:未配置的,可点击查看我之前的博客文章:
安装Maven 3.6.1:图文详细教程(适用于Windows系统
2.3 配置 Druid 数据源
需要添加 Druid 的依赖。在 Maven 项目中,可以在 pom.xml 文件中添加以下依赖配置:
<dependencies>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.6</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
</dependencies>
点击刷新加载之后,显示如下图示:
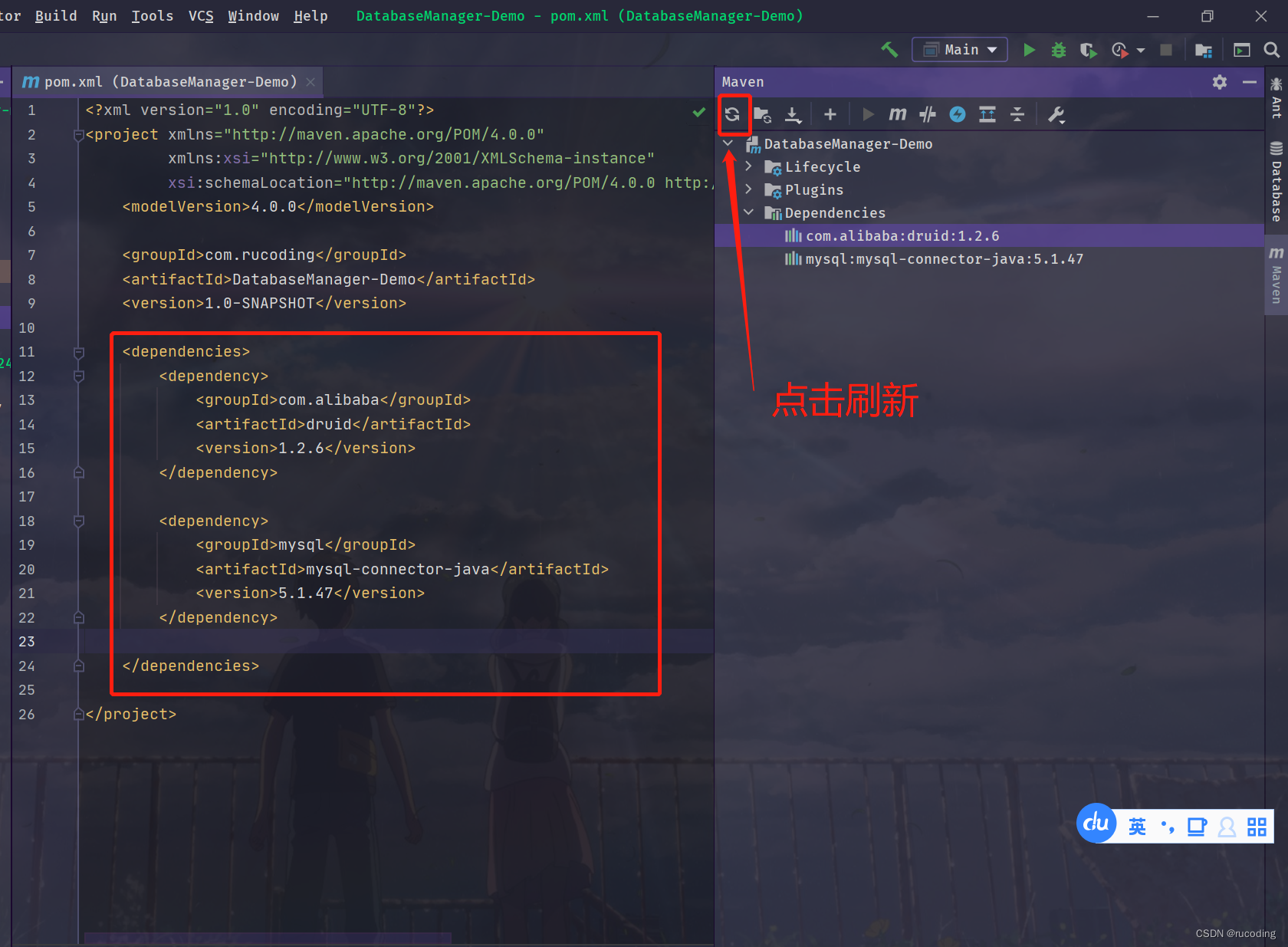
2.4 编写测试代码
2.4.1 创建一个 Druid 数据源连接池和获取连接
package com.rucoding.druid;
/**
* @author LiuYiXin
* @version 1.0.0
* @description
*/
import com.alibaba.druid.pool.DruidDataSource;
import java.sql.Connection;
import java.sql.SQLException;
public class DatabaseManager {
private static DruidDataSource dataSource;
static {
dataSource = new DruidDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/mydatabase?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC");
dataSource.setUsername("root"); //链接账密信息结合实际自己的
dataSource.setPassword("123456"); //链接账密信息结合实际自己的
// 其他连接池配置参数
dataSource.setInitialSize(10); // 初始连接数
dataSource.setMaxActive(100); // 最大连接数
}
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
}
在上述代码中,我们使用 DruidDataSource 类创建了一个 Druid 数据源连接池,并设置了数据库连接的相关配置,例如数据库驱动、连接地址、用户名、密码等。连接池的大小由 setInitialSize() 和 setMaxActive() 方法指定。
2.4.2 编写测试类
package com.rucoding.demo;
/**
* @author LiuYiXin
* @version 1.0.0
* @description
*/
import com.rucoding.druid.DatabaseManager;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class Main {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
connection = DatabaseManager.getConnection();
statement = connection.createStatement();
resultSet = statement.executeQuery("SELECT id, username, age FROM users");
while (resultSet.next()) {
// 处理查询结果
int id = resultSet.getInt("id");
String username = resultSet.getString("username");
int age = resultSet.getInt("age");
System.out.println("ID: " + id + ", Username: " + username + ", Age: " + age);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
// 释放资源
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
在上述示例中,我们使用 DatabaseManager.getConnection() 方法从 Druid 连接池中获取一个数据库连接,并使用该连接执行查询操作。在使用完连接后,需要手动释放连接资源,以便将连接归还给连接池供其他请求使用。
2.4.3 新建数据库表
新建一个数据库,名字为mydatabase
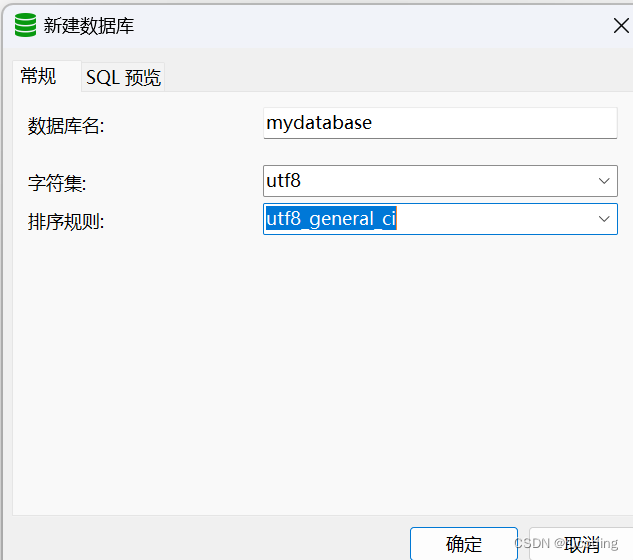
执行建表语句并添加数据:
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(50) NOT NULL,
age INT NOT NULL
);
INSERT INTO users (username, age) VALUES
('Alice', 25),
('Bob', 30),
('Charlie', 28);
2.4.4 运行截图
输出数据库users表数数据信息: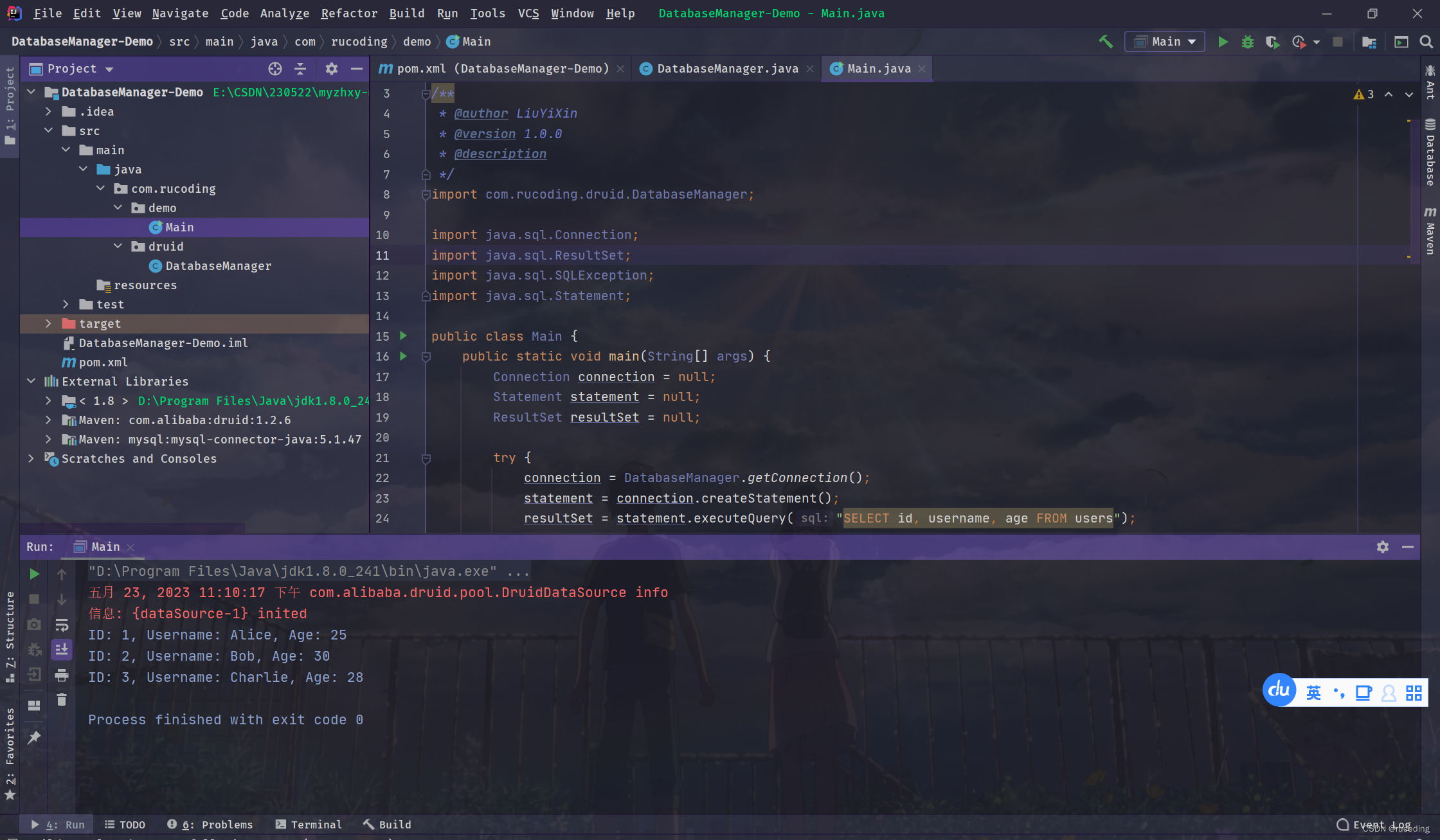
3. 完整代码下载
下载传送门