Seaborn是基于matplotlib的Python可视化库。 它提供了一个高级界面来绘制有吸引力的统计图形。Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,不需要经过大量的调整就能使你的图变得精致。但应强调的是,应该把Seaborn视为matplotlib的补充,而不是替代物。
Seaborn安装
pip install seaborn
安装完Seaborn包后,我们就开始进入接下来的学习啦,首先我们介绍kdeplot的画法。
kdeplot(核密度估计图)
核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。通过核密度估计图可以比较直观的看出数据样本本身的分布特征。具体用法如下:
seaborn.kdeplot(data,data2=None,shade=False,vertical=False,kernel='gau',bw='scott',
gridsize=100,cut=3,clip=None,legend=True,cumulative=False,shade_lowest=True,cbar=False, cbar_ax=None, cbar_kws=None, ax=None, **kwargs)
我们通过一些具体的例子来学习一些参数的用法:
- 首先导入相应的库
%matplotlib inline #IPython notebook中的魔法方法,这样每次运行后可以直接得到图像,不再需要使用plt.show()
import numpy as np #导入numpy包,用于生成数组
import seaborn as sns #习惯上简写成sns
sns.set() #切换到seaborn的默认运行配置
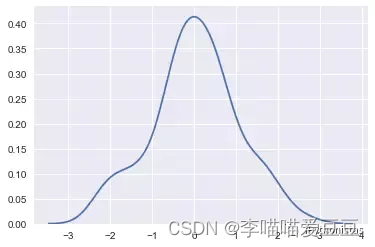
- 绘制简单的一维kde图像
x=np.random.randn(100) #随机生成100个符合正态分布的数
sns.kdeplot(x)
cut:参数表示绘制的时候,切除带宽往数轴极限数值的多少(默认为3)
sns.kdeplot(x,cut=0)
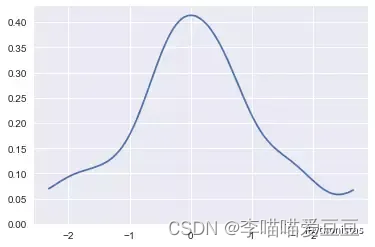
cumulative :是否绘制累积分布
sns.kdeplot(x,cumulative=True)
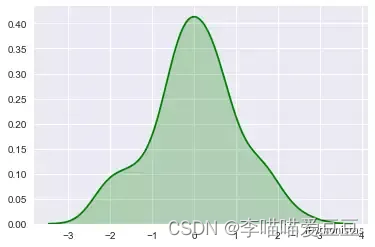
shade:若为True,则在kde曲线下面的区域中进行阴影处理,color控制曲线及阴影的颜色
sns.kdeplot(x,shade=True,color="g")
vertical:表示以X轴进行绘制还是以Y轴进行绘制
sns.kdeplot(x,vertical=True)
二元kde图像
y=np.random.randn(100)
sns.kdeplot(x,y,shade=True)
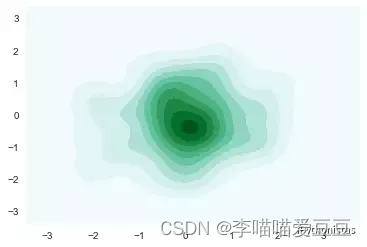
cbar:参数若为True,则会添加一个颜色棒(颜色帮在二元kde图像中才有)
sns.kdeplot(x,y,shade=True,cbar=True)

举例说明二元kde图像
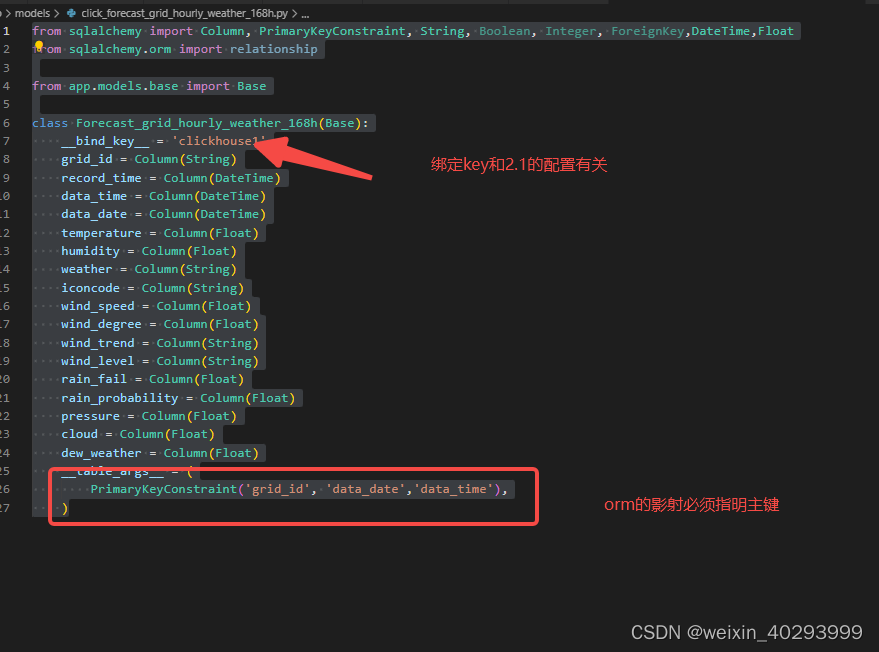
定义了一个函数
def plot_distribution_target(df, target, cols):
dist_cols=5
dist_rows=len(cols)
plt.figure(figsize=(5*dist_cols,5*dist_rows))
i=1
for col in cols:
ax=plt.subplot(dist_rows,dist_cols,i)
ax=sns.kdeplot(df[df[target]==1][col],color='Red',shade=True)#train_data
ax=sns.kdeplot(df[df[target]==0][col],color='Blue',shade=True)
ax.set_xlabel(col)
ax.set_ylabel('Frequency')
ax=ax.legend(['target=1','target=0'])
i+=1
plt.show()
现在有个数据,保存在csv文件中:
import seaborn as sns #习惯上简写成sns
sns.set() #切换到seaborn的默认运行配置
#定义训练数据集的位置
pathTrain='./PROCESSING_DATA'
train_tag = pd.read_csv(pathTrain+'/df_tag.csv')
print(train_tag.head())
输出如下:
id flag gdr_cd age mrg_situ_cd edu_deg_cd acdm_deg_cd deg_cd \
0 U7A4BAD 0 1 41 1 1 6 6
1 U557810 0 1 35 0 12 5 6
2 U1E9240 0 1 53 1 0 2 2
3 U6DED00 0 0 41 1 12 6 6
4 UDA8E28 0 0 42 1 1 6 1
job_year ic_ind ... crd_card_act_ind l1y_crd_card_csm_amt_dlm_cd \
0 3 0 ... 0 0
1 4 0 ... 0 0
2 9 0 ... 0 0
3 0 0 ... 0 0
4 3 1 ... 0 0
atdd_type perm_crd_lmt_cd cur_debit_cnt cur_credit_cnt \
0 0 3 1 0
1 0 1 1 0
2 0 7 2 0
3 0 1 1 0
4 0 2 7 0
cur_debit_min_opn_dt_cnt cur_credit_min_opn_dt_cnt cur_debit_crd_lvl \
0 3492 -1 10
1 4575 -1 10
2 4894 -1 40
3 4938 -1 10
4 2378 -1 20
isTest
0 -1
1 -1
2 -1
3 -1
4 -1
[5 rows x 44 columns]
plot_distribution_target(train_tag,'flag', ['gdr_cd','age'])
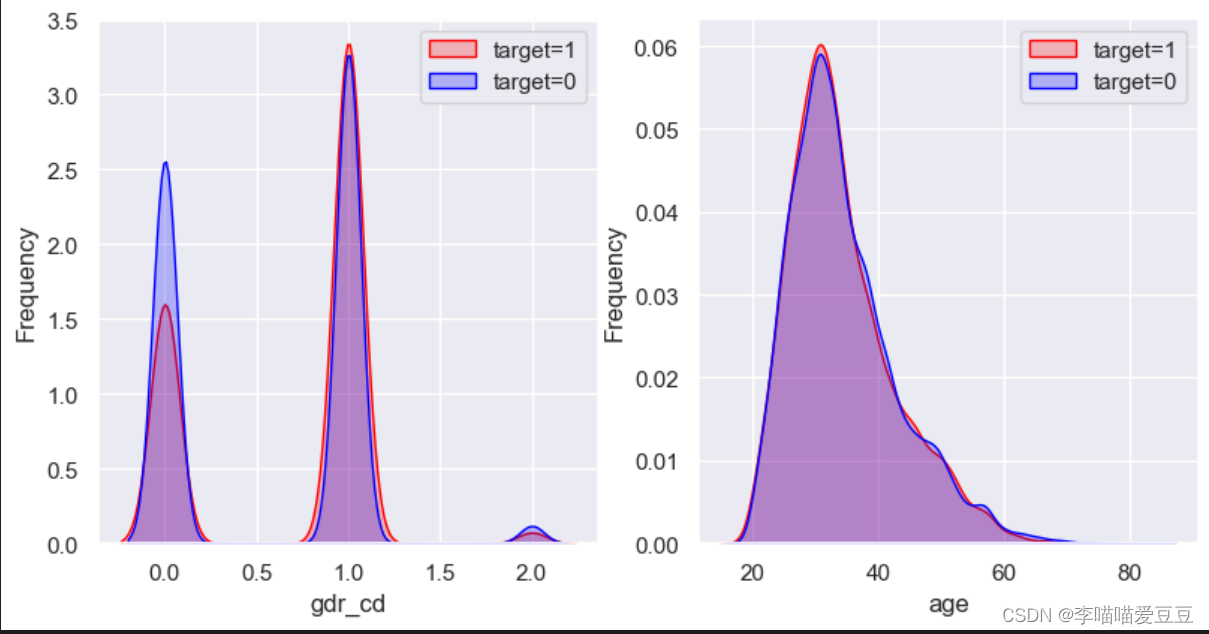
这几个特征,在target=0和target=1时的kde,发现这几个特征对target的区分能力都非常有限。