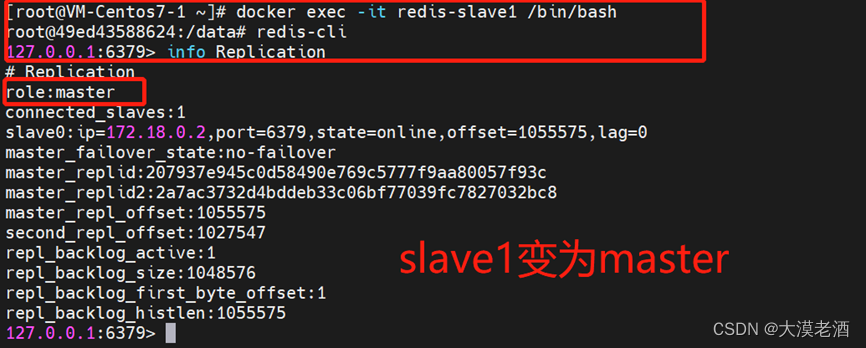
前言:美团的leaf集成了db分段生成id和雪花算法生成分布式id,本文对其实现部分细节展开讨论,leaf 的具体实现请参考:https://tech.meituan.com/MT_Leaf.html;
1 使用db分段id:
leaf 的分段id本质上是使用了id的区间段,看下id 区间段表:
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '',
`max_id` bigint(20) NOT NULL DEFAULT '1',
`step` int(11) NOT NULL,
`description` varchar(256) DEFAULT NULL,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- 使用biz_tag 作为业务的隔离;
- 使用max_id 作为下一段id 的起始值;
- 使用step 作为每段id 的长度

id 的获取过程: - 每次项目启动后,(开启了分段id 的开关)去获取分段id后,放入到系统的内存中
- 当使用的时候,通过http 请求接口:/api/segment/get/{key} 得到id,其中key对应leaf_alloc的biz_tag ;
- 获取本次使用的id 段SegmentBuffer,然后+1得到本次使用的id 并返回(如果本段的id 使用超过了10% 则去申请下一段id);
2 雪花算法id:
使用雪花算法生成的id 也是由时间戳+机器位+序列号组成的64位数字id,其中值得注意的是workId,会在每次项目启动的使用先去zookeeper中,通过ip+port 组成的key 去获取是否已经注册过,如果已经注册过则直接使用,否则注册持久有序的节点,以此来保证workId 唯一性;
看下SnowflakeZookeeperHolder 类中init 方法:
public boolean init() {
try {
CuratorFramework curator = createWithOptions(connectionString, new RetryUntilElapsed(1000, 4), 10000, 6000);
curator.start();
Stat stat = curator.checkExists().forPath(PATH_FOREVER);
if (stat == null) {
//不存在根节点,机器第一次启动,创建/snowflake/ip:port-000000000,并上传数据
zk_AddressNode = createNode(curator);
//worker id 默认是0
updateLocalWorkerID(workerID);
//定时上报本机时间给forever节点
ScheduledUploadData(curator, zk_AddressNode);
return true;
} else {
Map<String, Integer> nodeMap = Maps.newHashMap();//ip:port->00001
Map<String, String> realNode = Maps.newHashMap();//ip:port->(ipport-000001)
//存在根节点,先检查是否有属于自己的根节点
List<String> keys = curator.getChildren().forPath(PATH_FOREVER);
for (String key : keys) {
String[] nodeKey = key.split("-");
realNode.put(nodeKey[0], key);
nodeMap.put(nodeKey[0], Integer.parseInt(nodeKey[1]));
}
// private String listenAddress = null;//保存自身的key ip:port
Integer workerid = nodeMap.get(listenAddress);
if (workerid != null) {
//有自己的节点,zk_AddressNode=ip:port
zk_AddressNode = PATH_FOREVER + "/" + realNode.get(listenAddress);
workerID = workerid;//启动worder时使用会使用
if (!checkInitTimeStamp(curator, zk_AddressNode)) {
throw new CheckLastTimeException("init timestamp check error,forever node timestamp gt this node time");
}
//准备创建临时节点
doService(curator);
updateLocalWorkerID(workerID);
LOGGER.info("[Old NODE]find forever node have this endpoint ip-{} port-{} workid-{} childnode and start SUCCESS", ip, port, workerID);
} else {
//表示新启动的节点,创建持久节点 ,不用check时间
String newNode = createNode(curator);
zk_AddressNode = newNode;
String[] nodeKey = newNode.split("-");
workerID = Integer.parseInt(nodeKey[1]);
doService(curator);
updateLocalWorkerID(workerID);
LOGGER.info("[New NODE]can not find node on forever node that endpoint ip-{} port-{} workid-{},create own node on forever node and start SUCCESS ", ip, port, workerID);
}
}
} catch (Exception e) {
LOGGER.error("Start node ERROR {}", e);
try {
Properties properties = new Properties();
properties.load(new FileInputStream(new File(PROP_PATH.replace("{port}", port + ""))));
workerID = Integer.valueOf(properties.getProperty("workerID"));
LOGGER.warn("START FAILED ,use local node file properties workerID-{}", workerID);
} catch (Exception e1) {
LOGGER.error("Read file error ", e1);
return false;
}
}
return true;
}
ip 获取已激活网卡的IP地址,端口号来自于:leaf.snowflake.port 的设置;
3 MyBatis-Plus集成:
目前已经了解了分布式id 的生成方式,只需要在需要的项目中,创建package com.baomidou.mybatisplus.core.incrementer 包,并创建DefaultIdentifierGenerator 类:重写nextId 方法,通过http 访问获取id 的接口得到id即可。
package com.baomidou.mybatisplus.core.incrementer;
import com.alibaba.fastjson2.JSONObject;
import com.xiaoju.uemc.tinyid.client.utils.TinyId;
import lombok.extern.slf4j.Slf4j;
import java.util.Map;
@Slf4j
public class DefaultIdentifierGenerator implements IdentifierGenerator {
@Override
public Long nextId(Object entity) {
Object o = null;
if (null != entity) {
Map<String, Object> eMap = JSONObject.parseObject(JSONObject.toJSONString(entity), Map.class);
if (eMap.containsKey("bizTag")) {
o = eMap.get("bizTag");
}
}
if (null == o) {
o = "leaf-segment-test";
}
Long id = http 方法访问 /api/segment/get/{key} 或者 /api/snowflake/get/{key} 得到id;
return id;
}
}
4 总结:
- leaf 的分段id 通过leaf_alloc 中biz_tag作为业务分隔,使用max_id和step 来每次获取一段int 类型的id值,并且使用双buffer 的方式保证高效性和解决id服务短暂不可用的问题;
- leaf 的雪花算法通过向zookeeper 注册持久有序的节点,依次来作为workId 机器位的获取,通过ip+port 作为key ,来判断是否相同服务。
美团leaf 的 git 参考地址:git clone git@github.com:Meituan-Dianping/Leaf.git